论文阅读 2025-8-3 [FaceXformer, RadGPT , Uni-CoT]
最近ICCV 2025很多工作都release了,赶紧跟一波热度了解一下大家在做什么
1. FaceXFormer: A Unified Transformer for Facial Analysis
这篇论文的主要创新点在于设计了新的网络结构,使得模型能够在9个face analysis相关的task上得到比较好的结果。
网络结构设计上的创新:
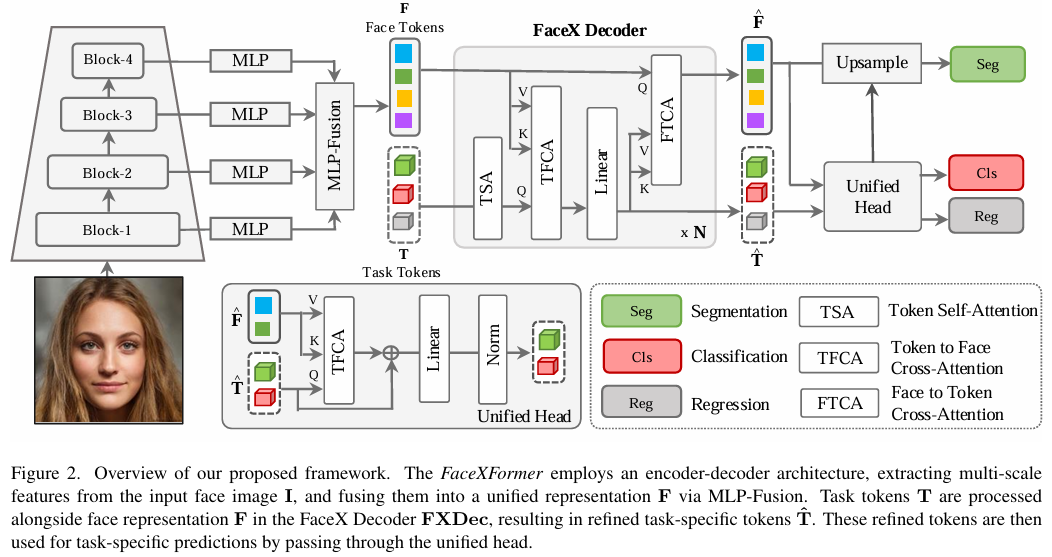
(1) 多尺度编码器
这个部分就是左侧的4个clock,金字塔一样的结构,明显使用CNN来构建,假设就是普通Unet吧,论文没说。
作者认为多尺度的信息有帮助“例如,年龄估计需要全局表示,而面部解析则需要细粒度表示。”
然后MLP-Fusion就是参考了SegFormer网络结构的设计, 从多尺度特征 {Si}n i=1 生成融合的面部表示。
(2)FaceX Decoder
参考了DeTr的工作,为每一个任务设计了任务Token,然后设计了FaceX Decoder,来完成后面的不同任务,这一步只是将face token 和 task token 进行交叉注意力机制来进行更深层次的特征交互,后续这里得到的高纬度特征还是需要经过不同的任务头。
(3)任务头,不同任务采用不同的任务头部网络:
- 关键点检测任务使用沙漏网络(hourglass network)
- 头部姿态估计任务使用回归MLP
- 年龄、性别、种族、表情、可见性以及属性预测任务则使用分类MLP
对于面部解析任务,我们利用输出F̂,先通过上采样层进行处理,然后与面部解析token进行叉乘操作,从而获得分割图。不同任务使用的token数量如下:
- 分割任务:token数量对应总类别数 (估计还是使用Unet的结构反向解码)
- 关键点预测:68个token(对应68个面部关键点)
- 头部姿态估计:9个token(表示3×3旋转矩阵)
- 其他任务:每个任务使用1个token
但是说实话,其实这个FaceXformer也就是把一些任务做细了。跟 Faceptor 相比,也就是多了 头部姿态估计(Head Pose Estimation) 和 面部可见性(Face Visibility) 分析这两个任务。
然后他的loss损失就是每一个任务的loss加权加起来,具体加权看代码。
2. RadGPT & AbdomenAtlas 3.0
这是一个放射学腹部CT的数据集和大模型的工作。
提出了一个1200+患者的一个CT数据集,然后训练了一个GPT来生成报告。
3. Uni-CoT: Towards Unified Chain-of-Thought Reasoning Across Text and Vision
这篇好像是基于Bagel做的,但是Bagel是近期的5月的模型,所以也是很新的工作。
因为视觉思考很费token,所以作者设计了一个马尔科夫链的一个决策推理模型。

