linux之IO存储子系统全流程分析
1、简介
kernel的各个子系统互相独立又相互纠缠,这篇文章旨在从系统调用到硬件磁盘给大家简单捋一遍整个io子系统的主线流程。中间涉及系统调用(syscall) -> 文件系统(fs) -> buffer_head/iomap -> bio -> request->io调度器 -> io软件调度队列(ctx) -> io硬件调度队列(hctx) -> scsi磁盘驱动 等相关知识.
2、操作文件代码引入
开篇先引入一个简单的c语言代码
int main()
{char buff[128] = {0};int fd = open("/var/pilgrimtao.txt", O_CREAT|O_RDWR);
write(fd, "pilgrimtao is cool", 18);pread(fd, buff, 128, 0);printf("%s\n", buff);
close(fd);return 0;
}这个demo非常简单,但是一些问题引发了我们的思考,例如read和write函数如何读写磁盘数据的,kernel如何解析fd、buf、len等参数,并转换为磁盘能看懂的信息,读出磁盘对应位置的数据的?
c函数库中read和write对应着内核的sys_read和sys_write两个系统调用(可用strace工具验证),我们将从这两个系统调用开始探索。
那么读写磁盘需要几步?
sys_read:
- 申请内存
- 将磁盘内容读到内存中
- 将内存内容返回用户态
sys_write
- 申请内存
- 将磁盘内容读到内存中
- 将需要修改的数据写入内存中
你肯定已经发现了,sys_write和sys_read前两步是完全相同的,对于sys_write而言,在写磁盘之前要把磁盘数据先读出来,修改完再写回去,也是非常合理的。但是有两点需要注意,sys_write并没有写磁盘的操作,而是把这个操作交给了定期开启的回写进程,如果不久之前刚读过磁盘,导致内存中有磁盘数据的缓存,那么本次读取时直接读取内存的缓存数据即可,避免了耗时的磁盘操作,这也是人们把这类内存称为page cache的原因。
问题:这个回写进程是哪个进程?
如果阅读了sys_write和sys_read系统调用的代码,可以发现这两个函数基本没什么干货,只是做了一些简单的check操作,然后直接进入了文件系统的file_oprations回调函数。file_operations回调函数是文件系统自定义的,我这里用xfs举例(初学者也可以阅读minix文件系统的源码做为铺垫,因为它足够简单)。
代码参考:
SYSCALL_DEFINE3(read, ...) -> ksys_read -> vfs_read -> read_iter -> xfs_file_read_iter
SYSCALL_DEFINE3(write, ...) -> ksys_write -> vfs_write -> new_sync_write -> call_write_iter ->write_iter -> xfs_file_write_iter磁盘(disk)的访问模式有三种 BUFFERED、DIRECT、DAX。前面提到的由于page cache存在可以避免耗时的磁盘通信就是BUFFERED访问模式的集中体现;但是如果我要求用户的write请求要实时存储到磁盘里,不能只在内存中更新,那么此时我便需要DIRECT模式;大家可能听说过flash分为两种nand flash和nor flash,nor flash可以像ram一样直接通过地址线和数据线访问,不需要整块整块的刷,对于这种场景我们采用DAX模式。
DAX模式:
DAX 模式是块设备的一种特殊访问模式,它允许应用程序直接(Directly)访问持久性内存(PMEM)设备,无需经过操作系统的页缓存(Page Cache)。
像nor flash 存储设备,既能按字节寻址、速度又接近内存、同时数据还能持久化的设备来说,页缓存成为了一个不必要的性能瓶颈和开销源。
DAX 模式访问的优点:
直接访问:应用程序通过
