Lecture 5 GPUs课程笔记
目标
让CUDA和GPU不再那么神秘
了解GPU何时变慢
理解如何创建快速算法
第一部分:深入了解GPU——其工作原理及重要组件
第二部分:理解GPU性能
第三部分:整合——解析FlashAttention
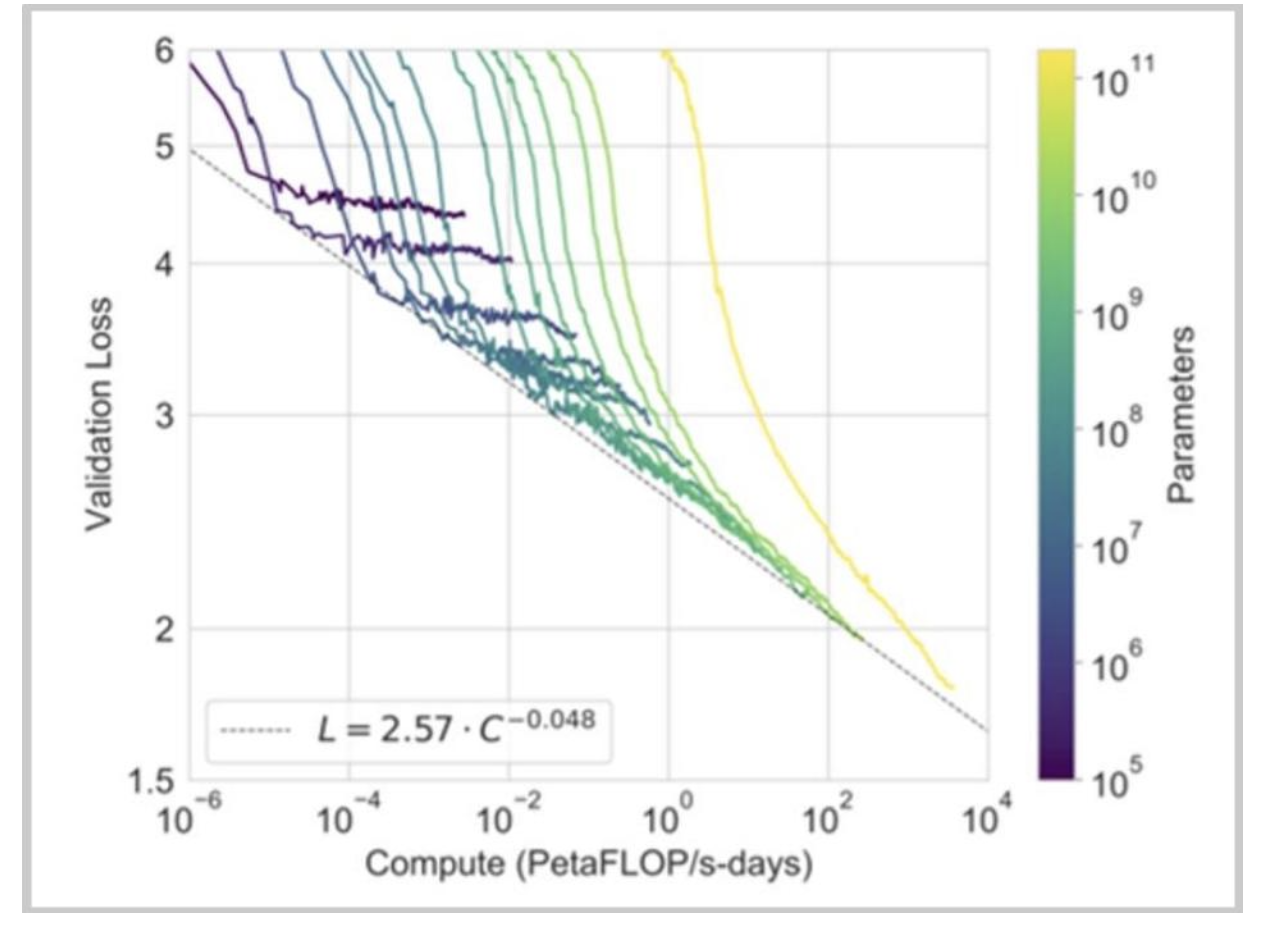
铺垫:算力带来可预测的性能提升
通常情况下,计算量的增加能为语言模型带来可预测的性能提升。
更快的硬件、更好的利用率、单独改进的并行化(目前……)就能推动进展。
我们如何实现计算能力的扩展?早期——依靠丹纳德缩放定律
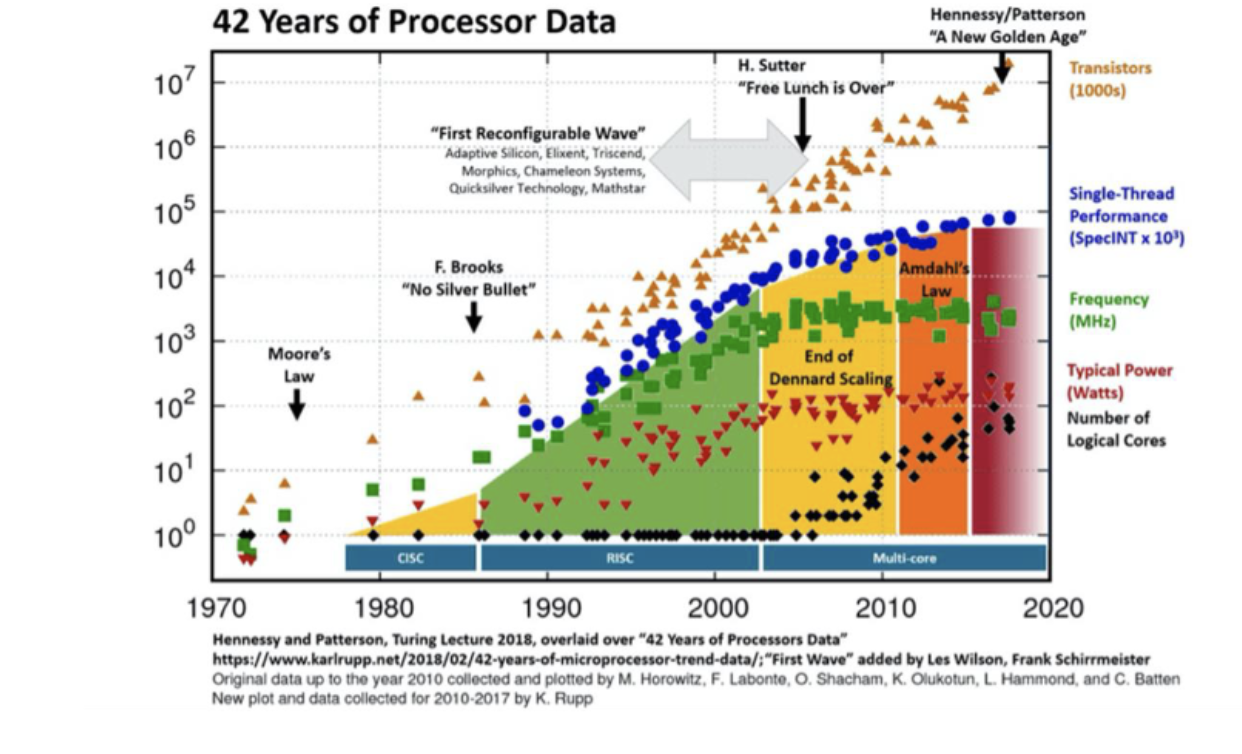
但20世纪80年代至21世纪初的传统缩放形式(登纳德缩放)已达极限。……我们如何满足大语言模型对计算永无止境的需求呢?
并行扩展仍在继续
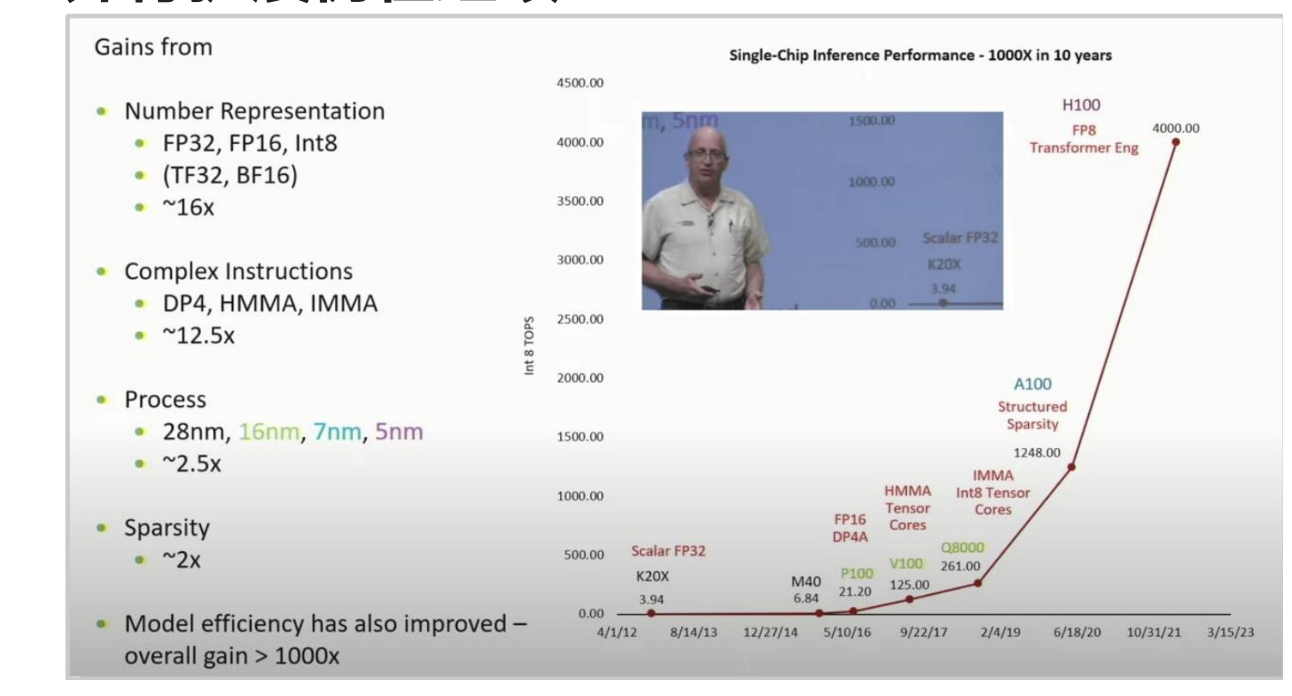
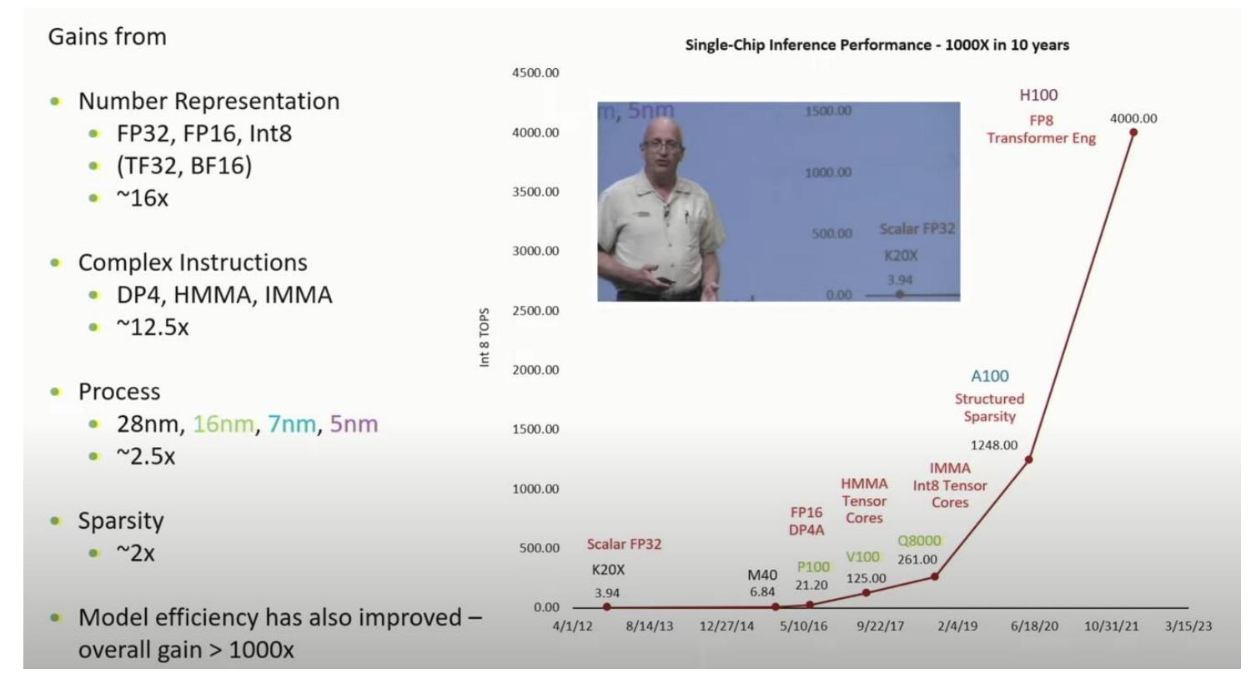
使用GPU进行并行扩展,在10年内实现了超过1000倍的扩展。
没有GPU的扩展,就没有大语言模型的扩展
GPU与CPU有何不同?
