数据结构 栈(1)
1. 栈的概念和结构
之前几篇我们分别讲解了顺序表和单链表的内容,今天我们又来学习一个新的关于数据结构的内
容--- 栈 。
栈:栈也属于线性表 , 但它是一种特殊的线性表,其只允许在固定的一端进行插入和删除元素操
作。进行数据插入和删除操作的一端称为栈顶,另一端称为栈底。栈中的数据元素遵守后进先出
LIFO(Last In First Out)的原则。
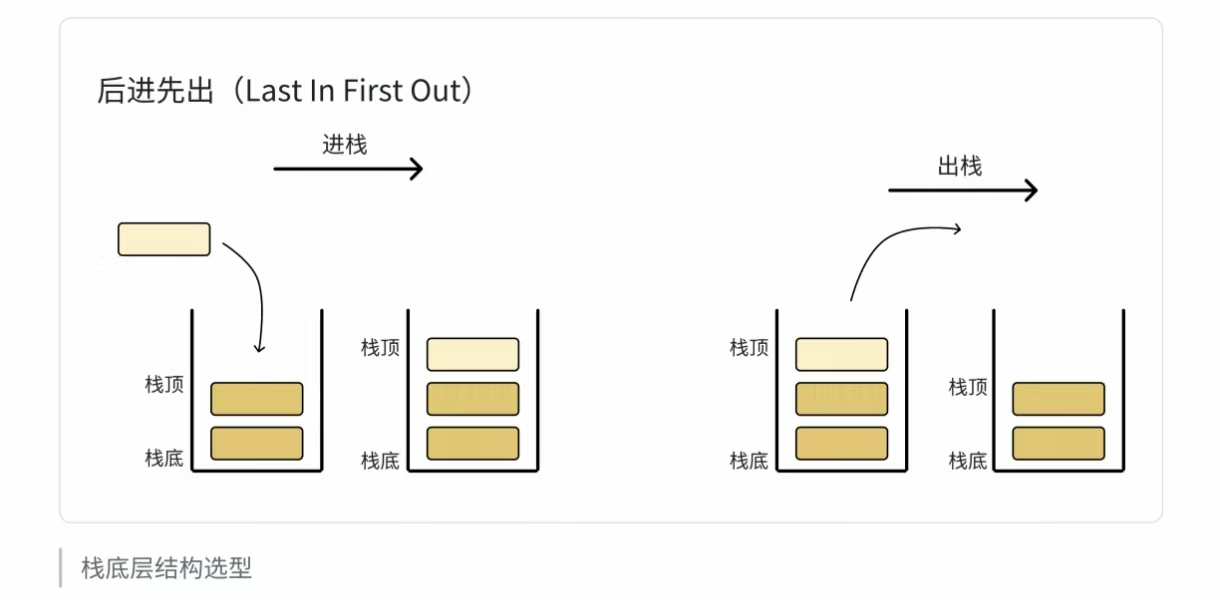
压栈:栈的插入操作叫做进栈/压栈/入栈,入数据在栈顶。
出栈:栈的删除操作叫做出栈。出数据也在栈顶。
栈底层结构选型:
栈的实现一般可以使用数组或者链表实现,相对而言数组的结构实现更优一些。因为数组在尾上插
入数据的代价比较小。
2. 栈,顺序表,单链表之间的关联
栈、顺序表和链表都是数据结构领域中重要的概念,它们之间存在着紧密的联系,也有着明显的区
别:
2.1 联系:
- 底层实现关联:栈可以使用顺序表(数组)或者链表作为底层的数据存储结构来实现。
- 基于顺序表实现栈:在以顺序表为基础实现栈时,通常使用数组来存储栈中的元素,用一个变量
(如 top )来记录栈顶的位置。入栈操作就是在数组末尾添加元素(当空间足够时),并更
新 top ;出栈操作则是移除数组末尾元素,并更新 top 。这种实现方式利用了顺序表在尾端插入
和删除元素的高效性(时间复杂度为O(1))。
- 基于链表实现栈:当用链表实现栈时,一般将链表的头节点作为栈顶。入栈操作通过在链表头部
插入新节点来完成,出栈操作则是删除链表头部节点。这是因为在链表头部进行插入和删除操作的
时间复杂度也是O(1) ,符合栈的操作特性。
- 栈底层结构选型:
栈的实现一般可以使用数组或者链表实现,相对而言数组的结构实现更优一些。因为数组在尾上插
入数据的代价比较小。
- 数据存储特性:从数据存储的角度来看,顺序表、链表和栈都是用于组织和存储数据的方式。顺
序表和链表是更基础的数据结构,提供了不同的存储和访问数据的方式;而栈是一种具有特定操作
约束(后进先出)的数据结构,它可以借助顺序表或链表来实现其功能。
2.2 区别:
- 数据结构定义:
- 栈:是一种抽象数据类型,它定义了一组特定的操作,主要包括入栈、出栈和获取栈顶元素等,
重点在于操作的规则(后进先出),而不是具体的存储方式。
- 顺序表:是一种线性数据结构,它使用连续的内存空间来存储数据元素,元素之间的逻辑顺序和
物理顺序是一致的。用户可以通过下标快速访问表中的任意元素,支持在任意位置插入和删除元素
(但在非末尾位置操作的时间复杂度较高 )。
- 链表:也是一种线性数据结构,它通过指针将各个数据节点链接起来,节点在内存中的存储位置
不一定连续。链表的优势在于插入和删除操作较为灵活高效(时间复杂度为O(1) ,前提是已知待
操作节点的前驱节点 ),但访问特定位置的元素需要从头节点开始遍历,时间复杂度为O(n) 。
- 操作特性:
- 栈:操作受限,只能在栈顶进行插入和删除操作,遵循后进先出原则,主要用于解决具有特定顺
序要求的问题,比如函数调用、表达式求值等。
- 顺序表:操作相对灵活,可以在任意位置进行插入、删除和访问操作。但在插入和删除元素时,
如果涉及到大量元素的移动(比如在表头插入元素 ),时间复杂度较高,为O(n) ;访问元素的时
间复杂度为O(1) 。
- 链表:插入和删除操作在已知前驱节点的情况下时间复杂度低,为O(1) ,但访问元素需要顺序遍
历链表,时间复杂度为O(n) ,不支持随机访问。
- 内存使用:
- 顺序表:需要预先分配一定大小的连续内存空间,如果数据量预估不准确,可能会导致内存浪费
(分配过大)或溢出(分配过小 )。
- 链表:采用动态内存分配,按需分配节点空间,不会造成内存的浪费,但每个节点除了存储数据
外,还需要额外存储指针,会占用一定的内存空间。
- 栈:根据其实现方式的不同,内存使用特点也有所不同。基于顺序表实现的栈,存在与顺序表类
似的内存分配问题;基于链表实现的栈,内存分配较为灵活,类似于链表的内存使用方式。
以上便是栈的概念内容以及它和顺序表和单链表之间的关系。下一篇文章小编将详细讲解关于栈的
内容的实现。