DeepPHY Benchmarking Agentic VLMs on Physical Reasoning
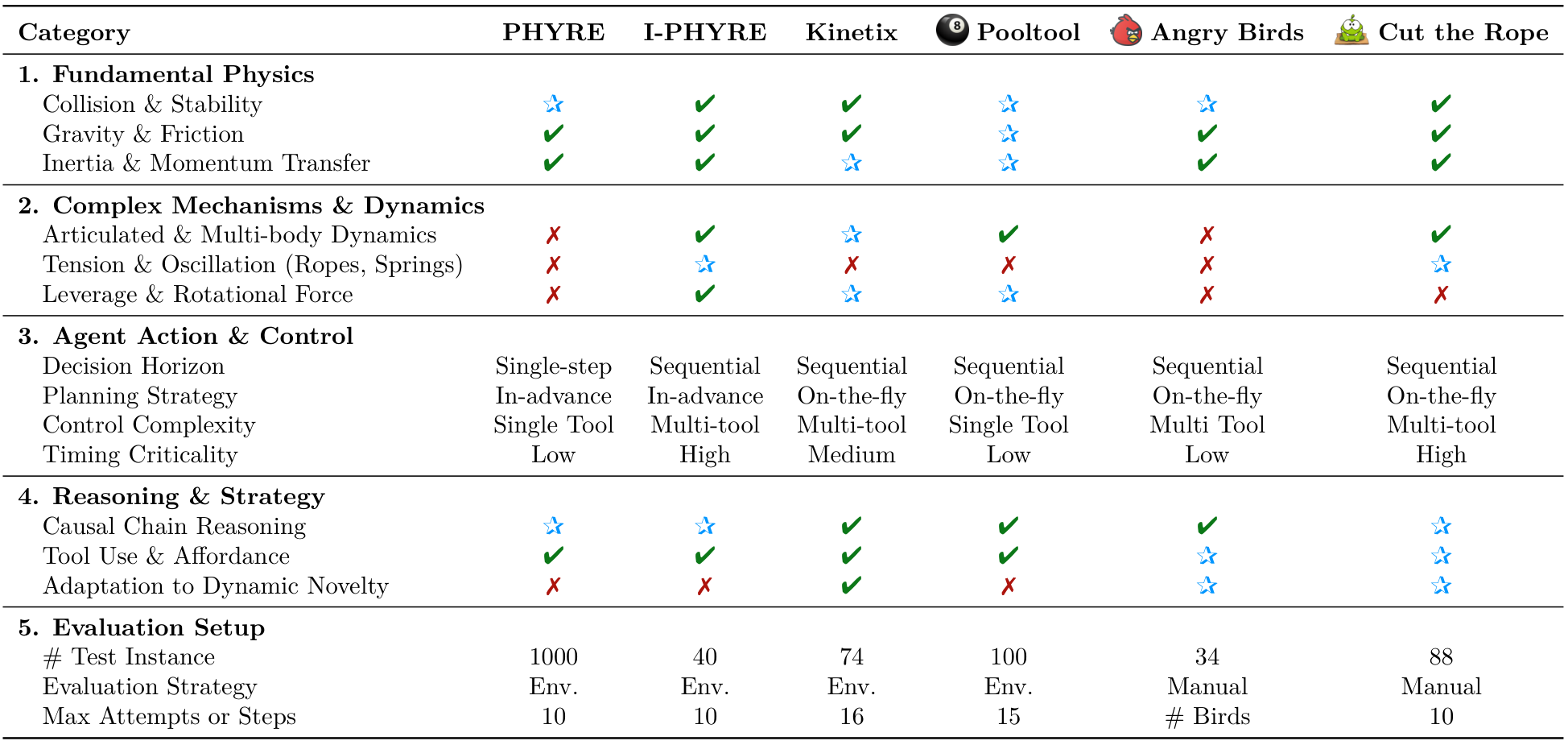
DeepPHY: Benchmarking Agentic VLMs on Physical Reasoning
Authors: Xinrun Xu, Pi Bu, Ye Wang, Börje F. Karlsson, Ziming Wang, Tengtao Song, Qi Zhu, Jun Song, Zhiming Ding, Bo Zheng
Deep-Dive Summary:
1 引言
视觉语言模型(VLMs)在静态视觉内容理解任务中展示了卓越的成果 [1, 2]。在此成功基础上,将这些模型应用于动态、交互式视觉环境(包括游戏 [3]、图形用户界面 [4, 5] 和具身人工智能 [6])已成为一个重要的研究前沿。然而,当前的基准测试和环境在模拟物理交互的真实性和复杂性方面存在显著局限性。游戏环境 [7-9] 通常提供高层次的观察/动作空间和简化的物理机制,绕过了对低层次物理推理的需求。图形用户界面环境 [10, 11] 并不基于现实世界的物理,具有离散、非连续的动作。而具身人工智能环境 [12-14] 主要关注语义层面的交互,通常过度简化了物理动态。这种对复杂物理现象建模的不足限制了智能体学习动作与长期物理后果之间深层因果关系的能力。为了解决这一差距,我们提出了 DeepPHY,一个强调智能体通过持续交互感知和理解其动作物理后果的基准测试。
DeepPHY 系统地集成了六个具有挑战性的基于物理的模拟环境:PHYRE [15]、IPHYRE [16]、Kinetix [17]、Pooltool [18] 以及游戏《愤怒的小鸟》和《割绳子》。这些环境此前从未被整合用于基准测试智能体 VLMs。这一集成集合与现有的 LLM 物理推理基准形成鲜明对比,后者主要通过静态问答格式或基于文本的物理问题评估物理推理能力 [19-22]。DeepPHY 则将智能体沉浸在交互式沙盒中,成功的关键在于执行动作并理解其随时间变化的物理后果。通过从不同环境策划这些多样化的挑战,我们创建了首个专门致力于评估智能体 VLMs 交互式物理推理能力的全面基准测试。
通过这项工作,我们旨在揭示当前 VLMs 的局限性和核心缺陷。我们在 DeepPHY 套件上进行的广泛评估揭示了它们在复杂物理交互、长程规划和动态适应方面的局限性。本文的主要贡献包括:
- 我们推出了 DeepPHY,首个系统评估智能体 VLMs 交互式物理推理能力的全面基准测试套件。
- 我们开发了一个统一的框架和标准化指标,将不同的物理模拟器转化为一个严谨且易于访问的测试平台。该平台评估 VLMs 并收集交互数据,有助于训练更具物理现实感的 AI 智能体。
- 我们对领先的开源和闭源 VLMs 进行了广泛的实证研究,提供了明确的基准线,并揭示了它们在物理交互、规划和适应方面的局限性。
3.1 问题形式化
我们将DeepPHY中的物理推理挑战形式化为一个基于试验的决策过程。任何单次尝试的底层环境是一个部分可观察的马尔可夫决策过程(POMDP),表示为 M=(S,A,T,R,Ω,O)M = (S, A, T, R, \Omega, O)M=(S,A,T,R,Ω,O),其中 SSS 是潜在的物理状态,AAA 是单步动作空间,RRR 是一个仅在最终任务成功时给予的稀疏奖励。智能体被允许最多进行 KKK 次尝试来解决给定任务,每次尝试总是从相同的初始观察 OinitialO_{\text{initial}}Oinitial 开始。核心挑战不仅是找到解决方案,而是从失败的尝试中学习。我们将其建模如下:令 k∈{1,…,K}k \in \{1, \dots, K\}k∈{1,…,K} 为尝试索引。单次尝试或试验会产生一个轨迹 τ(k)\tau^{(k)}τ(k)。
- 对于提前规划环境(例如PHYRE),智能体基于 OinitialO_{\text{initial}}Oinitial 和过去的历史提交一个完整的动作计划 a(k)a^{(k)}a(k)。由此产生的轨迹是一个包含计划及其结果的元组:
KaTeX parse error: Expected 'EOF', got '\right' at position 78: …m{\scriptsize~x\̲r̲i̲g̲h̲t̲|}\right.\mathr…
其中 γ(k)\gamma^{(k)}γ(k) 表示成功或失败的结果(111 表示成功,000 表示失败)。
- 对于即时规划环境(例如Kinetix),智能体与环境进行顺序交互。轨迹包含完整的交互序列,最终以最终奖励结束:
τ(k)≡(O0(k),O0(k),O1(k),O1(k),O1(k),∗⋅,OT(k),r(k))\tau^{(k)}\equiv\left({\cal O}_{0}^{(k)},{\cal O}_{0}^{(k)},{\cal O}_{1}^{(k)},{\cal O}_{1}^{(k)},{\cal O}_{1}^{(k)},\ast\cdot,{\cal O}_{T}^{(k)},r^{(k)}\right) τ(k)≡(O0(k),O0(k),O1(k),O1(k),O1(k),∗⋅,OT(k),r(k))
其中 O0(k)=OinitialO_0^{(k)} = O_{\text{initial}}O0(k)=Oinitial,r(k)r^{(k)}r(k) 是在最终观察 OT(k)O_T^{(k)}OT(k) 后收到的最终奖励。
在每次新的尝试 kkk 开始时,智能体可以访问之前所有失败试验的历史记录,H(k)={τ(1),τ(2),…,τ(k−1)}H^{(k)} = \{\tau^{(1)}, \tau^{(2)}, \dots, \tau^{(k-1)}\}H(k)={τ(1),τ(2),…,τ(k−1)}。为了成功,智能体必须利用这一历史来优化其内部世界模型 fphyf_{\text{phy}}fphy,并改进其规划。第 kkk 次尝试的计划生成策略 π(k)\pi^{(k)}π(k) 可以表示为:
π‾(k)=argmaxπ∈ΠV(fphy(π∣Oinitial,H(k)))\overline{{\pi}}^{(k)} = \mathrm{argmax}_{\pi \in \Pi} V(f_{\text{phy}}(\pi | O_{\text{initial}}, H^{(k)})) π(k)=argmaxπ∈ΠV(fphy(π∣Oinitial,H(k)))
其中 Π\PiΠ 是所有可能计划的空间(可以是单个动作或序列策略)。函数 fphy()f_{\text{phy}}()fphy() 现在表示智能体模拟候选计划 π\piπ 结果的能力,不仅基于初始观察,还基于过去失败的历史 H(k)H^{(k)}H(k)。价值函数 V()V()V() 估计模拟结果成功的可能性。这一形式化突显了DeepPHY从根本上评估智能体通过跨试验更新其预测模型 fphyf_{\text{phy}}fphy 进行迭代改进和从失败中学习的能力。
3.2 环境
DeepPHY 集成了以下环境:
PHYRE [15]:PHYRE 提供了一套二维物理推理任务,要求智能体在有限的尝试次数内,通过在场景中放置互动物体来触发正确的物理连锁反应,从而实现指定的目标。详见附录 B。
I-PHYRE [16]:I-PHYRE 是一个动态演变的互动物理推理基准,智能体需要通过在精确的时间点以正确顺序移除障碍物来解决谜题。详见附录 C。
Kinetix [17]:这是一个为智能体设计的开源二维物理仿真平台,生成大量且多样的物理控制任务,涵盖从机器人运动和抓取到经典控制问题的各种场景。详见附录 D。
Pooltool [18]:这是一个高保真的台球仿真基准,精确建模多体碰撞、旋转效应以及摩擦引起的轨迹变化。详见附录 E。

Angry Birds:这是一个基于物理的益智游戏,智能体需要策略性地发射小鸟以摧毁复杂的结构(如木材、石头、冰块),通过精确的力量和角度计算,消灭指定的目标,并引发大规模连锁反应以高效解决谜题。详见附录 F。