CPU针对少量快速线程进行优化,而GPU针对大量线程进行优化。
CPU着重于对延迟进行优化(每个线程都快速完成)
GPU着重于对吞吐量(总数据处理量)进行优化
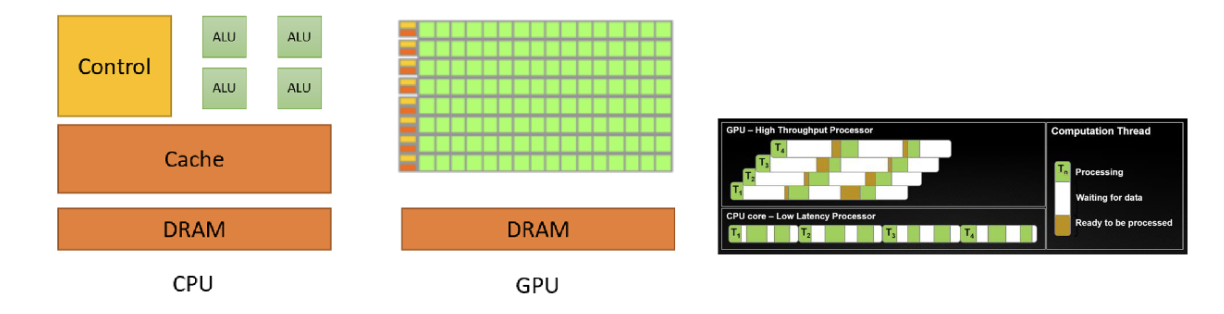
GPU剖析(执行单元)
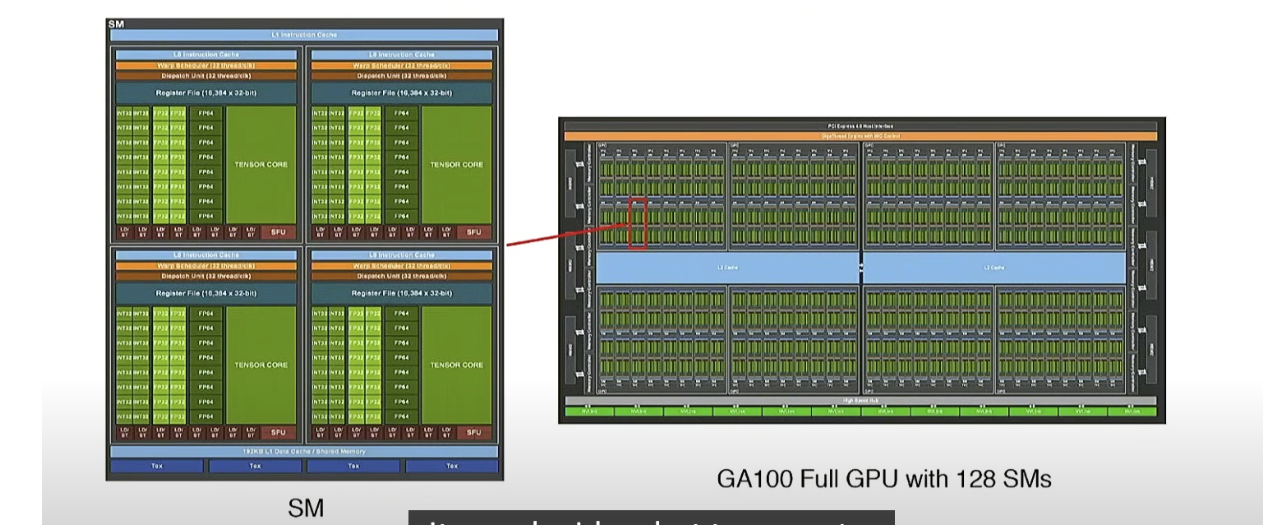
GPU有许多流式多处理器(SM),可以独立执行“块”(任务)
每个SM还有许多流式处理器(SP),这些流式处理器可以并行执行“线程”
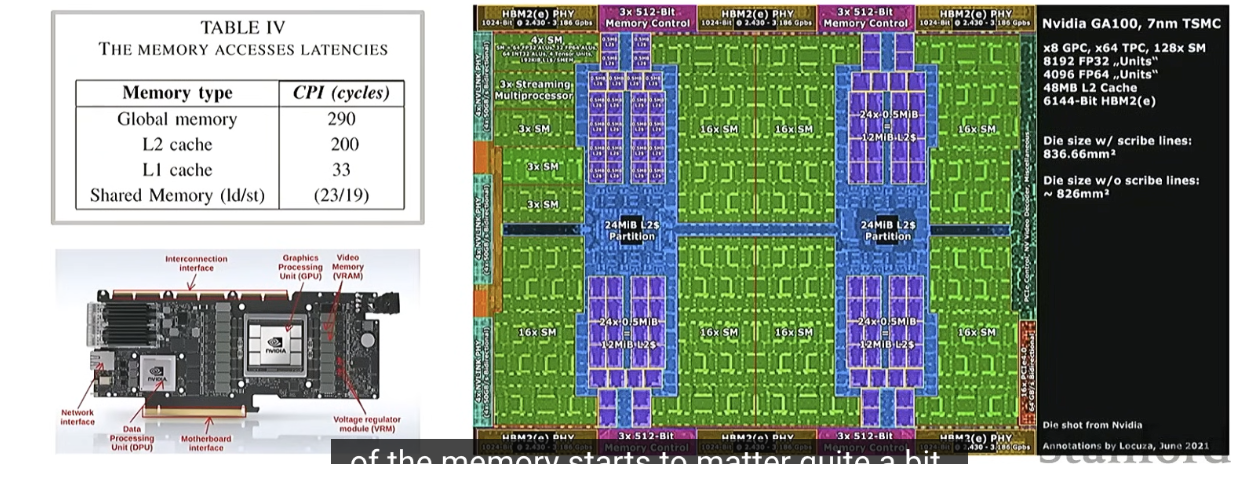
GPU(内存)剖析
内存离流式多处理器(Streaming Multiprocessor,SM)越近,速度就越快——一级缓存(L1)和共享内存位于SM内部。二级缓存(L2)在芯片上,而全局内存则是GPU旁边的存储芯片。
GPU的执行模型
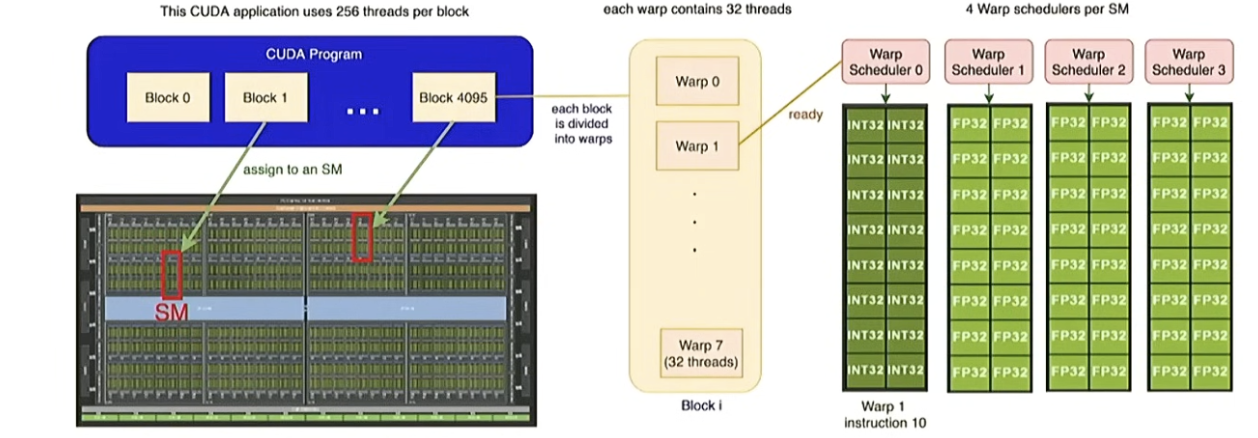
在执行模型中有3个重要参与者
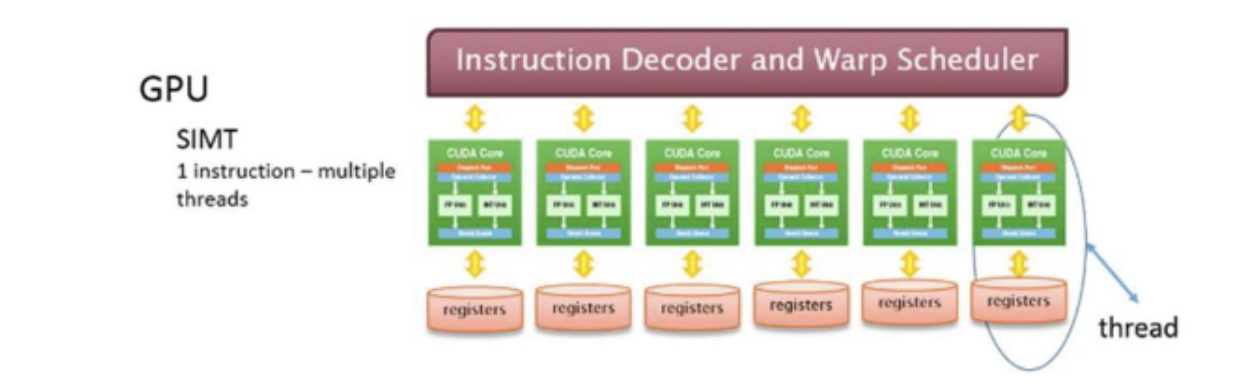
线程:线程以并行方式“执行任务”——所有线程执行相同的指令,但输入不同(单指令多线程,SIMT)。
线程块:线程块是线程组。每个线程块在具有自己共享内存的流多处理器(SM)上运行。
