Oracle索引
目录
一、索引的原理引入
二、创建索引
1.语法结构
2.索引分类
3.创建唯一索引
4.创建普通索引
5.创建位图索引
6.创建组合索引(最左原则)
三、关于执行计划
1.PL/SQL中如何查看执行计划
2.DataGrip中如何查看Oracle的执行计划
四、索引相关面试题
1.什么时候该创建索引
2.主键字段和唯一索引的区别(面试题)
3.索引失效的情况
4.索引的优缺点
4.1索引的优点
4.2索引的缺点
一、索引的原理引入
例如有一万条数据,表里有一个字段 ID ,ID 存储的数据时从1 到 10000 递增的数据索引条目,ID 1到10 范围的数据存储在第一个索引条目,10到20 的数据时存储在第二个索引条目里,以此类推。
查找数据的时候,会根据索引条目返回的 ROWID 查找数据
如果要查询ID = 5 的数据,就会到第一个索引条目里去找。再将找到的 ROWID 返回。
二、创建索引
Oracle数据库会为表的主键和包含唯一约束的列自动创建唯一索引。
索引可以提高查询的效率。
1.语法结构
CREATE UNIQUE INDEX index_name ON table_name(column_name,column_name…);语法解析:
1.UNIQUE:指定索引列上的值必须是唯一的。称为唯一索引。
2.index_name:指定索引名。
3.table_name:指定要为哪个表创建索引。
4.column_name:指定要对哪个列创建索引。我们也可以对多列创建索引;这种索引称为组合索引。
2.索引分类
3.创建唯一索引
必须保证该列数据不重复
DROP TABLE EMP_818;
CREATE TABLE EMP_818 AS SELECT * FROM EMP;
CREATE UNIQUE INDEX UNI_EMPNO_818 ON EMP_818(EMPNO);-- JOB字段有重复数据,唯一索引创建失败
CREATE UNIQUE INDEX UNI_JOB_818 ON EMP_818(JOB);
---当往唯一索引的字段中插入重复的数据时,会报错
INSERT INTO EMP_818(EMPNO,ENAME) VALUES (7788,'TEST2');---向唯一索引中插入空值,是可以存在多行数据都是空
INSERT INTO EMP_818(EMPNO,ENAME) VALUES (NULL,'TEST2');
INSERT INTO EMP_818(EMPNO,ENAME) VALUES (NULL,'TEST3');SELECT * FROM EMP_818;
-- 查询结果后回滚
ROLLBACK;4.创建普通索引
