详解MySQL中的多表查询:多表查询分类讲解、七种JOIN操作的实现
精选专栏链接 🔗
- MySQL技术笔记专栏
- Redis技术笔记专栏
- 大模型搭建专栏
- Python学习笔记专栏
- 深度学习算法专栏
欢迎订阅,点赞+关注,每日精进1%,与百万开发者共攀技术珠峰
更多内容持续更新中!希望能给大家带来帮助~ 😀😀😀
分类讲解MySQL中的多表查询
- 1,什么是多表查询
- 2,多表查询的分类
- 3,等值连接和非等值连接
- 3.1,等值连接的定义及应用
- 3.2,非等值连接的定义及应用
- 4,自连接和非自连接
- 4.1,自连接的定义及应用
- 4.2,非自连接的定义及应用
- 5,内连接和外连接
- 5.1,内连接的定义及应用
- 5.2,外连接的定义及应用
- 6,使用SQL语言实现七种JOIN操作(面试重点)
- 6.1,UNION和UNION ALL
- 6.2,MySQL的7种JOIN操作
- 6.2.1,内连接
- 6.2.2,左外连接
- 6.2.3,右外连接
- 6.2.4,左排除连接
- 6.2.5,右排除连接
- 6.2.6,全外连接
- 6.2.7,外排除连接
1,什么是多表查询
多表查询,也称为关联查询,指两个或更多个表一起完成查询操作。
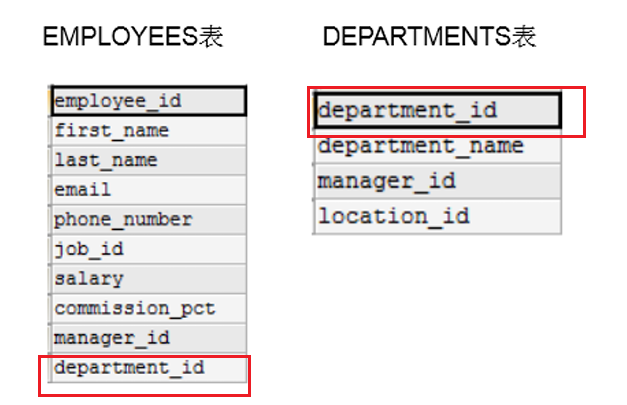
可进行多表查询的前提条件: 这些一起查询的表之间是有关系的(一对一、一对多),它们之间一定是有关联字段,如下图:员工表和部门表,这两个表依靠“部门编号”进行关联,因此符合多表查询的条件。
2,多表查询的分类
连接查询通过表之间的关联条件,将多张表的数据合并输出。根据匹配逻辑和结果集范围,可分为以下类型:
- 等值连接和非等值连接;
- 自连接和非自连接 ;
- 内连接和外连接;
接下来我们详细看一下这些不同种类多表查询的定义和应用。
3,等值连接和非等值连接
根据多表查询的连接条件的类型可分为等值连接和非等值连接。
- 等值连接通过(=)运算符进行比较;
- 非等值连接通过其他运算符进行比较;
3.1,等值连接的定义及应用
