机器学习中的「损失函数」:模型优化的核心标尺
在模型训练中,我们常听到“预测值要逼近真实值”。
但如何量化“逼近”?这便是损失函数的核心使命——它如同精密标尺,衡量预测偏差,并为模型优化提供方向指引。
一、损失函数的本质作用
量化预测偏差
通过数学函数计算预测值与真实值的差异,将抽象误差转化为可优化数值。
示例:房价预测中,10万元误差比1万元误差的损失值更高。
驱动参数优化
损失函数的梯度指示参数调整方向(如梯度下降算法),是模型自我迭代的引擎。
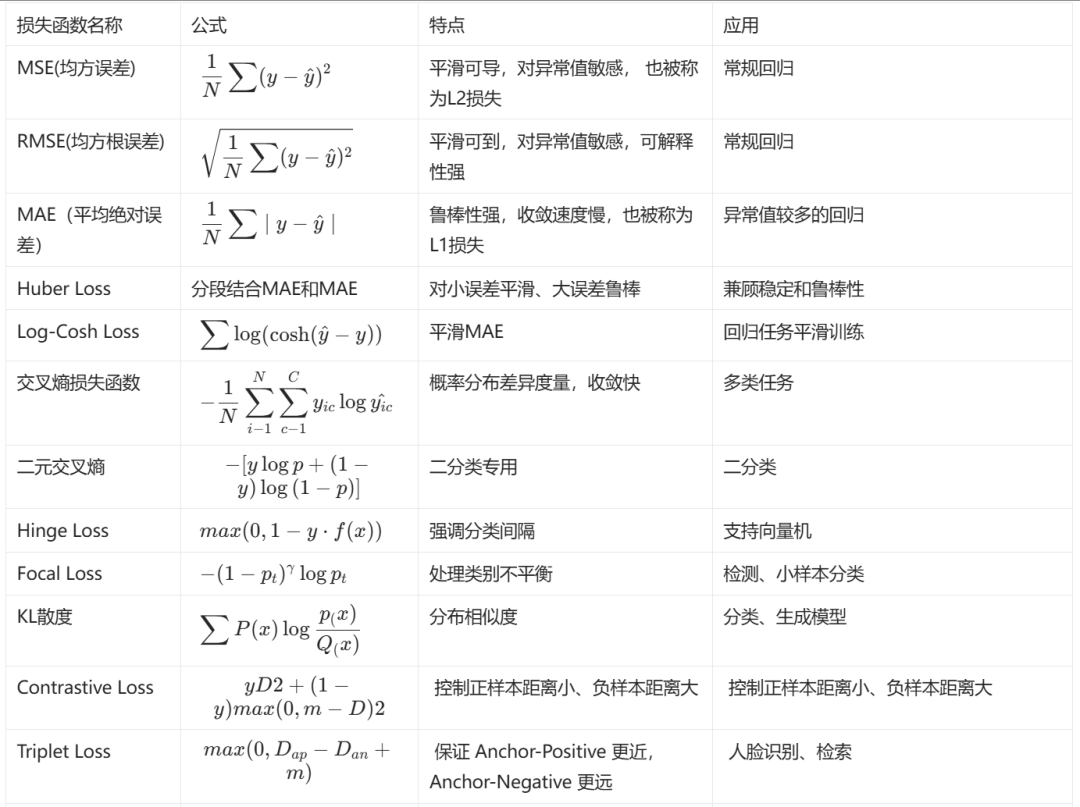
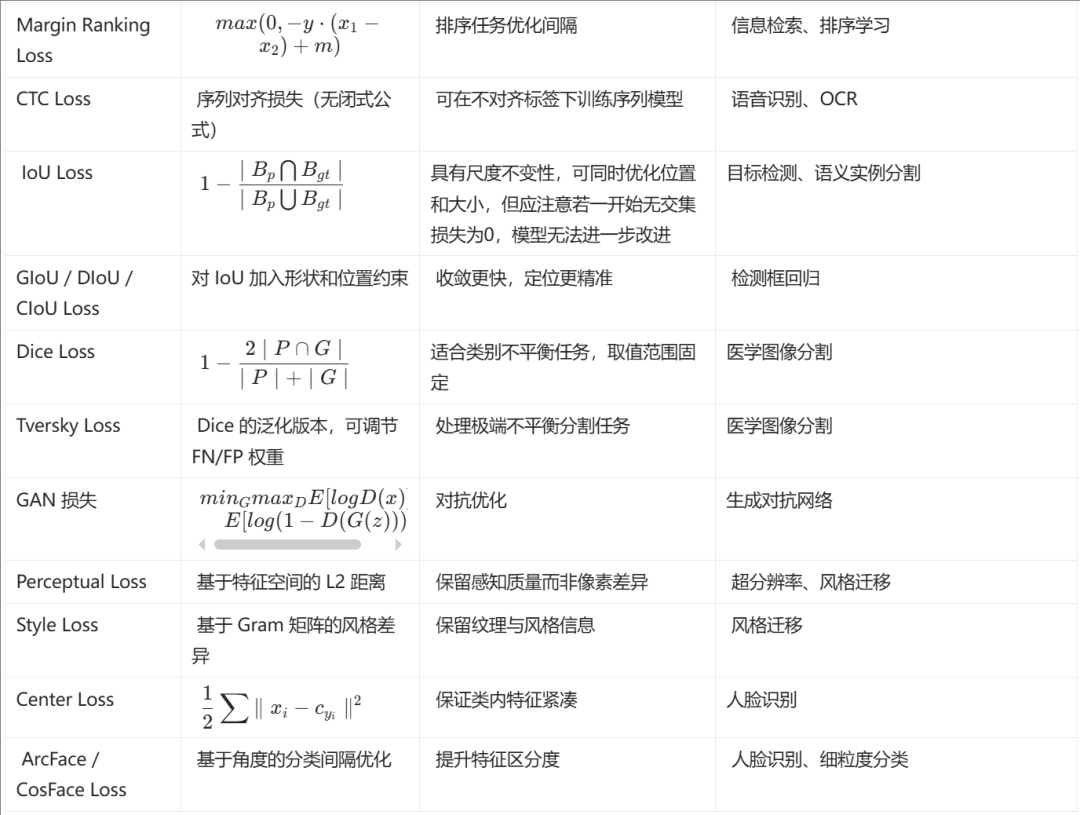
二、常用损失函数全景图
根据任务类型选择损失函数至关重要:
任务类型 | 典型损失函数 | 适用场景 |
|---|---|---|
回归任务 | MSE(L2损失)、MAE(L1损失) | 房价预测、销量分析等连续值预测 |
分类任务 | 交叉熵(Cross Entropy) | 图像分类、情感分析等离散标签任务 |
分割任务 | Dice Loss、IoU Loss | 医学图像分割、自动驾驶场景解析 |
🔍 核心区别对比
MSE vs MAE:
MSE对异常值敏感(平方放大误差),MAE更鲁棒但收敛较慢。
交叉熵为何适合分类:
直接衡量概率分布差异,对错误分类的惩罚随置信度升高呈指数增长。
三、工程师必知的实践技巧
二分类任务:
优先选用
BCEWithLogitsLoss(PyTorch),避免 Sigmoid+BCE 的数值不稳定问题。类别不平衡场景:
交叉熵叠加类别权重(
class_weight)医疗分割任务中,Dice Loss + BCE 组合效果显著:
目标检测框优化:
使用改进版 IoU Loss(如 CIoU),解决无重叠时梯度消失问题。
四、高效学习路径建议
为帮助开发者深入理解损失函数的底层逻辑与代码实践,我们整理了一套图文代码结合的学习资料:
包含损失函数推导、梯度计算可视化及产业应用案例:
链接:https://pan.quark.cn/s/da4ae6566542
结语
损失函数不仅是数学工具,更是模型与业务场景的翻译器。理解其设计思想,比死记公式更重要。正如某算法工程师所言:
“当损失函数与业务目标对齐时,模型才能真正创造价值。”