Cut the Rope:智能体需要在精确的时刻切割绳子并与其他道具(如气泡和垫子)互动,以引导糖果到达一个名叫 Om Nom 的小绿色怪物。详见附录 G。
3.3 观察空间
DeepPHY 的主要目标是评估智能体的物理推理能力,而不仅仅是感知定位。为此,我们对每个环境的观察空间进行了重构和增强,提供了清晰的标注图像渲染,显示互动物体的位置和身份,从而最大程度地减少目标检测的负担。这种设计使智能体专注于理解物理动态和规划操作,从而更具针对性地评估其物理推理能力。这种增强在基准套件中以不同的方式实现:
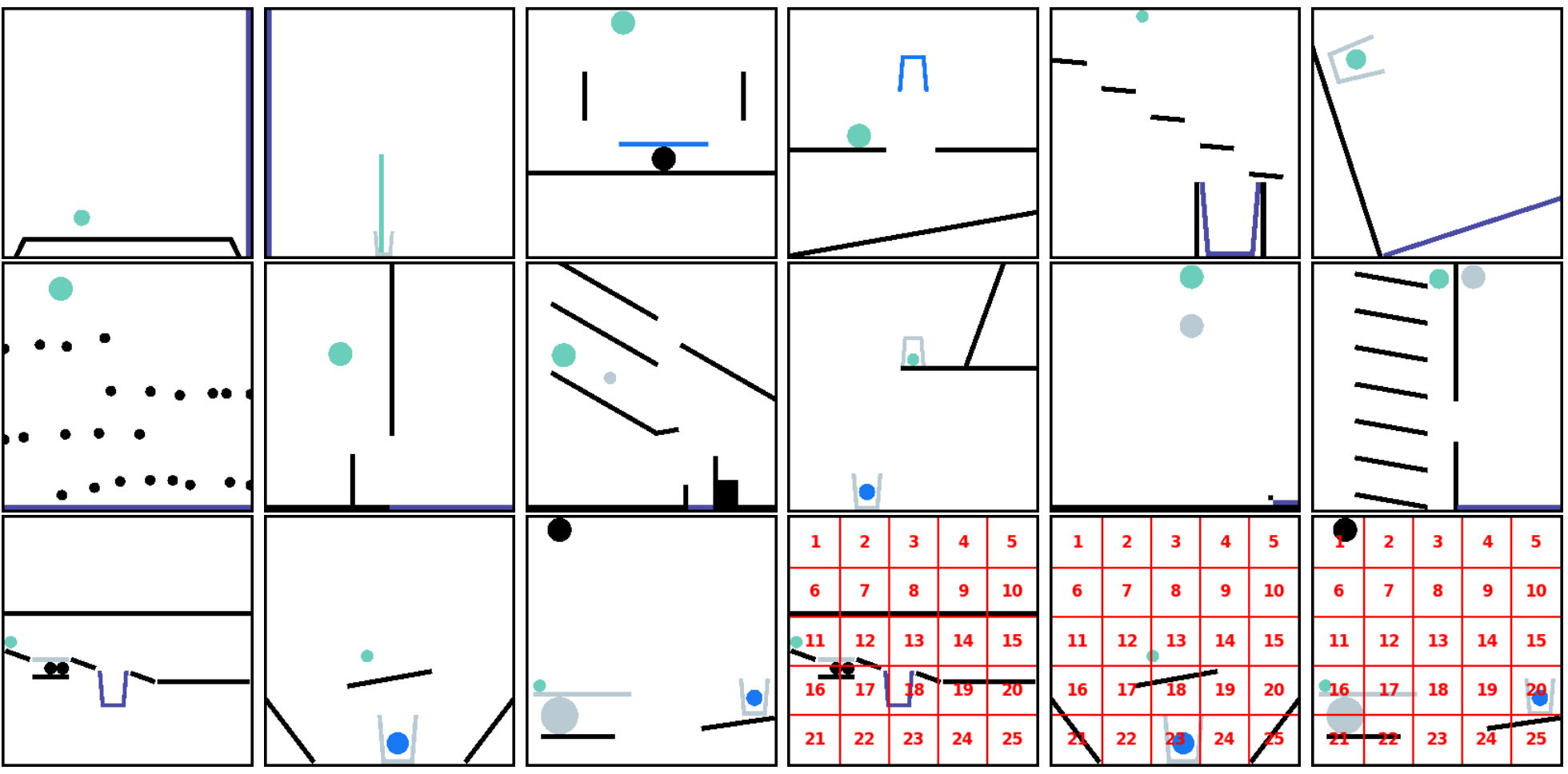
网格和标注覆盖:视觉场景可选地覆盖网格或数字 ID。在 PHYRE 中,场景上叠加了一个 5x5 网格,用于离散化物体放置位置。在 I-PHYRE、Kinetix 和 Cut the Rope 中,互动元素标注有数字标签。
维度降低:对于 Pooltool,原生的三维环境被转换为更适合视觉语言模型(VLM)的二维俯视图,简化了视觉信息并使空间关系更加清晰。
直接视觉输入:在 Angry Birds 中,观察空间由游戏的原始截图组成,显示结构和目标(猪),没有明确的标签和可用小鸟的文本信息。
通过提供这些修改后的观察,DeepPHY 确保核心挑战仍然集中在理解和预测物理动态上。
3.4 动作空间
当前视觉语言模型(VLMs)在未经过专门预训练或针对代理控制进行微调的情况下,面临的一个核心挑战是它们在连续空间中生成动作时的表现不佳。在自由形式的文本响应中指定精确的坐标、力或角度往往不可靠。为了解决这一问题,DeepPHY 所有环境的一个共同原则是将连续或复杂的动作空间转换为离散和结构化的格式。这种转换针对每个环境进行定制,以保留其核心物理挑战,同时使 VLMs 的交互变得更加可行。这一策略至关重要,因为现有游戏通常是为人类设计的,人类可以提供及时且精确的模拟反馈。对于 VLMs,尤其是在零样本(zero-shot)设置下,这些离散和结构化的动作空间使任务变得可处理。
不同环境在整个套件中的实现方式各不相同,展示了多种离散化方法:
-
离散化参数空间:在 PHYRE 环境中,原本可以在任意 (x, y) 坐标放置球并选择任意半径的连续动作,被转换为从 25 个网格单元中选择一个,并从 5 个半径级别中选择一个。类似地,在 Pooltool 环境中,代理从一小组预定义的命名选项中选择击球力量(3 个选项)和旋转类型(9 个选项),从而抽象掉了指定连续力和偏移值的需要。
-
整数到命令的映射:在 Kinetix 环境中,代理输出一个简单的整数向量。每个整数映射到相应电机或推进器的特定动作。这允许通过简单、结构化的输出实现多个组件的协调控制。
-
结构化命令语言:对于涉及多种交互类型的游戏,如《愤怒的小鸟》和《割绳子》,我们设计了预定义的 Python 代码。在《愤怒的小鸟》中,代理必须生成带有角度和力量参数的发射命令——
shoot(angle, power)。在《割绳子》中,代理生成的动作如cut_pin(Index)、pop_bubble(Index)等。这为代理提供了一套强大但受限的交互方式。 -
结构化数据格式:在 I-PHYRE 环境中,代理输出一个 JSON 列表,其中每个对象指定一个块的索引及其移除的精确时间,从而实现复杂的定时动作序列。
Table 2 提供了 DeepPHY 基准套件中每个环境的观察和动作空间转换的总结。
4 评估协议
(原文未完整提供评估协议的具体内容,因此此处仅保留标题以保持结构一致性。)
4.1 评估设置
我们旨在保持评估设置的简单性和跨环境的一致性。在每次交互的时间步长中,智能体被提示根据其与环境的过去交互历史输出下一步行动。为了在DeepPHY中表现出色,模型必须展示强大的指令遵循能力,包括读取视觉观察场景和解释环境规则,理解动作空间,推断物理原理,并产生有效的行动以有效完成任务。
规划策略。我们根据决策过程将环境分为两种不同的交互范式:
- 提前规划(In-advance Planning):智能体需要从初始状态开始制定完整的解决方案计划。如果失败,智能体将收到失败反馈,并在下一次尝试中生成全新的完整计划。这种设置测试智能体的全面因果推理和预见能力。
- 即时规划(On-the-fly Planning):需要与环境进行顺序的、逐回合的交互。在每一步,智能体输出一个单一动作,观察即时的物理后果,并根据新状态决定下一步动作。这种模式评估智能体的持续观察、动态适应和反应控制能力。
提示格式。我们使用了两种提示策略:
- 视觉-语言-动作(Vision-Language-Action, VLA):模型接收环境规则、当前视觉观察以及失败尝试的历史记录,然后直接输出一个动作。
- 世界模型(World Model, WM):在VLA提示的基础上,还要求预测模型选择的动作将导致的环境变化。
评估指标。我们使用了三个主要指标:
- 成功率(Success Rate):成功解决任务的比例。
- Pass@K:在最多K次尝试内解决任务的比例。
- 平均尝试次数(Average Attempts):仅针对成功试验,解决任务所需的平均交互尝试次数。
4.2 模型
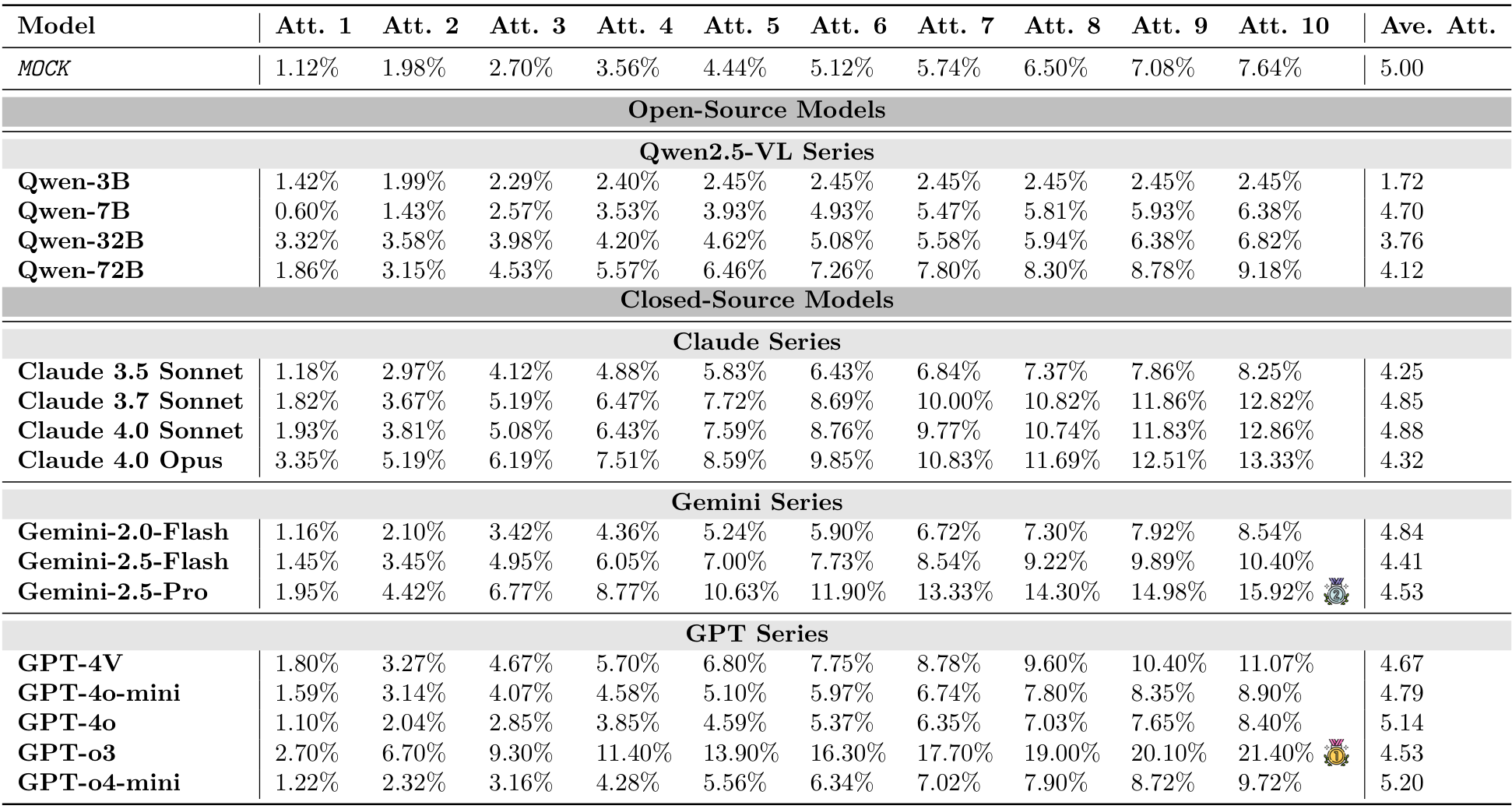
我们评估了17个流行的开源和闭源模型,详细信息见表4。开源模型包括Claude 4.0 Opus [38, 39];Gemini-2.0-Flash、Gemini-2.5-Pro-06-17和Gemini-2.5-Flash-06-17 [40, 41];以及GPT-4-Vision-Preview、GPT-40-mini-0718、GPT-4o-0806、GPT-03-0416和GPT-04-mini-0416 [42-44]。此外,还包括一个执行随机动作的MocK模型作为基线。
5 实验结果
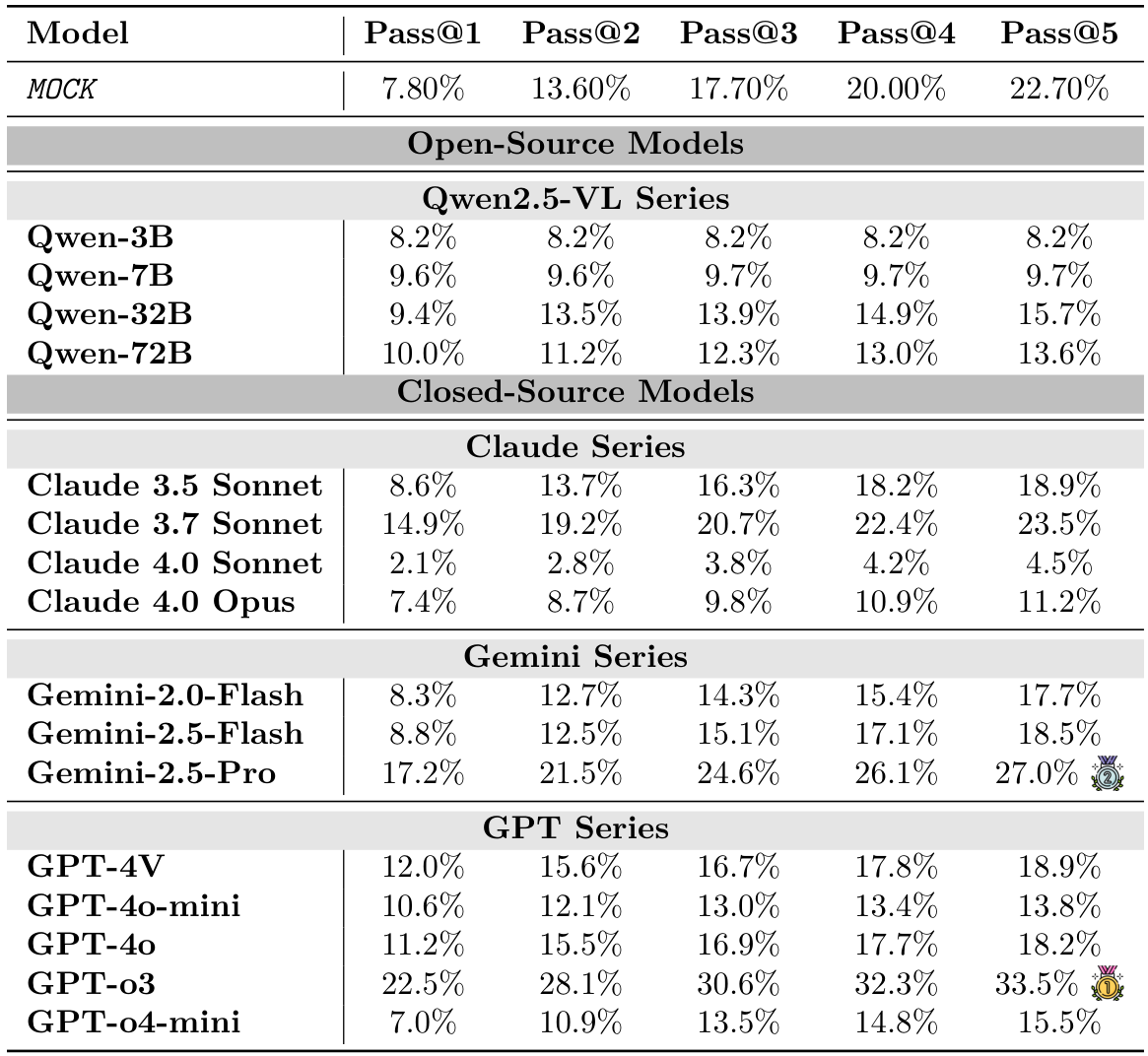
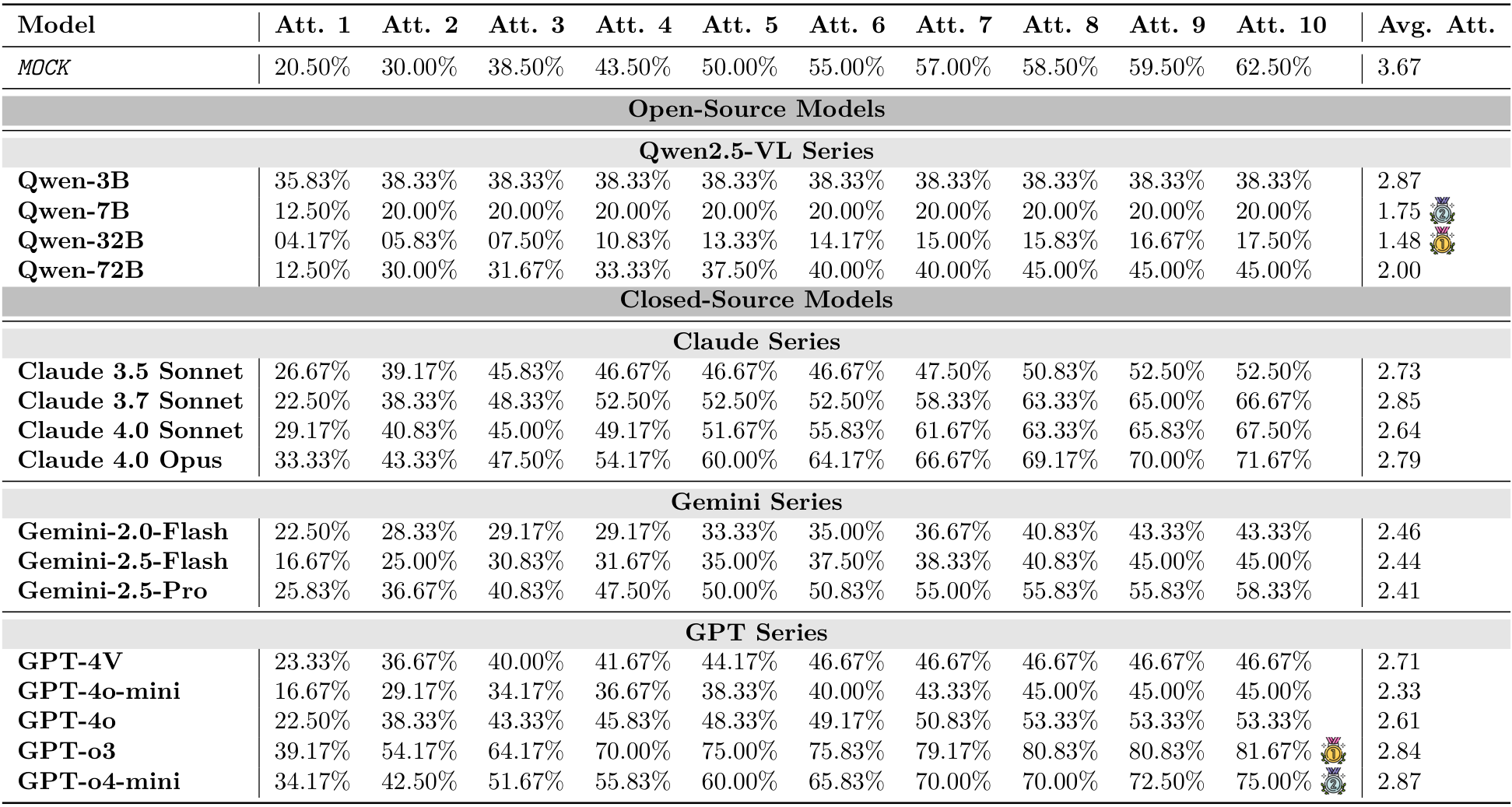
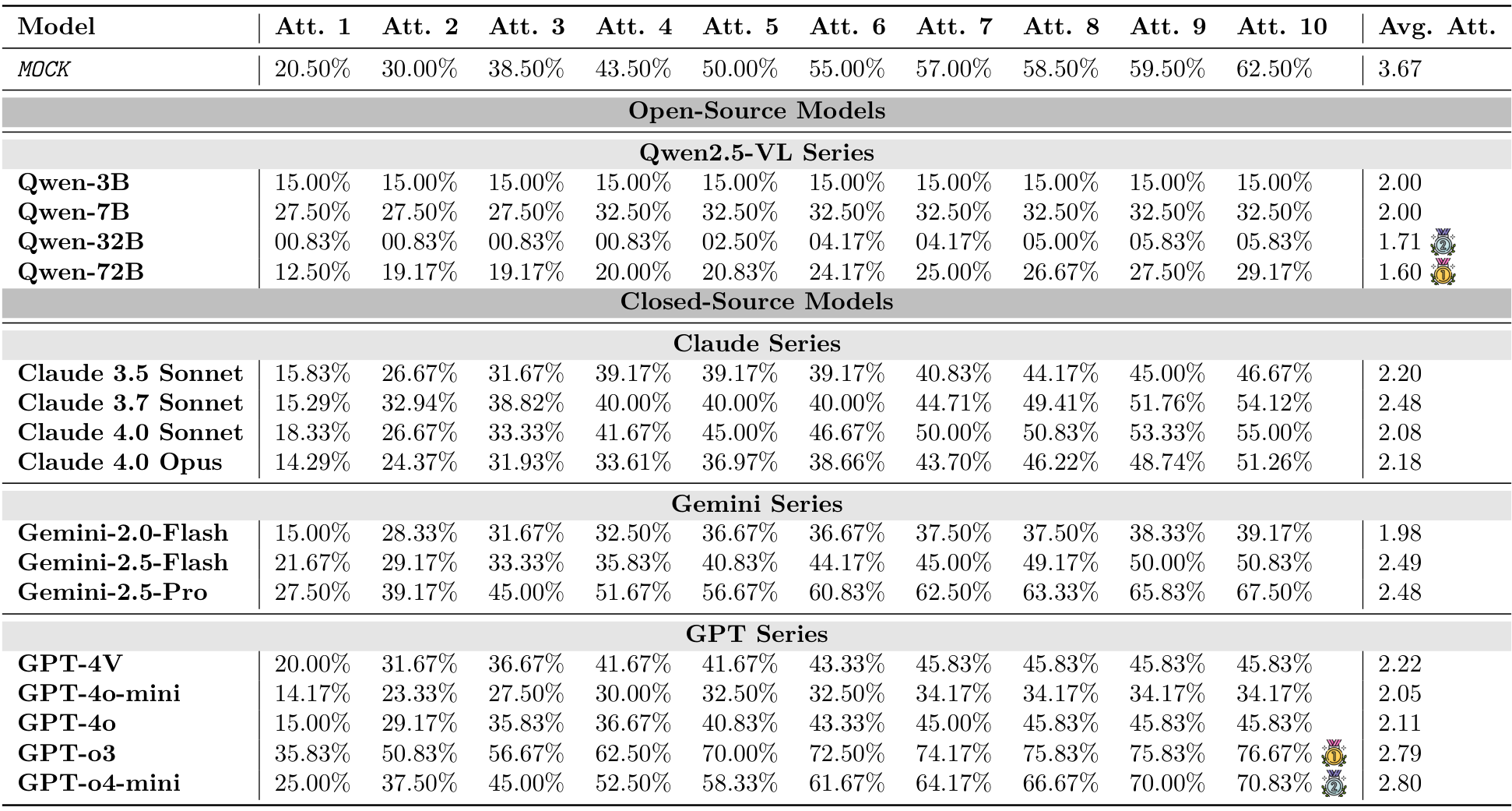
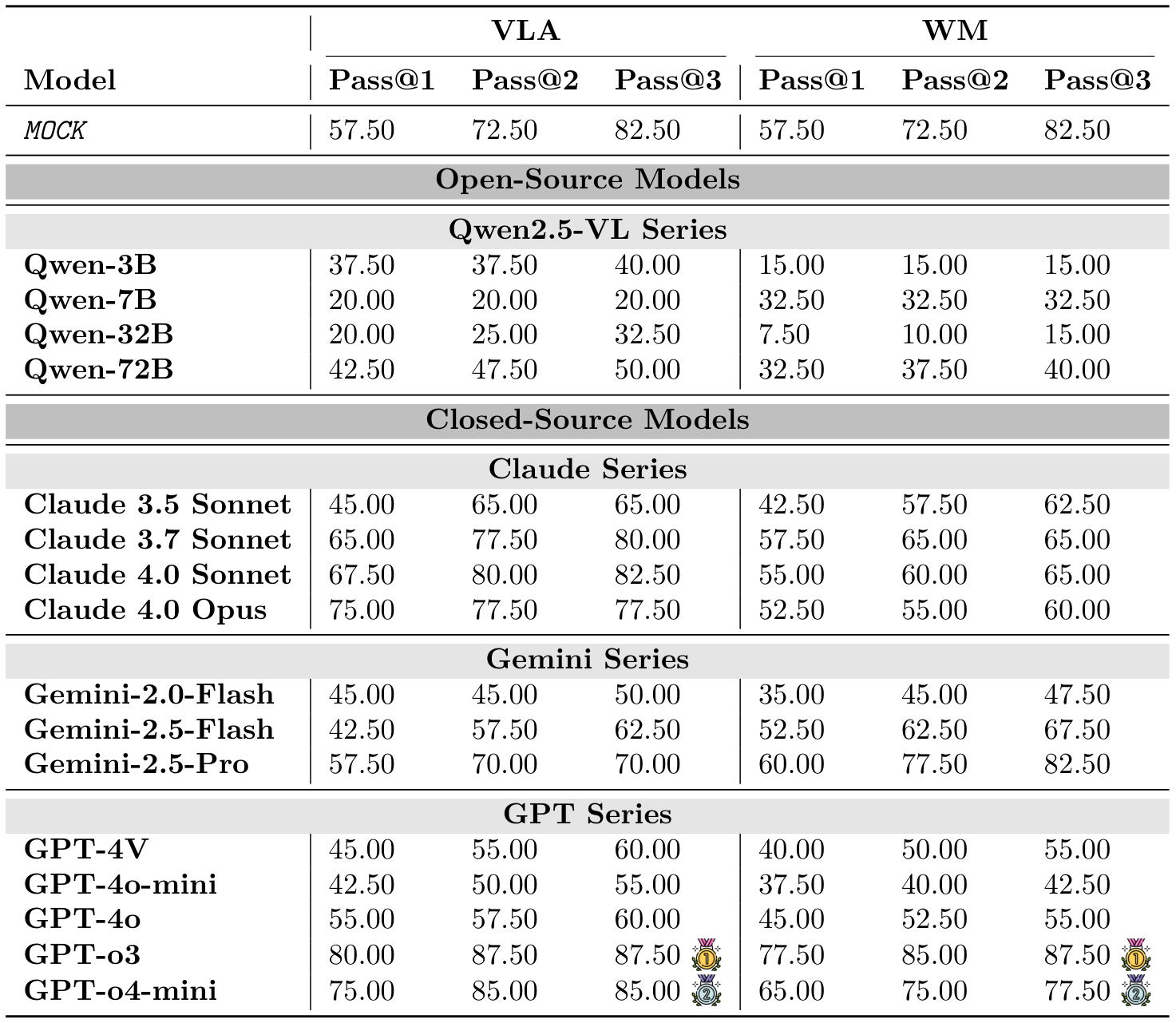
在此,我们在DeepPHY上评估了所有视觉语言模型(VLMs),以确立其零样本基线性能。我们报告了在不同物理环境下,温度设置为0.1的情况下,经过3次运行的成功率、Pass@K和平均尝试次数。
5.1 总体性能分析
实验结果表明,当前的视觉语言模型(VLMs)在交互式物理推理任务中面临重大挑战。如图2、图3以及表3所示,大多数模型(尤其是开源模型)即使在为VLMs设计的简化动作空间下,仍无法超越MocK结果。这表明模型缺乏对底层物理原理的深刻理解以及零样本规划能力。在所有测试模型中,最新的旗舰闭源模型(例如GPT-o3、Gemini-2.5-Pro和Claude 4.0 Opus)凭借先进的架构在物理推理能力上有所提升。然而,所有模型在不同环境中的表现各异,关键是与人类的表现相比存在显著的性能差距。模型的成功率远低于理想水平,这凸显了在实现物理智能方面仍有很长的路要走。
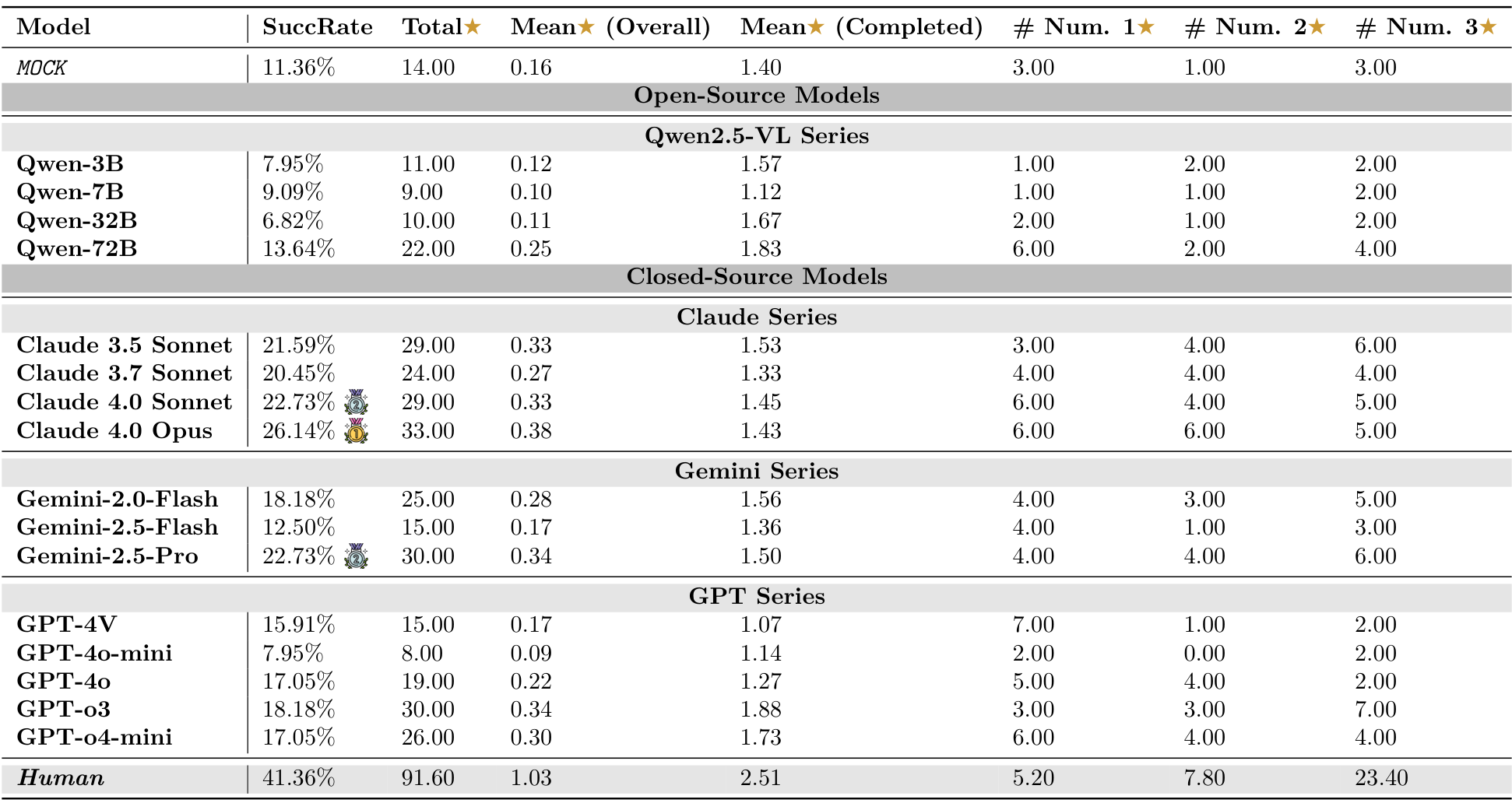
Table 3: Model performance summary across Pooltool, Angry Birds, and Cut the Rope. Stars (★) in AngryBirds are based on fewer launches and greater building destruction, while in Cut the Rope, they are collectedduring gameplay. and denote the highest model scores in each environment (besides Human).
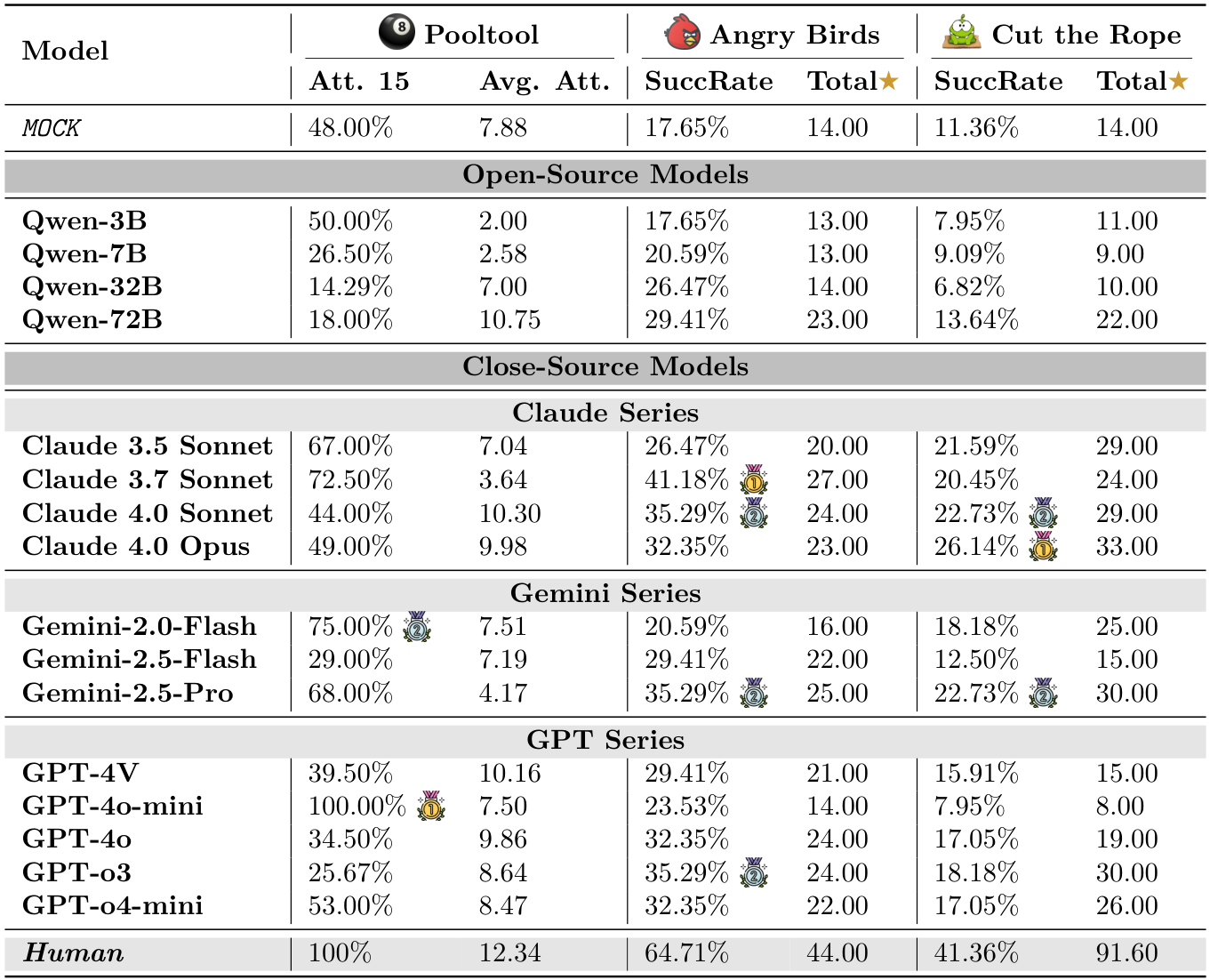
5.2 按环境的详细分析
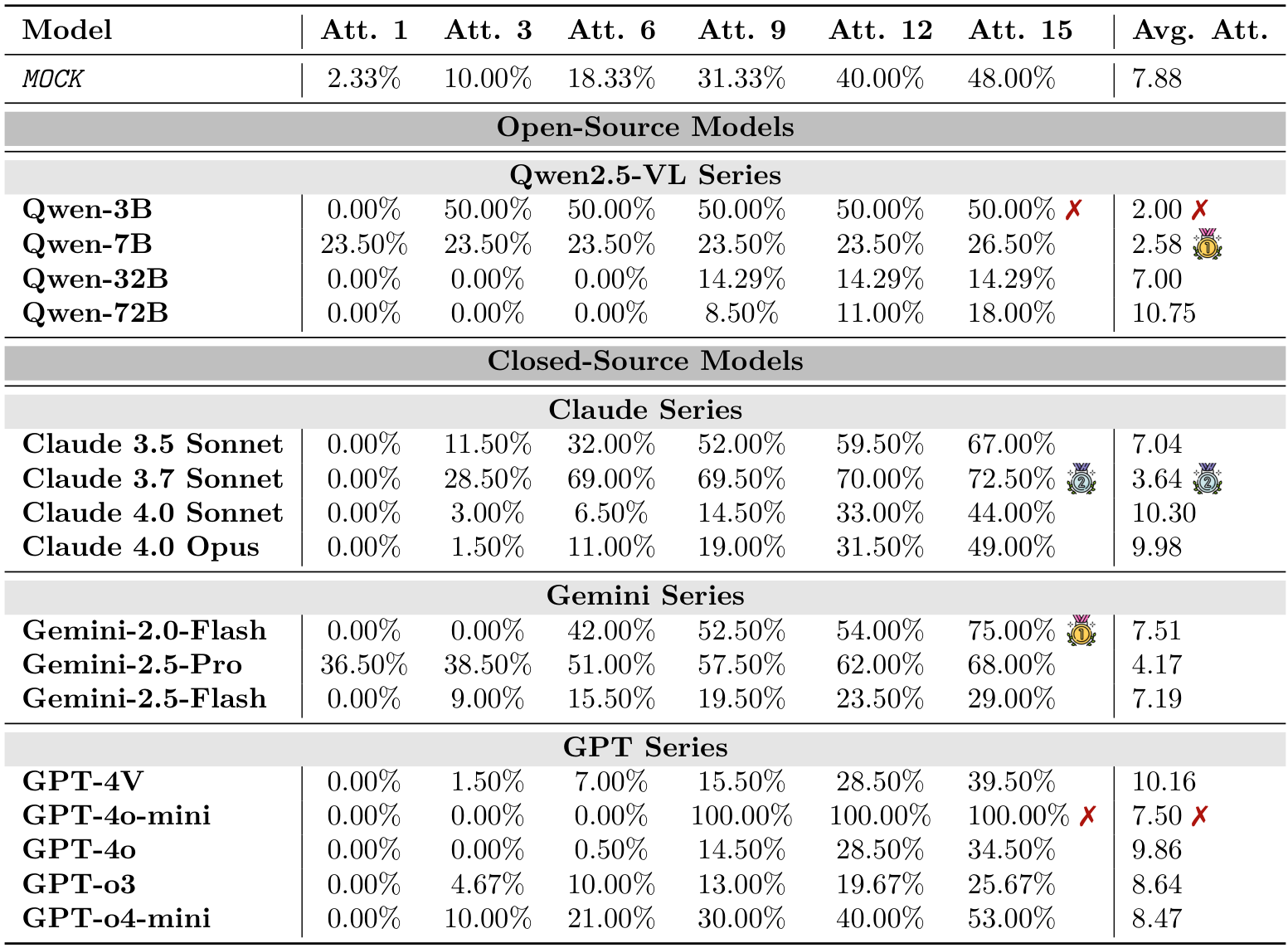
PHYRE:即使是最先进的模型,在第一次尝试时的成功率通常低于4%(见图2,以及附录B中的表6和表7)。虽然随着尝试次数的增加,成功率有所提高,但提升速度较慢,这表明模型难以从失败的尝试中有效学习并相应地调整策略(最佳成功率仅为23.1%)。
I-PHYRE:在这一环境中,领先模型如GPT-o3表现出相对较高的成功率,在第10次尝试时达到81.67%(见图2,以及附录C中的表10和表11),显示出这些模型在时间规划和因果推理方面的能力。然而,开源模型在这一环境中的表现仍然较差,成功率低于MocK基线。
Kinetix:随着任务难度的增加,模型的成功率显著下降(见图3,以及附录D中的表14和表15)。视觉标注的效果好坏参半。在简单的S级任务中,标注帮助模型识别可控组件并提升性能。然而,在更困难的M级和L级任务中,这种优势消失甚至对性能产生负面影响,特别是在使用WM提示时。这表明在更难的任务中,额外的标签成为一种认知干扰。此外,WM提示也未能提供帮助,常常降低成功率。这揭示了视觉语言模型(VLM)无法从视觉输入中形成准确的世界模型的局限。
Pooltool:如表3所示(更多细节见表16和表17),顶级模型(如GPT-4o-mini)取得了较高的成功率,有时甚至在平均步数上超越人类玩家。然而,深入分析表明,这种“效率”并非源于策略,而是来自一种“暴力试探法”。模型始终使用最大力量沿最直接路径将目标球击入口袋。这种策略在简单布局中有效,但忽略了核心技能:母球控制。我们的分析显示,没有一个测试模型在规划中使用复杂的物理学。例如,它们很少使用侧旋来改变角度,或使用上旋/下旋来控制母球以备下一杆。GPT-4o-mini的100%成功率因此具有误导性,这是确定性输出和非随机环境的结果。模型只是重复了偶然有效的暴力解决方案。
 # Angry Birds &
# Angry Birds &