mmap()将文件映射到其地址空间后,CPU 的加载(load)和存储(store)指令直接操作在持久性内存介质上,完全 bypass(绕过)了内核的页缓存。零拷贝:消除了内核态和用户态之间的数据拷贝。
更低延迟:访问路径更短,没有缓存管理开销。
更低的 CPU 占用:减少了上下文切换和拷贝所需的 CPU 周期。
DAX的技术实现基础:
硬件支持:必须使用持久性内存(PMEM) 设备,例如 Intel Optane Persistent Memory。这些设备在系统中可以通过两种模式出现:
FS-DAX 模式:PMEM 被配置为一个块设备(如
/dev/pmem0),然后在其上创建一个支持 DAX 的文件系统。Dev-DAX 模式:PMEM 被呈现为一个字符设备(如
/dev/dax0.0),可以像内存一样直接mmap,完全绕过文件系统。
文件系统支持:运行在 PMEM 块设备之上的文件系统必须支持 DAX 选项。常见的支持 DAX 的文件系统有:
ext4 和 xfs(最常用)
NOVA
在挂载时使用
-o dax选项来启用,或者在文件系统的超级块中指定dax挂载属性。
3、bio机制
常见的磁盘有机械硬盘和固态硬盘两种,机械硬盘是由一个个扇区组成,而固态硬盘由一个个存储页组成,我们统称它们为sector,为了兼容历史,我们规定一个sector为512字节。因此访问磁盘时我们需要两个信息,数据存储的sector位置和连续sector的数目。磁盘需要内存作为缓存以提高访问速度,所以我们需要先申请内存,并确定的page地址和页内偏移。磁盘驱动只有拿到sector位置、sector数目、page(folio)地址、page(folio)页内偏移才能将数据写入或者写出。
4、folio简介
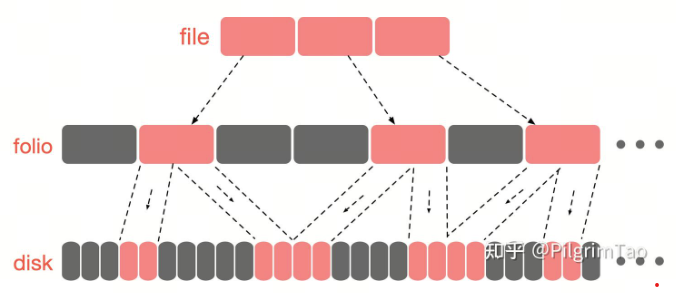
首先做一个简单科普,如图所示,内存是以page (4k)为单位的

kernel在2020年12月的patch中提出了folio的概念,我们可以把folio简单理解为一段连续内存,一个或多个page的集合,他和page的关系如图:

图中展示了一个8k的folio,同理我们也可以申请16K或者32K的folio,本质上是folio_alloc也是调用了alloc_pages(gfp, order),对比4K的folio和4K的page其实没什么区别,而且现在kernel的folio cache一般也都是4K,但是下文依然想用folio的称呼替代page,可能是因为folio是未来趋势,代码中也是用folio表示的。
代码参考:
xfs_file_write_iter -> xfs_file_buffered_write -> iomap_file_buffered_write -> iomap_write_iter -> iomap_write_begin -> __filemap_get_folio -> filemap_alloc_folio缓存的folio 申请是文件系统write 函数实现。
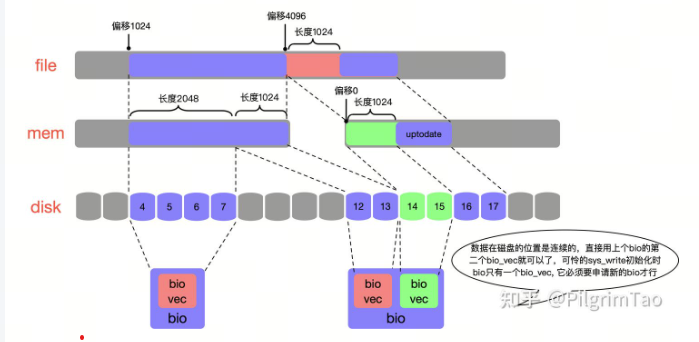
5、file、mem和disk的映射关系
如sys_read和sys_write所表示的那样,kernel给用户营造的视角是一个地址连续的file,用户读取file内容时只需要从偏移地址0的位置一直读到文件结尾,但是实际文件数据存储在mem和disk上却是不连续的。那么他们之间的关系是怎样的呢,我给大家举个例子。
重点理解这里的关系:如果上图是一个12K的文件,那么我可以将这个文件分为3个4K的数据块,将这3个4k的数据块存储在不连续的3个4K folio中,针对每个folio又能以文件系统自定义的block size(不是磁盘sector)为单位,将一个folio映射多个不连续的磁盘空间。
kernel需要定义一些数据结构来表示这个映射关系,同时也需要存储一些关键信息,例如sector位置、sector数目、folio 地址、folio页内偏移等等,我们需要用具体的结构体将它表示出来,所以kernel定义了struct bio来实现这一目的,如下图:
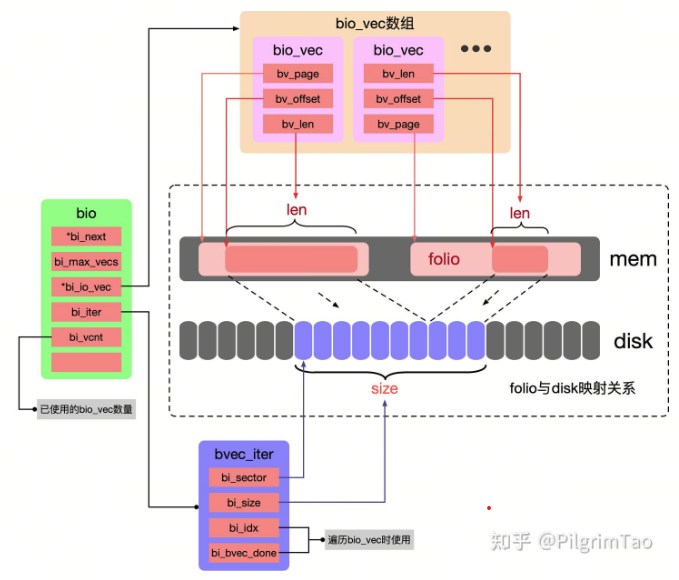
所以说, 上面三者的关系,使用的数据结构是struct bio.