线程束:线程始终以每组32个连续编号的线程组成的“线程束”形式执行。
线程块由多个线程束组成,每个线程束是由32个连续编号的线程组成
GPU的内存模型
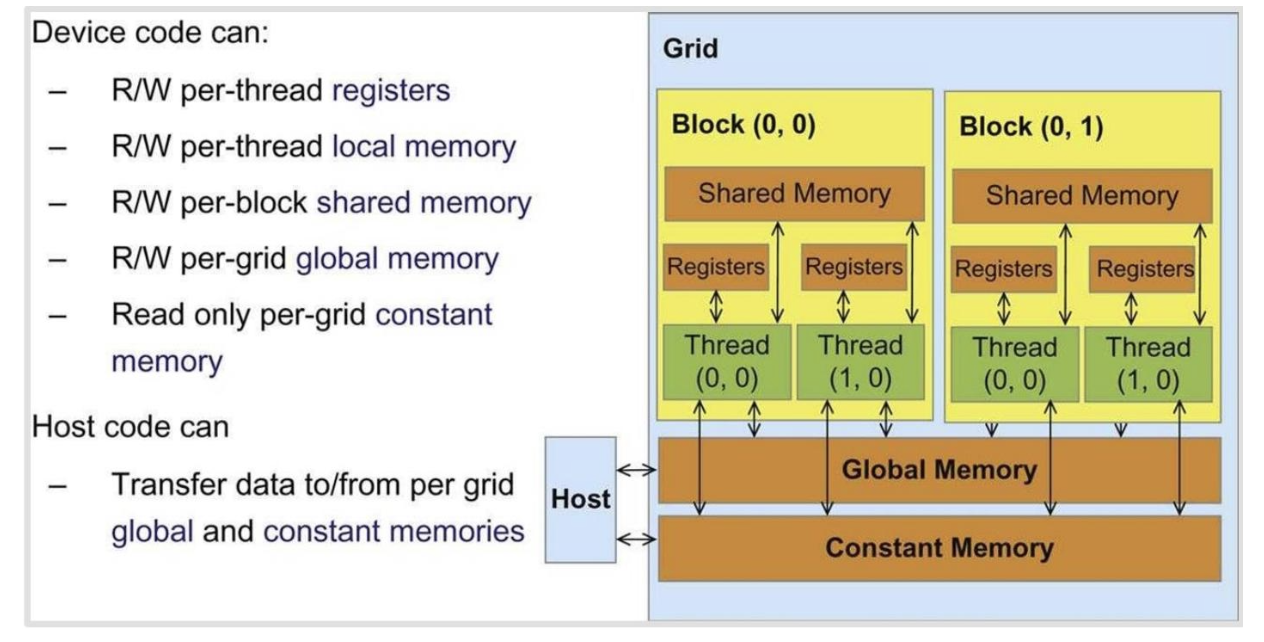
每个线程都可以访问其自身的寄存器以及所在线程块内的共享内存。
跨块的信息需要读/写入全局内存(速度较慢)
题外话——张量处理单元(TPU)情况如何?
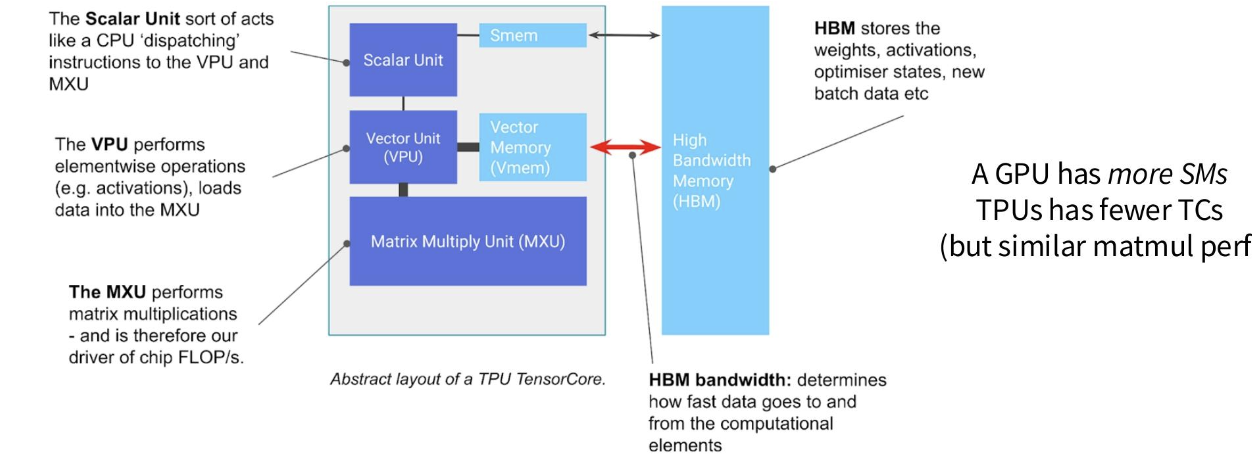
从高层次来看,图形处理器(GPU)、张量处理器(TPU)以及许多其他加速器是相似的
核心结构——轻量级控制、快速(大型)矩阵乘法单元、快速内存。
差异 - 加速器如何联网(在并行性讲座中)
- 无线程束(只有线程块——矩阵乘法与非矩阵乘法之间的权衡)
GPU模型的优势
轻松扩展繁重的工作负载(通过添加更多流式多处理器)
由于单指令多线程(SIMT)模型,编程较为容易(?)
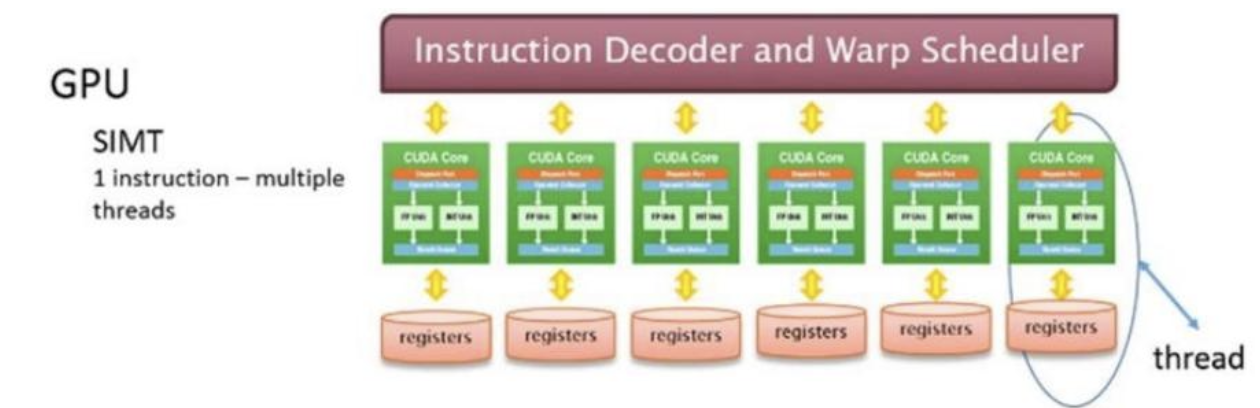
线程是“轻量级的”,可以随时停止和启动
这使得GPU能够在每个SM内获得高利用率
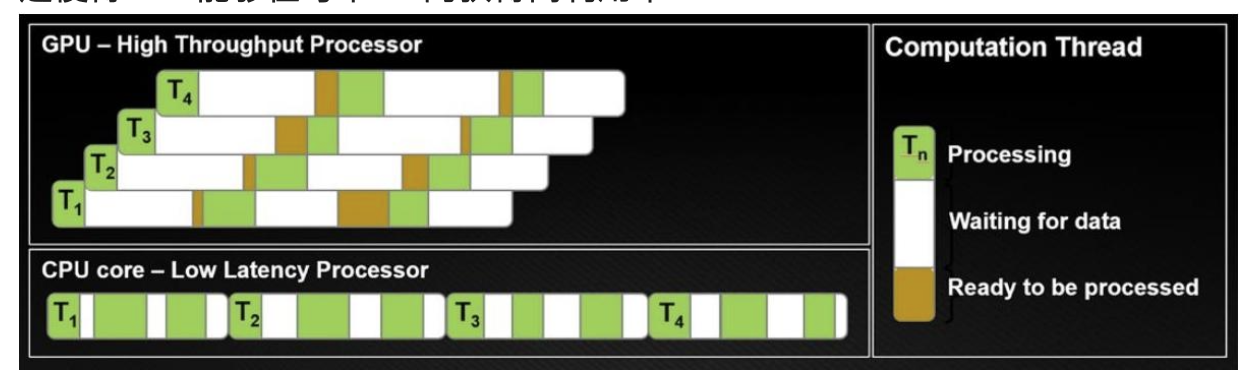
GPU作为快速矩阵乘法器
