深度学习基础概念【持续更新】
1. 梯度消失
如果网络中某一层的激活函数(如 sigmoid 或 tanh)在输入较大的情况下有很小的梯度(比如接近零),那么当这些小的梯度通过多层反向传播时,它们会逐渐变得更小。这意味着在深层网络的前面几层,梯度接近零,导致权重更新变得非常缓慢,甚至停滞。
1.1 为什么会有梯度消失:
激活函数的饱和区间:像 sigmoid 和 tanh 这样的激活函数在输入值非常大或非常小时,其导数(梯度)非常小。当这些激活函数的输出接近于 0 或 1 时,导数趋近于 0,导致梯度在反向传播过程中逐渐消失。
深度网络的层数:随着网络层数的增加,梯度逐层缩小,导致在浅层的梯度变得几乎为零,无法有效地更新权重。
1.2 解决方法:
使用 ReLU 激活函数:ReLU(Rectified Linear Unit)在正值区间有较大的梯度(不会消失),因此可以减轻梯度消失的问题。
初始化方法:通过合适的权重初始化方法(如 Xavier 或 He 初始化),可以帮助缓解梯度消失问题。
批量归一化(Batch Normalization):通过对每一层的输入进行标准化,保证数据的分布不至于过于极端,从而避免梯度消失。
梯度裁剪:对于 RNN,采用梯度裁剪(Gradient Clipping)可以防止梯度爆炸和梯度消失。
2. 通道
在图像处理或深度学习中,通道(Channel) 是指一张图像或特征图在每个像素位置上存储的不同维度的信息。通道可以看作是“图像的维度”,每个通道记录某种特征。
2.1 现实中的例子:RGB图像
一张彩色图片通常有 3 个通道:
R:红色通道 G:绿色通道 B:蓝色通道
所以一张 224×224 的 RGB 图像的形状是:
[3, 224, 224] (3表示通道数)每个 [i, j] 位置,有红、绿、蓝三个颜色值。
2.2 深度学习中的例子:卷积特征图
在神经网络中,经过卷积层后输出的是多通道的特征图,比如:
shape = [batch_size, channels, height, width]比如某一层输出:
[1, 64, 32, 32]表示有 64 个不同的“滤镜”提取出了 64 种不同的特征,每个特征图大小为 32×32,这些就是 64 个通道。
2.3 总结类比
类比 | 通道数 |
黑白照片 | 1 |
彩色照片(RGB) | 3 |
网络中一层输出 | 可为 16、32、64... 任意数量,表示提取了多少种特征 |
3. 各类激活函数
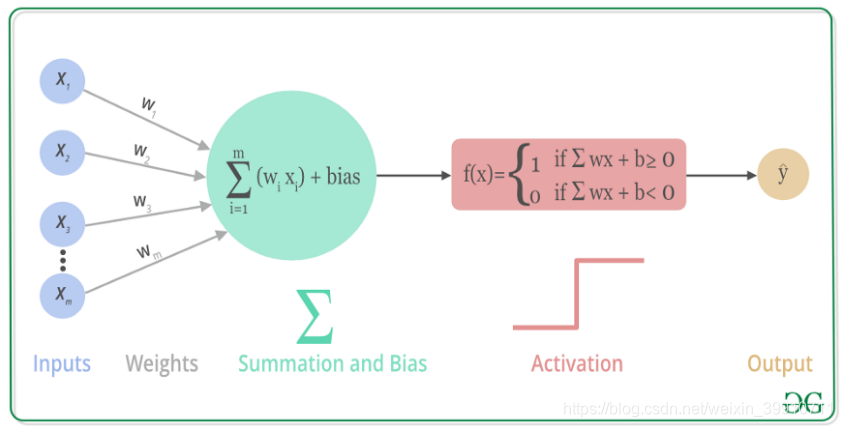 ReLU:f(x)=max(0,x)
ReLU:f(x)=max(0,x)
即对于输入值 xxx,如果 xxx 大于0,就输出 xxx;如果 xxx 小于等于0,就输出0。
激活函数 | 适用位置 | 优点 | 缺点 |
ReLU | 隐藏层 | 快、简洁 | 死亡神经元 |
Leaky ReLU | 隐藏层(替代ReLU) | 缓解死亡问题 | 多了超参数 |
Sigmoid | 输出层(二分类) | 输出概率 | 梯度消失 |
Tanh | RNN中常见 | 零中心、平滑 | 梯度消失 |
Softmax | 输出层(多分类) | 概率归一化 | 仅用于最后一层 |
Swish | 深层网络(CNN、NLP) | 表现优于ReLU | 计算复杂 |
GELU | Transformer/BERT | 训练稳定 | 计算开销大 |