Angry Birds & Cut the Rope:如表3所示(更多细节见表18和表19),在这些游戏中,所有模型与人类玩家之间存在巨大的性能差距。这暴露了模型的一个核心弱点。
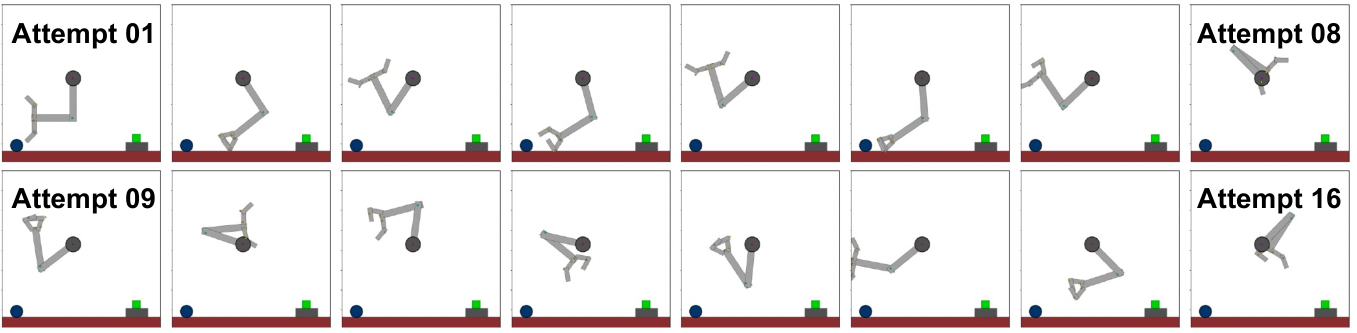 # Attempt 01:
# Attempt 01:
Prediction:机械臂将通过顺时针旋转其基座关节,向右开始摆动。同时,后续关节将开始展开并伸直,将手臂向下并朝绿色物体延伸。
Action: [1, 2, 2, 2, 2, 0]
Attempt 05:
Prediction:机械臂将伸展其段并旋转基座向右,使其末端执行器更靠近绿色物体。
Action: [1, 2, 2, 2, 2, 0]
论文总结(中文)
以下是对所提供论文片段的中文总结,保留了原文中的图像部分及其格式,并按照原文结构组织内容。
Attempt 12:
预测:机械臂将顺时针旋转其底座,并且其各段会展开,使末端执行器朝绿色物体移动。
动作:[1,2,2,2,2, 1]
- a sd
当前视觉语言模型(VLMs)的局限性:这些模型在处理需要精确时机的复杂多阶段物理任务时表现不佳。我们的设计为所有交互元素(如弹弓、绳索和气泡)提供了清晰的视觉标签,将挑战从低层次的感知转移到高层次的推理。尽管模型能够识别哪些元素是可交互的,但它们在动态物理过程的时空推理方面存在困难,大多数失败源于错误的时机或顺序。例如,在《割绳子》游戏中,模型可能会过早割断绳子,导致糖果无法获得足够的动量。在《愤怒的小鸟》中,模型难以规划能引发连锁反应的攻击顺序,无法理解一只鸟的撞击如何改变结构从而影响下一次攻击。这些系统性失败表明,当前模型无法为动态环境中的多步决策构建连贯的预测性内部世界模型。
5.3 提示格式的案例研究
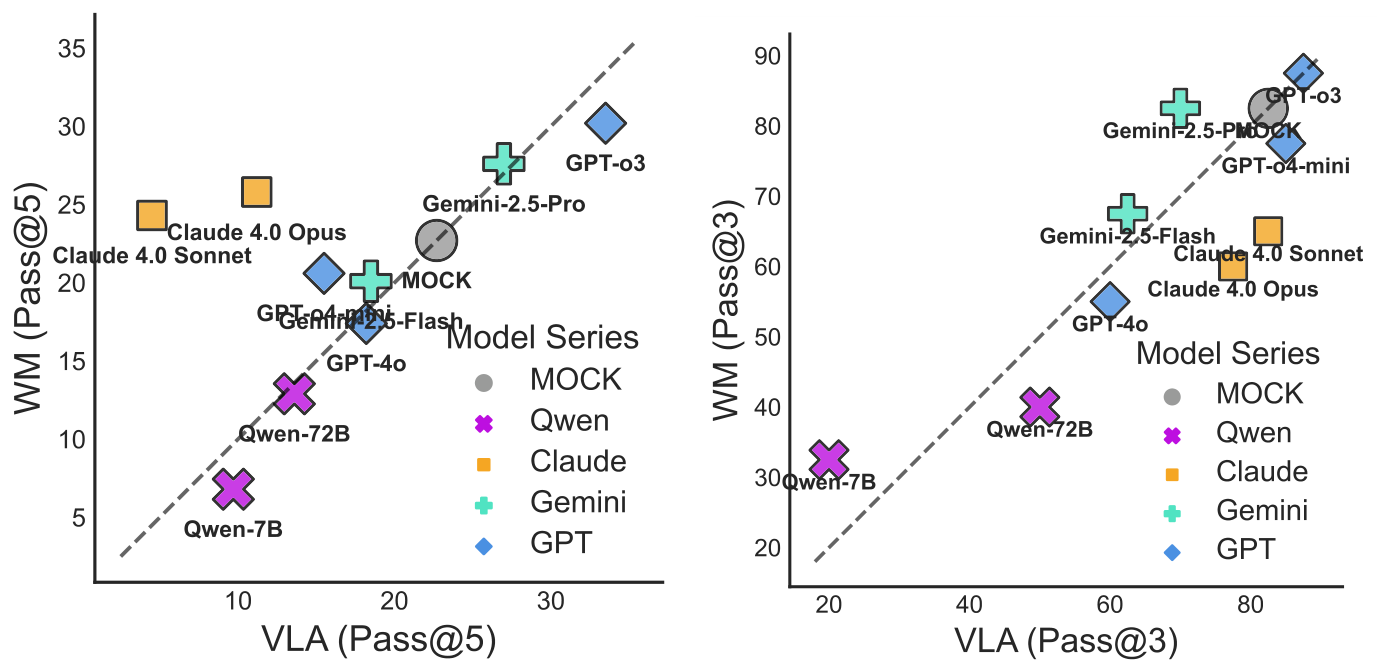
VLA 与 WM 提示格式的比较分析(见图 2、3 和 4)揭示了当前代理型视觉语言模型(VLMs)的内在局限性。在所有环境中,我们发现 WM 方法目前仅在较简单的任务(如 PHYRE/I-PHYRE)中提供有限的好处。强制进行预测可能有助于模型在初始的“零历史”情境中避免纯粹的随机探索,但这种优势非常脆弱,随着复杂性的增加会迅速消失。事实上,在更复杂的任务中,WM 往往成为一种负担。我们推测,当物理规划任务的内在难度已经将模型推向极限时,生成准确动态预测(WM 任务)的额外需求会带来过多的开销。此外,当前模型的世界建模能力仍不成熟。值得注意的是,即使模型能够生成文本上正确的预测(如图 5 所示),提供对期望物理结果的准确描述,它们仍然无法将这种描述性知识转化为精确、可执行的控制信号来实现该结果。这凸显了模型对物理的理解主要是描述性的,而非真正具备预测性和程序性控制能力。
6 结论
在本文中,我们介绍了 DeepPHY,这是第一个全面评估视觉语言模型(VLMs)交互式物理推理的基准测试。我们的系统性评估揭示,即使是最先进的模型在动态环境中的精确多步规划方面也存在困难。我们发现模型在描述物理现象的能力与其利用该知识进行预测和控制结果的能力之间存在根本性脱节。我们发布了 DeepPHY 作为一个严格的测试平台,用于基准测试此类局限性,并促进开发更具物理基础的 AI 代理。
A 模型缩写
B Benchmark: PHYRE 总结 (中文)
PHYRE2 基准测试包含在一个模拟的二维世界中的物理谜题,并分为两个任务层级:PHYRE-B 和 PHYRE-2B。PHYRE-B 中的任务可以通过放置一个动态球来解决,而 PHYRE-2B 中的任务需要放置两个球。在实验中,选择了 PHYRE-B 层级进行测试。任务中的对象包括紫色(静态)球或蓝色(动态)球;黑色对象是静态的,灰色对象是动态的。PHYRE 的任务分布如表 5 所示。“Within-Template”设置测试对已见模板的新任务的泛化能力,而“Cross-Template”设置测试对完全未见模板的任务的泛化能力。由于我们的测试套件不涉及模型训练或微调,因此将“Within-Template”和“Cross-Template”设置的测试集合并(共计 1000 个任务)用于最终评估。