等值连接是最常见的一种连接类型,它基于两个表之间的相等条件来连接记录。这通常意味着连接条件中的两个字段通过等于(=)操作符进行比较。
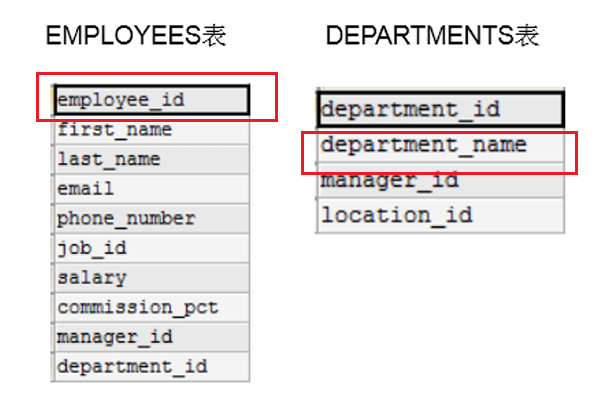
我们根据前面介绍已知EMPLOTYEES表和DEPARTMENTS表满足多表查询的前提条件。当我们有如下需求时:
需求:查询每一位员工的employee_id和department_name。
注意: 如下图所示,员工的employee_id位于EMPLOYEES表,而department_name字段位于DEPARTMENTS表。
此时正确的SQL语句如下:
SELECT employee_id,department_name
FROM employees,departments# 两个表的连接条件
WHERE employees.department_id = departments.department_id;
运行结果如下:
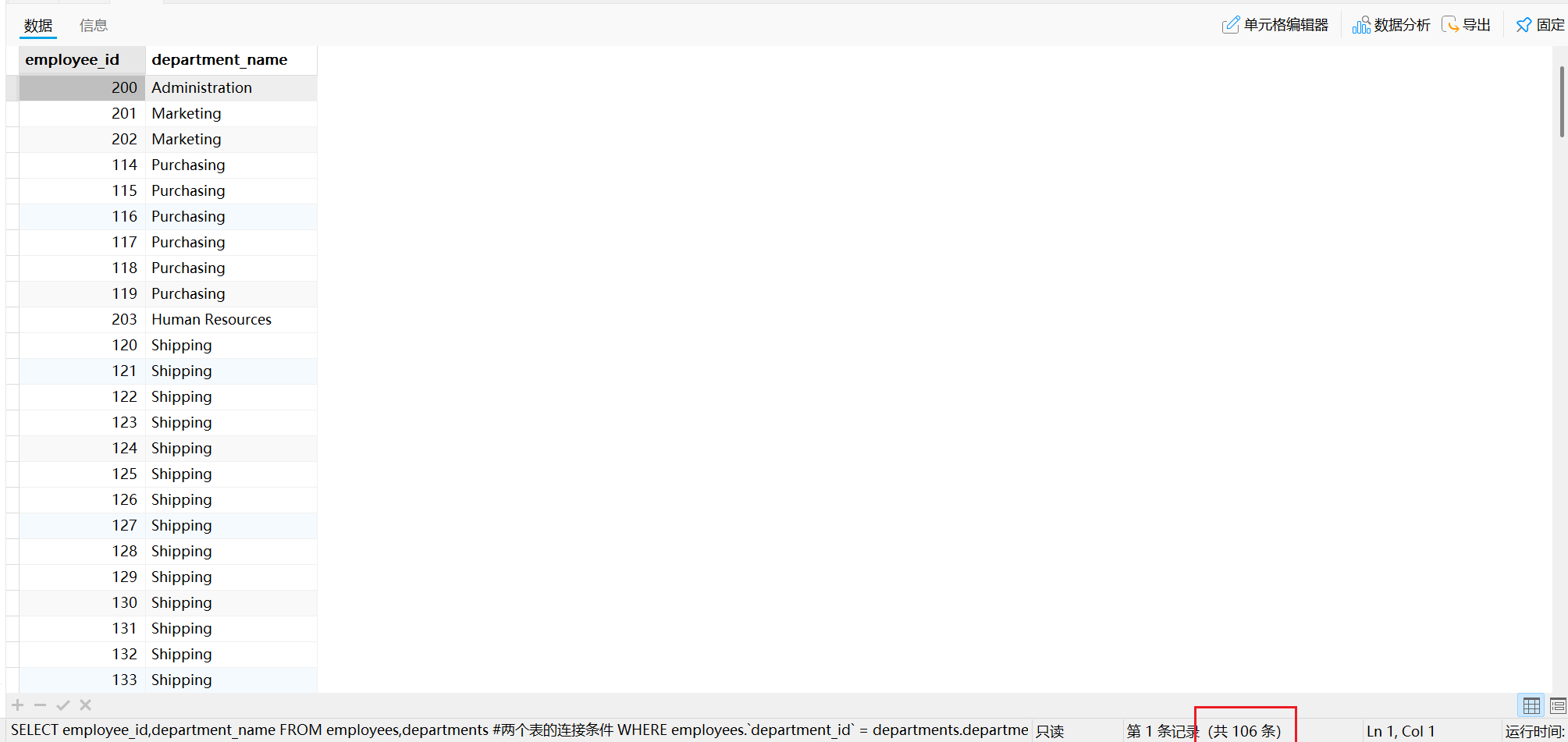
此即为一个等值连接的应用示例。
3.2,非等值连接的定义及应用
非等值连接则不局限于等于(=)操作符,而是可能使用其他比较操作符(如>、<、>=、<=、<>等),或者通过表达式或函数来连接两个表。
EMPLOYEES表中每个员工都有SALARY(工资)字段;而JOB_GRADES表中又对不同薪资范围做了等级的划分。
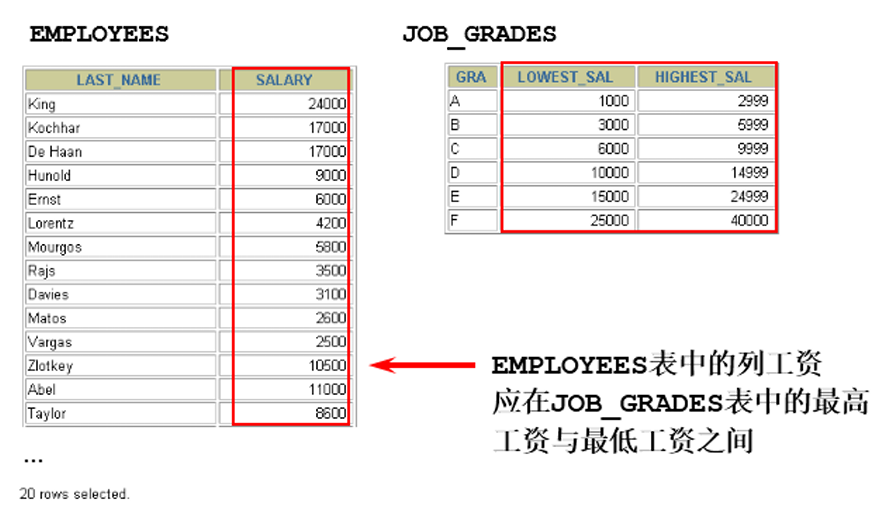
当我们有如下需求时:
需求:查看员工的姓名、工资、工资等级
SQL语句如下:
SELECT e.last_name, e.salary, j.grade_level
FROM employees e, job_grades j
# 非等值连接条件
WHERE e.salary BETWEEN j.lowest_sal AND j.highest_sal
或者:
SELECT e.last_name, e.salary, j.grade_level
FROM employees e, job_grades j
