PillarNet: Real-Time and High-PerformancePillar-based 3D Object Detection
ECCV 2022
paper:[2205.07403] PillarNet: Real-Time and High-Performance Pillar-based 3D Object Detection
code:https://github.com/VISION-SJTU/PillarNet-LTS
纯点云基于pillar3D检测模型
网络比较
SECOND
-
基于voxel,one-stage,基于sparse 3D conv
-
将点云划分为3D voxel,在BEV空间识别box
-
模型结构包括
-
encoder:编码非空3D voxel特征,生成多size3D特征
-
neck:将bev空间下的多尺度3D特征flatten,转换成多尺度(和多size区别?)特征;top-down
-
detect head:用多尺度bev特征做box分类回归
-
PointPillars
-
用一个小PointNet将点云投射到xy平面,生成一个稀疏2D底图
-
2Dconv(top-down)网络,对底图生成多尺度特征
-
detect head
分析
-
基于pillar的网络性能瓶颈(资源性能?效果性能?)主要在于sparse encoder、neck模块
-
PointPillar直接在稠密的2d底图上 用特征金字塔网络 fuse多尺度特征
-
缺少pillar特征编码
-
把输出特征的size和初始pillar范围耦合了,造成所用计算资源随着pillar scale上涨
-
改进
-
将SECOND中的3d sparse conv替换成2d
-
用neck模块融合稀疏的空间特征、抽象高维语义特征
-
总结
-
学pillar 特征:较重的 sparse encoder
-
空间特征融合:较轻的neck
-
结构
 encoder
encoder
-
输入:稀疏2d pillar特征
-
stage1-4:2d conv,逐渐降采样pillar特征
-
可使用2d检测backbone:vgg,resnet,并且可提升3d效果
-
逐渐降采样,缓解了pillar size绑定的影响
-
neck
-
16倍下采样稠密特征
-
3种设计
-
v1:SECOND设计
-
v2:基于1多一条skip connection
-
v3:基于2多一层conv
-

loss
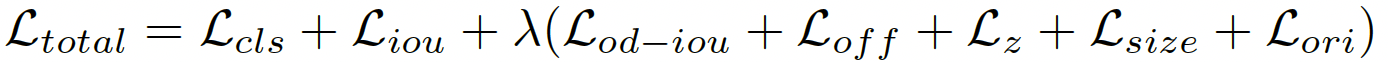
-
cls:focal loss
-
iou:

-
-
S:分类score
-
W:3d iou score
-
L1 loss
-
β:超参
-
iou计算:2 ∗ (W − 0.5) ∈ [−1, 1].
-
-
解耦朝向:xxIoU loss → OD-xxIoU
-
-
size(3d box),off(位置偏移量),z(z方向位置),ori(朝向):L1 loss