B.1 Conversion Details
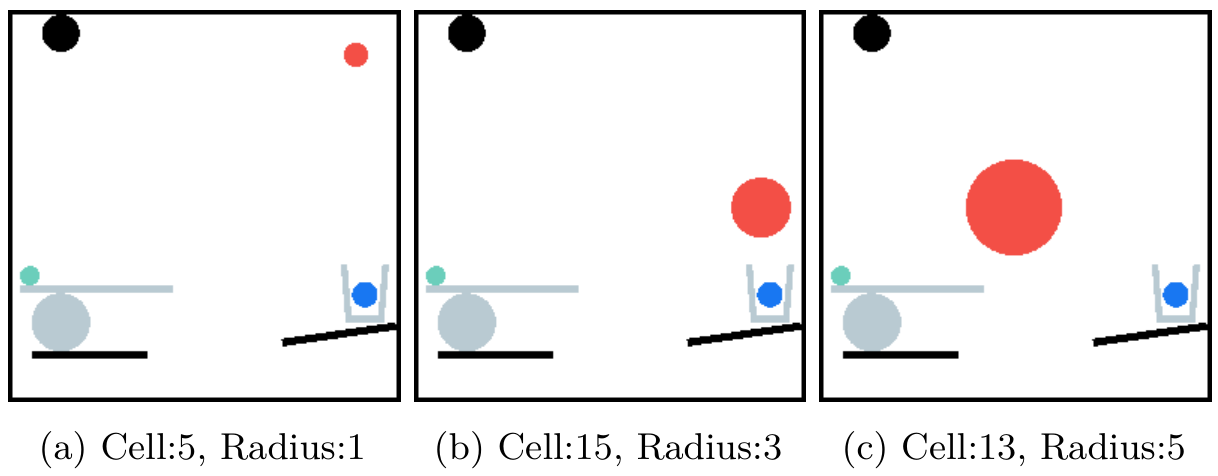
在 PHYRE 中,我们没有输出连续坐标(范围在 x,y∈[0,1]x, y \in [0,1]x,y∈[0,1]),而是将空间离散化为 {GRIDSIZE[0]×GRIDSIZE[1]}\{GRID_SIZE[0] \times GRID_SIZE[1]\}{GRIDSIZE[0]×GRIDSIZE[1]} 个均分的网格(如图 7 的最后 3 张图像所示)。代理 VLM 必须选择目标网格单元的中心作为对象放置位置,并指定离散的球大小级别(从 1 到 {RADIUSLEVELS}\{RADIUS_LEVELS\}{RADIUSLEVELS})(如图 6 所示)。在我们的实验中,通过定义一个 5×55 \times 55×5 的网格来离散化放置位置的动作空间,并为球的半径设置 5 个离散级别。
B.2 Prompts
PHYRE: System Prompt 总结 (中文)
PHYRE 的系统提示要求分析场景并确定新对象的单一最佳放置位置以实现特定目标。场景图例包括:红色球(你将放置的动态球)、绿色球(必须操作的主要动态对象)、蓝色球(动态目标)、紫色球(静态目标)、灰色球(其他动态对象)和黑色对象(静态障碍物)。任务目标是策略性地放置一个红色球以触发连锁反应,成功结果是绿色球与蓝色球或紫色球发生物理接触。动作参数包括:网格单元编号(从 1 到 {GRIDSIZE[0]×GRIDSIZE[1]}\{GRID_SIZE[0] \times GRID_SIZE[1]\}{GRIDSIZE[0]×GRIDSIZE[1]})和半径大小级别(从 1 到 {RADIUSLEVELS}\{RADIUS_LEVELS\}{RADIUSLEVELS})。放置约束包括无碰撞和边界内限制。输出格式必须严格遵循指定格式,例如:Cell: 13, Radius: 3。初始场景图像和带有网格的场景图像用于选择动作。
PHYRE:用户提示与实验结果总结
用户提示部分总结(中文)
在论文中,PHYRE 任务的用户提示部分详细描述了用户在解决物理谜题时的尝试过程。如果之前的尝试失败,系统会提供反馈,总结如下:
- 有效操作的反馈:如果用户上一次的操作是有效的,但未能解决谜题,系统会显示“尝试 {past_num}:您选择了(单元格:{past_cell},半径:{past_radius}),但未能解决谜题(FAILED)。”并展示该尝试的关键帧。
- 无效操作的反馈:如果上一次操作无效(例如超出边界或重叠),系统会显示“尝试 {past_num}:您选择了(单元格:{past_cell},半径:{past_radius}),这是一个无效操作(INVALID ACTION)。”
基于完整的历史记录和初始场景图像,用户需要分析错误并提出一个新的、更好的操作。系统要求用户必须提出一个全新的操作,不得重复之前失败尝试中的单元格和半径组合。用户需要仔细观察网格场景(图像 2’)进行放置,并记住半径的范围是从 1(非常小)到 {RADIUS_LEVELS}(大)。用户的回复格式必须严格为:“单元格:[数字],半径:[数字]”。
实验结果部分总结(中文)
在实验结果部分,研究表明所有测试模型在 PHYRE 任务中的总体成功率极低,凸显了任务的难度。即使是表现最好的模型 GPT-o3(提示格式:VLA),在 10 次尝试后的最终成功率也仅为 23.1%。开源模型(如 Qwen)的表现通常接近或低于 M0cK 基线,进一步强调了这一局限性。
此外,大多数模型在第一次尝试(Pass@1)时的成功率低于 4%(见表 8 和表 9)。这表明模型在提前规划方面存在显著弱点,即在没有任何先前交互历史的情况下,模型难以仅基于单一静态观察设计出完整且正确的解决方案。模型在很大程度上无法利用内化的物理原理来成功预测初始结果。
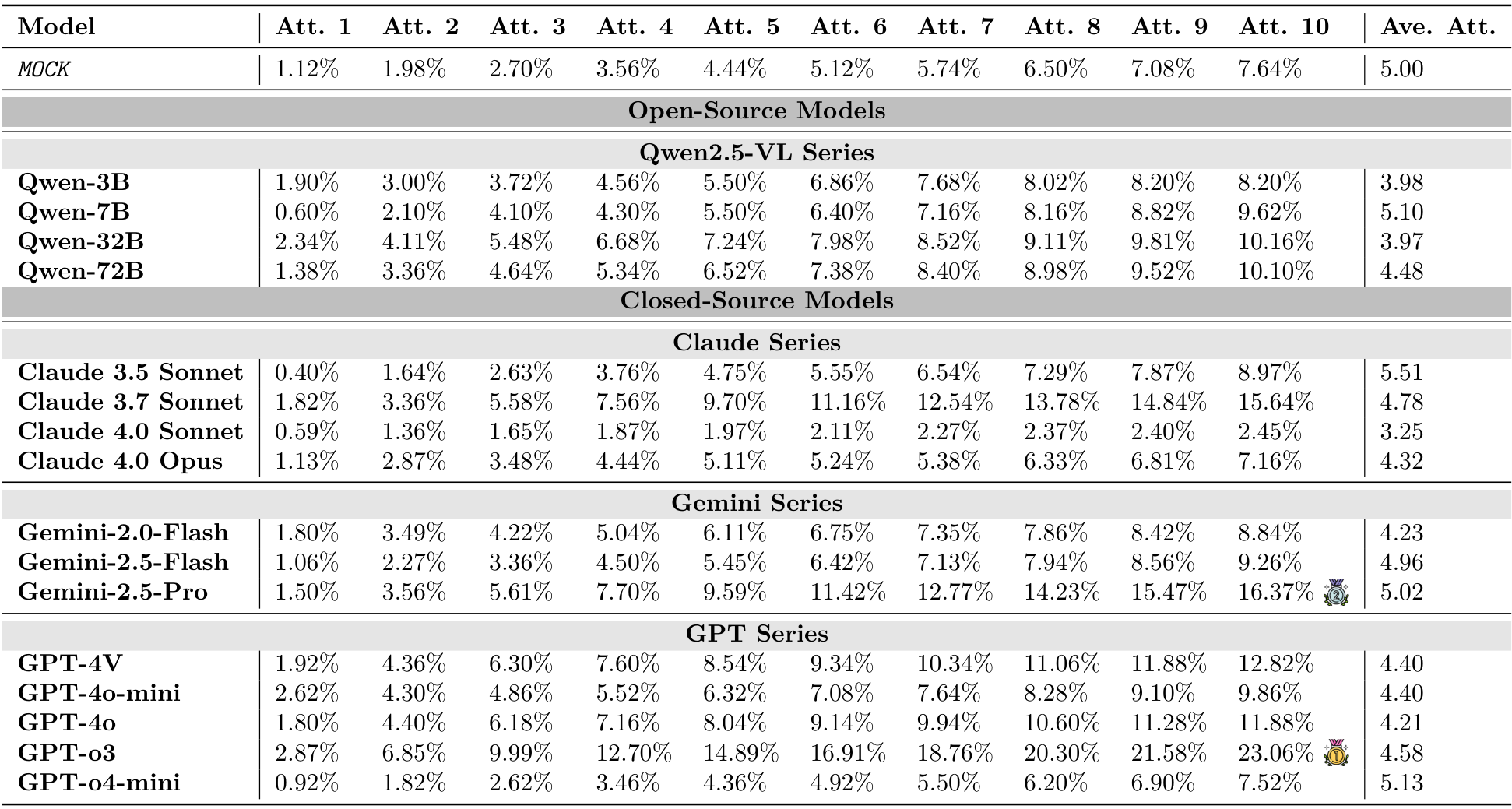
模型通常需要平均 4-5 次尝试才能取得进展(见图 2)。这表明失败轨迹的反馈(即看到错误操作的结果)不足以帮助模型构建一个准确且具有预测性的内部世界模型来指导后续决策。
通过提示策略的比较,发现了一个反直觉的结果:WM 策略在大多数模型中的表现持续低于更简单的 VLA 方法(见图 4(a))。虽然 WM 在早期尝试中加速了进展,但其收益在后续尝试中逐渐减少。大多数数据点落在等价对角线下方。这一发现揭示了一个根本性的脱节:即使模型能够描述潜在结果,这种描述性知识也无法转化为改进的操作控制。这与研究的主要结论一致,即当前的视觉语言模型(VLMs)仅具备描述性而非预测性和可控性的物理理解。