# # 非等值连接条件
WHERE e.salary >= j.lowest_sal AND e.salary<=j.highest_sal
运行结果如下:
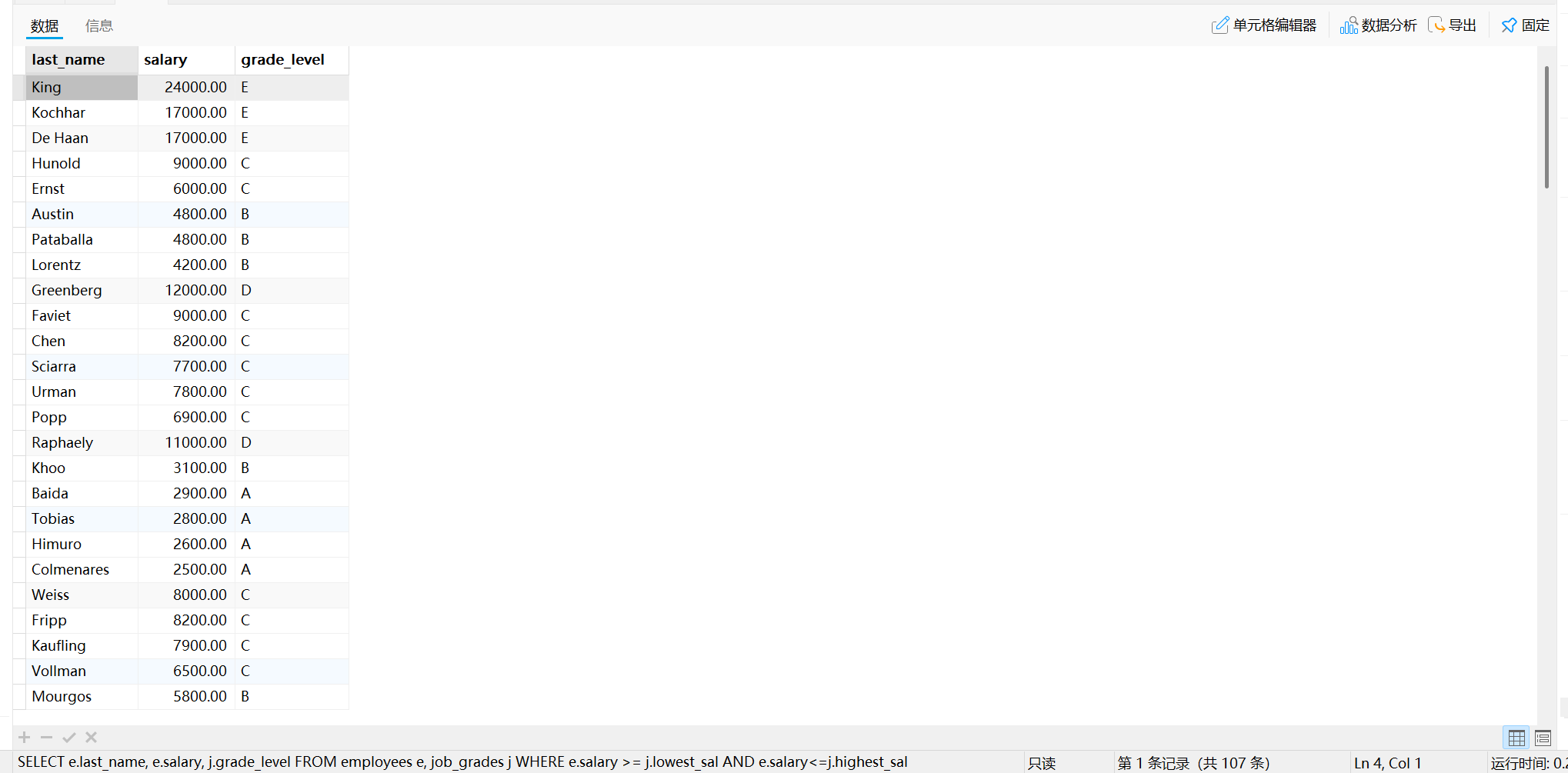
此即为一个非等值连接的应用示例。
4,自连接和非自连接
根据多表查询连接的表是否为同一张表可分为自连接和非自连接。(本节之前列举的多表查询例子连接的表为不同表,因此均为非自连接)
- 自连接指连接的表为同一张表;
- 非自连接连接的表不是同一张表;
4.1,自连接的定义及应用
自连接是指同一张表与其自身进行连接的操作。这种类型的连接通常用于处理具有层级关系的数据,比如在员工表中查找每个员工的直接上级。为了实现这一点,需要为同一个表赋予不同的别名,以便在查询时区分不同的实例。
自连接对应了表中自我引用的关系。如下图员工表的例子所示,104号和105号员工的主管是103号员工(103号员工是一名员工,同时担任主管)。
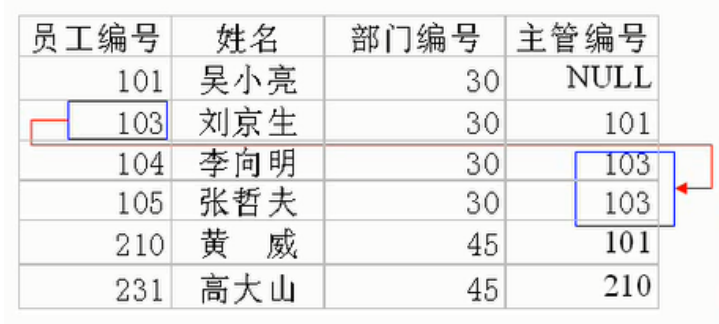
需求: 要查询员工ID、员工姓名及其管理者ID和姓名
SQL语句如下:
SELECT emp.employee_id,emp.last_name,mgr.employee_id,mgr.last_name# 给同一张表起两个别名,一份看作员工,一份看作管理者
FROM employees emp ,employees mgr
WHERE emp.`manager_id` = mgr.`employee_id`;
查询结果如下:
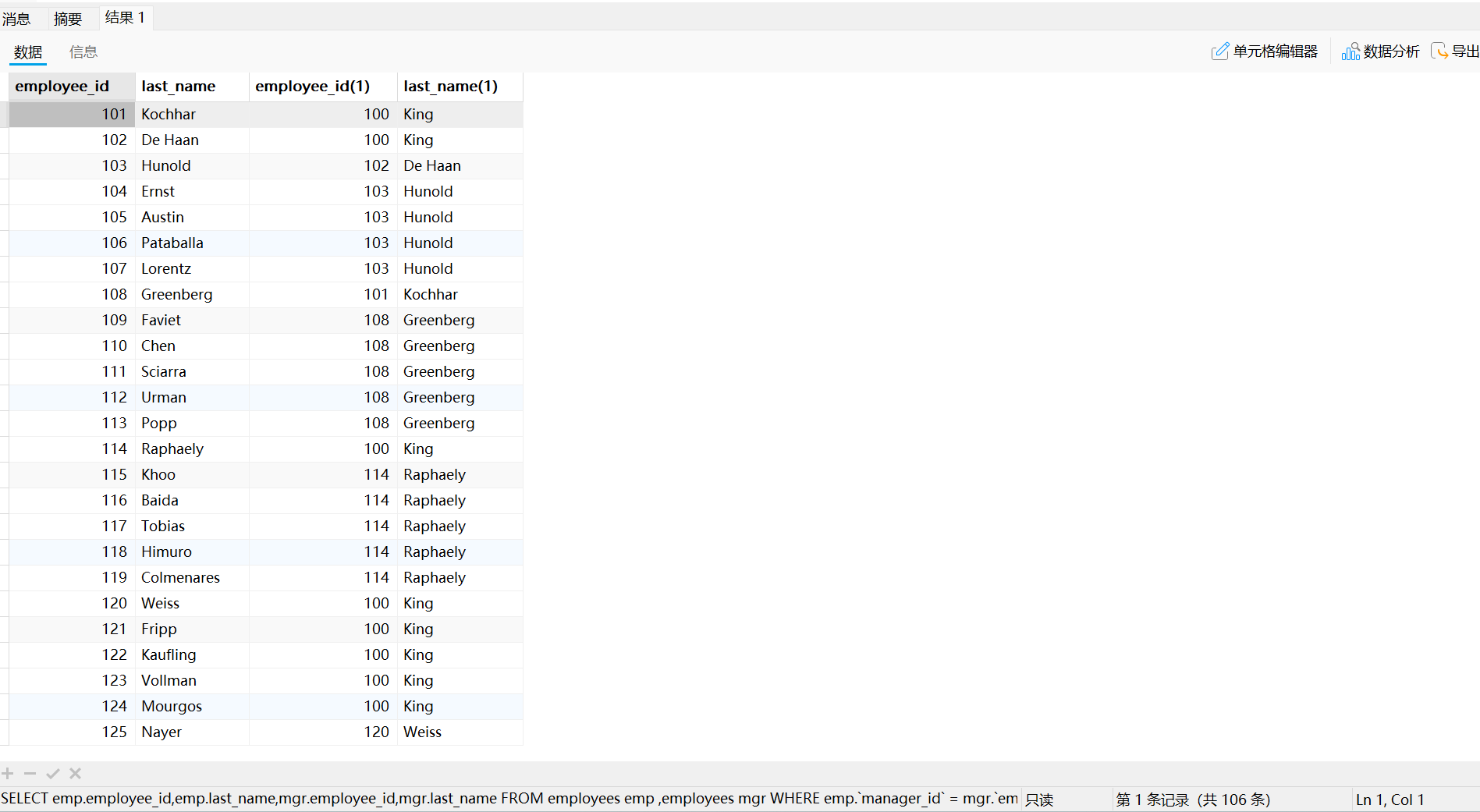
此即为一个自连接的示例。
4.2,非自连接的定义及应用
非自连接是最常见的连接形式。非自连接和自连接相反,非自连接指的是不同表之间的连接,用于处理两个或多个独立表之间的数据关系。
由于4章节节之前列举的多表查询例子连接的表均为不同表,因此均为非自连接。此处不再赘述。
5,内连接和外连接
根据多表查询连接结果中是否包含未匹配的行可分为内连接和外连接。