struct bio描述了一段连续的磁盘空间,bvec_iter.bi_sector和bvec_iter.bi_size分别记录这段连续物理磁盘的起始段号和总大小。kernel也会申请一个名叫bio_vec的数组,赋值给bio.bi_io_vec,一个bio_vec描述了一段连续的mem空间,并且它不会超过一个folio的范围。bio_vec.bv_page记录了这个folio的head page,bio_vec.bv_offset记录folio内部offset,bio_vec.bv_len记录了mem映射长度,bv_len一般不会超过一个folio size的长度,除非两个folio物理地址是连续的,会通过bio_add_page合并bio_vec。一个bio中包含多少个bio_vec取决于,bio描述的这一段连续的磁盘空间映射了多少个不连续mem空间,同时如果一个bio中bio_vec的数目达到了bio_vec数组的最大值,也另外申请新的bio,至于bio_vec数组的最大值由bio初始化的时候指定(见函数bio_alloc)。每当bio使用了一个bio_vec,bio.bi_vcnt就会累加,如果想使用新的bio_vec,直接使用bio_vec的bi_vcnt偏移的成员即可。有个比较有意思的现象是,sys_write产生的bio只有一个bio_vec,但是sys_read产生的bio却有多个bio_vec。
6、bio关键信息获取
用户调用syscall时,内核能获取到的信息只有文件fd、文件offset、读写size,如syscall的形参所表示的那样,但是磁盘(disk)并不能识别文件的fd、offset、size,我们需要将它们转化成磁盘能看懂的信息。那么如何将用户层传进来的file fd和file offset转化为folio offset、folio len、sector ID、sector size,并把这些信息交给struct bio打包起来,发送给disk,是我们要考虑的问题。
6.1 获取folio信息
每一个file都会维护一棵基数树(radix tree,当前kernel优化为xarray),这棵树保存在一个per file的结构体address_space->i_pages中,这个文件已经映射过的folio都存储在了这棵树上,如果我们发现需要读写的folio可以在这棵树中找到,那么便不需要申请新的folio,直接从树上拿过来用即可(参考__filemap_get_folio函数),最终将folio head赋值给bio_vec.bv_page。
想要获得内存的folio offset和folio len十分简单,folio不仅仅在mem物理地址维度是连续的,它描述的文件数据在用户file角度也是连续的,所以我们只需要将file offset除以folio size(这里是4K)再取余数,就能得到folio offset,folio len为用户读取文件的size,保证磁盘连续的前提下与folio size取最小值。
6.2 获取sector信息
如果想要获取磁盘的sector ID和sector size比较复杂。一个文件有很多固有属性,包括文件名、创建时间、访问时间、修改时间、文件存储在磁盘的位置(sector ID和sector size)等,他们都存储在struct inode结构体中,每个实体文件都维护着自己私有的inode,大家可能会想,获取磁盘的sector ID和sector size有什么难的,直接从struct inode读取不就好了?事实确实是这样,如果inode存在那么确实十分简单,但是如果物理机刚刚重启过,内存清空,inode需要重建,这些信息又从何处而来?而且inode的数目十分庞大占据大量的内存空间,当内存不足时,kernel会清除这些繁重的inode(参考shrink_slab函数),那么此时又如何获得磁盘的sector ID和sector size。不必担心文件系统会专门从磁盘中开辟一段空间存储inode信息,xfs中有一条路径是在磁盘mount的时候,将挂载位置的第0号sector保留,专门存储所有文件的inode信息,因此inode也可以理解为磁盘上文件固有属性的mem cache。
如前文所述,如果inode不存在或者被回收,此时sys_write流程便会发生如下变化:
- 申请内存
- 将磁盘的file inode信息读到内存中
- 解析inode,填充bio
- 将磁盘中真正的文件数据读到内存中
- 将需要修改的数据写入内存中