基准测试:I-PHYRE 部分总结(中文)
I-PHYRE 基准测试包含 40 个交互式物理场景,每个场景要求智能体引导红色球进入深渊。其唯一的交互机制是在特定时刻移除指定的灰色方块。不同任务环境中包含多种对象,以促进复杂的物理推理:静态黑色方块作为固定障碍物,动态蓝色方块响应重力和碰撞。为了进一步提升复杂性,引入了弹簧和刚性棒等元素,丰富了物理动态,确保成功完成任务需要超越琐碎的规划。
C.1 转换细节
在原始的 I-PHYRE [16] 评估中,GPT-4 未使用图像输入,而是采用了符号矩阵表示(如下图橙色框所示)。然而,在我们的实现中,我们引入了视觉输入。我们通过在原始 I-PHYRE 图像上添加数字索引来增强图像信息,以便于视觉语言模型 (VLM) 进行对象选择。图 8 展示了这一修改,上方一行显示了原始渲染场景,下方一行显示了带有索引的对应场景。
与原始方法一致,我们在评估中采用了“提前规划”策略,每轮最多允许 10 次尝试。
I-PHYRE:初始观察空间(纯文本)
在一个大小为 600×600 的模拟二维正方形世界中,包含若干对象。
对象配置数组如下(方块和球体均为对象):
对于方块:
- [xl, yl, x2, y2, radius, eli, dynamic, joint, spring]
- [xl, y1] 表示左端点,[x2, y2] 表示右端点。方块的高度(两倍半径)为 20。
对于球体:
- [x, y, x, y, radius, eli, dynamic, joint, spring]
- [x, y] 表示球的中心点,‘radius’ 表示球的半径。
eli:
- 0/1 表示相应对象是否可被消除。1 表示可消除,0 表示不可消除。
dynamic:
- 0/1 表示相应对象是否可通过外力移动。1 表示动态,0 表示静态。
joint:
- 0/1 表示相应对象是否连接到一根棒。1 表示已连接,0 表示未连接。
spring:
- 0/1 表示相应对象是否连接到一个弹簧。1 表示已连接,0 表示未连接。
以下是具体的对象配置字典:
[100. 400. 400. 400. 10. 0. 0. 0. 0.]
[200. 350. 210. 350. 10. 1. 0. 0. 0.]
[200. 300. 210. 300. 10. 1. 0. 0. 0.]
[480. 400. 550. 400. 10. 0. 0. 0. 0.]
[390. 350. 400. 350. 10. 1. 0. 0. 0.]
[390. 300. 400. 300. 10. 1. 0. 0. 0.]
[100. 380. 100. 360. 10. 0. 0. 0. 0.]
[550. 380. 550. 360. 10. 0. 0. 0. 0.]
[200. 280. 400. 280. 10. 0. 1. 0. 0.]
[260. 250. 260. 250. 20. 0. 1. 0. 0.]
[340. 250. 340. 250. 20. 0. 1. 0. 0.]
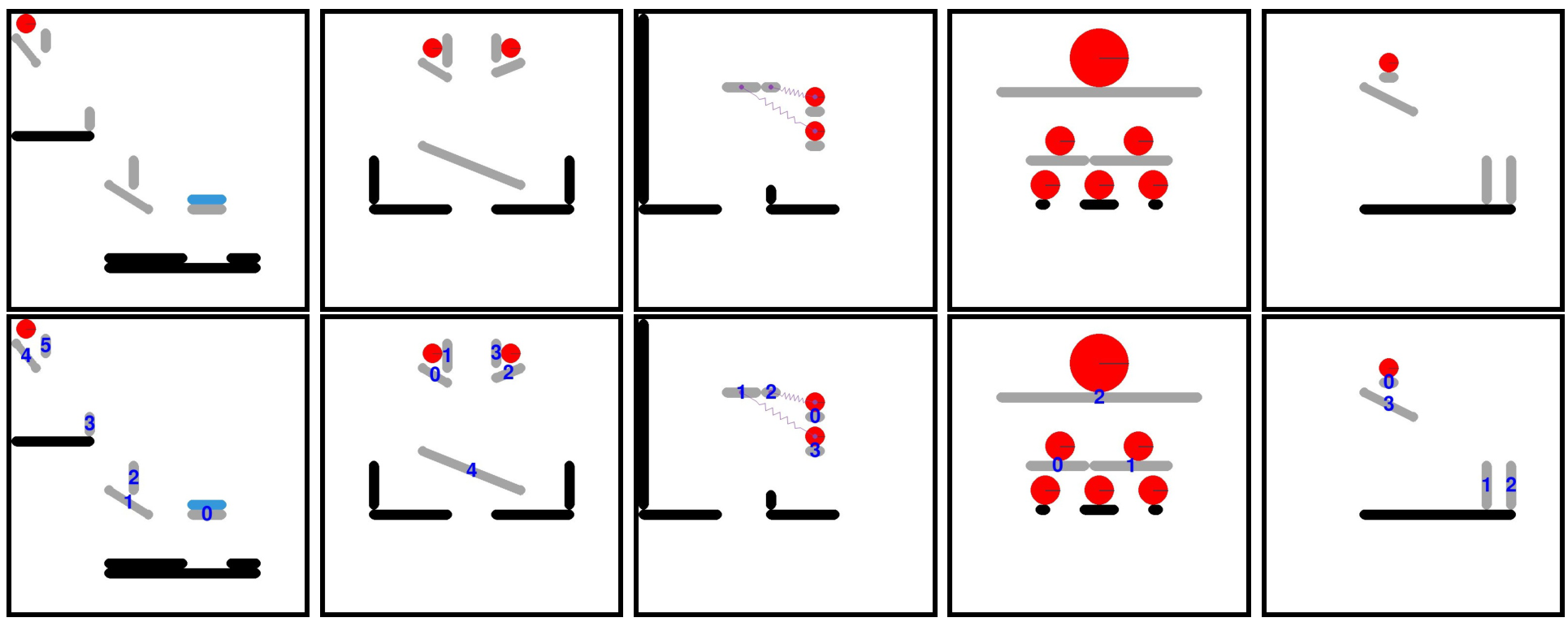
这使得 VLM 能够精确引用对象。
C.2 提示
I-PHYRE:系统提示
您是一位擅长通过策略性方块消除进行轨迹操控的二维物理谜题解决专家。您的目标是通过精确地定时移除指定的灰色方块(唯一可消除的对象),引导红色球体进入深渊。
游戏环境:
- 核心机制:
- 目标:将所有红色球体引导进入深渊
- 只有灰色方块可以被消除
- 静态方块(灰色/黑色)构成固定结构
- 动态蓝色方块受重力/物理影响(例如弹簧机制、刚性棒约束)
操作要求:
- 生成一个消除动作序列,以 JSON 数组形式表示
- 每个动作必须指定:
- ‘time’:执行时间戳(0.0-15.0 秒)
- ‘index’:目标方块在配置数组中的位置(0-{max_index})
- 在选择前核对框架中的方块编号
- 当前有 {num_blocks} 个灰色方块符合消除条件
输出规则:
- 严格遵守 JSON 语法
- 时间精度建议保留一位小数
输出格式:
[{"time": 0.5, "index": 2},{"time": 2.1, "index": 0}
]
I-PHYRE:用户提示
分析初始场景配置和框架,制定最佳的方块消除序列。考虑以下因素:
- 球的初始轨迹
- 方块移除时机的后果
- 每次消除引发的连锁反应
- 环境的物理约束
<initial_image> 图像
(第一次尝试后:)
之前尝试分析:
:来自尝试 {past_num}
论文总结(中文)
以下是对所提供论文内容的总结,重点涵盖了故障诊断、修订策略需求以及实验结果的部分内容。原始的图片部分按照原文格式保留在适当位置。
故障诊断
- 时间问题:
- 提前移除导致[特定影响]。
- 延迟移除导致[不良结果]。
- 顺序错误:
- 块优先级错误。
- 错过连锁反应机会。
- 物理计算错误:
- 轨迹不准确。
- 碰撞预测失误。
修订策略需求
- 避免所有先前失败的方法。
- 结合失败尝试中的运动学见解。
- 优化以实现最少动作。
- 考虑新观察到的物理行为。
提出一个结合这些经验教训的改进解决方案,改进后的动作序列如下:
C.3 实验结果
I-PHYRE 的实验结果与 PHYRE 中观察到的困难形成了有趣的对比,揭示了当前一代视觉语言模型(VLMs)的具体优势和劣势。与其他环境中的广泛失败不同,顶级模型在 I-PHYRE 中表现出色,展现了非凡的能力。
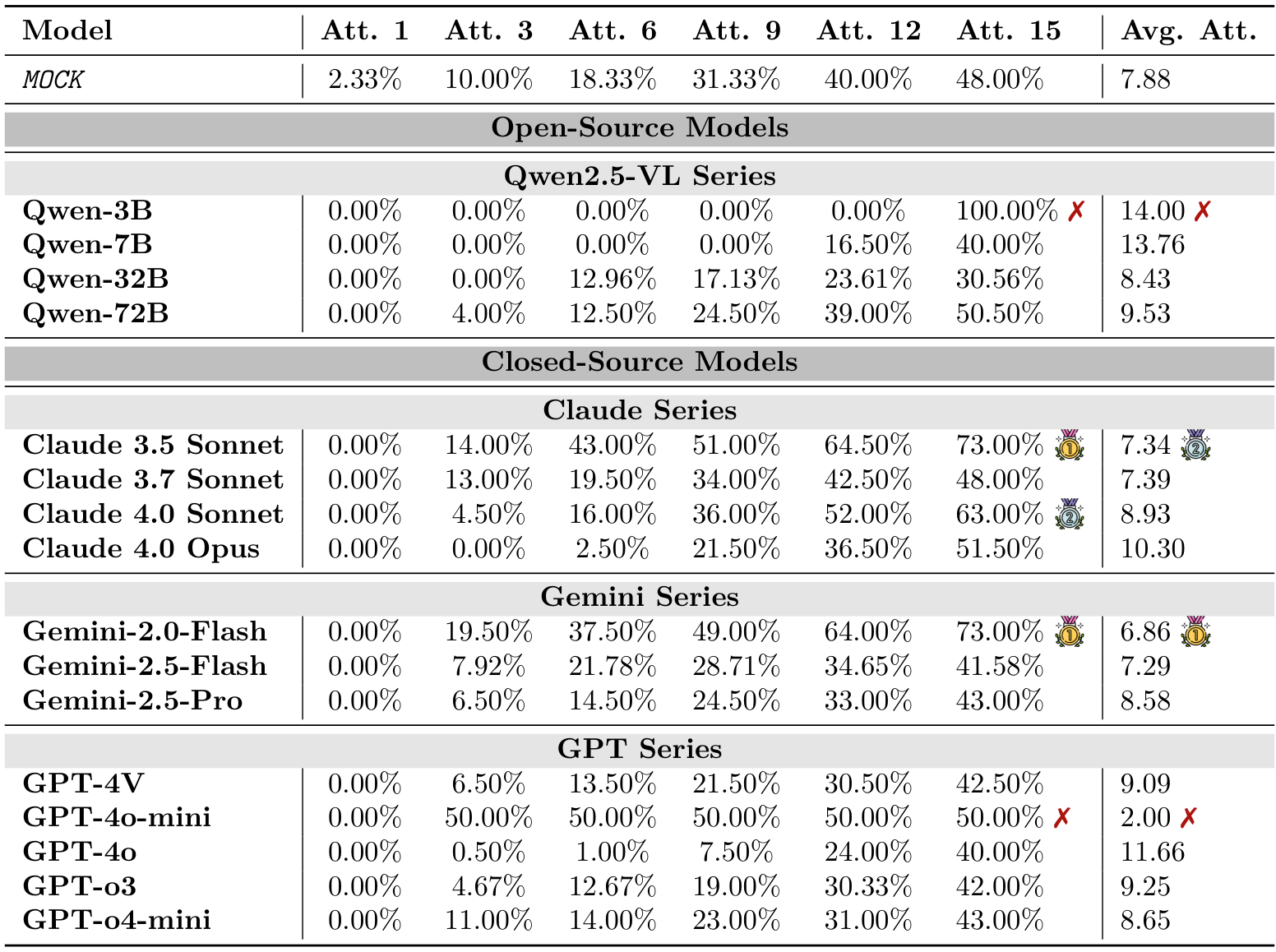
如图 2 所示及表 10 所详述,领先模型如 GPT-o3 在 10 次尝试内最终成功率可达 81.67%。类似地,GPT-o4-mini 和 Claude 4.0 Opus 也表现出较强的性能,成功率分别达到 75.00% 和 71.67%。这表明这些先进模型在时间规划和因果链推理方面具有显著能力。高成功率表明,当物理问题被框架化为结构化的顺序谜题时,VLMs 在逻辑和序列生成方面的潜在优势可以被有效利用。此外,成功模型的平均尝试次数相对较低(例如,GPT-o3 为 2.84 次尝试),这意味着它们能更高效地从失败尝试中学习并修正时间策略。
然而,I-PHYRE 也暴露了明显的性能差距。虽然最好的闭源模型表现出色,但我们测试的开源模型仍然面临重大困难。例如,Qwen 系列模型的性能持续远低于 MOCK(随机行动)基准线,Qwen-7B 的成功率仅勉强达到 20%。这种明显的失败表明,它们解析视觉场景并将其映射到结构化、时间敏感的行动计划的能力严重不足。因此,I-PHYRE 成为一个有效的区分工具,将具有强大顺序推理能力的模型与缺乏此关键能力的模型区分开来。
我们对提示格式的分析也为该环境得出了明确的结论。如图 4(b) 的比较图所示,WM 提示格式始终无法超越更简单的 VLA 格式。对于几乎所有高性能模型,数据点均位于等价对角线下方,表明 VLA 格式目前更优。例如,GPT-o3 的成功率从 VLA 格式的 81.67% 下降到 WM 格式的 76.67%。
这进一步印证了我们基准论文的一个核心发现:强迫模型生成物理结果的描述性预测并不一定会转化为更好的程序控制(至少在当前一代模型中是如此)。在 I-PHYRE 的背景下,预测复杂落块级联的认知负担可能会干扰生成正确定时 JSON 序列的更直接任务,从而导致性能下降。这进一步凸显了描述性理解与有效行动生成之间的脱节,以及在新一代模型中进行此类基准测试的必要性。
DBenchmark: Kinetix D 总结 (中文)
概述
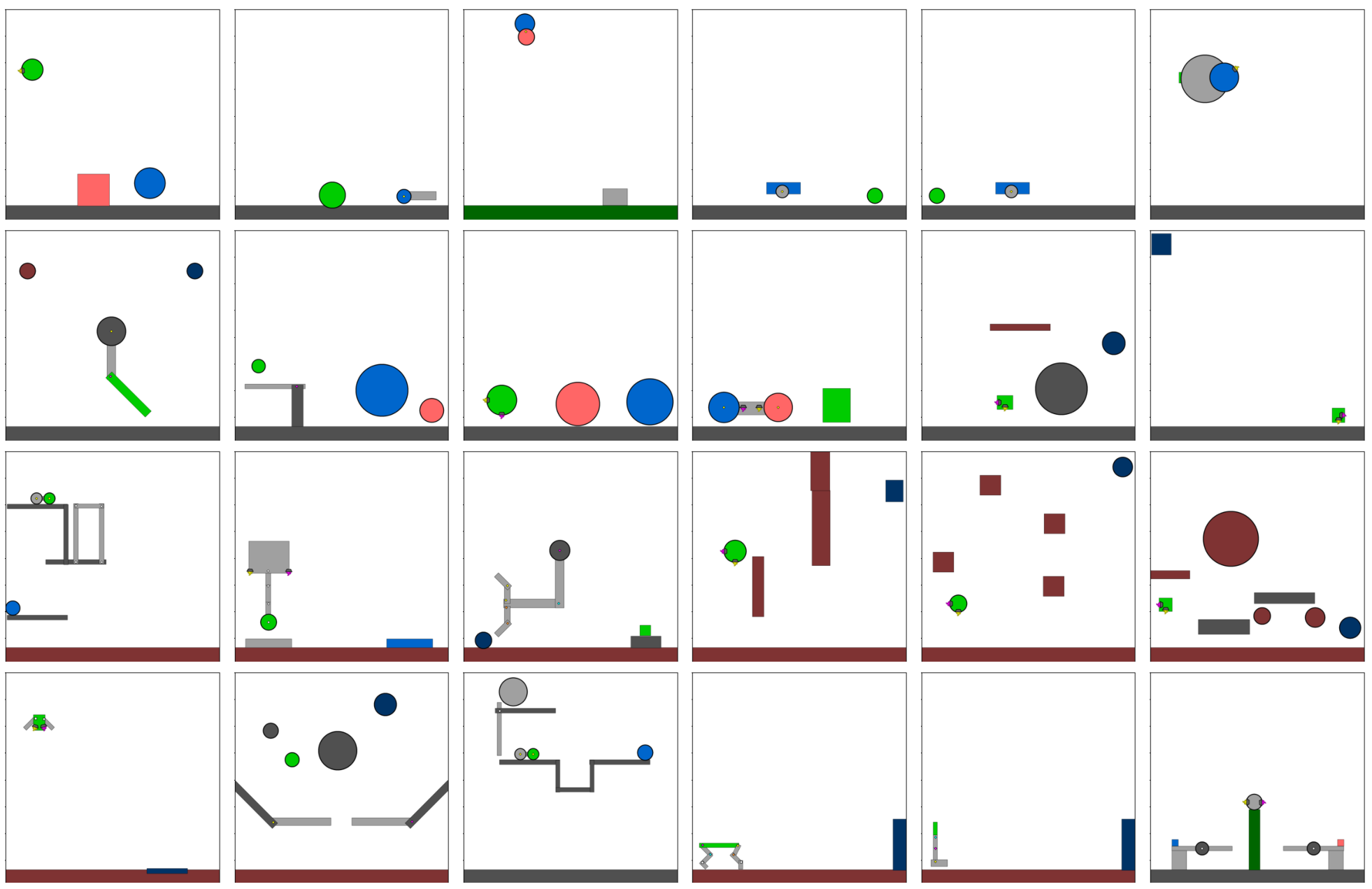
在 Kinetix 基准测试中,所有环境的目标是统一的,即让绿色方块接触蓝色方块,同时避免接触红色方块。每个环境最多包含四个可控电机(可正向/反向旋转以驱动连接的部件,如机械臂或轮子)和两个可控推进器。通过任意组合多边形、关节、电机和推进器,该基准测试生成了高度多样化的环境(例如,机器人移动、物体抓取、弹球游戏)。任务难度分为三个级别(如下图 9 所示):
- S (Small):基础物理谜题,测试智能体对单一控制的掌握(如推动/摆动)。
- M (Medium):复杂机制,需要协调控制多个电机/推进器。
- L (Large):系统性挑战任务,复现经典难题(如机器人行走),以评估高级规划和精细控制能力。
任务分布
- 训练:通过程序化采样的关卡(理论上无限,每个难度级别有数千万个关卡)。
- 测试:固定的手工设计关卡,形成一个可解释的测试集(S:10 个关卡,M:24 个关卡,L:40 个关卡),总计 10 + 24 + 40 = 74 个关卡。
D.1 转换细节
由于 Kinetix 最初并非为视觉语言模型(VLM)设计,其原生图像渲染的分辨率和清晰度不够理想。因此,我们重构了其观察空间,并升级了渲染流程以提高清晰度(如下图 10 所示),使 VLM 能够更准确地解析视觉信息。
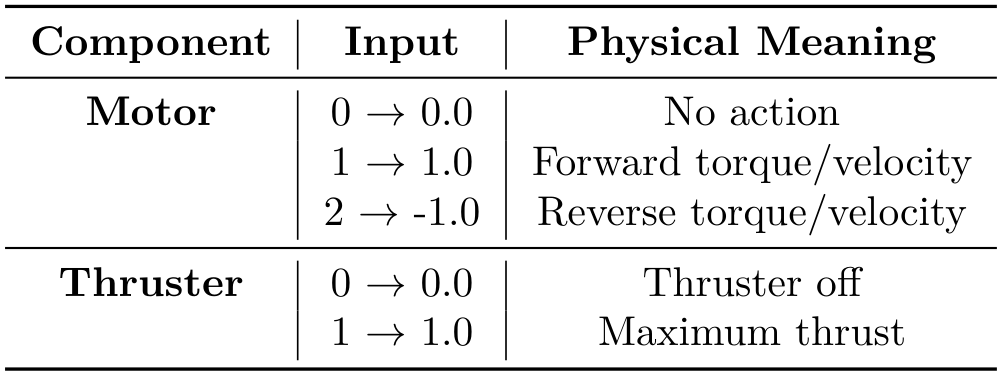
智能体通过定义的动作空间与环境交互,即 [a_motor, b_motor, c_motor, d_motor, a_thruster, b_thruster],每个组件的值为连续值,范围在 [-1, 1] 内。为了适应 VLM 的离散命令,我们建立了从离散整数输入到这些连续值的特定映射。根据表 13 的详细说明,对于电机,输入 0、1、2 分别对应无动作、正向扭矩和反向扭矩;对于推进器,输入 0 和 1 分别控制关闭和开启(最大推力)状态。
Kinetix 环境在时间上较为密集,最多有 256 个步骤。为了减轻 VLM 因步骤间变化微小而产生的困惑,我们引入了一个步骤扩展因子 step_times(实验中设置为 16),将每个步骤的物理仿真时长扩展为 step_times 倍。模型会获得过去 history_memory_steps 步的历史记录,在我们的实验中设置为 5。
D.2 提示设计
Kinetix: 系统提示
您是一个控制 2D 物理环境中实体的 AI 智能体。您的任务是生成一个长度为 {sum_actions} 的整数向量来控制标记的实体。您将获得当前场景的两张图像:一张干净的图像和一张带有可控实体标签的图像。
{
“summary”: “本文档部分介绍了动作向量的结构及其在Kinetix渲染管线中的应用。动作向量包含 {sum_actions} 个整数元素,其中前 {num_active_joints} 个元素对应于电机(标注为 {motor_labels}),后 {num_active_thrusters} 个元素对应于推进器(标注为 {thruster_labels})。对于电机和推进器,动作值分别定义为:‘0’ 表示无动作,‘1’ 表示正向旋转或正向推力,‘2’ 表示反向旋转。目标是使绿色物体接触蓝色物体,同时避免接触红色物体。文中还展示了渲染管线的改进,以提高视觉语言模型(VLM)的兼容性,通过重构渲染和添加明确标识(如 ‘MO’、‘T1’)来增强识别效果。历史记录包括过去 {history_memory_steps} 个视觉场景、对应的动作列表 {previous_action_list} 以及物体距离 {distance_list}。当前任务是输出一个包含 {num_active_joints} + {num_active_thrusters} 个整数的动作向量,格式为 ‘[int, int, …, int]’。”,
“content”: "
动作向量结构:
- 向量包含 {sum_actions} 个整数元素。
- 前 {num_active_joints} 个元素对应于电机,在标注图像中标记为 {motor_labels}。
- ‘0’: 无动作
- ‘1’: 正向旋转