- 连接结果中不包含未匹配行即为内连接;
- 连接结果中包含未匹配行即为外连接;
5.1,内连接的定义及应用
内连接返回的是满足连接条件的所有行的交集部分。 这意味着只有当两个表中存在相应的匹配记录时,这些记录才会出现在结果集中。
需求:查询员工ID及部门名
SQL语句如下:
SELECT employee_id,department_name
FROM employees e,departments d
WHERE e.department_id = d.department_id
或者:
SELECT employee_id,department_name
# INNER JOIN表示内连接(SQL99语法)
FROM employees e INNER JOIN departments d
ON e.`department_id` = d.`department_id`;
查询结果如下:
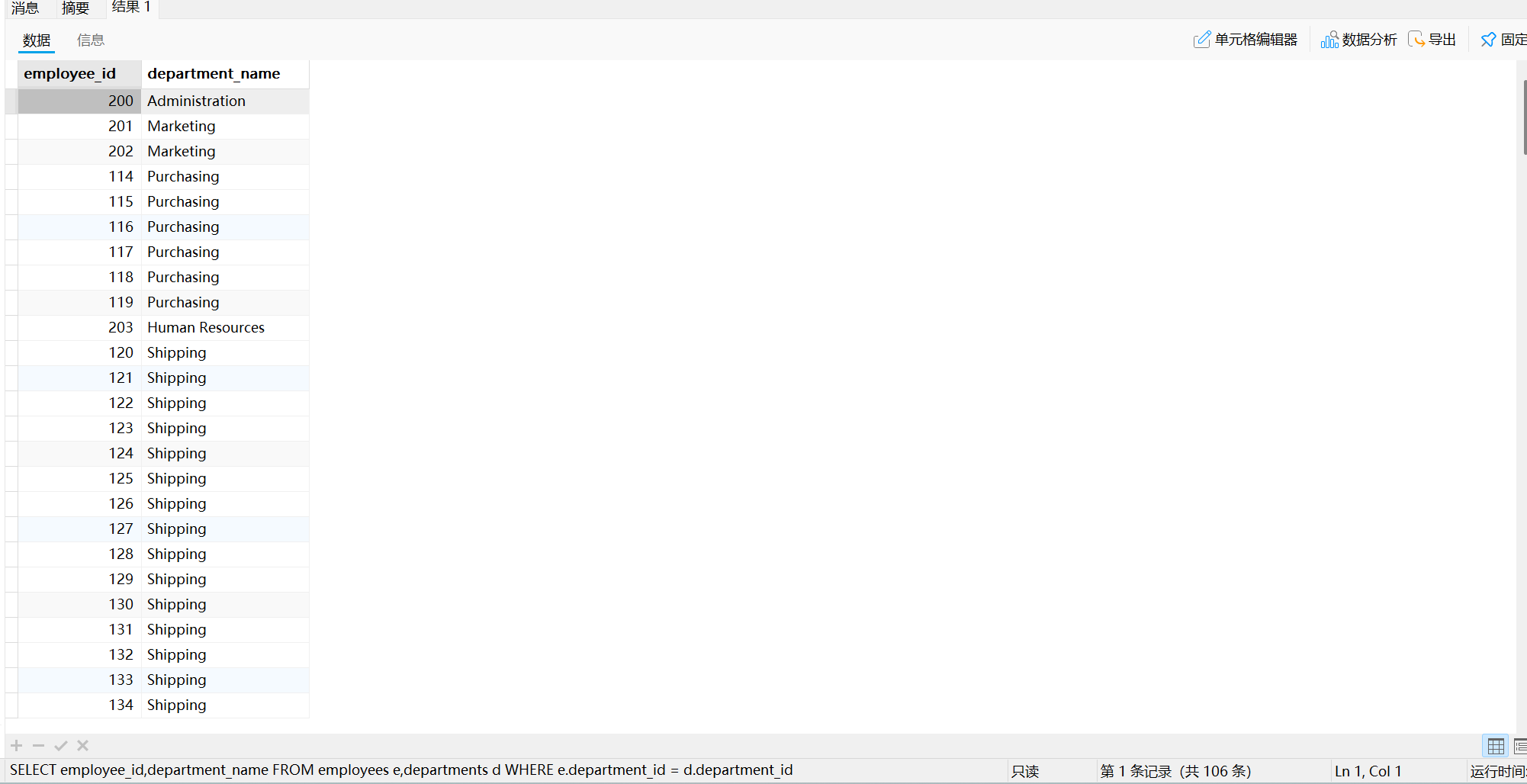
此即为一个内连接的简单例子。这段SQL语句的核心在于只把左表和右表中满足连接条件的数据查出来了,此即为内连接。比如:如果某员工的department_id为空,则不会出现在查询得到的结果集中。
5.2,外连接的定义及应用
外连接包括主表中的所有记录,即使它们在另一个表中没有匹配项。
而外连接又分为左外连接、右外连接和全外连接。
- 左外连接会返回左表中的所有记录以及右表中符合条件的记录;
- 右外连接会返回右表中的所有记录以及左表中符合条件的记录;
- 全外连接则返回两张表中的所有记录,对于没有匹配项的部分用NULL填充。
需求: 查询
所有的员工姓名、所在部门名信息
注意:提及所有的员工,说明是外连接。
SQL语句如下:
SELECT last_name,department_name
# LEFT OUTER JOIN 表示左外连接 ,以左表employees为基础
FROM employees e LEFT OUTER JOIN departments d