英伟达GPU的早期阶段——可编程着色器。研究人员通过破解这一技术来进行矩阵乘法运算。
新的矩阵乘法硬件意味着矩阵乘法运算速度快且具有特殊性
张量核心(在V、T系列中引入)是专门的矩阵乘法电路。矩阵乘法比其他浮点运算更快(10x)
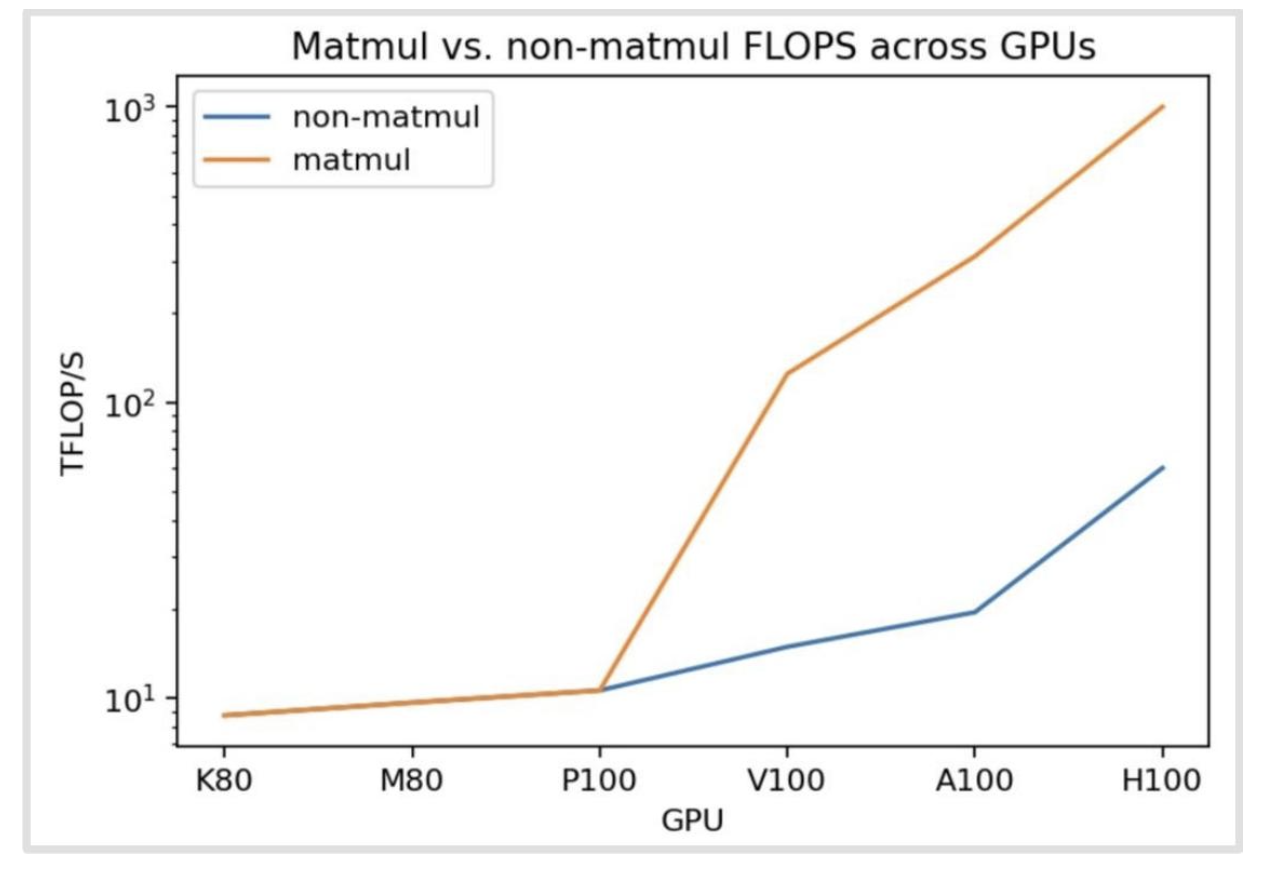
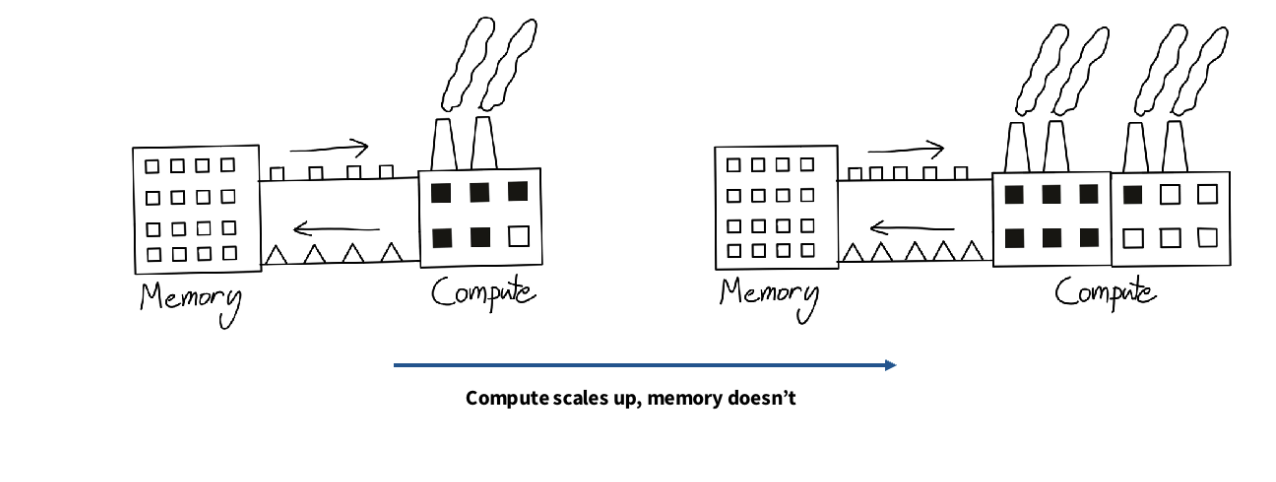
计算扩展比内存扩展更快
每秒浮点运算次数(FLOPs)的增长速度比内存快——很难保证我们的计算单元有足够的数据供应!
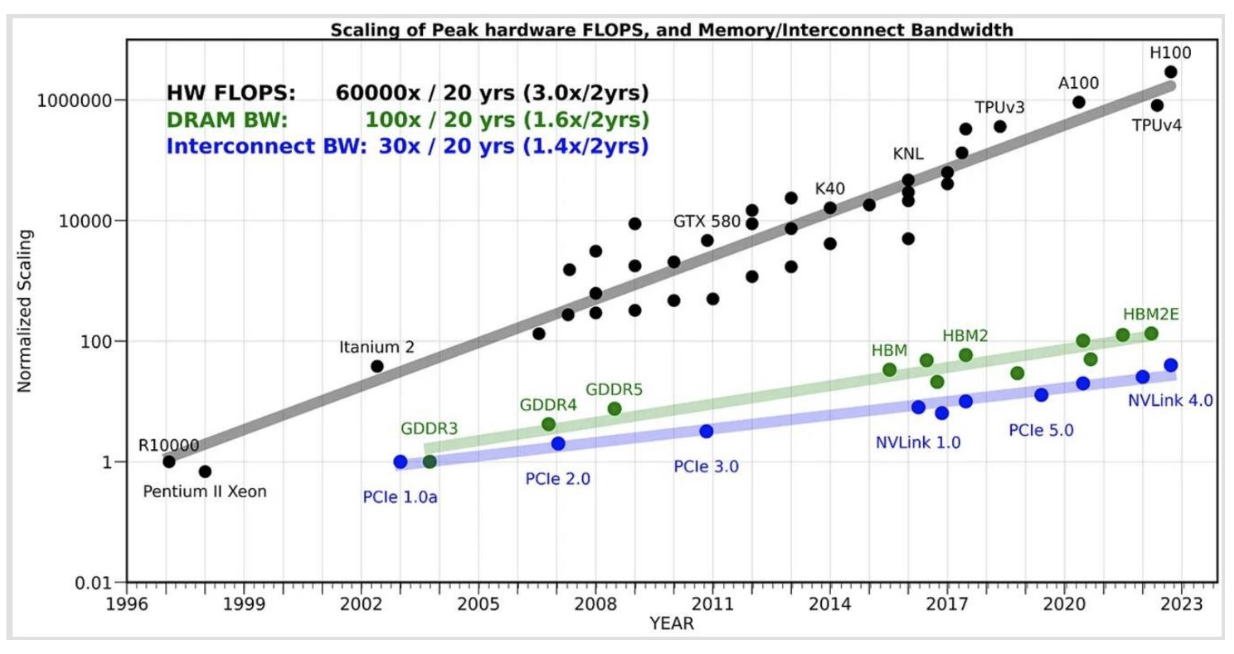
回顾:GPU——它们是什么以及如何工作
GPU具有大规模并行性——同一指令可在多个运算单元上执行
计算(尤其是矩阵乘法)的扩展速度比内存更快
我们必须关注 内存层次结构,以提高运行速度。
第2部分:在GPU上加速机器学习工作负载
在GPU上的性能可能很复杂,即使是像方阵矩阵乘法这样简单的操作。
是什么让机器学习工作负载运行速度加快?
The roofline model
在左边受到内存影响,在右边充分利用,收到吞吐量影响
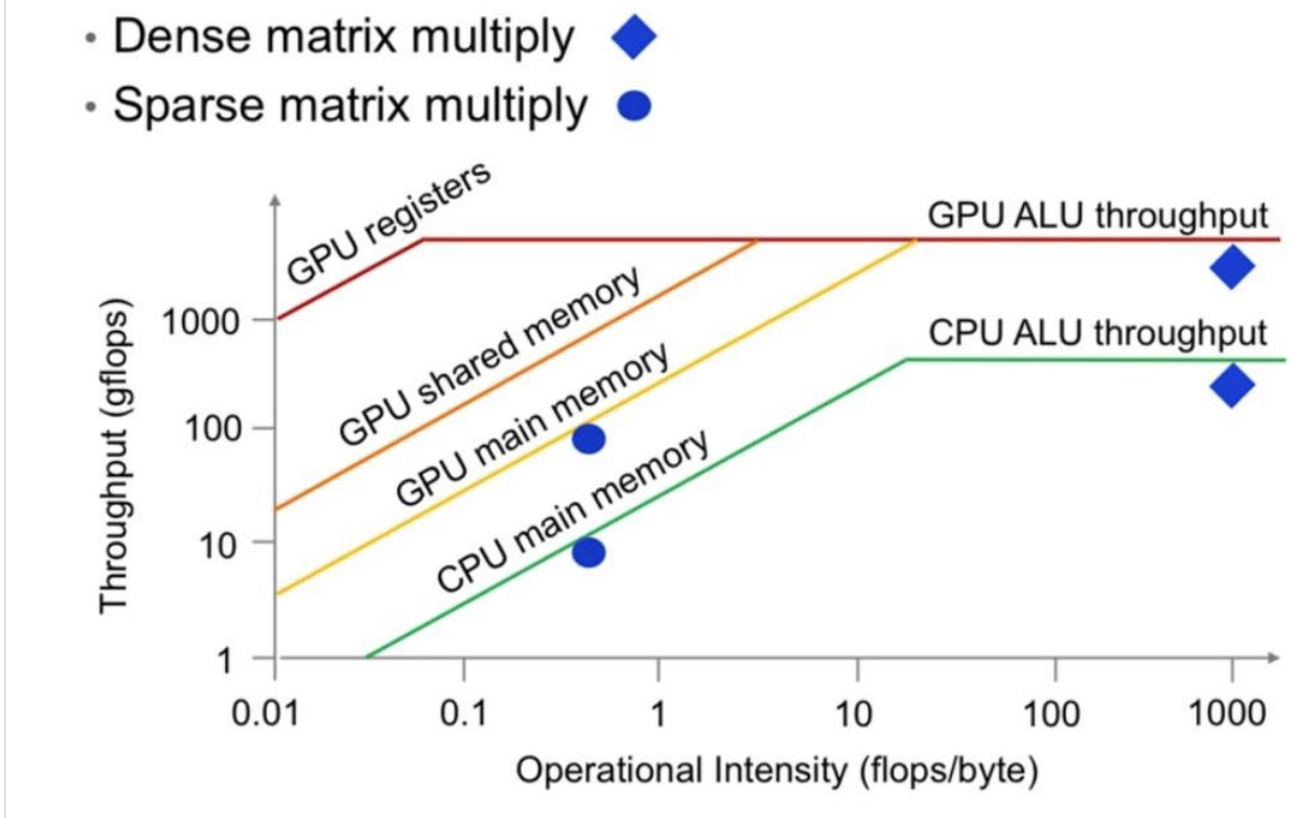
本节关键:我们如何避免受限于内存?
我们如何让GPU运行得更快?
