【Tech Arch】Apache HBase分布式 NoSQL 数据库
HBase是一种高可靠性、高性能、面向列(列族)的开源分布式数据库,是Google Bigtable的开源实现。作为Apache Hadoop生态系统的重要组成部分,HBase填补了Hadoop在实时读写能力上的空白,通过构建在HDFS之上的分布式架构,为海量结构化数据提供了低延迟的随机访问能力。HBase最初由PowerSet公司的Chad Walters和Jim Kelleman于2006年末发起,首个版本于2007年10月发布,2010年5月成为Apache顶级项目 。
它采用主从架构,核心组件包括HMaster、HRegionServer和ZooKeeper,通过RowKey、Column Family、Column和Timestamp构成其独特的数据模型。HBase特别适合处理RowKey明确、高并发随机读写的场景,如用户行为日志、物联网时序数据和实时分析应用,与传统关系型数据库(如MySQL)和同类NoSQL数据库(如Cassandra)相比,在特定场景下展现出显著优势。

一、什么是 HBase?
Apache HBase 是一个分布式、可扩展、面向列的 NoSQL 数据库,设计用于在 commodity hardware(普通硬件)上存储和处理海量结构化和半结构化数据。它借鉴了 Google 的 BigTable 论文思想,运行在 Hadoop 分布式文件系统(HDFS)之上,为超大规模数据提供高可靠性、高吞吐量和随机实时读写能力。
简单来说,HBase 可以看作是一个能够存储 PB 级数据、支持百万级 QPS、分布式部署的 "大表",特别适合存储非结构化和半结构化数据,以及需要随机访问的海量数据场景。
二、HBase 的诞生背景
要理解 HBase 的价值,我们需要回到 2000 年代中期的大数据存储挑战:
- 传统关系型数据库在处理 TB 甚至 PB 级数据时力不从心,难以水平扩展
- 当时的分布式文件系统(如 HDFS)擅长存储大文件和批处理,但缺乏随机读写能力
- 互联网应用爆发式增长,产生了海量的用户行为数据、日志数据、社交关系数据等,需要高效存储和查询
2006 年,Google 发表了著名的《BigTable: A Distributed Storage System for Structured Data》论文,提出了一种分布式存储海量结构化数据的方案。受此启发,Apache 基金会在 Hadoop 生态系统上开发了 HBase 项目,2008 年成为 Apache 顶级项目。
HBase 的诞生填补了 Hadoop 生态中实时随机访问的空白,与 HDFS(存储)、MapReduce(批处理)、Pig/Hive(数据分析)共同构成了完整的大数据处理体系。
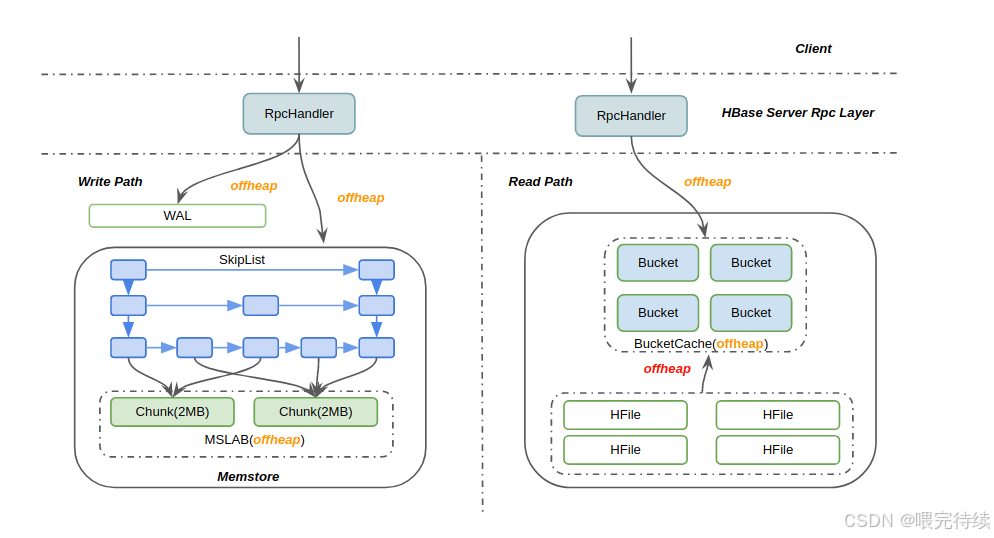
三、HBase 的架构设计
HBase 采用典型的主从架构(Master-Slave),由以下核心组件构成:
1. 客户端(Client)
- 提供与 HBase 集群交互的 API(Java API 为主,也有 REST、Thrift 等接口)
- 负责数据的 Put、Get、Scan 等操作
- 维护缓存,减少与集群的通信开销
2. HMaster
- 集群的主节点,负责管理和协调 RegionServer
- 分配 Region 到 RegionServer
- 处理 Region 的分裂和合并
- 管理元数据(Meta 表)
- 处理 Schema 变更(表的创建、删除、列族修改等)
- 通常部署多个 HMaster 实现高可用(通过 ZooKeeper 选举)
3. RegionServer
- 从节点,负责实际的数据存储和处理
- 管理多个 Region
- 处理客户端的读写请求
- 执行 Region 的分裂操作
- 与 HDFS 交互,存储实际数据
4. Region
- HBase 表的基本分片单位,每个 Region 包含表中一段连续的行
- 每个 Region 由 <表名,起始行键,结束行键> 唯一标识
- 当 Region 大小达到阈值时,会自动分裂为两个更小的 Region
5. ZooKeeper
- 虽然不是 HBase 的核心组件,但 HBase 严重依赖 ZooKeeper
- 存储 HBase 的元数据信息
- 实现 HMaster 的高可用(选举机制)
- 监控 RegionServer 的状态(上线、下线)
- 维护集群的分布式锁
6. HDFS
- 作为 HBase 的底层存储系统
- 存储 HBase 的实际数据(HFile)和日志(WAL)
- 提供数据的高可靠性和容错能力
数据存储结构
HBase 的数据在物理上按列族(Column Family)存储,每个列族对应多个 HFile 文件:
- WAL(Write-Ahead Log):写入数据时先写入日志,确保数据不丢失