我们可以看到,虽然只有一次sys_write调用,但是至少会有两次读磁盘的操作,第一次读磁盘只为重建inode,第二次读磁盘才是真正的填充文件数据。
读取磁盘inode代码参考:
iomap_file_buffered_write -> iomap_iter -> .iomap_begin -> xfs_buffered_write_iomap_begin -> xfs_iread_extents -> xfs_btree_visit_blocks ->
xfs_btree_readahead_ptr -> xfs_buf_readahead -> xfs_buf_readahead_map -> xfs_buf_read_map -> xfs_buf_read -> xfs_buf_submit ->
__xfs_buf_submit -> xfs_buf_ioapply_map -> submit_bio
7、iomap机制如何打包bio
sys_read场景下,我用流程图的方式给大家展示一下从syscall到bio生成的大概过程。

从sys_read读文件开始:

代码参考:
xfs_file_read_iter -> xfs_file_buffered_read -> generic_file_read_iter -> filemap_read -> filemap_get_pages -> filemap_create_folio -> filemap_alloc_folio -> folio_alloc
filemap_get_pages -> filemap_readahead -> page_cache_async_ra -> ondemand_readahead -> do_page_cache_ra -> page_cache_ra_unbounded -> filemap_alloc_folio/filemap_add_folio

代码参考: xfs_file_read_iter -> xfs_file_buffered_read -> generic_file_read_iter -> filemap_read -> copy_folio_to_iter(offset)

代码参考:filemap_get_pages -> filemap_readahead -> page_cache_async_ra -> ondemand_readahead -> do_page_cache_ra -> page_cache_ra_unbounded -> read_pages -> aops.readahead -> xfs_vm_readahead -> iomap_readahead -> iomap_iter -> ops.iomap_begin(xfs文件系统维护的回调函数)

代码参考:iomap_readahead -> iomap_readahead_iter -> iomap_readpage_iter -> bio_alloc/bio_add_folio
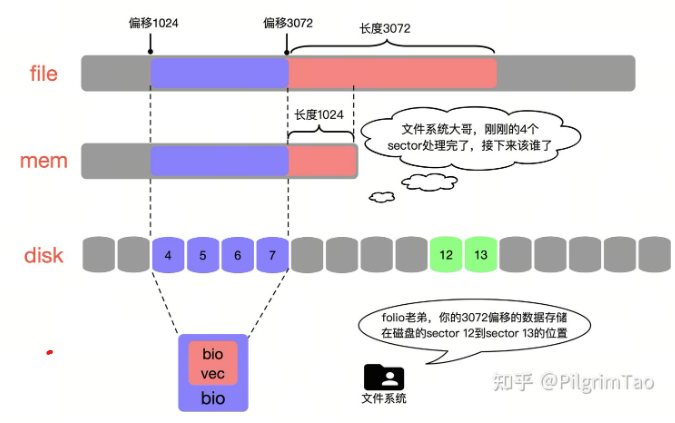
代码参考:iomap_readahead -> iomap_iter -> ops.iomap_begin(xfs文件系统维护的回调函数)

代码参考:iomap_readahead -> iomap_readahead_iter -> iomap_readpage_iter -> bio_alloc/bio_add_folio

代码参考:
sys_read:ondemand_readahead -> do_page_cache_ra -> page_cache_ra_unbounded -> xa_load(在sys_read流程中,因为一开始就会把所有的folio都拿到,不是一个一个拿的)
iomap_readahead_iter -> readahead_folio
sys_write:
xfs_file_write_iter -> xfs_file_buffered_write -> iomap_file_buffered_write -> iomap_write_iter -> iomap_write_begin -> __filemap_get_folio -> mapping_get_entry/filemap_add_folio (在sys_write流程,是用完一个folio,再申请新的folio)

代码参考;iomap_readahead_iter -> iomap_adjust_read_range