- 控制分歧(并非内存瓶颈…)
- 低精度计算
- 算子融合
- 重计算
- 合并内存
- 平铺
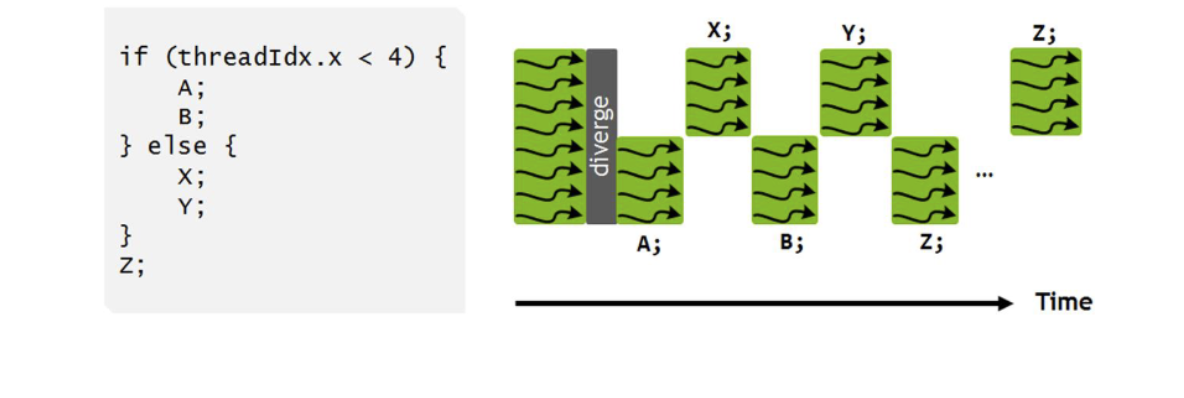
控制分歧(非内存问题)
GPU以单指令多线程(SIMT)模型运行——一个线程束中的每个线程都执行相同的指令(不同数据)
条件语句本身没问题,但会在执行模型中导致显著的额外开销
技巧1:低精度计算
如果你的比特数较少,那么需要移动的比特数也较少。
即使从全局内存中读取,所花的时间也少得多
低精度提高了算术强度
示例:对大小为n的向量进行逐元素ReLU(((x=max (0, x))))运算。
(单精度浮点32位情况)
内存访问:1次读取 (x),1次写入 ((if x<0 )) ,浮点型 (32=8) 字节
运算:1次比较运算,1次浮点运算。
强度:8字节/次浮点运算
(16位浮点数)
内存访问:1次读取(x),1次写入((if x<0 )) ,读取(16=4)字节
运算:1次比较运算,1次浮点运算。
强度:4字节/次浮点运算
低精度可加快矩阵乘法运算
现代GPU中的许多操作都是通过低精度/混合精度操作来加速的
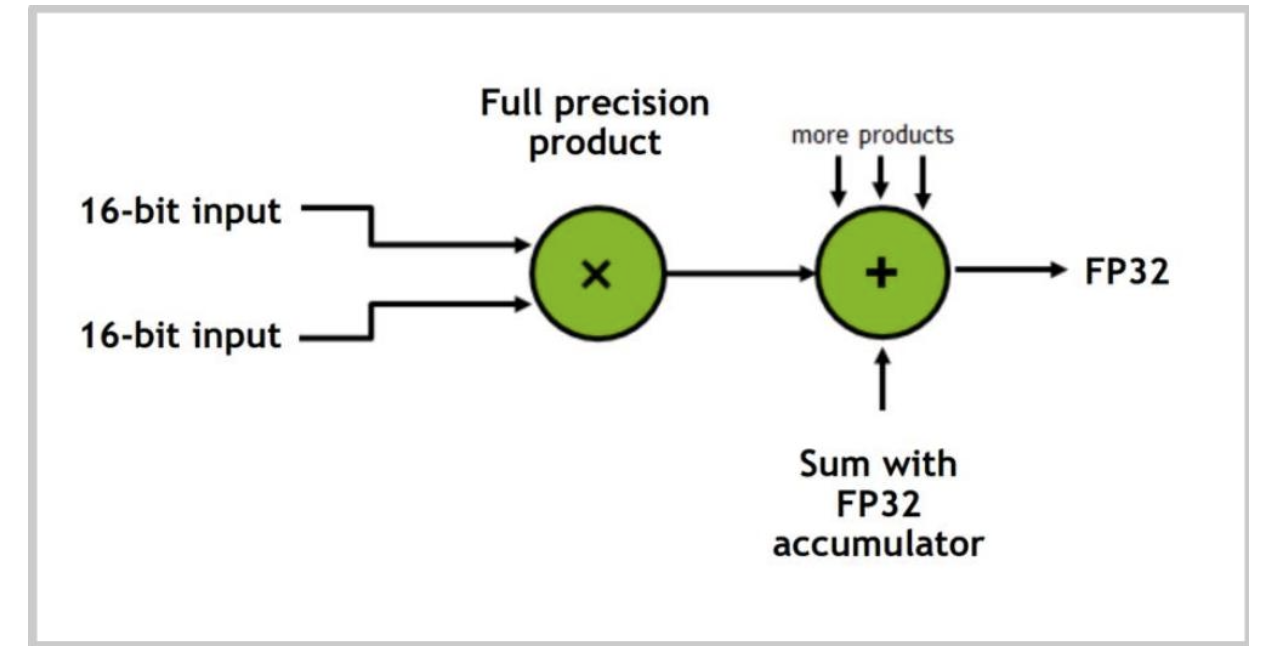
张量核心
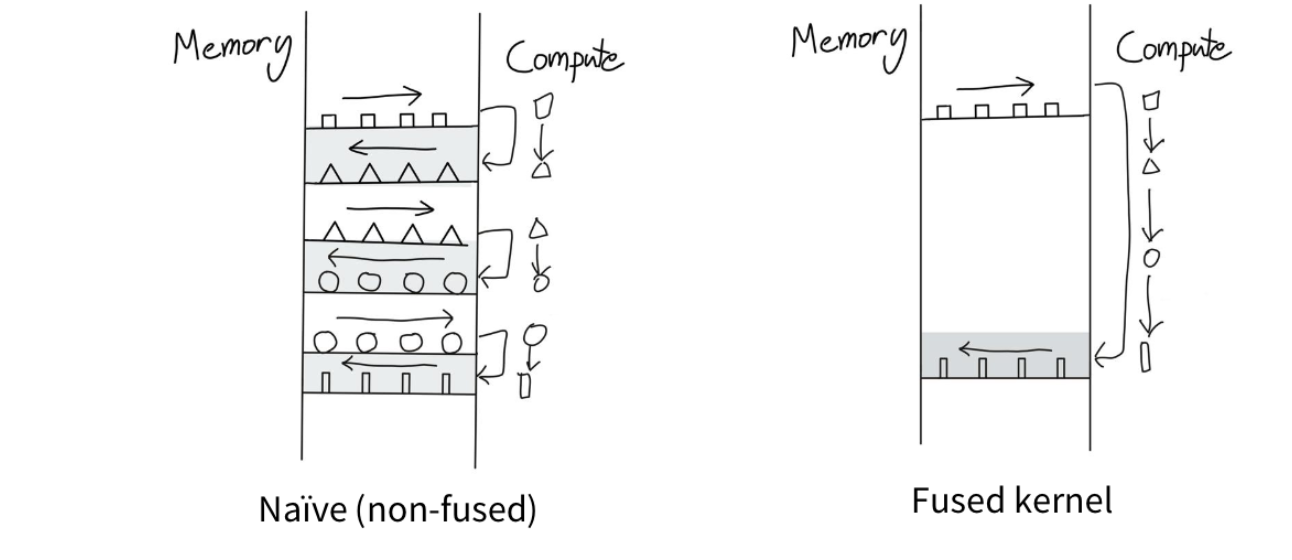
技巧2:算子融合
可以把GPU想象成一座工厂——输入数据来自仓库(内存),并在工厂中进行处理。
