AI在金融、医疗、教育、制造业等领域的落地案例(含代码、流程图、Prompt示例与图表)
引言
人工智能(AI)正以前所未有的速度渗透到各行各业,推动产业智能化升级。从金融风控到医疗诊断,从个性化教育到智能制造,AI技术不仅提升了效率,还创造了全新的商业模式与服务体验。本文将系统性地分析AI在金融、医疗、教育、制造业四大核心领域的落地应用,结合实际案例、代码实现、流程图(Mermaid格式)、Prompt设计示例、可视化图表与示意图,深入探讨AI如何赋能各行业数字化转型。
一、AI在金融行业的应用
1.1 应用场景概述
金融行业是AI技术最早落地的领域之一,主要应用场景包括:
- 信用评分与风险控制
- 欺诈检测
- 智能投顾与量化交易
- 客户服务(智能客服、聊天机器人)
- 反洗钱(AML)监测
1.2 案例:基于机器学习的信用评分系统
银行和消费金融公司利用AI模型对用户信用进行自动化评估,替代传统人工审核。
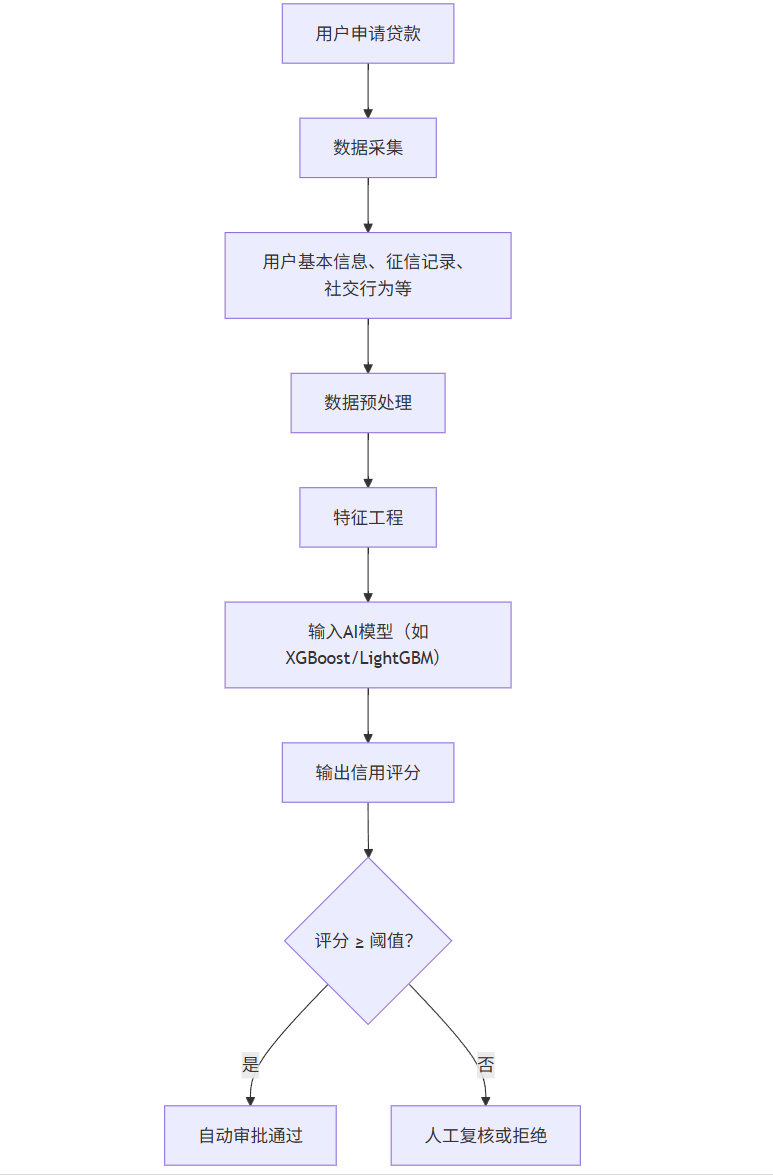
流程图(Mermaid)
graph TD
A[用户申请贷款] --> B[数据采集]
B --> C[用户基本信息、征信记录、社交行为等]
C --> D[数据预处理]
D --> E[特征工程]
E --> F[输入AI模型(如XGBoost/LightGBM)]
F --> G[输出信用评分]
G --> H{评分 ≥ 阈值?}
H -->|是| I[自动审批通过]
H -->|否| J[人工复核或拒绝]
代码示例:使用XGBoost构建信用评分模型(Python)
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from xgboost import XGBClassifier
from sklearn.metrics import accuracy_score, classification_report
# 模拟数据
data = {
'age': np.random.randint(18, 70, 1000),
'income': np.random.randint(20000, 100000, 1000),
'loan_amount': np.random.randint(5000, 50000, 1000),
'credit_history': np.random.choice(['good', 'fair', 'poor'], 1000),
'employment_years': np.random.randint(0, 40, 1000),
'default': np.random.choice([0, 1], 1000, p=[0.8, 0.2]) # 目标变量
}
df = pd.DataFrame(data)
# 数据预处理
le = LabelEncoder()
df['credit_history_encoded'] = le.fit_transform(df['credit_history'])
# 特征选择
features = ['age', 'income', 'loan_amount', 'credit_history_encoded', 'employment_years']
X = df[features]
y = df['default']
# 划分训练测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练XGBoost模型
model = XGBClassifier(use_label_encoder=False, eval_metric='logloss')