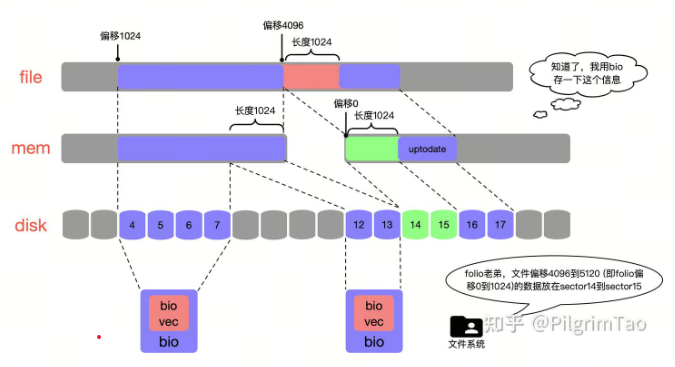
代码参考:iomap_readahead -> iomap_iter -> ops.iomap_begin(xfs文件系统维护的回调函数)
代码参考:
sys_read:iomap_readpage_iter -> bio_add_folio -> __bio_try_merge_page
sys_write:xfs_file_write_iter -> xfs_file_buffered_write -> iomap_file_buffered_write -> iomap_write_iter -> iomap_write_begin -> __iomap_write_begin -> iomap_read_folio_sync -> bio_init/bio_add_folio (一个bio只有一个bio_vec)

最后通过submit_bio或者submit_bio_wait,开始进入下一层级 “request层”。等submit_bio结束,将folio的数据copy到用户buff中,返回用户态,或者是将用户态buff数据写到folio中,最后通过会写进程写回磁盘。
扇区16,17 之所以没有设置到bio , 是因为在mem 中已经存在这部分数据
有些人可能会听说过buffer_head机制,它是历史的产物,还有一些早期的文件系统使用buffer_head机制,并且buffer_head的bio一般只有一个bio_vec,且bio_vec一般以block_size为单位。而iomap比buffer_head更加灵活,并且iomap兼容了buffer_head机制,如果使用iomap时标记为IOMAP_F_BUFFER_HEAD,那么iomap就会走buffer_head的回调函数。当前xfs也已经全面接入了iomap。
代码参考:.write_begin -> minix_write_begin -> block_write_begin -> __ block_write_begin -> __ block_write_begin_int -> ll_rw_block -> submit_bh (minix文件系统举例)
有时bio layer的下一层是最终的磁盘驱动程序,例如 drbd(分布式复制块设备)或 brd(基于 RAM 的块设备)。有时下一层是中间层,例如由 md 和 dm 提供的虚拟设备。最常见的可能是整个block层级结构中的其余部分,我选择将其称为“request layer”。
8、request管理机制
8.1 request简介
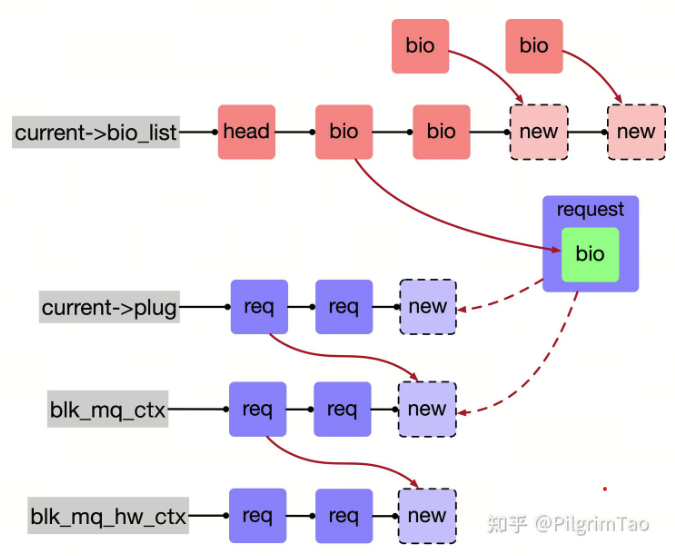
bio打包完成,现在我们需要将它发送给磁盘。一个bio描述了一段连续的磁盘空间,如果两个bio在磁盘物理地址正好是相邻的,组合起来也刚好是一段连续的磁盘空间,对于这种情况实际上也只需要给磁盘发送一次请求就够了,不需要将两个bio分别单独发给磁盘。因此为了将bio重新封装,把相邻的bio进行合并,kernel又提出了新的结构体struct request。struct request和struct bio的关系如图所示。

相邻的bio通过bio.bi_next构成一个链表,挂载到struct request上,由request进行统一管理,request.bio记录链表头,request.biotail记录链表尾。为了使bio找到合适自己request,我们也需要将request串成链表统一管理,有新的bio来到时,只需要遍历链表就可以找到合适自己的request,进行merge。大家可能会有一些疑问,为什么内核不将两个连续的bio合并成一个bio,而仅仅用一个request将两个连续的bio串起来管理呢?因为每个bio都有自己的上下文环境,在很多场景下(参考submit_bio_wait),进程需要等这个bio结束,才能继续进行下一步操作,如果bio被合并没了,那么这个bio是否执行完成也无法通知到自己的上下文。
最后我按照地址是否连续给大家做一个总结
| 磁盘物理地址 | 用户文件地址 | 内存物理地址 | |
|---|---|---|---|
| bio_vec | 地址连续 | 地址连续 | 地址连续 |
| bio | 地址连续 | 地址连续 | 地址不连续 |
| request | 地址连续 | 地址不连续 | 地址不连续 |