算子融合以最小化内存访问
如果我们必须进行许多操作怎么办?来回传输数据有点愚蠢
尽可能在一个地方完成所有计算,然后只当必须送回内存时才送回
示例 - 正弦和余弦
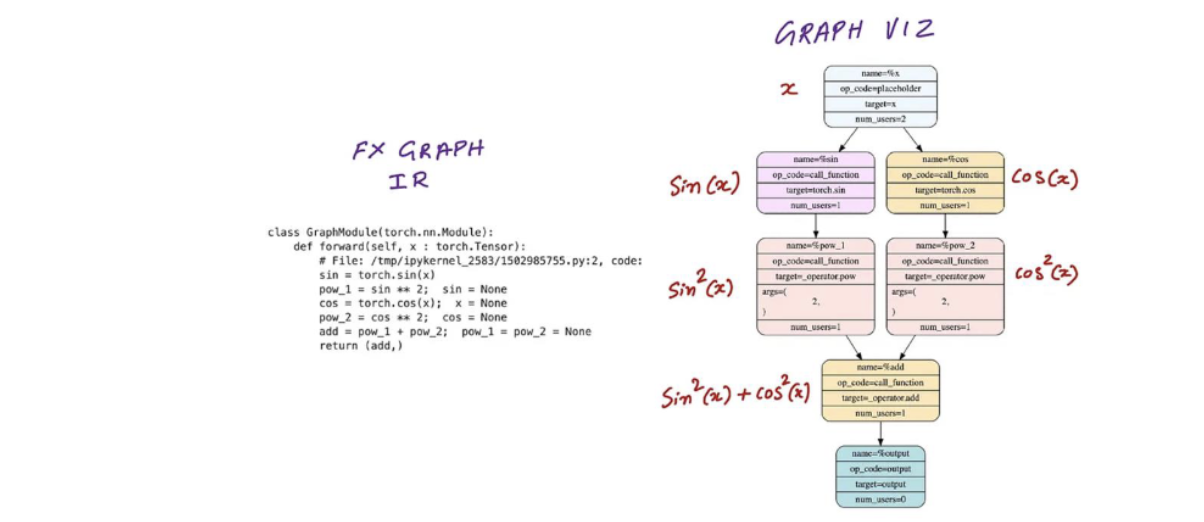
直接计算(sin2x+cos2xsin ^{2} x+cos ^{2} xsin2x+cos2x)会盲目地启动5个CUDA内核(来回切换)
融合示例
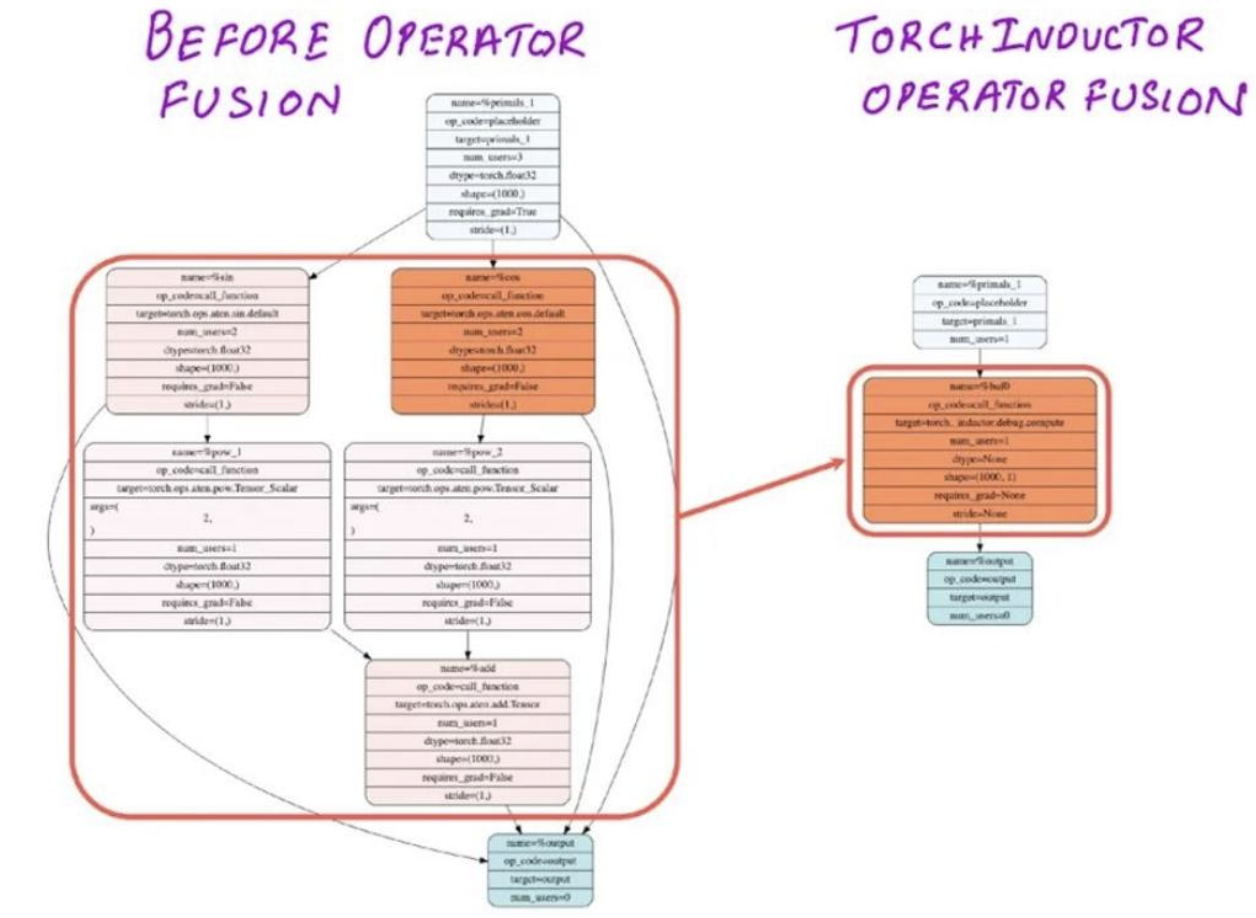
所有5种逐点运算都可以融合为一次CUDA内核调用。像这样的 “简单” 融合可以由编译器(torch.compile)自动完成。
技巧3:重新计算
使用更多的计算来避免进行内存访问
在反向传播中,我们存储激活值(黄色)并计算雅可比矩阵(绿色)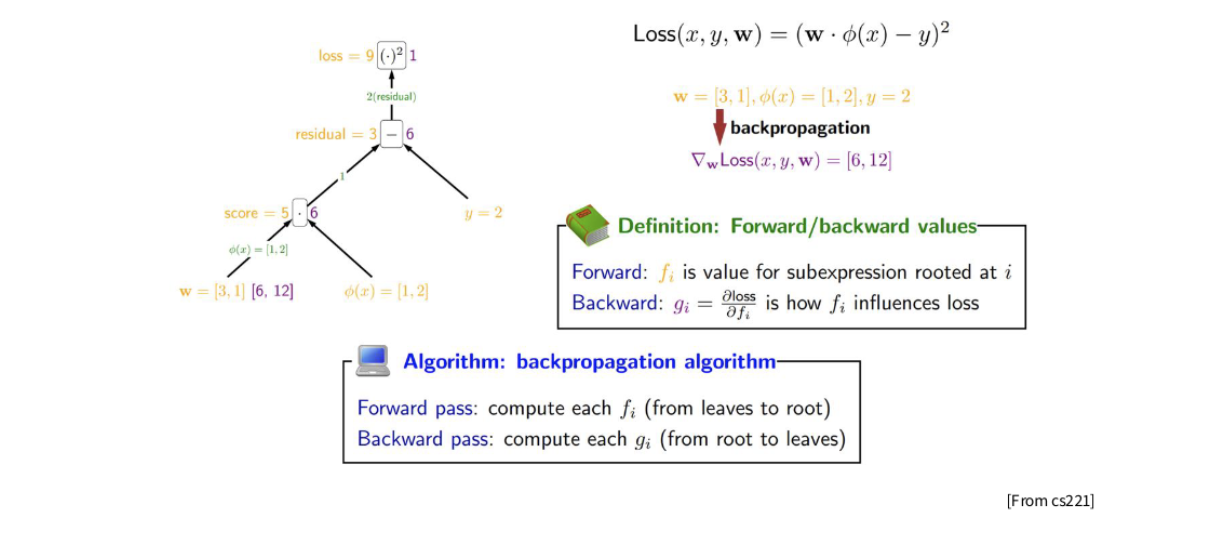
存储(和检索)激活值可能代价高昂!
假设我们将3个sigmoid函数堆叠在一起。
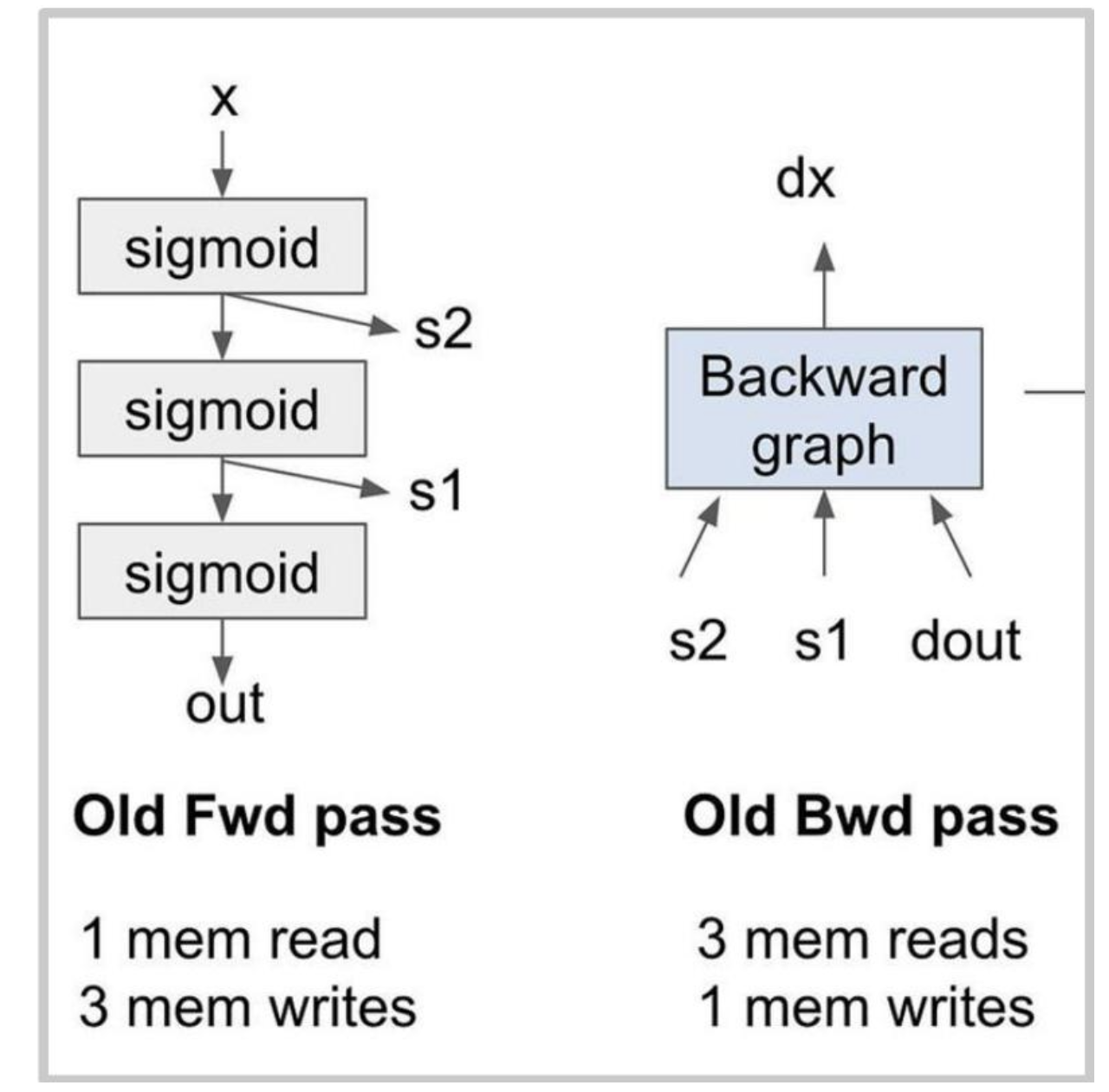
这对性能来说真的很糟糕——8次内存读/写,算术强度非常低。
丢弃激活值,重新计算它们!
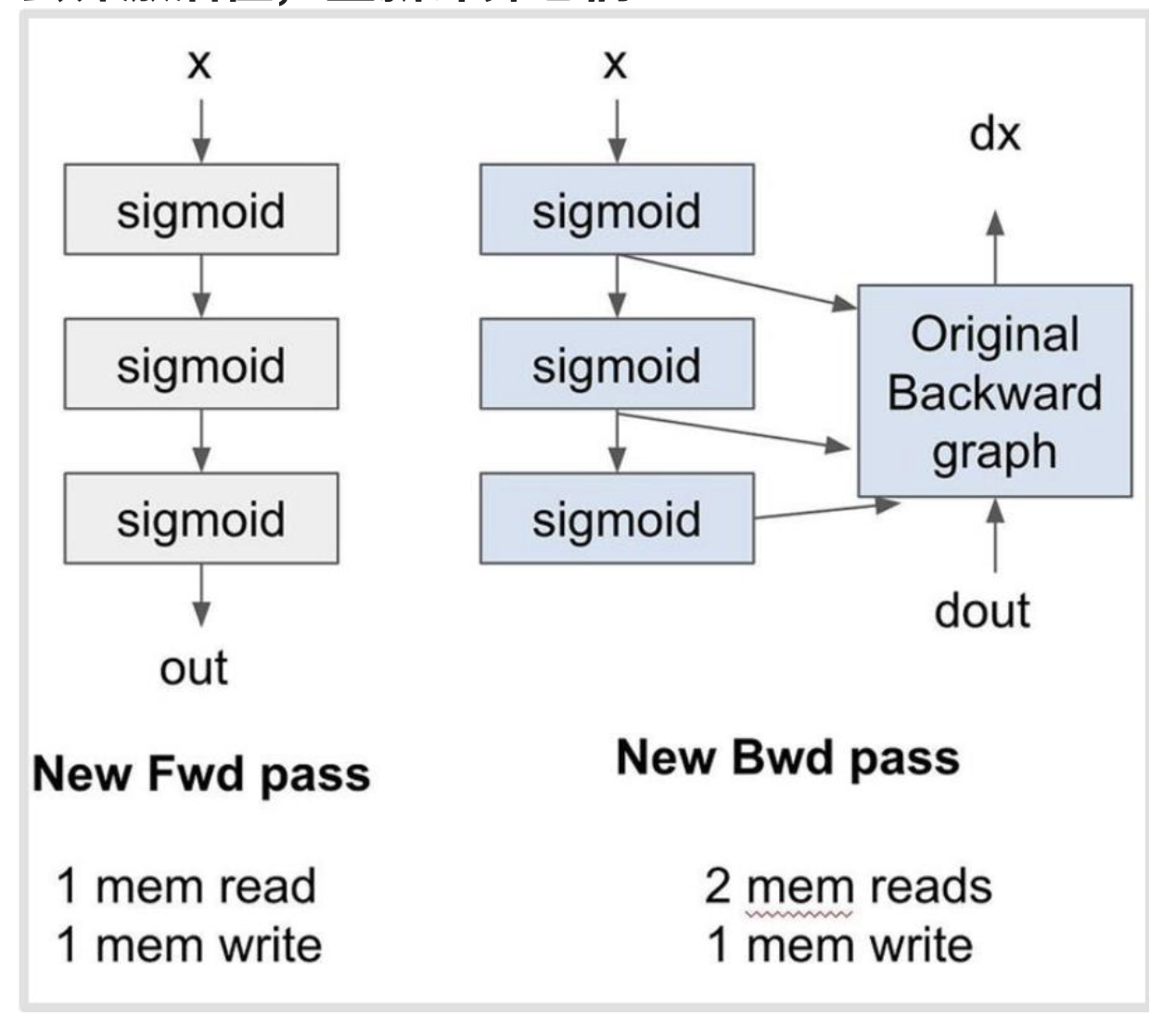
丢弃计算实际上可能是最优的,(w/ 5/8th) 次内存访问!