- ‘2’: 反向旋转
- 接下来的 {num_active_thrusters} 个元素对应于推进器,在标注图像中标记为 {thruster_labels}。
- ‘0’: 无动作
- ‘1’: 正向推力
目标:使绿色物体接触蓝色物体,且绿色物体不得接触红色物体。
Kinetix:用户提示
以下是历史记录:过去 {history_memory_steps} 个视觉场景、对应的动作 {previous_action_list} 以及结果物体距离 {distance_list}。
目标:使绿色物体接触蓝色物体;绿色物体不得接触红色物体。
输出当前 {num_active_joints} + {num_active_thrusters} 维的动作向量。
格式:‘[int, int, …, int]’,包含 {num_active_joints} + {num_active_thrusters} 个整数。
"
}
D.3 实验结果
表14:Kinetix基准测试。模型性能比较。'w/o anno’条件使用重构图像,而’w/ anno’条件在可控实体上提供额外的数字标签(如图10所示)。
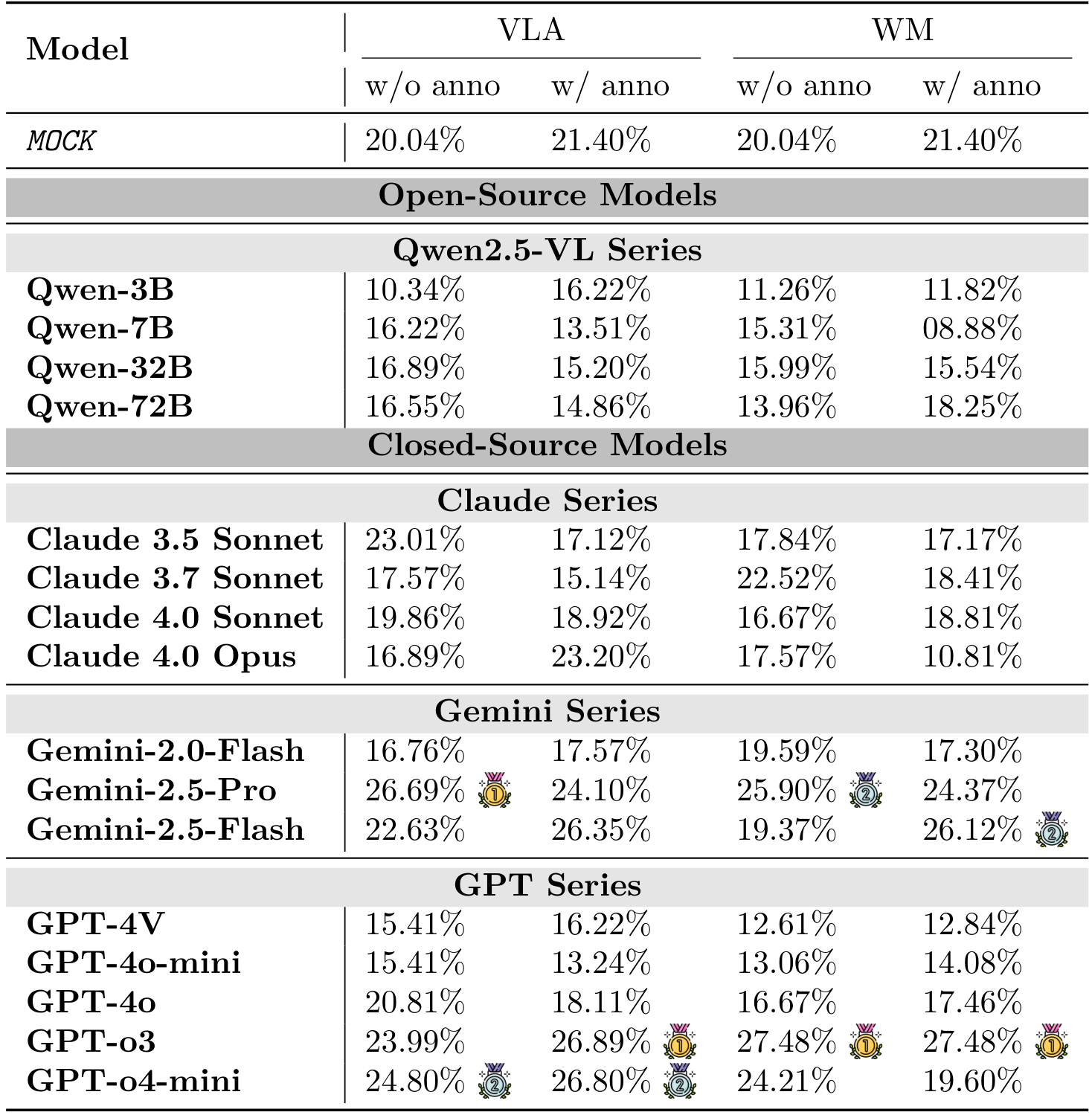
Kinetix环境揭示了随着物理复杂性的增加,VLM性能呈现明显且急剧的下降,凸显了在多步骤、协调控制方面的显著局限性。如图3所示及表14和表15的详细数据,所有模型在从简单任务(S级)过渡到更复杂的任务(M级和L级)时,成功率显著下降。例如,表现最佳的模型如GPT-o3,其成功率从S级任务的超过60%骤降至L级任务的不足15%。这一趋势在所有模型家族中均成立,表明虽然当前的VLM能够处理基本的单组件操作,但在面对需要长时间同步控制多个电机和推进器的任务时表现不佳。
我们对视觉注释实用性的消融研究得出了一个微妙且反直觉的结果。在简单的S级任务中,为可控部件提供明确标签通常会提升性能,因为这有助于模型将动作与正确的组件关联起来。
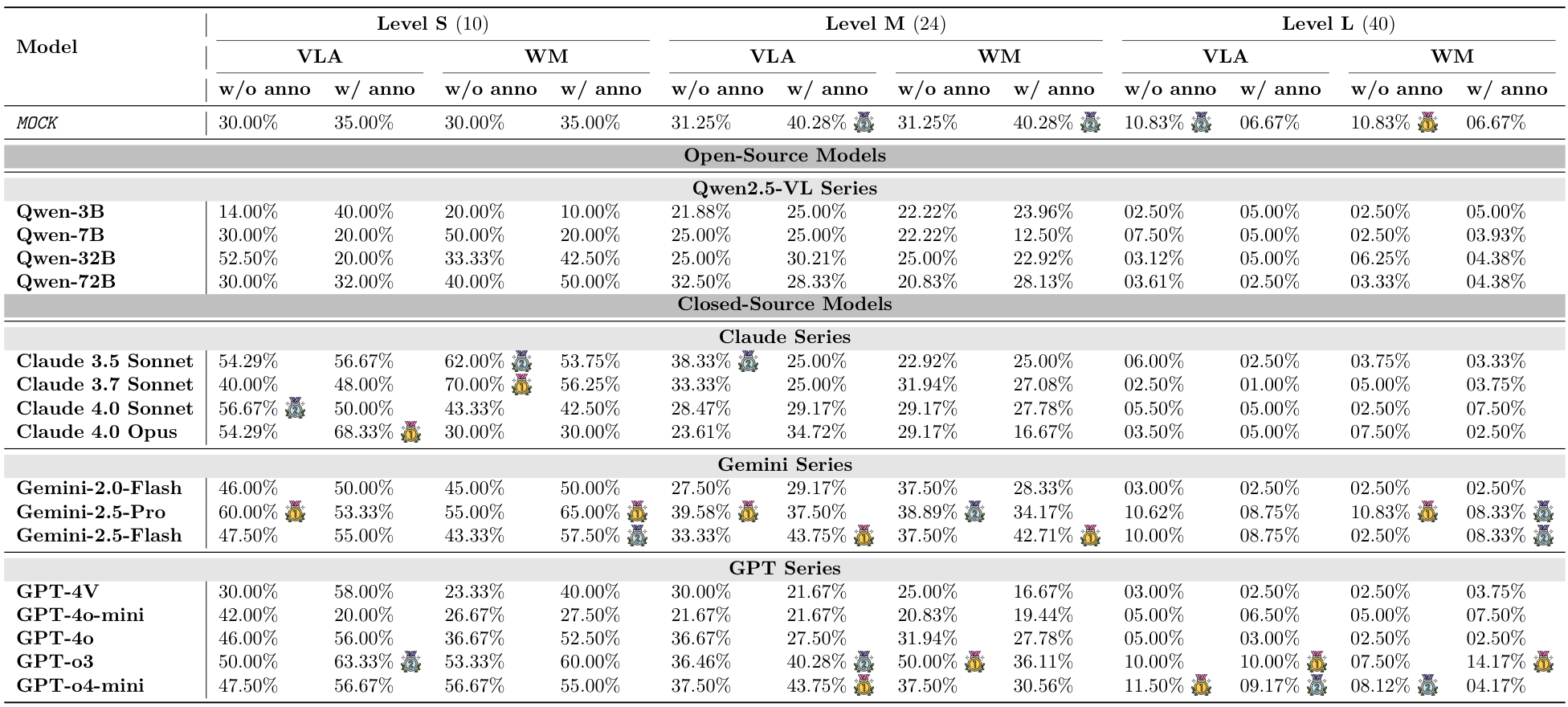
然而,这种效应在更困难的M级和L级任务中往往会逆转。对于许多模型,尤其是使用WM提示时,带有注释的性能反而比没有注释时更差。这表明对于模型能力范围内的任务,添加注释并使用WM提示格式可以进一步增强其物理推理能力。然而,随着交互组件数量的增加,这些标签及其所需的解释可能反而成为负担,导致模型专注于解析标签本身,而非对整体物理结构和动态进行推理。
此外,与直接VLA方法相比,WM提示格式始终未能改善性能,且经常降低性能。这在M级和L级任务中尤为明显,与我们套件中先前基准测试结果的发现一致。
D.4 案例研究
如图11所示,模型能够正确预测第一次尝试的结果,但由于重复相同动作而未能考虑代理的新状态和动量,导致失败。这揭示了描述性预测与有效的状态感知控制之间的根本脱节。在第一次尝试中,模型成功预测并执行了向右上角的移动,缩短了与目标的距离。然而,在第二次尝试中,它重复了完全相同的动作,未能考虑物体的新位置和第一次移动获得的动量。这种短视的重复导致代理直接与障碍物碰撞,最终任务失败。