注意:bio在设计上其实只要保证磁盘物理地址连续即可,但是由于用户读取文件为顺序读取,所以几乎在所有的使用场景下,bio和bio_vec在用户视角的文件地址上也一定是连续的。
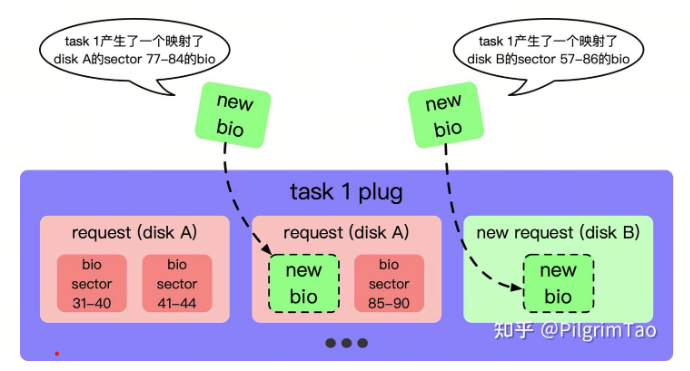
8.2 current->plug链表
为了更好的管理request,内核定义了一个per task的结构体struct blk_plug,我们可以在struct task_struct找到它。同一个进程的request都会暂时挂载到blk_plug.mq_list中, 新的bio到来时,会遍历blk_plug.mq_list如果发现存在合适的request,那么就不必再申请新的request了,只需要在已经存在的request.bio链表上新增成员就可以了,具体是放在链表头还是链表尾取决于磁盘的相对位置(参考函数blk_attempt_bio_merge)。
代码参考:
链表新增节点位置:submit_bio -> submit_bio_noacct -> submit_bio_noacct_nocheck -> __ submit_bio_noacct_mq/ __ submit_bio_noacct -> __ submit_bio -> blk_mq_submit_bio -> blk_add_rq_to_plug
链表遍历位置:__ submit_bio -> blk_mq_submit_bio -> blk_mq_get_cached_request -> blk_mq_attempt_bio_merge -> blk_attempt_plug_merge
值得注意的是在2013年之后的版本中,plug机制已经不能满足硬件需求了,kernel又提供了新的机制来替代它,所以当前版本current->plug并不是必须的,例如sys_read中使用了plug机制,但是sys_write已经不再使用plug机制。具体是否使用取决于代码作者是否在调用submit_bio函数前后调用了blk_start_plug和blk_finish_plug两个函数对blk_plug进行初始化。
这里说一句题外话,当bio生成后必须调用submit_bio函数,将bio再次封装后发送给disk。disk本质上属于一个块设备,使用“md”(例如软件 RAID)和“dm”(例如 LVM2)之类的虚拟块设备很可能会产生一个块设备堆,每个块设备都会修改一个 bio并将其发送到堆栈中的下一个块设备,大量块设备会造成内核调用堆栈溢出。为了避免submit_bio函数嵌套导致的内核堆栈溢出,kernel会将同一进程的bio统一放到current->bio_list暂时存储,submit bio时从bio_list中一个一个取出进行submit。
代码参考:submit_bio -> submit_bio_noacct -> submit_bio_noacct_nocheck -> bio_list_add
current->plug链表是进程结构体中的一个成员变量。
8.3 multi-queue多队列排队机制
2013年之后引入新的patch,新增了io多队列排队机制。之前的plug仅仅在per task维度进行管理,显然对于日益复杂的硬件来说是远远不够的。现在一个物理机常常会接多块磁盘,每个磁盘可能归属不同厂商,硬件配置与软件驱动都不相同。所以kernel在per disk的维度为每个磁盘构建了blk_mq_ctx(软件队列)和blk_mq_hw_ctx(硬件队列)来管理本磁盘所有的request,他们之间的关系如图所示:
request一般不需要往bk_mq_hw_ctx.dispatch放,它仅仅用作内核或设备资源不足时(非错误),由函数blk_mq_request_bypass_insert将request暂时存储到这个链表,下次flush时重试,
前面提到过disk本质上属于一个块设备,如果对kernel设备驱动框架了解的同学可以明白,在scsi adapter driver代码的probe函数中会扫描所有的scsi devices(对于scsi协议的disk而言,disk即是一个scsi device),如果scsi找到了存在的disk设备,那么便会根据具体硬件对disk相关数据结构进行初始化,其中就包括struct blk_mq_ctx和blk_mq_hw_ctx,所以也进一步说明ctx和hctx是per disk的。