技巧(?)4:内存合并与动态随机存取存储器
动态随机存取存储器(全局内存)以“突发模式”读取——每次读取可获取多个字节!

内存合并
如果所有线程(在一个线程束中)都处于同一突发访问范围内,则内存访问会被合并。
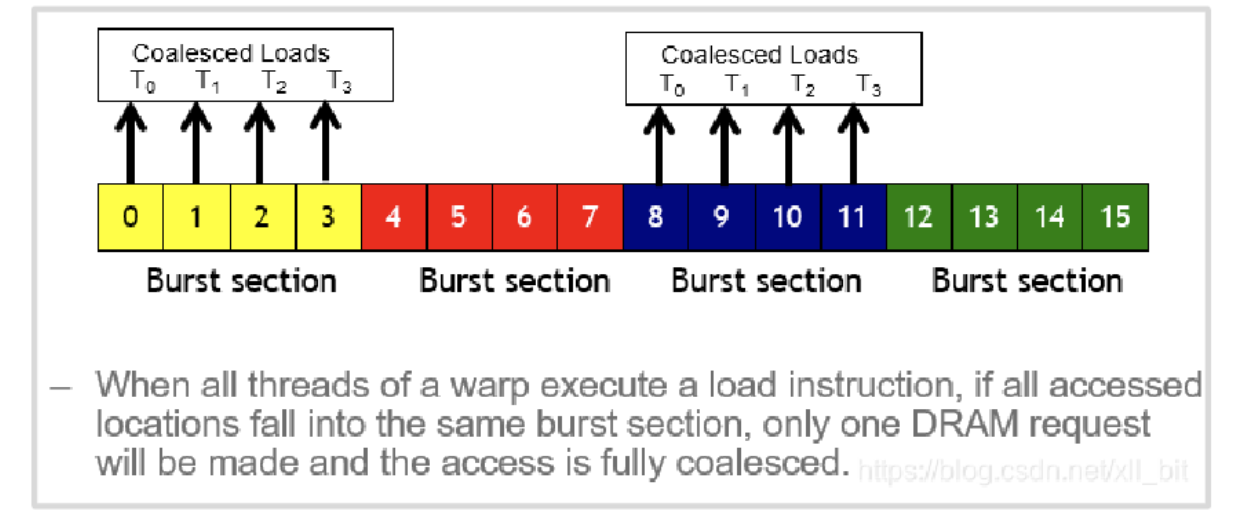
提醒:一个线程束(warp)是一组32个连续编号的线程,它们在一个线程块中共同执行。内存访问也是同时进行的。
矩阵乘法的合并
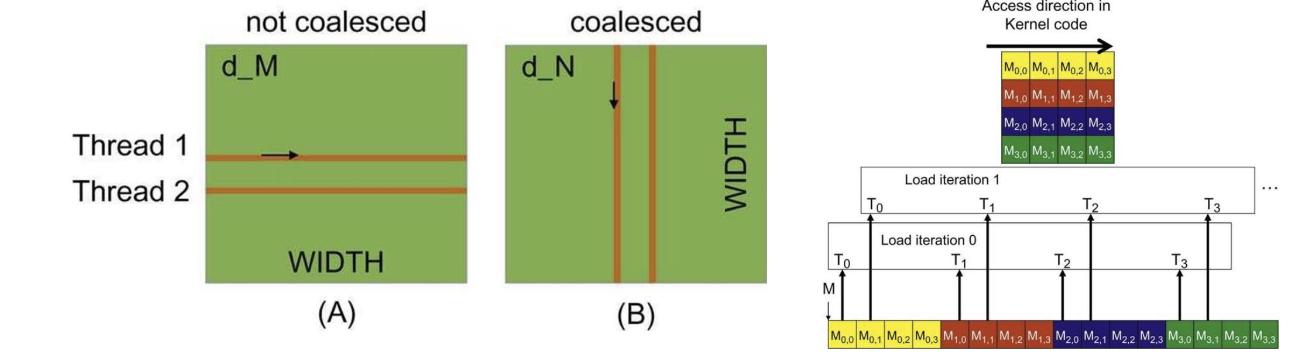
对于按行优先存储的矩阵——沿行移动的线程是未合并的。请注意,第二张图在每一步是如何读取整个向量的!
技巧5(重要的一个):平铺
平铺(Tiling)是一种将线程分组并排序以最小化全局内存访问的思路。
![![[Pasted image 20250814161200.png]]](https://i-blog.csdnimg.cn/direct/37b451f6eca14e65b4139255058fada0.png)
请注意,内存访问不是合并的,并且存在重复(M0,0 和 N1,0)
平铺——在共享内存中存储和重用信息
将矩阵分割成较小的“小块”,并将其加载到共享内存中
![![[Pasted image 20250814161325.png]]](https://i-blog.csdnimg.cn/direct/2e4c2c33b65f4a8889f2279bc172694e.png)
优点:重复读取现在访问的是共享内存,而非全局内存,并且内存访问可以合并。
平铺数学
![![[Pasted image 20250814161526.png]]](https://i-blog.csdnimg.cn/direct/42e2e714f3924d9eb54fbec31f64cc28.png)
非分块矩阵乘法:每个输入从全局内存中读取N次。
分块矩阵乘法:每个输入从全局内存中读取(NT)(\frac{N}{T})(TN)次,并且在每个分块内读取T次。这使得全局内存访问次数减少了T倍。
平铺的复杂性
平铺大小可能无法整除矩阵大小,从而导致利用率低下
![![[Pasted image 20250814161729.png]]](https://i-blog.csdnimg.cn/direct/e14d786d6bba4f248ce35ae747f1867e.png)
影响分块大小的因素
• 合并内存访问
• 共享内存大小
• 矩阵维度的可整除性
平铺2的复杂性 - 内存对齐
内存以突发方式出现
![![[Pasted image 20250814162138.png]]](https://i-blog.csdnimg.cn/direct/90424abb20244f179847259a8a7f16cb.png)
如果突发传输与矩阵对齐,加载图块的速度会很快
![![[Pasted image 20250814162235.png]]](https://i-blog.csdnimg.cn/direct/6db75bad97f240c4b4fa3791d4e14859.png)
根据矩阵的维度,合并访问可能无法实现。(必须进行填充)
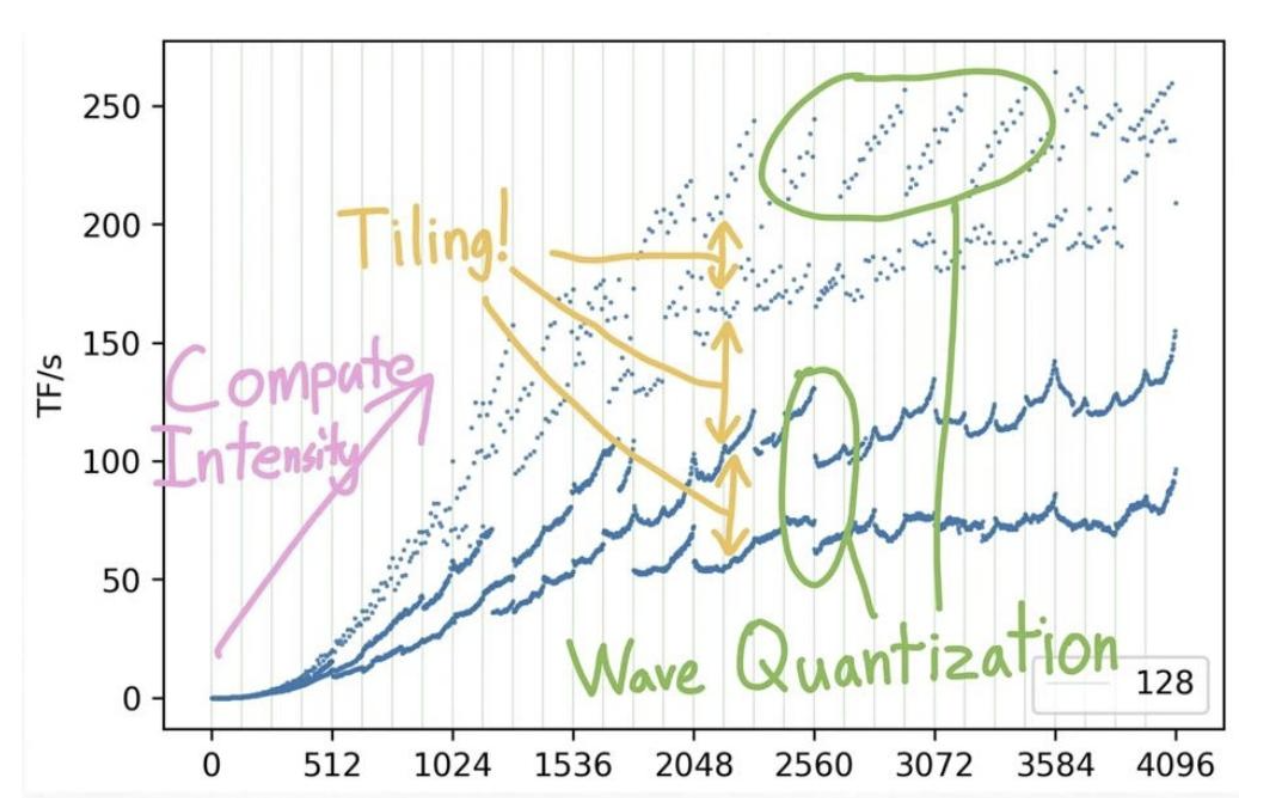
整合起来:理解矩阵谜题
到目前为止,对nanoGPT最显著的优化(提速约25倍),就是简单地将词汇表大小从50257增加到50304(最接近64的倍数,这会计算出增加的无用维度,但会沿着占用率高得多的不同内核路径进行。要注意2的幂次方)
为什么更大的矩阵运算速度更快?