ON e.`department_id` = d.`department_id`;
或者:
SELECT last_name,department_name
# 省略OUTER,LEFT JOIN 也可表示左外连接
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`;
运行结果如下:
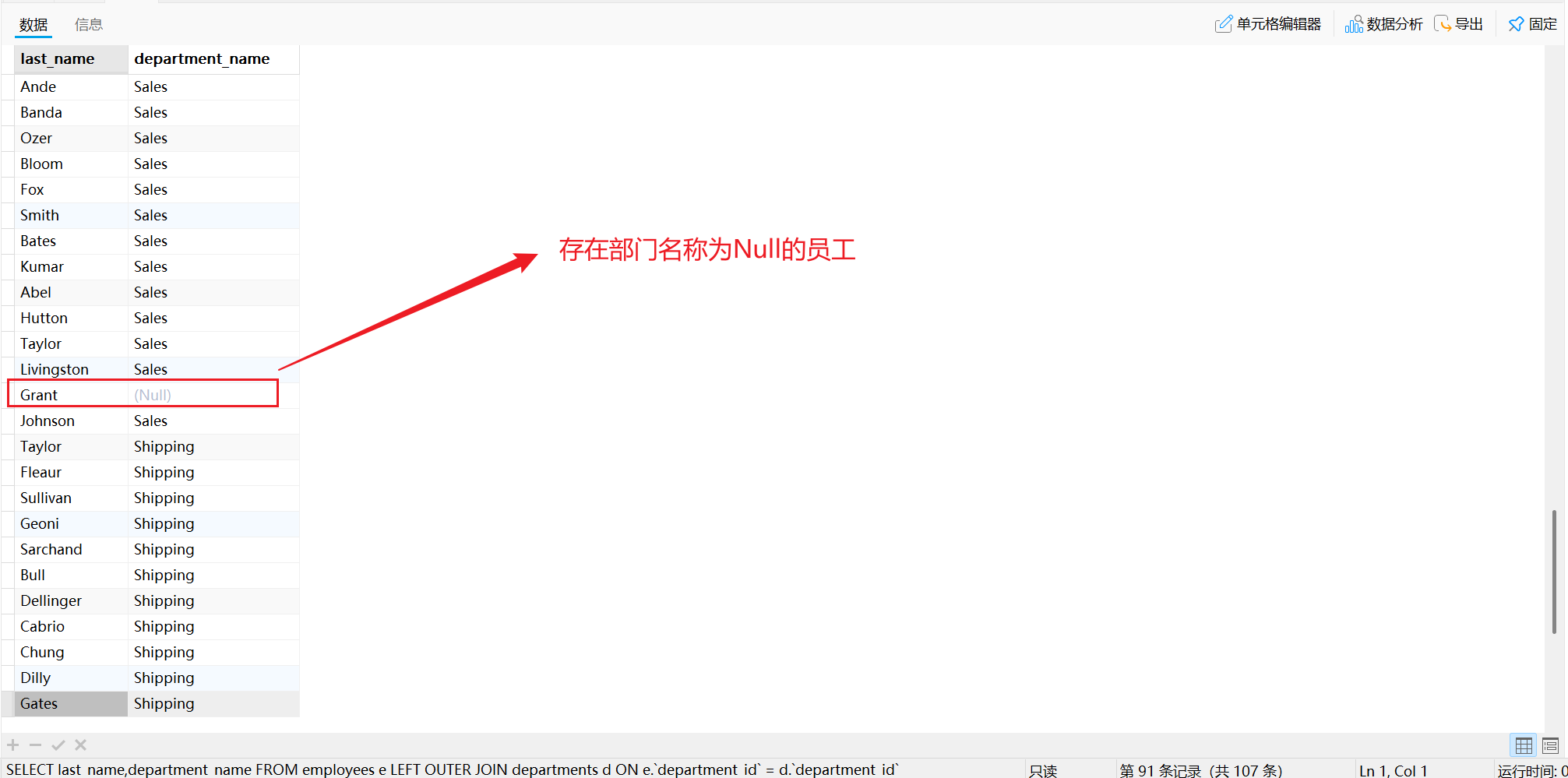
从查询结果可以看到,结果包含左表中所有的记录以及右表中符合条件的记录。即使EMPLOYEES表内存在一个员工的department_name为Null,经过左外连接查询后依然现实中查询得到的结果集中。
此即为一个外连接的示例,具体而言是左外连接。接下来我们详细学习其中JOIN操作。
6,使用SQL语言实现七种JOIN操作(面试重点)
6.1,UNION和UNION ALL
- 使用UNION操作符可以返回两个查询的结果集的并集,
去除重复记录; - 使用UNION ALL操作符可以返回两个查询的结果集的并集,
对于两个结果集的重复部分,不去重; - 执行UNION ALL语句时所需要的资源比UNION语句少。 如果明确知道合并数据后的结果数据
不存在重复数据,或者不需要去除重复的数据,则尽量使用UNION ALL语句,以提高数据查询的效率。
应用案例:
需求1: 查询部门编号>90或邮箱包含a的员工信息
实现方式1:
SELECT * FROM employees WHERE email LIKE '%a%' OR department_id>90;
实现方式2:
SELECT * FROM employees WHERE email LIKE '%a%'
# union会自动去重
UNION
SELECT * FROM employees WHERE department_id>90;
需求2::查询中国用户中男性的信息以及美国用户中年男性的用户信息
实现方式 :
SELECT id,cname FROM t_chinamale WHERE csex='男'
UNION ALL