ctx申请代码参考:__scsi_scan_target -> scsi_report_lun_scan -> scsi_alloc_sdev -> blk_mq_init_queue -> blk_mq_init_queue_data -> blk_mq_init_allocated_queue -> blk_mq_alloc_ctxs/blk_mq_realloc_hw_ctxs
8.4 blk_mq_ctx软件队列
在重io的服务器场景下,request的数量是庞大的,为了减少全局锁的使用,避免内核同步带来的麻烦,kernel将blk_mq_ctx定义为per cpu变量,每个request仅可以加到本cpu的blk_mq_ctx链表上,这也是kernel惯用的策略。在另一方面,io请求分为读和写,在nvme设备中读和写请求共用一个queue时,写请求会将读请求阻塞,因此kernel总结出三种模式供request进行选择 default模式、只读模式、poll轮询模式(详见HCTX_MAX_TYPES的定义),ctx和hctx都遵循这个标准。
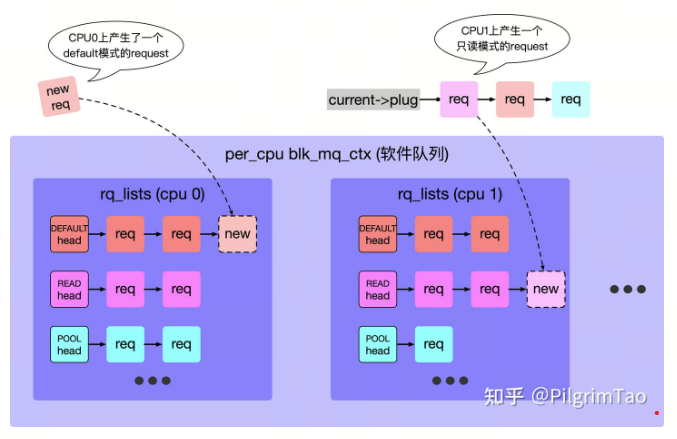
如果不使用plug机制(也就是不加blk_start_plug函数),此时若有一个只读request,它会直接根据自己的request->mq_ctx成员,找到自己所映射的是哪个磁盘的ctx,然后将request加到当前cpu的ctx.rq_lists[HCTX_TYPE_READ]链表中,关于plug链表中所做的bio合并操作在ctx.rq_lists链表中也会重新做一遍。如果使用plug机制,plug链表和ctx.rq_lists链表二者也并不冲突,blk_plug.mq_list最终也会通过blk_finish_plug或者主动调用blk_flush_plug,重新将request加到ctx.rq_lists中。
代码参考:
bio合并:blk_mq_submit_bio -> blk_mq_get_new_requests -> blk_mq_sched_bio_merge -> blk_bio_list_merge -> blk_attempt_bio_merge
request插入ctx:blk_mq_submit_bio -> blk_mq_sched_insert_request -> __ blk_mq_insert_request -> __ blk_mq_insert_req_list -> list_add(&rq->queuelist, &ctx->rq_lists[type])
取出request:blk_mq_run_hw_queue -> __ blk_mq_delay_run_hw_queue -> __ blk_mq_run_hw_queue -> blk_mq_sched_dispatch_requests -> __ blk_mq_sched_dispatch_requests -> blk_mq_do_dispatch_ctx -> blk_mq_dequeue_from_ctx -> dispatch_rq_from_ctx
__blk_mq_sched_dispatch_requests -> blk_mq_flush_busy_ctxs(取出)/blk_mq_dispatch_rq_list(发送给磁盘)
8.5 io调度器
其实ctx软件队列并不是必要的,kernel有很多可选的io调度器(elevator_queue),例如:bpf、kyber、deadline,实现思想和cpu调度器类似。io调度器通过自定义的回调函数ops.insert_requests拿到新的request,使用一系列调度算法将request进行合并与重新排列,通过回调函数ops.dispatch_request输出最合适的request,跳过ctx机制,直接将request发送给磁盘。我认为ctx和elevator_queue两者是互相替代的关系,默认情况下使用ctx机制,在复杂的场景下可选择elevator_queue机制,举个例子,对于机械硬盘而言,磁头需要通过不停的旋转扫描盘片数据,我们总是希望多个request之间尽管不是连续的,但也尽量是一个顺序分布的关系,以减少磁盘旋转的范围,提高访问速度,在这种情况下,不同的io调度器提供的不同调度策略往往能起到更好的效果。 ctx和elevator_queue调度器本质上都是为了更高效的访问磁盘,殊途同归。具体io调度器的实现细节我也没看过,elevator_queue内部是否会用到ctx也不是很清楚.