- MemStore:内存中的数据缓冲区,数据先写入 MemStore
- HFile:当 MemStore 达到阈值时,数据被刷写到磁盘形成 HFile
- StoreFile:HFile 的抽象,可能由多个 HFile 组成,通过 Compaction 合并
四、HBase 解决的核心问题
HBase 针对大数据场景中的关键挑战提供了有效的解决方案:
1. 海量数据存储
HBase 可以轻松存储 PB 级别的数据,通过水平扩展 RegionServer 实现存储能力的线性增长,突破了单机存储的瓶颈。
2. 高并发随机读写
相比 HDFS 适合批处理但不支持随机读写,HBase 提供了毫秒级的随机读写能力,支持每秒数十万次的操作,满足实时业务需求。
3. 动态扩展
HBase 集群可以根据数据量和访问量动态添加或移除节点,扩展过程无需停机,不影响线上服务。
4. 数据高可靠性
- 依托 HDFS 的副本机制(默认 3 副本)实现数据的高可靠存储
- 通过 WAL 机制确保数据写入不丢失
- 自动检测并恢复故障节点,保证服务连续性
5. 灵活的数据模型
HBase 采用松散的 schema 设计,无需预定义严格的表结构,支持动态添加列,非常适合存储半结构化和非结构化数据。
五、HBase 的关键特性
HBase 之所以能在大数据领域占据重要地位,源于其独特的技术特性:
1. 强一致性
HBase 提供强一致性的读写操作,不同于某些最终一致性的 NoSQL 数据库,确保读取到的数据总是最新的。
2. 面向列族的存储
数据按列族存储,而非按行存储,这使得查询时可以只读取需要的列族,大幅减少 I/O 开销,提高查询效率。
3. 自动分片
HBase 表会根据数据量自动分裂为 Region,并均衡分布到各个 RegionServer,无需人工干预。
4. 版本化
HBase 中的单元格(Cell)可以存储多个版本的数据,每个版本通过时间戳区分,方便数据回溯和历史查询。
5. 布隆过滤器(Bloom Filter)
HBase 提供布隆过滤器功能,可以快速判断一个行键或列是否存在,减少不必要的磁盘 IO,提高查询性能。
6. 块缓存(Block Cache)
RegionServer 会缓存频繁访问的数据块,提高读操作性能。
7. 压缩
支持多种压缩算法(如 GZip、Snappy),可以有效减少存储空间和 IO 传输量。
六、与同类产品对比
HBase 在 NoSQL 数据库领域有多个同类产品,它们各有侧重和适用场景:
1. HBase vs 关系型数据库(MySQL/PostgreSQL)
- 数据规模:HBase 支持 PB 级,关系型数据库通常在 TB 级以下
- 扩展性:HBase 水平扩展简单,关系型数据库扩展复杂
- 事务支持:关系型数据库支持 ACID 事务,HBase 仅支持单行事务
- 数据模型:HBase 是松散 schema,关系型是严格 schema
- 查询能力:关系型数据库支持复杂 SQL 查询,HBase 查询相对简单
2. HBase vs Cassandra
- 一致性模型:HBase 强一致性,Cassandra 可配置一致性级别
- 架构:HBase 是主从架构,Cassandra 是 P2P 架构
- 写入性能:Cassandra 写入性能略优,HBase 读取性能略优
- 生态集成:HBase 与 Hadoop 生态无缝集成,Cassandra 独立性更强
- 适用场景:HBase 适合需要强一致性和 Hadoop 生态集成的场景,Cassandra 适合多数据中心部署
3. HBase vs MongoDB
- 数据模型:HBase 是列族模型,MongoDB 是文档模型
- 查询能力:MongoDB 支持更丰富的查询语法,HBase 查询相对简单
- 事务支持:MongoDB 支持多文档事务,HBase 仅支持单行事务
- 扩展性:两者都支持水平扩展,但实现方式不同
- 适用场景:HBase 适合海量结构化数据和随机访问,MongoDB 适合存储文档型数据
4. HBase vs Redis
- 存储介质:HBase 主要存储在磁盘,Redis 主要存储在内存
- 性能:Redis 性能更高(微秒级),HBase 是毫秒级
- 数据规模:HBase 支持更大数据量,Redis 受限于内存大小
- 功能:Redis 支持丰富的数据结构和功能,HBase 功能相对单一
- 适用场景:Redis 适合缓存和高频访问的小数据,HBase 适合海量数据存储
七、HBase 的使用方法(实战入门)
下面我们通过实际操作来演示 HBase 的基本使用方法:
1. 环境准备
首先需要安装 HBase 集群,最简单的方式是使用 Hadoop 生态的分发版如 Cloudera 或 Hortonworks,也可以手动搭建:
# 下载HBase
wget https://archive.apache.org/dist/hbase/2.4.9/hbase-2.4.9-bin.tar.gz
tar -zxvf hbase-2.4.9-bin.tar.gz
cd hbase-2.4.9# 配置环境变量
export HBASE_HOME=/path/to/hbase-2.4.9
export PATH=$HBASE_HOME/bin:$PATH# 启动HBase(单机模式)
start-hbase.sh
2. 使用 HBase Shell
HBase 提供了交互式命令行工具 HBase Shell,用于管理表和数据:
# 进入HBase Shell
hbase shell# 查看集群状态
status# 创建表(表名:user,列族:info和address)
create 'user', 'info', 'address'# 查看表列表
list# 查看表结构
describe 'user'# 插入数据
put 'user', 'row1', 'info:name', 'Zhang San'
put 'user', 'row1', 'info:age', '30'
put 'user', 'row1', 'address:city', 'Beijing'
put 'user', 'row1', 'address:street', 'Chang'an Street'put 'user', 'row2', 'info:name', 'Li Si'
put 'user', 'row2', 'info:age', '25'
put 'user', 'row2', 'address:city', 'Shanghai'# 获取单行数据
get 'user', 'row1'# 获取指定列族的数据
get 'user', 'row1', 'info'# 获取指定列的数据
get 'user', 'row1', 'info:name'# 扫描表数据
scan 'user'# 扫描指定范围
scan 'user', {STARTROW => 'row1', ENDROW => 'row2'}# 更新数据
put 'user', 'row1', 'info:age', '31'# 删除数据
delete 'user', 'row1', 'address:street'# 删除整行
deleteall 'user', 'row2'# 统计表行数
count 'user'# 禁用表(删除表前必须先禁用)
disable 'user'# 删除表
drop 'user'# 退出Shell
exit
3. Java API 操作
HBase 最常用的方式是通过 Java API 进行编程:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;import java.io.IOException;public class HBaseExample {// 表名private static final String TABLE_NAME = "user";// 列族private static final String CF_INFO = "info";private static final String CF_ADDRESS = "address";public static void main(String[] args) throws IOException {// 配置HBaseConfiguration config = HBaseConfiguration.create();// 如果是远程集群,需要配置zk地址// config.set("hbase.zookeeper.quorum", "zk1,zk2,zk3");// 创建连接try (Connection connection = ConnectionFactory.createConnection(config);Admin admin = connection.getAdmin()) {// 创建表TableName tableName = TableName.valueOf(TABLE_NAME);if (!admin.tableExists(tableName)) {HTableDescriptor tableDescriptor = new HTableDescriptor(tableName);tableDescriptor.addFamily(new HColumnDescriptor(CF_INFO));tableDescriptor.addFamily(new HColumnDescriptor(CF_ADDRESS));admin.createTable(tableDescriptor);System.out.println("表创建成功");}// 获取表对象try (Table