E.1 转换细节
本文的评估重点在于单个智能体的表现,而非对抗性游戏,因此我们对原始的九球规则进行了调整:智能体的目标是通过击打桌上当前编号最小的球来将9号球入袋。每个模型将进行100次实验,每次实验最多尝试15次,以评估其平均成功率。这样的设置旨在更精确地测量当前智能体视觉语言模型(VLMs)对物理规则的理解及其与环境的交互能力,暂时不引入对抗性智能体或人类,这可能是未来智能体物理推理进步的一个研究方向。
观察空间:我们将Pooltool的原生3D渲染(如下图12所示)转换为2D俯视图渲染(如下图13所示),以更好地适应当前VLMs的视觉输入处理。
动作空间:Pooltool提供了一个Python API用于控制,其中击打母球的动作通过“Cue”对象及其“set_state”方法进行参数化。这些参数共同决定了击球的力量、方向和旋转(侧旋)。Pooltool Python API包括以下参数的设置:
-
v0(初始速度):
- 定义:表示母球被球杆击打后的初始速度(米/秒),直接对应击球的力量或强度。
- VLM选择:VLM选择一个预定义的离散力量级别。
SPEED_MAPPING = {"Low": 2, # 低速"Medium": 5, # 中速"High": 8 # 高速 }
-
a(横向偏移)和b(纵向偏移):

- 定义:aaa 定义了从母球中心点水平偏移的距离(米),控制侧旋(English/Side Spin);bbb 定义了垂直偏移的距离(米),控制上下旋(Top/Bottom Spin)。
- VLM选择:VLM通过选择预设的击打点类型来确定aaa和bbb的值。
STRIKESPOT_MAPPING = {"Top Left Spin": {"a": 0.35, "b": 0.35},"Top Spin": {"a": 0, "b": 0.5},"Top Right Spin": {"a": -0.35, "b": 0.35},"Middle Left Spin": {"a": 0.35, "b": 0},"Middle Spin": {"a": 0, "b": 0},"Middle Right Spin": {"a": -0.35, "b": 0},"Bottom Left Spin": {"a": 0.35, "b": -0.35},"Bottom Spin": {"a": 0, "b": -0.5},"Bottom Right Spin": {"a": -0.35, "b": -0.35} }
-
phi(水平角度):
- 定义:定义了球杆击打相对于母球的水平角度(度数),对应瞄准方向。
- VLM简化处理:考虑到VLM在选择精确连续角度方面的挑战,我们简化了处理:瞄准方向默认直接针对桌上当前编号最小的球(即通过设置cue_ball_id)。这样,VLM无需直接输出角度值。
-
theta(垂直角度):
- 定义:定义了球杆相对于桌面水平面的垂直角度(度数),对应球杆高度。
- VLM简化处理:我们忽略此参数,因为掌握此类高级技术对VLM来说过于复杂。
E.2 提示

8 Pooltool:系统1提示
您是一位专门研究台球游戏策略的专家AI智能体。您的目标是指导玩家在九球台球游戏中进行操作。
游戏目标:
您的最终目标是将9号球入袋。在每一回合中,您将通过击打编号最小的球来将9号球入袋。您的任务是提供最佳的母球击打参数以实现这一目标。
至关重要的是,避免将母球(白球)入袋。母球入袋是犯规,将对游戏进程产生负面影响。
论文摘要(中文)
以下是对论文中指定部分的总结,内容涉及 Pooltool 环境中的实验结果分析,并保留了原文中的图片部分及其格式。
E.3 实验结果
Pooltool 环境的实验结果显示出一种虚假的能力表象,高水平的成功指标掩盖了模型在深层物理推理上的根本缺陷。尽管一些顶级模型看似取得了较高的成功率,但进一步分析表明,这种表现并非源于战略洞察,而是依赖于简单粗暴的启发式方法。
如表3以及表16和表17的详细数据所示,GPT-4o-mini (VLA) 和 Qwen-3B (WM) 的100%成功率尤为引人注目,似乎在效率上超过了人类玩家,平均尝试次数更少。然而,这是一种误导性的假象。研究发现,当温度参数设置为0.1时,GPT-4o-mini 的输出变得确定性,每次尝试都一致地产生相同的动作(速度:“Medium”,击球点:“Top Spin”)。这种僵硬的行为导致模型在每次试验的第八次尝试中成功。与此形成鲜明对比的是,其他成功的模型(未标记为x的模型)通过在多次尝试中动态调整击球策略取得了胜利。这清楚地表明,输出固定的模型缺乏真正的物理推理能力,暴露了所有测试模型在该环境中的核心缺陷:完全无法掌握台球的细微物理特性。
此外,VLA 和 WM 提示格式之间的比较再次凸显了描述性知识与程序性控制之间的脱节。对于大多数模型,WM 提示未能带来显著改进,反而经常导致性能下降(例如,Gemini-2.5-Pro 的成功率从 VLA 格式的68.00%下降到 WM 格式的43.00%)。
Angry Birds 论文摘要(中文)
本文讨论了基于物理的益智游戏《愤怒的小鸟》(Angry Birds)的核心目标和机制。游戏的主要目标是消灭所有的绿色猪,玩家需要通过弹弓发射有限数量的小鸟,这些小鸟可能具备不同的能力,以击中猪或摧毁它们藏身的结构。这一任务不仅考验对抛物运动的掌握,还要求深入理解结构力学以及对每种小鸟独特能力的策略性应用。智能体必须能够准确分析视觉场景,识别结构弱点,预测小鸟的轨迹,并规划合适的发射顺序以消灭所有猪。本基准测试中,选择了游戏第一章的34个关卡进行研究。
F.1 转换细节
观察空间:游戏的截图作为智能体的直接视觉输入,代表关卡的当前状态。
动作空间:我们为每个关卡标注了可用小鸟的数量和类型。智能体的唯一动作是从弹弓发射当前小鸟。例如,第21关和第33关的小鸟配置分别如图14和图15所示。

“level 21”: {“bird_number”: 8, “number”: 8, “bird_type”: [“blue”, “red”, “yellow”]}
每次发射仅需指定发射角度(从0到90度)和功率级别(从0.0到1.0)。

“level 33”: {“bird_number”: 6, “bird_type”: [“red”, “yellow”, “black”]}
F.2 提示

Angry Birds: 系统提示
你是一名《愤怒的小鸟》游戏的大师级策略家。你的目标是使用有限数量的小鸟,通过弹弓发射,消灭所有的猪。你对抛物运动、结构弱点以及每种小鸟的独特能力有深刻的理解。
核心目标:消灭所有猪
- 当屏幕上所有猪被消灭时,关卡胜利。
- 如果在消灭所有猪之前用完所有小鸟,则关卡失败。
核心机制与操作
射击:你唯一的动作是从弹弓发射小鸟。你必须定义射击角度和发射功率。
- 角度:一个从0到90的整数,0表示水平向右,90表示垂直向上。
- 功率:一个从0.0到1.0的浮点数,其中1.0为最大功率(将弹弓拉到最远)。
小鸟能力:一些小鸟在发射后通过点击屏幕可以激活特殊能力。你的计划应假定能力会被最佳使用,仅关注初始发射参数。
武器库:小鸟类型
你必须了解每种小鸟的优势来规划你的攻击:
- 红鸟:标准小鸟,无特殊能力。最适合直接撞击和推倒结构。
- 黄鸟:发射后点击屏幕可使其沿直线加速,对木质结构非常有效。
- 蓝鸟:发射后点击屏幕可分裂成三只小鸟,对玻璃或冰结构极其有效。
- 黑鸟:作为炸弹,撞击后不久会爆炸,对石头结构威力巨大,可引发大规模连锁反应。
策略原则
- 轨迹至关重要:仔细分析射击历史、猪的位置及周围结构,计算最佳发射角度和功率。
- 结构弱点:瞄准结构的弱点,移除关键支撑块可引发连锁破坏。
- 小鸟顺序:必须按给定顺序使用小鸟,围绕可用小鸟序列规划整个策略。
你的任务是分析游戏状态,并为当前在弹弓上的小鸟确定最佳单次射击动作。
Angry Birds: 用户提示与实验结果总结(中文)
当前关卡状态分析与任务指令
在《Angry Birds》游戏中,目标是通过分析当前游戏屏幕,计划一次射击动作以摧毁猪。任务要求分析结构和猪的位置,并为当前小鸟设计最佳射击方案,提供发射参数。输出格式需严格按照指定格式,仅提供行动代码在“[ ]”括号中,不得添加其他文本、推理或评论。
实验结果总结(F.3 节)
《Angry Birds》基准测试的结果显示,当前视觉语言模型(VLMs)与人类水平的战略物理推理能力之间存在显著差距。根据表3和表18的数据,即使表现最好的模型(Claude 3.7 Sonnet)也仅取得了41.18%的成功率,远低于非专家人类的基准成功率64.71%。这一差距凸显了模型在整合抛物运动预测和长期战略规划的环境中存在根本性缺陷。深入分析模型的失败原因表明,其主要弱点不在于简单的轨迹计算,而在于预测动作复杂的连锁后果。虽然模型偶尔能在直接命中暴露的猪时取得成功,但它们在游戏核心战略元素——通过连锁反应导致大规模结构坍塌——上持续表现不佳。人类玩家擅长识别关键结构弱点,例如移除某个单一块体即可导致塔楼倒塌,并计划最大化这种破坏的射击。
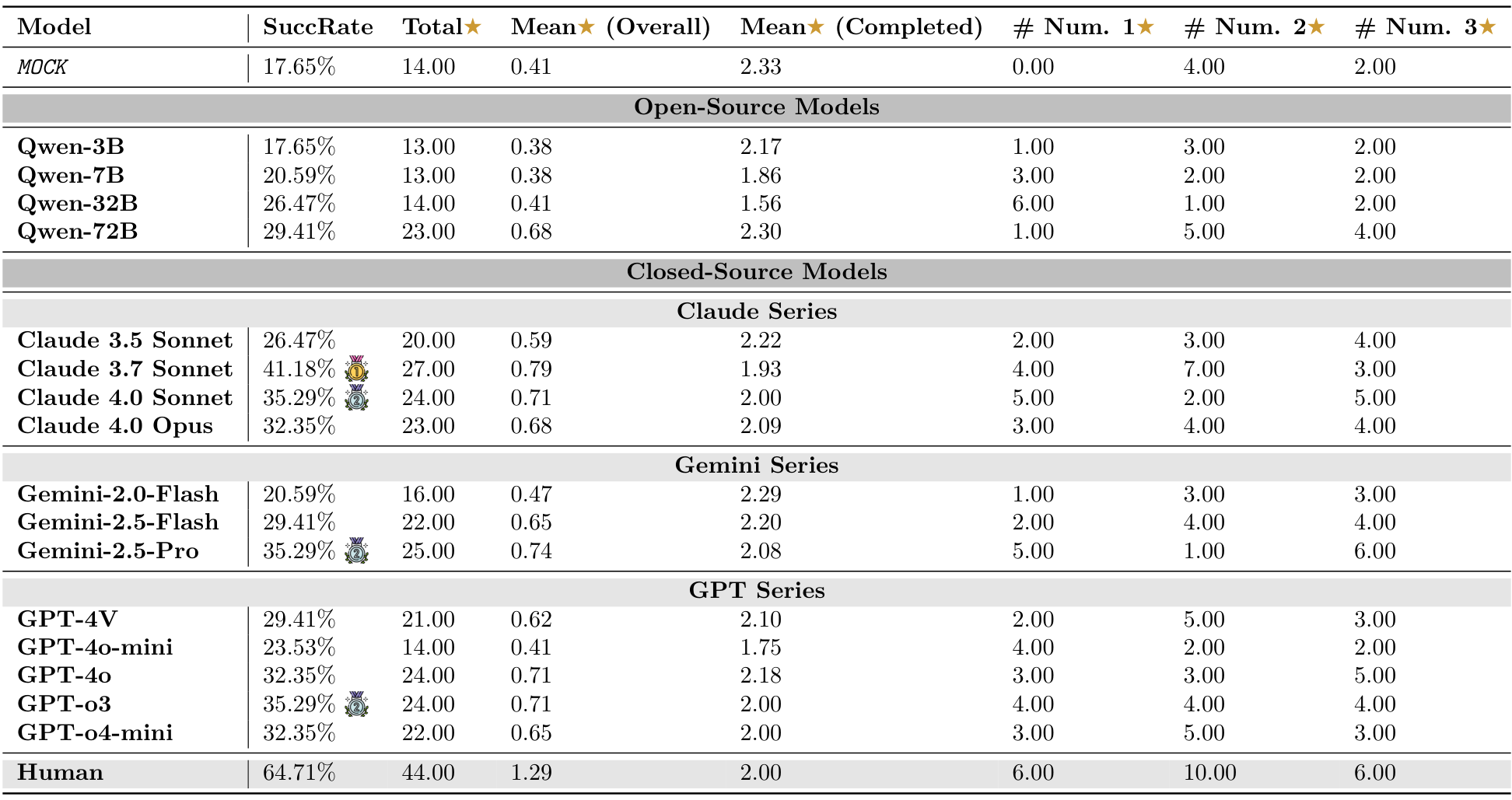
然而,对星星收集的分析提供了更细致的见解。虽然模型的总体成功率较低,但“Mean ★ (Completed)”指标显示,当模型成功时,其解决方案的质量往往令人满意。几个顶级模型,如Qwen-72B(2.30)和Claude 3.5 Sonnet(2.22),在完成任务时的平均星星数与人类玩家(2.00)相当,甚至略高。这表明模型的失败并非由于无法生成精确输出,而是缺乏可靠的物理直觉。当模型的内部模拟恰好与谜题的具体物理对齐时,它可以产生接近最优的解决方案。
总之,《Angry Birds》环境有效地暴露了当前VLMs在多阶段、动态物理推理中的局限性。这项任务不仅仅需要感知场景,还需要预测性地理解一次动作如何彻底改变环境以影响后续动作。模型在计划连锁反应和跨一系列射击调整策略方面的挣扎,凸显了描述性知识(了解小鸟的能力)与程序性、预测性控制(精确知道在何处及如何发射以获得最大效果)之间的关键差距。
G.1 转换细节
观察空间: 为了使智能体视觉语言模型(VLMs)能够理解并在游戏环境中操作,我们对游戏内的元素和交互过程进行了转换。对于静态道具,如销钉(Pins)、活动销钉(Active Pins)和气垫(Air Cushions),我们通过在游戏截图上标注它们的物理位置来增强智能体对这些关键元素的空間感知能力(如图16所示)。对于动态元素,如包裹糖果的气泡(Bubble),我们采用基于OpenCV的方法进行实时识别,以确保智能体能够及时捕捉其状态并与之交互(如图17所示)。在执行流程方面,当智能体完成一个动作后,游戏会暂停并截取屏幕截图。此截图作为下一轮决策的视觉输入。一旦智能体发出新命令,游戏继续运行,从而形成一个完整的“感知-决策-行动”循环。在这个基准测试中,我们从《割绳子》(Cut the Rope)游戏第一部分(Session 1)的5个盒子中的125个关卡中选择了88个关卡,筛选掉了涉及多屏幕转换的关卡(如图18所示)以及无法实时获取元素位置的关卡。
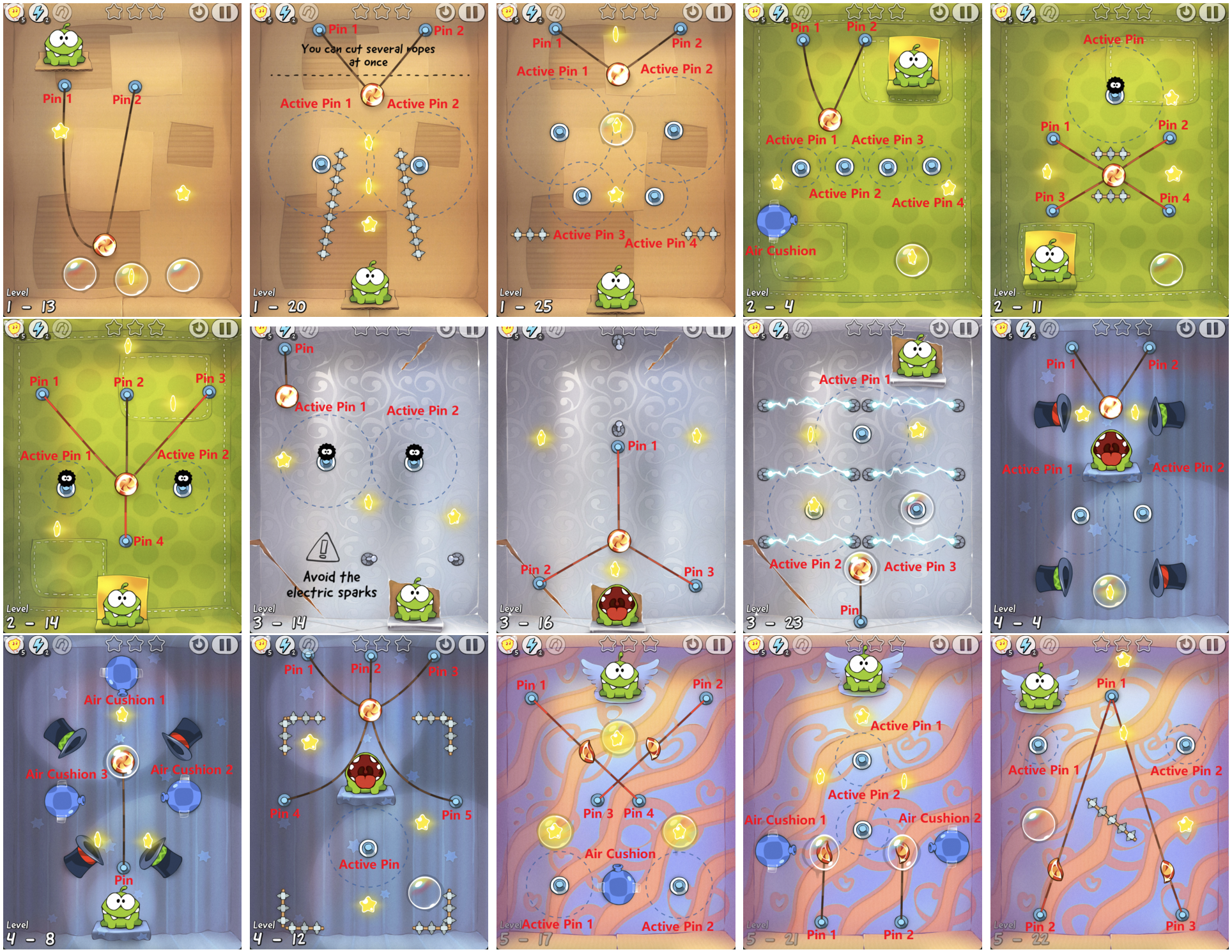