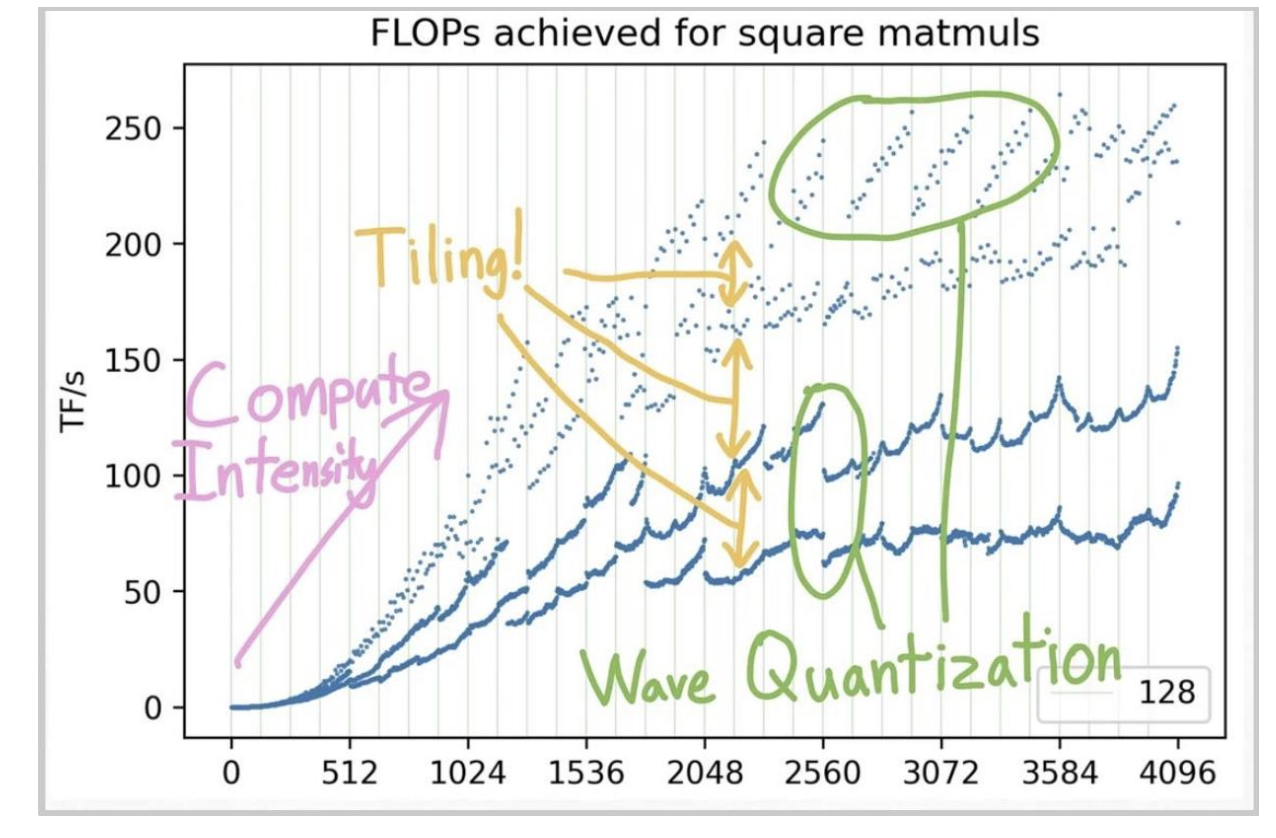
矩阵奥秘
第一部分:平铺
![![[Pasted image 20250814162537.png]]](https://i-blog.csdnimg.cn/direct/37bad24612d84299ba5d8ebad94c5508.png)
方阵乘法实现的每秒浮点运算次数(根据形状是否能被K整除进行颜色编码)
随着k变大FLOPs越来越小
平铺通过对齐产生重大影响。
第2部分:波形量化
这种周期性行为是怎么回事?
![![[Pasted image 20250814162722.png]]](https://i-blog.csdnimg.cn/direct/976f00e1a8fa42c48f175c63d68e5176.png)
第二部分回顾:加速机器学习工作负载
减少内存访问
合并
融合
将内存移动到共享内存
平铺
用内存换取计算量/精度
量化
重计算
第3部分:运用已知知识理解Flash Attention
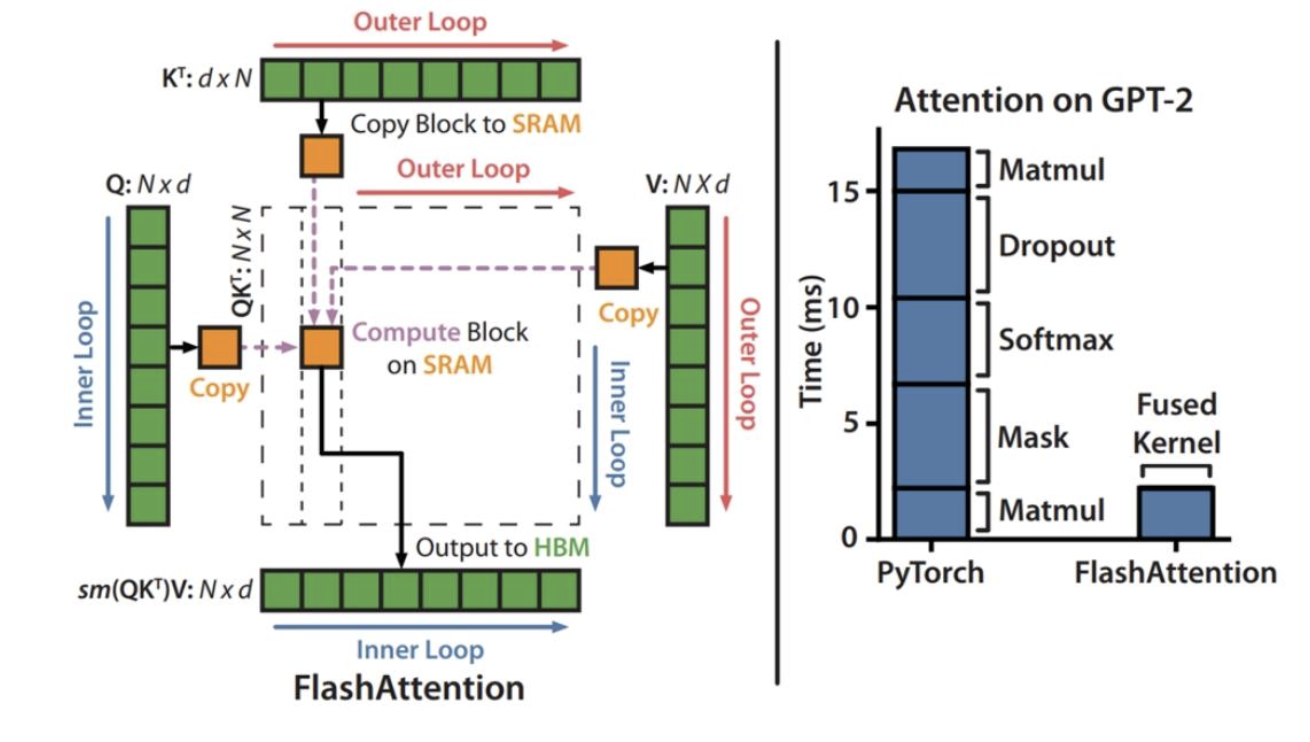
Flash注意力机制显著加快了注意力计算……但这是如何实现的呢?
![![[Pasted image 20250814163128.png]]](https://i-blog.csdnimg.cn/direct/f67c36cfd89a4a3fa863c15784e87493.png)
论文中的技术:
我们应用两种成熟的技术(平铺、重计算)来克服在亚二次 HBM 访问中计算精确注意力的技术挑战。我们在算法 1 中对此进行描述。
注意力计算回顾
注意力计算:3次矩阵乘法(K、Q、V),中间穿插一次softmax运算
![![[Pasted image 20250814163252.png]]](https://i-blog.csdnimg.cn/direct/fc52d1726c6441fea5429b412296d63f.png)
平铺部分1:KQV矩阵乘法的平铺
![![[Pasted image 20250814163308.png]]](https://i-blog.csdnimg.cn/direct/6cdc2b0989b24e5cbc6f9c20cddeae11.png)
论文中的图1实际上只是用于KQV矩阵乘法的平铺操作……但我们该如何处理softmax呢?
平铺部分2:softmax的增量计算
![![[Pasted image 20250814163452.png]]](https://i-blog.csdnimg.cn/direct/19bdd717c74b44099af4a4ecab5b9238.png)
为了跟踪最大值,逐步更新最大值,并建立一个叠缩和。
这使你能够逐块计算softmax
将所有内容整合起来——FlashAttention的前向传播
![![[Pasted image 20250814163622.png]]](https://i-blog.csdnimg.cn/direct/ed40ee023ac248bf836bbe796d1f4a90.png)
• 内积的分块计算,(𝑆)
• 指数算子的融合
• 通过在线累和技巧逐块计算softmax
(我们不会涉及反向传播——但他们会逐块重新计算……)
整堂讲座回顾
硬件性能会扩展,底层细节决定了哪些能扩展,哪些不能。
当前基于GPU的计算大力提倡考虑矩阵乘法
数据移动
对GPU(合并、平铺、融合)进行仔细思考,有助于我们获得良好的性能。
总结
-
GPU与CPU的核心设计差异是什么?
GPU针对大规模并行线程优化,以吞吐量(总数据处理量)为核心目标;CPU则优化少量快速线程,聚焦延迟(单线程执行速度)。GPU通过大量流式多处理器(SM)和流式处理器(SP)实现并行,而CPU侧重复杂控制逻辑和低延迟缓存。 -
GPU内存层次结构的关键特点是什么?
内存速度随与流式多处理器(SM)的距离增加而降低:SM内部的L1缓存和共享内存最快,芯片上的L2缓存次之,芯片外的全局内存最慢。优化性能需减少全局内存访问,优先利用近距内存。 -
提升GPU上机器学习工作负载性能的核心思路有哪些?
核心是减少内存访问并提高计算效率:通过低精度计算减少数据传输量;算子融合避免多次内存交互;平铺技术利用共享内存重用数据;重计算以额外计算换取内存开销降低;合并内存访问匹配DRAM突发读取模式。 -
FlashAttention如何利用GPU特性加速注意力计算?
结合平铺(分块计算KQV矩阵乘法,利用共享内存减少全局内存访问)和增量计算(逐块更新softmax的最大值和累加和,避免存储完整中间结果),显著降低内存访问成本,充分发挥GPU并行计算能力。 -
计算能力(FLOPs)扩展快于内存速度的影响及应对策略?
导致计算单元易因数据供应不足而闲置(内存瓶颈)。应对需聚焦内存效率:优化数据 locality(如平铺)、减少内存交互(如算子融合、重计算)、降低单次数据传输量(如低精度)。