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
print("准确率:", accuracy_score(y_test, y_pred))
print(classification_report(y_test, y_pred))
Prompt 示例(用于生成客户信用报告)
Prompt:
“你是一名金融风控分析师。请根据以下客户信息生成一份简要信用评估报告,包括风险等级、建议授信额度和理由。
客户信息:年龄35岁,年收入75000元,贷款申请金额20000元,信用历史良好,已工作12年。”
AI 输出示例:
“该客户信用风险较低。年龄适中,收入稳定,工作年限长,信用记录良好。建议授信额度为25000元,可批准贷款申请。”
图表:信用评分分布直方图(Python代码)
import matplotlib.pyplot as plt
# 假设模型输出概率作为信用评分
scores = model.predict_proba(X_test)[:, 1] # 预测违约概率
plt.hist(scores, bins=20, color='skyblue', edgecolor='black')
plt.title('客户信用评分(违约概率)分布')
plt.xlabel('违约概率')
plt.ylabel('人数')
plt.grid(True)
plt.show()
二、AI在医疗行业的应用
2.1 应用场景概述
AI正在重塑医疗行业,典型应用包括:
- 医学影像识别(如CT、MRI)
- 疾病预测与辅助诊断
- 药物研发
- 个性化治疗方案推荐
- 智能问诊机器人
2.2 案例:基于深度学习的肺癌CT影像检测
利用卷积神经网络(CNN)自动识别肺部CT图像中的结节,辅助医生诊断早期肺癌。
流程图(Mermaid)
graph LR
A[患者进行CT扫描] --> B[图像上传至AI系统]
B --> C[图像预处理:去噪、标准化]
C --> D[CNN模型推理]
D --> E[检测肺结节位置与大小]
E --> F[生成诊断报告]
F --> G[医生复核]
G --> H[确诊或进一步检查]

代码示例:使用PyTorch构建简单CNN模型(模拟)
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import transforms
from torch.utils.data import DataLoader, Dataset
import numpy as np
# 模拟CT图像数据集
class LungDataset(Dataset):
def __init__(self, num_samples=1000):
self.images = np.random.rand(num_samples, 1, 64, 64).astype(np.float32) # 灰度图
self.labels = np.random.randint(0, 2, num_samples) # 0: 正常, 1: 有结节
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
return torch.tensor(self.images[idx]), torch.tensor(self.labels[idx])
# CNN模型
class LungCNN(nn.Module):