SELECT id,tname FROM t_usmale WHERE tGender='male';
6.2,MySQL的7种JOIN操作
MySQL中共有7种JOIN操作,如下图所示。但实际上常用的只有四种,它们分别是:
- 内连接;
- 左外连接;
- 右外连接;
- 全外连接;
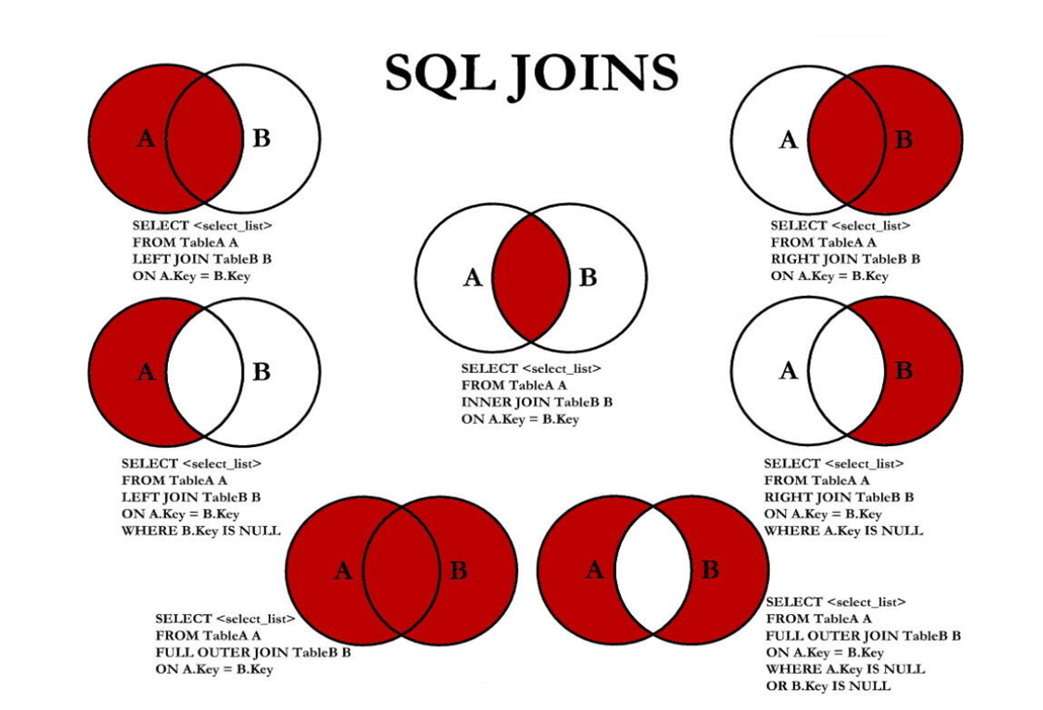
接下来我们一一实现这些JOIN操作。
6.2.1,内连接
内连接返回的是满足连接条件的所有行的交集部分。 这意味着只有当两个表中存在相应的匹配记录时,这些记录才会出现在结果集中。
内连接图示如下:
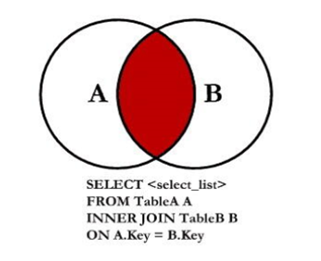
需求: 查询出
已分配有效部门的员工的ID和部门名字:
SQL语句如下:
SELECT employee_id,last_name,department_name
FROM employees e JOIN departments d
ON e.`department_id` = d.`department_id`;
6.2.2,左外连接
左外连接会返回左表中的所有记录以及右表中符合条件的记录;
左外连接图示如下 :
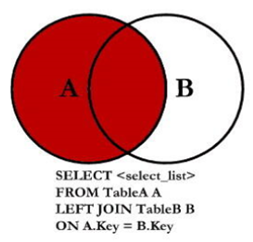
需求: 查询
所有员工ID以及部门姓名
SQL语句如下:
SELECT employee_id,last_name,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`;
6.2.3,右外连接
右外连接会返回右表中的所有记录以及左表中符合条件的记录;
右外连接图示如下:
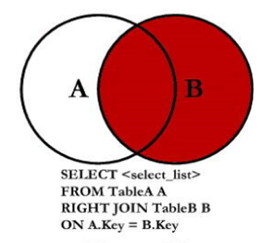
需求: 列出
所有部门(包括没有员工的部门),并显示每个部门中的员工信息(如果有的话)
SQL语句如下:
SELECT employee_id,last_name,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`;