bpf(Budget Fair Queueing) - 公平性之王:
为系统上的每个进程提供近似平等的磁盘带宽和低延迟,类似于 CPU 调度器中的 CFS(完全公平调度器)。它旨在为交互式应用(如桌面、多媒体播放)提供极致的响应速度。每个进程被分配一个时间片(预算)来发射其 I/O 请求。
Kyber - 延迟目标驱动
种现代的、自适应的调度器,专为快速设备(如 NVMe SSD)设计。它不追求复杂的排序或绝对的公平,而是专注于满足明确的延迟目标。
- 队列分离:将请求分为同步读、同步写 和其他(通常是异步)三个独立的队列。这是因为同步读(例如,应用程序等待数据才能继续)对延迟最敏感.
- 令牌桶(Token Buckets):为每个队列设置延迟目标(例如,同步读的默认目标是 100 微秒)。调度器通过计算“令牌”来限制每个队列的深度,如果某个队列的延迟超过了目标,就会节流该队列的请求发放,直到延迟恢复正常。
Deadline - 防止饥饿
在传统的 CFQ(完全公平队列)和简单的 Noop 调度器之间取得平衡。它的核心目标是防止请求饥饿,确保没有任何 I/O 请求等待“无限长”的时间.
代码参考:
插入:blk_mq_sched_insert_request -> ops.insert_requests
取出:__ blk_mq_sched_dispatch_requests -> blk_mq_do_dispatch_sched -> __ blk_mq_do_dispatch_sched -> ops.dispatch_request
将request发送给disk:__ blk_mq_do_dispatch_sched -> blk_mq_dispatch_rq_list -> .queue_rq
8.6 blk_mq_hw_ctx硬件队列
机械磁盘只有一个磁头在不断的旋转扫描扇区数据,所以它只有一个数据传输通道,但是对于flash而言,可能硬件上支持多个通道同时传输数据,所以磁盘驱动又定义了一种新的per disk per channel的数据结构struct blk_mq_hw_ctx。
首先我对已知的request队列管理模式做了个简单的总结:

关于plug和ctx已经介绍过了,并且ctx和hctx都是per disk的结构体,但是per cpu的ctx如何映射per channel hctx呢?其实没有那么复杂,默认场景下它们仅仅是一一对应的关系,但是驱动也能根据blk_mq_ops->map_queues回调函数自定义映射关系。
这里以默认的HCTX_TYPE_DEFAULT模式举例:

HCTX_TYPE_READ和HCTX_TYPE_POLL(如果有)也是一样的映射关系,并且可以做到硬件通道层面的隔离,kernel也做了一个优化,当cpu数目大于硬件通道数目时,同一物理cpu的不同虚拟cpu所对应的ctx,会映射到同一hctx。
代码参考:blk_mq_alloc_tag_set->blk_mq_update_queue_map->blk_mq_map_queues
内核支持同步和异步两种方式发送request,在hctx中维护了一个delayed_work,用于异步方式往disk发送request,避免进程由于磁盘性能问题阻塞。
blk_mq_sched_insert_request -> blk_mq_run_hw_queue -> __ blk_mq_delay_run_hw_queue ->(异步分支:hctx.run_work -> blk_mq_run_work_fn) -> __ blk_mq_run_hw_queue -> blk_mq_sched_dispatch_requests -> __ blk_mq_sched_dispatch_requests -> blk_mq_dispatch_rq_list -> .queue_rq
request经过合并和排序之后,不断的调用磁盘驱动的回调函数.queue_rq,将request发送给磁盘。磁盘驱动会根据request和hctx记录的硬件信息生成总线对应的通信指令(如果磁盘是scsi设备,则会生成scsi_cmd),存储到struct request结尾(参考函数blk_mq_rq_to_pdu)。仔细阅读代码会发现每次申请struct request结构体时,会申请远大于struct request结构体本身大小的内存,多出来的部分通过磁盘驱动.init_request回调函数填充cmd(参考blk_mq_alloc_rqs),直接用于通信。
代码再深入便是硬件厂商维护的驱动代码了,对于这种五花八门的驱动代码