作者的分析和观察以及解决方法如下:

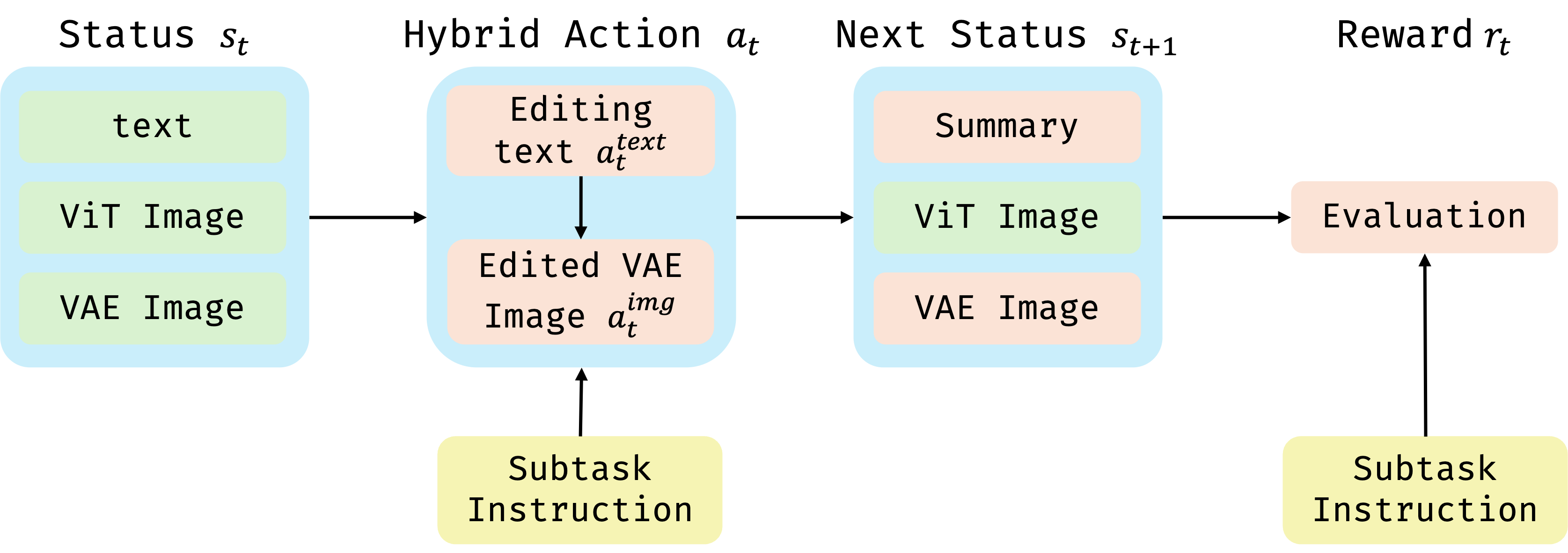
具体来说,模型的思考过程有4个stage,其中subtask可以有很多个,然后每一个状态节点可以被考虑成之前的所有文本+当前的图像(不知道是不是所有图像都输入,不然token也太多了吧,看了一下好像只有原始的图像以及当前的edit image):

这个是他设计的马尔科夫链的流程:
具体状态转移明显就是让bagel来生成下一步的图片以及summary,然后再给他一个奖励。
这个明显很不好做,因为不像GRPO一样很快地给出奖励(如果累积到最后面,那么梯度都要爆炸了,或者显存都要爆炸了)。