详细标注的理由: 当前的视觉语言模型(VLMs)缺乏分析像《割绳子》这类游戏中的卡通艺术风格的能力。为了说明这一问题,我们将图19中的图像呈现给高性能模型(Gemini-2.5-Pro 和 GPT-o3),并询问“图片中有多少条绳子?描述每条绳子是如何连接的。”如下面的示例所示,它们的回答揭示了显著的感知挑战。
论文摘要(中文) - Gemini-2.5-Pr0 和 GPT-03 模型分析与游戏动作空间设计
模型分析:绳索计数与连接描述
在论文中,研究者通过两个模型(Gemini-2.5-Pr0 和 GPT-03)对图片中的绳索数量和连接方式进行了分析,并探讨了视觉语言模型(VLM)在简单任务上的局限性。
- Gemini-2.5-Pr0 模型:
初始分析认为图片中有三根绳索,并描述了它们的连接方式:- 左侧垂直绳索:连接左上和左下的蓝色锚点,附有一个包含红色和橙色物体的气泡。
- 右侧垂直绳索:连接右上和右下的蓝色锚点,同样附有气泡。
- 中间绳索:松散悬挂并交叉成“X”形状。
在进一步考虑游戏机制和绳索交叉点后,模型修正为四根绳索,并更新了连接描述:
- 一根绳索从左上蓝色销钉连接到右侧的糖果气泡。
- 一根绳索从右上蓝色销钉连接到左侧的糖果气泡,两绳在中心交叉。
- 一根绳索从左下蓝色销钉连接到左侧糖果气泡。
- 一根绳索从右下蓝色销钉连接到右侧糖果气泡。
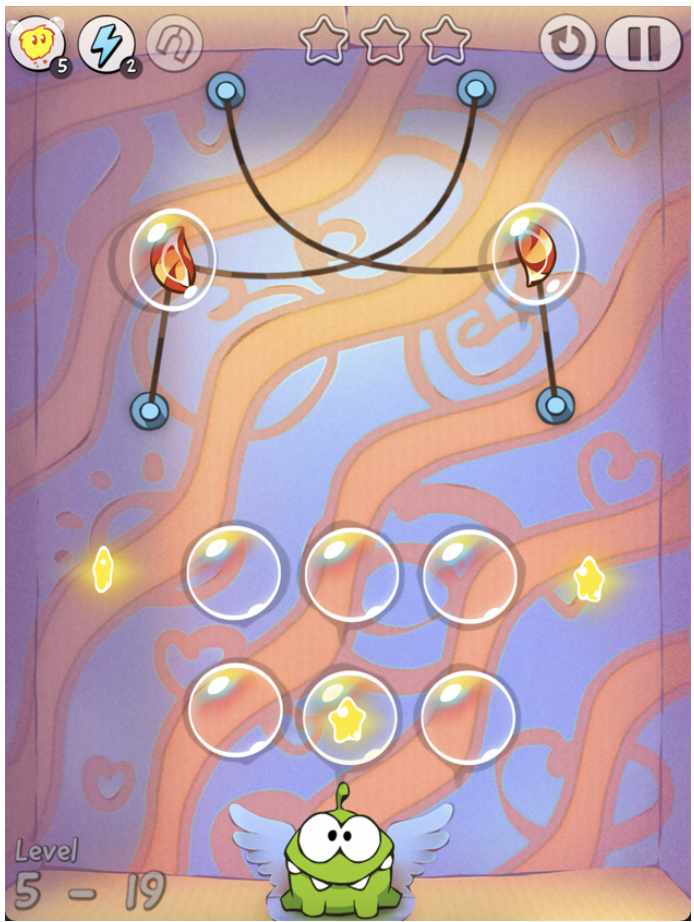
- GPT-03 模型:
该模型直接识别出图片中有四根独立的绳索,并描述如下:- 左上绳索:从左上销钉连接到中心顶部销钉(中间下垂)。
- 右上绳索:从中心顶部销钉连接到右上销钉(下垂并与第一根交叉)。
- 左侧垂直绳索:从左侧气泡垂直向下连接到左下销钉。
- 右侧垂直绳索:从右侧气泡垂直向下连接到右下销钉。
在回答关于绳索交叉点的问题时,模型再次确认有四根绳索,并重申了连接方式。
研究指出,即便是最先进的视觉语言模型(VLM)在人类看似简单的任务上仍表现不佳,这凸显了细致标注的必要性,以实现更公平和准确的评估。
动作空间设计
论文还设计了一个动作空间,将游戏的核心交互抽象为一系列离散且结构化的命令,使智能体能够以清晰且明确的方式执行动作。主要动作包括:
- 切割:这是主要交互方式。智能体可使用
cut_pin(id)和cut_active_pin(id)命令切断连接到不同类型锚点的绳索。 - 工具交互:智能体可使用
pop_bubble(id)刺破气泡使糖果下落,或使用tap_air_cushion(id, times)激活气垫为糖果提供推力。 - 时间控制:
sleep(seconds)是一个关键命令,允许智能体在执行下一动作前暂停,等待游戏内的物理过程(如摆动或下落)达到最佳时机。 - 终止命令:
success()和fail()是特殊命令,用于在智能体判断任务必然成功或已不可逆转地失败时结束当前关卡尝试。
通过这些动作的策略性组合和精确的时间控制,智能体能够解决游戏中的各种复杂物理谜题,并最终实现每关的目标。
G.2 提示 G.2

总结(中文)
本部分介绍了一个名为“割绳子”(Cut the Rope)的游戏中的提示和指导,玩家被设定为一名精通物理学和策略的大师,目标是通过操控环境,将糖果精准地送到小绿怪Om Nom的口中。内容主要包括以下几个方面:
- 核心目标:玩家的首要任务是将糖果送到Om Nom口中,同时需要在喂食前将两块糖果合并。此外,每一关有三个星星,玩家需通过让糖果触碰所有星星来获得满分(三颗星)。失败条件包括糖果掉出屏幕、被危险物(如尖刺)摧毁或被蜘蛛偷走。
- 核心机制与操作:玩家可以通过划动切断绳子(可以同时切多条绳子)以及通过点击激活特殊工具来与游戏环境互动。所有的策略和操作都需要基于对物理原理(如重力、动量、惯性和轨迹)的深刻理解,以确保任务成功完成。
本部分强调了分析和指令的精准性、逻辑性以及对完美得分的追求。
论文摘要(中文)
以下是对论文《The Arsenal: Game Elements & Tools》部分的中文总结,保留了原文中的图像部分及其位置。
游戏元素与工具
要制定获胜策略,必须理解每个元素的功能:
- 绳子:悬挂糖果的基本元素,可以被切割。
- 张力:拉紧的绳子会变红,表示张力较高,切割时会产生更强的摆动或弹射效果。
- 活动销钉:周围有虚线圆圈的销钉,当糖果进入圆圈范围时,会自动发射一根新绳子连接到糖果上。
- 魔法帽:成对出现。当糖果进入一顶帽子时,会立即传送到同颜色的另一顶帽子,保持进入时的动量。
- 危险物(尖刺、电火花):致命障碍物。如果糖果触碰到它们,糖果会被摧毁,务必避开。
- 蜘蛛:敌人,会沿着绳子爬向糖果。必须在它到达糖果之前切割绳子。
战略原则:大师思维
要成功,你必须像物理学家和《割绳子》大师一样思考:
- 顺序(操作顺序):切割绳子和激活工具的顺序至关重要。错误的顺序会导致失败。在采取第一步行动前,分析整个系统。
- 时机(精准行动):行动的时机与行动本身同样重要。在摆动顶点切割绳子可以将势能转化为动能,从而最大化水平距离。在正确时机戳破气泡可以将糖果完美地落在移动平台上。
- 预测(基于物理的预见):必须持续预测糖果的轨迹。在每次行动前,根据物理定律在脑海中模拟结果:
- 重力:持续向下的拉力。
- 惯性与动量:运动中的物体保持运动,利用摆动积累动量。
- 浮力:气泡提供的向上推力。
- 组合(工具协同):最复杂的谜题需要组合工具。例如,可能需要气泡将糖果提升到气垫的喷射气流中,然后推动糖果越过尖刺并到达最后一个星星。
你的任务是分析每个关卡的初始状态,并输出一个清晰的、逐步的计划,指定切割和互动的精确时机与顺序,以收集所有三颗星星并安全地将糖果送到 Om Nom。

当前关卡状态分析与任务指令
请分析当前游戏屏幕,并计划一个单一行动,最终将糖果送到绿色怪物 Om Nom。你将收到一张带注释的游戏截图,以及下方更详细的文本状态描述。
当前关卡状态分析:
- 销钉:共 {len(pins)} 个,ID 从 1 到 {len(pins)}。
- 活动销钉:共 {len(active_pins)} 个,ID 从 1 到 {len(active_pins)}。
- 气泡:共 {len(bubbles)} 个,ID 从 1 到 {len(bubbles)}。
- 气垫:共 {len(air_cushions)} 个,ID 从 1 到 {len(air_cushions)}。
- {history_prompt_text}
任务指令:
请仔细分析游戏元素的空间关系和物理可能性。从以下列表中选择一个最有助于实现目标的单一行动:
- cut_pin(id=pin_index) # 效果:切割连接到 pin_index 的绳子。
- cut_active_pin(id=active_pin_index) # 效果:切割连接到 active_pin_index 的绳子。
- pop_bubble(id=bubble_index) # 效果:戳破指定 bubble_index 的气泡。糖果将失去浮力并开始垂直下落。仅在糖果在气泡内时有效。
- tap_air_cushion(id=air_cushion_index, times=[1, 3, 5]) # 效果:点击指定 air_cushion_index 的气垫指定次数,使其释放气流,推动糖果朝特定方向移动。
- sleep(seconds=x) # 效果:等待指定秒数。
论文摘要(中文)
以下是对论文中指定部分的中文总结,保留了原文中的 markdown 格式图像部分,并确保其位置适当。
效果描述
- 等待效果:等待 xxx 秒,让游戏内的物理效果得以展开。当需要等待某个物理过程(例如摆动)达到特定状态后再执行下一个动作时使用。调用此效果后,系统将在 xxx 秒后提供新的游戏状态并请求下一个动作。
- 成功效果:声明任务成功。当确定糖果已处于不可避免地进入 Om Nom 嘴里的轨迹,且无需进一步动作时调用此效果。
- 失败效果:声明任务失败。当确定糖果已丢失且后续动作无法成功时调用此效果。
输出格式
请严格遵守以下格式来选择你的动作。不要添加任何额外的解释。仅在“[”和“]”括号内输出动作代码,不含任何额外文本或注释。例如:[ACTION_CODE(parameters)]
G.3 实验结果
在“割绳子”(Cut the Rope)环境中,代理视觉语言模型(agentic VLMs)面临着所谓的“最后一英里”挑战,暴露了它们在感知、物理直觉和动态控制方面的深层局限性。正如表3和表19所示,所有测试模型的表现都远低于人类基准。表现最好的模型Claude 4.0 Opus仅取得了26.14%的成功率,明显落后于人类玩家的平均成功率41.36%。在解决方案质量上的差距更为明显:人类玩家平均收集了91.6颗星,几乎是最佳模型(33.00颗星)的三倍,展示了人类在寻找最优多目标解决方案方面的卓越能力。
对失败模式的分析揭示了模型在时空推理方面的关键弱点,这种弱点从最基本的感知层面开始。游戏中充满活力、卡通风格的图形用户界面(GUI)对五岁儿童来说可能非常简单,但对即使是最先进的模型也构成了重大障碍,这些模型经常在基本任务上失败,例如正确计数场景中的绳子数量。这突显了我们精心标注的必要性,以便开始评估推理能力。除了感知之外,模型还无法掌握游戏中的直觉物理——那种无法通过文本提示或游戏指南简单传达的、关于动量和轨迹的隐性“无言”理解。成功往往取决于在摆动高峰时割断绳子或精确控制气垫吹气的次数。模型无法掌握这一点,在它们的频繁错误中表现得尤为明显:它们要么立即采取“暴力”行动,要么因犹豫不决而陷入瘫痪,未能等待糖果摆动到最佳位置。这种时空缺陷在需要屏幕转换的关卡中变得更加严重,模型表现出一种“失忆”现象,无法在视角切换时保持一致的状态表示,这是我们最终基准测试中排除此类关卡的主要原因,因为它们目前超出了任何视觉语言模型(VLM)的能力范围。
此外,成功尝试的质量进一步凸显了这一局限性。Mean★(Completed)指标显示,即使模型成功解决了一个关卡,它们的解决方案也缺乏精细度。人类玩家在完成关卡时平均获得2.51颗星,而最佳模型如GPT-o3和Claude 4.0 Opus分别仅获得1.88和1.43颗星。这表明模型的成功尝试往往是简单或“暴力”的解决方案,仅实现了主要目标(喂饱Om Nom),但未能执行收集所有三颗星所需的优雅、精确计时的操作。它们在动态物理约束下的多目标规划方面遇到了困难。
总之,“割绳子”基准测试有效地暴露了当前视觉语言模型物理推理的脆弱性。通过要求整合细致的感知、隐性的物理直觉和精确的时机,它超越了静态谜题,测试了动态交互的核心。模型的广泛失败证实了在识别物理元素和在动态、时间敏感的系统中程序化控制它们之间存在根本性的脱节。
H 人类表现
报告的用于基准测试Pooltool、Angry Birds和Cut the Rope的人类表现数据并非旨在作为与代理视觉语言模型结果比较的大致结果。
对于Pooltool和Angry Birds,人类结果代表两位非专家合著者玩游戏的平均结果。对于Cut the Rope,人类表现是5名非专家众包工人玩游戏的平均结果。
Original Abstract: Although Vision Language Models (VLMs) exhibit strong perceptual abilities
and impressive visual reasoning, they struggle with attention to detail and
precise action planning in complex, dynamic environments, leading to subpar
performance. Real-world tasks typically require complex interactions, advanced
spatial reasoning, long-term planning, and continuous strategy refinement,
usually necessitating understanding the physics rules of the target scenario.
However, evaluating these capabilities in real-world scenarios is often
prohibitively expensive. To bridge this gap, we introduce DeepPHY, a novel
benchmark framework designed to systematically evaluate VLMs’ understanding and
reasoning about fundamental physical principles through a series of challenging
simulated environments. DeepPHY integrates multiple physical reasoning
environments of varying difficulty levels and incorporates fine-grained
evaluation metrics. Our evaluation finds that even state-of-the-art VLMs
struggle to translate descriptive physical knowledge into precise, predictive
control.
PDF Link: 2508.05405v1
部分平台可能图片显示异常,请以我的博客内容为准