def __init__(self):
super(LungCNN, self).__init__()
self.conv1 = nn.Conv2d(1, 16, kernel_size=3, padding=1)
self.pool = nn.MaxPool2d(2)
self.conv2 = nn.Conv2d(16, 32, kernel_size=3, padding=1)
self.fc1 = nn.Linear(32 * 16 * 16, 128)
self.fc2 = nn.Linear(128, 2)
self.relu = nn.ReLU()
def forward(self, x):
x = self.pool(self.relu(self.conv1(x)))
x = self.pool(self.relu(self.conv2(x)))
x = x.view(x.size(0), -1)
x = self.relu(self.fc1(x))
x = self.fc2(x)
return x
# 训练过程
dataset = LungDataset()
loader = DataLoader(dataset, batch_size=32, shuffle=True)
model = LungCNN()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
for epoch in range(5):
for images, labels in loader:
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
print(f"Epoch {epoch+1}, Loss: {loss.item():.4f}")
Prompt 示例(用于生成诊断建议)
Prompt:
“你是一名AI辅助诊断系统。请根据以下CT影像分析结果,向主治医生提供诊断建议。
检测结果:在右肺上叶发现一个直径约8mm的实性结节,边界清晰,无钙化。”
AI 输出示例:
“检测到右肺上叶实性结节,大小8mm,边界清晰,提示良性可能性较高,但仍需警惕早期肺癌。建议3个月后复查CT,观察结节变化。若增大或形态改变,建议进行PET-CT或活检。”
图表:AI vs 医生诊断准确率对比(柱状图)
import matplotlib.pyplot as plt
models = ['传统医生', 'AI模型', '医生+AI']
accuracy = [0.82, 0.89, 0.95]
plt.bar(models, accuracy, color=['red', 'blue', 'green'])
plt.title('肺癌CT诊断准确率对比')
plt.ylabel('准确率')
plt.ylim(0.7, 1.0)
for i, v in enumerate(accuracy):
plt.text(i, v + 0.01, f"{v:.2f}", ha='center')
plt.show()
三、AI在教育行业的应用
3.1 应用场景概述
AI正在推动教育个性化与智能化,主要应用包括:
- 智能辅导系统(ITS)
- 自适应学习平台
- 作业自动批改
- 学生行为分析与预警
- 虚拟教师与AI助教
3.2 案例:基于NLP的作文自动评分系统
利用自然语言处理技术对学生的中文作文进行评分,提升批改效率。
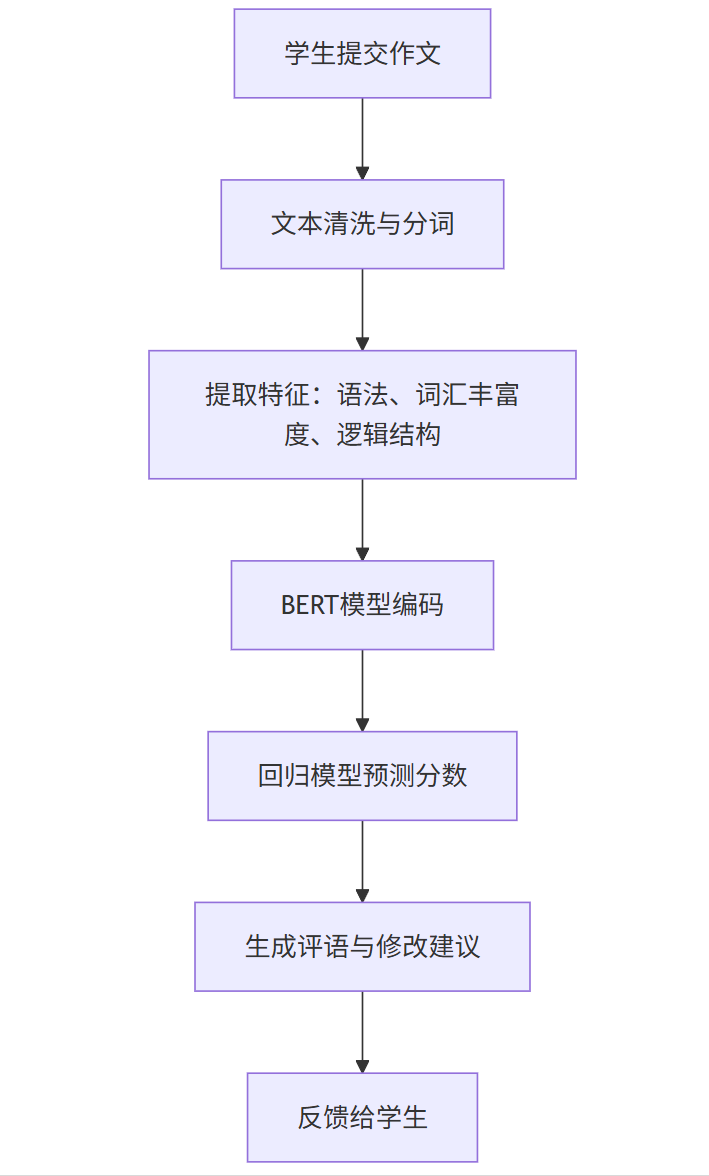