table = connection.getTable(tableName)) {// 插入数据Put put = new Put(Bytes.toBytes("row1"));put.addColumn(Bytes.toBytes(CF_INFO), Bytes.toBytes("name"), Bytes.toBytes("Zhang San"));put.addColumn(Bytes.toBytes(CF_INFO), Bytes.toBytes("age"), Bytes.toBytes("30"));put.addColumn(Bytes.toBytes(CF_ADDRESS), Bytes.toBytes("city"), Bytes.toBytes("Beijing"));table.put(put);System.out.println("数据插入成功");// 获取数据Get get = new Get(Bytes.toBytes("row1"));Result result = table.get(get);byte[] name = result.getValue(Bytes.toBytes(CF_INFO), Bytes.toBytes("name"));byte[] age = result.getValue(Bytes.toBytes(CF_INFO), Bytes.toBytes("age"));System.out.println("姓名: " + Bytes.toString(name));System.out.println("年龄: " + Bytes.toString(age));// 扫描数据Scan scan = new Scan();// 只扫描info列族scan.addFamily(Bytes.toBytes(CF_INFO));try (ResultScanner scanner = table.getScanner(scan)) {System.out.println("扫描结果:");for (Result res : scanner) {System.out.println("行键: " + Bytes.toString(res.getRow()));System.out.println("姓名: " + Bytes.toString(res.getValue(Bytes.toBytes(CF_INFO), Bytes.toBytes("name"))));}}}// 删除表admin.disableTable(tableName);admin.deleteTable(tableName);System.out.println("表删除成功");}}
}
4. 依赖配置(Maven)
使用 Java API 需要添加 HBase 相关依赖:
<dependencies><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-client</artifactId><version>2.4.9</version></dependency><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-common</artifactId><version>2.4.9</version></dependency><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-server</artifactId><version>2.4.9</version></dependency>
</dependencies>
八、HBase 最佳实践与性能优化
表设计优化
- 合理设计行键(RowKey),避免热点问题
- 控制列族数量(建议不超过 3 个)
- 根据访问模式设计列族的配置(如压缩、TTL 等)
读写优化
- 批量操作(Batch Put/Get)减少 RPC 开销
- 合理设置 Write Buffer 大小
- 启用布隆过滤器提高查询效率
- 调整 Block Cache 大小适应业务场景
集群管理
- 合理规划 Region 大小(通常 10-50GB)
- 配置自动分裂和合并策略
- 监控并平衡 Region 分布
- 根据需求调整 WAL 策略
文末
Apache HBase 作为 Hadoop 生态系统中的核心组件,为海量数据提供了高可靠、高扩展、高性能的存储解决方案。它特别适合需要存储 PB 级数据、支持高并发随机访问、要求强一致性的场景,如用户行为分析、日志存储、时序数据管理等。
随着大数据技术的不断发展,HBase 也在持续演进,引入了更多新特性如 MOB(中等对象)支持、多租户能力等,进一步扩展了其应用范围。掌握 HBase 不仅能帮助你更好地应对大数据存储挑战,也是深入理解分布式系统设计的重要途径。