6.2.4,左排除连接
左排除连接图示如下:

左排除连接通过在LEFT JOIN的基础上添加WHERE B.Key IS NULL来实现的,左排除连接返回的是表A中那些在表B中没有匹配项的记录。
需求: 查找没有分配到任何部门的员工的信息
SELECT employee_id,last_name,department_nameFROM employees e LEFT JOIN departments dON e.`department_id` = d.`department_id`WHERE d.`department_id` IS NULL
运行结果如下:

6.2.5,右排除连接
右排除连接用于从右表中选择那些在左表中没有匹配记录的数据行。简单来说,右排除连接返回的是右表中的所有在左表中找不到匹配项的记录。
右排除连接图示如下:

需求: 查询没有员工关联的部门信息,即列出那些没有任何员工分配到的部门。
SQL语句如下:
SELECT employee_id,last_name,department_nameFROM employees e RIGHT JOIN departments dON e.`department_id` = d.`department_id`WHERE e.`department_id` IS NULL
运行结果如下:
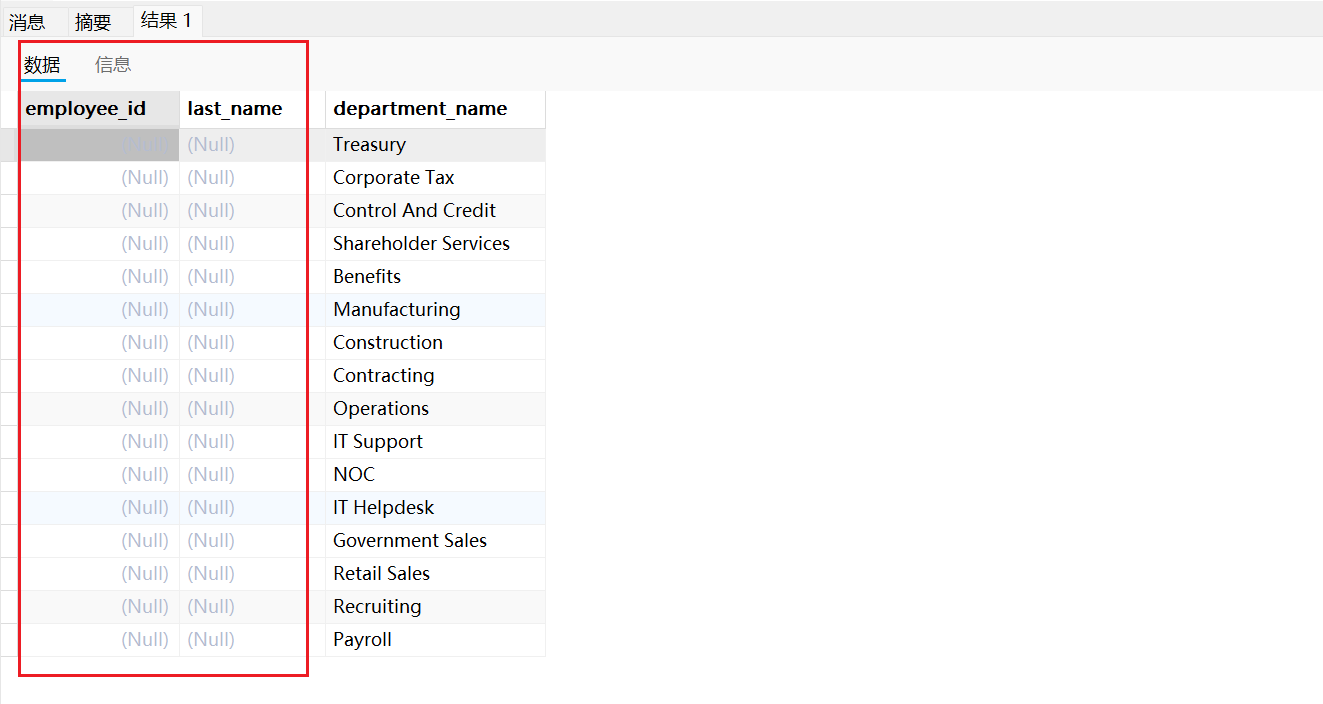
6.2.6,全外连接
全外连接则返回两张表中的所有记录,对于没有匹配项的部分用NULL填充。
全外连接图示如下:
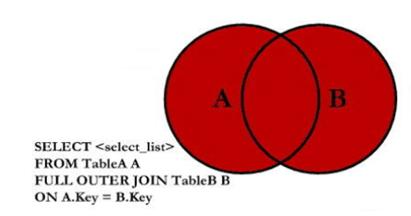
观察示意图,可以发现:全外连接可以由两种其它JOIN操作的并集组合而成。具体有两种组合方式:
- 方式一:左外连接
UNION ALL右排除连接; - 方式二:右外连接
UNION ALL左排除连接;
需求: 查询所有员工(无论是否有对应部门)和所有部门(无论是否有员工)信息。
方式一SQL语句如下:(实际上是合并了两个SQL语句的查询结果,通过UNION ALL合并)
SELECT employee_id,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`
UNION ALL
SELECT employee_id,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE e.`department_id` IS NULL;
方式二SQL语句如下:
SELECT employee_id,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE d.`department_id` IS NULL
UNION ALL
SELECT employee_id,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`;
注意:
- 由于MySQL数据库不识别FULL OUTER JOIN关键字(Oracle数据库支持),全外连接一般通过如上并集的方式等价实现;
- 使用UNION ALL而不用UNION的原因是UNION ALL无需去重操作, 效率更高;
6.2.7,外排除连接
外排除连接是由左排除连接和右排除连接组合而成。 。它返回左表和右表中没有与对方表匹配的行,而匹配的行将被排除在结果集之外。
外排除连接图示如下:

观察示意图,可以发现:外排除连接是由左排除连接和右排除连接组合而成。
需求: 联合查询员工表与部门表之间的不匹配记录,找出 没有对应部门的员工以及没有员工的部门
SQL语句如下:
SELECT employee_id,last_name,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE d.`department_id` IS NULL
UNION ALL
SELECT employee_id,last_name,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE e.`department_id` IS NULL