流程图(Mermaid)
graph TB
A[学生提交作文] --> B[文本清洗与分词]
B --> C[提取特征:语法、词汇丰富度、逻辑结构]
C --> D[BERT模型编码]
D --> E[回归模型预测分数]
E --> F[生成评语与修改建议]
F --> G[反馈给学生]
代码示例:使用Hugging Face Transformers进行文本评分预测(模拟)
from transformers import BertTokenizer, BertModel
import torch
import numpy as np
from sklearn.linear_model import LinearRegression
# 加载预训练中文BERT模型
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
model = BertModel.from_pretrained('bert-base-chinese')
# 模拟学生作文
essays = [
"我的家乡是一个美丽的小山村,春天有花,秋天有果。",
"人工智能正在改变世界,它可以帮助医生诊断疾病。"
]
true_scores = [85, 92] # 真实评分
# 编码文本
embeddings = []
for essay in essays:
inputs = tokenizer(essay, return_tensors='pt', truncation=True, padding=True, max_length=128)
with torch.no_grad():
outputs = model(**inputs)
# 取[CLS] token的向量作为句子表示
cls_embedding = outputs.last_hidden_state[:, 0, :].numpy().flatten()
embeddings.append(cls_embedding)
# 训练简单线性回归模型(实际中可用更复杂模型)
regressor = LinearRegression()
regressor.fit(embeddings, true_scores)
# 预测新作文
new_essay = "科技让生活更美好,我们应该努力学习。"
inputs = tokenizer(new_essay, return_tensors='pt', truncation=True, padding=True, max_length=128)
with torch.no_grad():
outputs = model(**inputs)
new_embedding = outputs.last_hidden_state[:, 0, :].numpy().flatten().reshape(1, -1)
predicted_score = regressor.predict(new_embedding)
print(f"预测作文分数: {predicted_score[0]:.1f}")
Prompt 示例(用于生成个性化评语)
Prompt:
“你是一名AI语文老师。请根据以下学生作文内容和评分,生成一段鼓励性评语,并提出1-2条改进建议。
作文:'我的梦想是当一名医生,帮助病人。'
评分:78分(满分100)”
AI 输出示例:
“你的作文表达了真挚的情感,主题明确。语言简洁但略显单薄。建议:1. 增加具体事例,如‘我想像钟南山爷爷一样在疫情中救人’;2. 使用比喻或排比句增强表现力。继续加油!”
图表:学生学习路径个性化推荐(流程图)

四、AI在制造业的应用
4.1 应用场景概述
AI在制造业的应用聚焦于“智能制造”,主要包括:
- 预测性维护
- 质量检测(视觉检测)
- 生产排程优化
- 供应链智能管理
- 数字孪生与仿真
4.2 案例:基于AI的工业缺陷检测系统
使用计算机视觉技术自动识别生产线上的产品表面缺陷(如划痕、裂纹)。
流程图(Mermaid)
graph LR
A[产品进入检测区] --> B[工业相机拍照]
B --> C[图像预处理:灰度化、去噪]
C --> D[YOLOv5模型检测缺陷]
D --> E[标注缺陷位置与类型]
E --> F{缺陷面积 > 阈值?}
F -->|是| G[标记为不合格品]
F -->|否| H[标记为合格品]
G --> I[自动剔除]
H --> J[进入包装环节]

代码示例:使用OpenCV + YOLO进行缺陷检测(简化版)
import cv2
import numpy as np
# 加载YOLO模型(需预先训练)
net = cv2.dnn.readNet("yolov5s.weights", "yolov5s.cfg")
layer_names = net.getLayerNames()
output_layers = [layer_names[i[0] - 1] for i in net.getUnconnectedOutLayers()]
# 读取图像
img = cv2.imread("product.jpg")
height, width, channels = img.shape
# 检测
blob = cv2.dnn.blobFromImage(img, 0.00392, (416, 416), (0, 0, 0), True, crop=False)
net.setInput(blob)
outs = net.forward(output_layers)
# 解析检测结果
for out in outs:
for detection in out:
scores = detection[5:]
class_id = np.argmax(scores)
confidence = scores[class_id]
if confidence > 0.5 and class_id == 0: # 假设0为缺陷类
center_x = int(detection[0] * width)
center_y = int(detection[1] * height)
w = int(detection[2] * width)
h = int(detection[3] * height)
x = int(center_x - w / 2)
y = int(center_y - h / 2)
cv2.rectangle(img, (x, y), (x + w, y + h), (0, 0, 255), 2)
cv2.imshow("Defect Detection", img)
cv2.waitKey(0)
cv2.destroyAllWindows()
Prompt 示例(用于生成设备维护建议)
Prompt:
“你是一名AI工厂运维助手。请根据以下传感器数据,判断设备是否需要维护,并给出建议。
数据:电机振动值连续3天上升,当前为8.7 mm/s(正常范围<5 mm/s),温度正常。”
AI 输出示例:
“电机振动值持续超标,存在轴承磨损或不平衡风险。建议:1. 立即安排停机检查;2. 进行动平衡校正;3. 更换润滑油脂。避免突发故障导致停产。”
图表:预测性维护 vs 传统维护成本对比
import matplotlib.pyplot as plt
years = ['Year 1', 'Year 2', 'Year 3']
predictive_maintenance = [120, 130, 140] # 万元
reactive_maintenance = [200, 250, 300]
plt.plot(years, predictive_maintenance, marker='o', label='预测性维护')
plt.plot(years, reactive_maintenance, marker='s', label='事后维护')
plt.title('维护成本对比(单位:万元)')
plt.ylabel('年维护成本')
plt.legend()
plt.grid(True)
plt.show()
五、跨行业AI通用能力与Prompt工程
5.1 AI通用能力框架
自然语言理解 | NLP、BERT、GPT | 客服、教育、医疗报告 |
计算机视觉 | CNN、YOLO、ResNet | 质检、影像诊断 |
预测分析 | 回归、时间序列、XGBoost | 金融风控、设备维护 |
推荐系统 | 协同过滤、深度学习 | 教育路径、金融产品推荐 |
自动化决策 | 强化学习、规则引擎 | 生产调度、投资组合管理 |
5.2 Prompt设计原则(适用于各行业)
- 角色设定:明确AI角色(如“资深医生”、“风控专家”)
- 上下文清晰:提供足够背景信息
- 输出格式要求:指定结构化输出(JSON、列表等)
- 限制与约束:避免幻觉,要求基于事实
多行业Prompt模板
【金融】
"你是一名银行风控官。请根据客户{信息},判断贷款风险等级(高/中/低),并说明理由。"
【医疗】
"你是一名放射科AI助手。请分析CT报告:{描述},给出可能的诊断及建议。"
【教育】
"你是一名中学数学老师。请为学生解答:{题目},要求分步骤讲解。"
【制造】
"你是一名生产主管。请根据当前订单{数据},优化未来3天的排产计划。"
六、挑战与未来展望
6.1 当前挑战
- 数据隐私与安全(尤其在医疗、金融)
- 模型可解释性不足
- 行业数据孤岛问题
- AI伦理与偏见
6.2 未来趋势
- 多模态AI融合(文本+图像+语音)
- 边缘AI部署(实时性要求高的场景)
- AI Agent自主决策系统
- 大模型+行业小模型协同
结语
AI已在金融、医疗、教育、制造等领域实现深度落地,通过数据驱动、模型赋能、流程重构,显著提升了效率与服务质量。未来,随着大模型、边缘计算与物联网技术的融合,AI将进一步从“辅助工具”演变为“智能中枢”,推动各行业进入真正的智能化时代。