CREATE INDEX UNI_JOB_818 ON EMP_818(JOB);![]()
5.创建位图索引
用法:重复性比较高,基数小。比如:性别列、婚姻状态、学历。
CREATE BITMAP INDEX IDX_EMP_DEPTNO ON EMP_818(DEPTNO);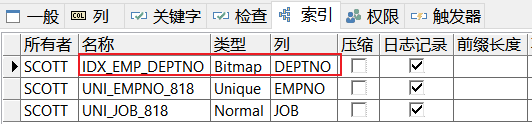
DROP TABLE EMP_BAK;CREATE TABLE EMP_BAK AS SELECT * FROM EMP;INSERT INTO EMP_BAK SELECT * FROM EMP;
COMMIT;CREATE BITMAP INDEX IDX_EMP_BAK_DEPTNO ON EMP_BAK(DEPTNO);SELECT * FROM EMP_BAK WHERE DEPTNO=10; -- 查看执行计划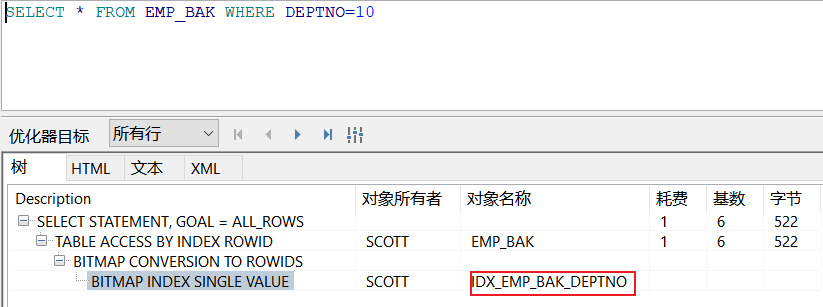
6.创建组合索引(最左原则)
1、何时创建:当两个或多个列经常一起出现在where条件中时,则在这些列上同时创建
2、组合索引中列的顺序是任意的,也无需相邻。但是建议将最频繁访问的列放在列表的最前面
3、最左原则:索引字段顺序为
(A,B,C)时,查询条件需从左到右匹配字段(如A、A+B、A+B+C),否则可能无法完全利用索引。
CREATE INDEX INDEX_EMPNO_JOB_818 ON EMP_818(DEPTNO,JOB);
索引扫描:
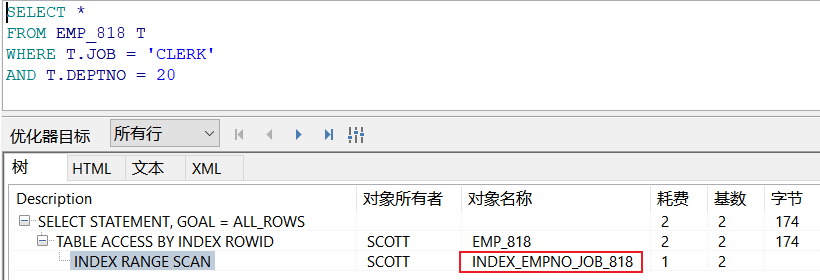
索引扫描:
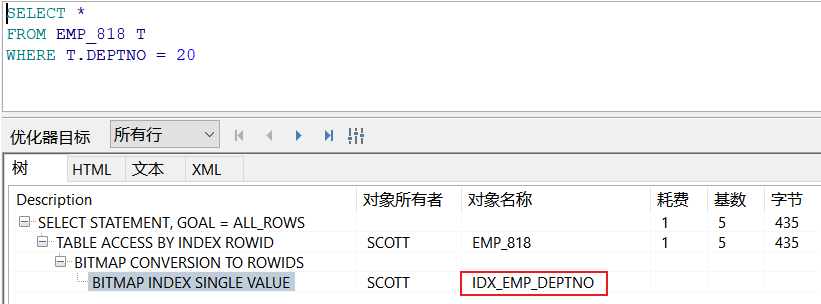
全表扫描:
DROP INDEX UNI_JOB_818;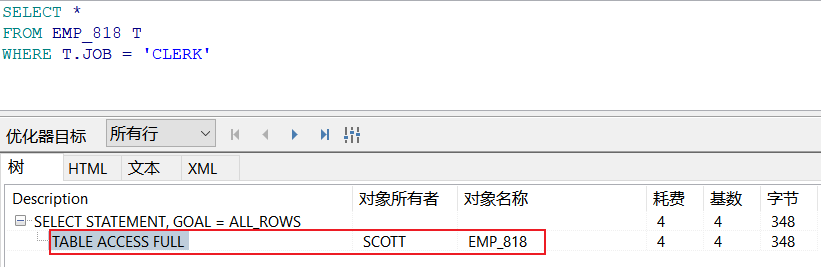
三、关于执行计划
1.PL/SQL中如何查看执行计划
选中代码,按 F5看执行计划
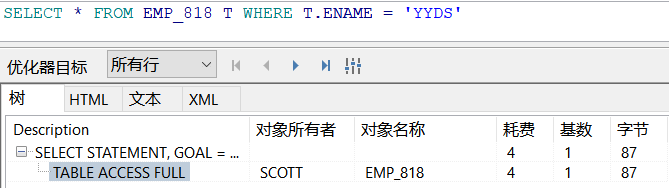
当 WHERE 条件中 用到 索引字段时,就会走索引扫描
看表的扫描方式
全表扫描:TABLE ACCESS FULL
索引扫描:INDEX SCAN
SELECT * FROM EMP_818 T WHERE T.EMPNO = 7369; SELECT * FROM EMP_818 T WHERE T.ENAME = 'YYDS';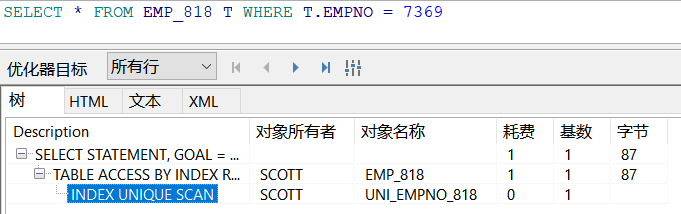
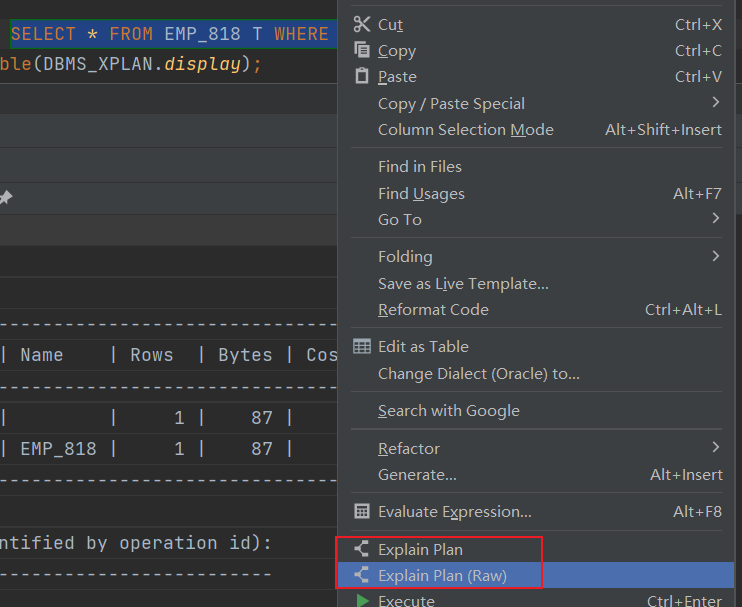
2.DataGrip中如何查看Oracle的执行计划
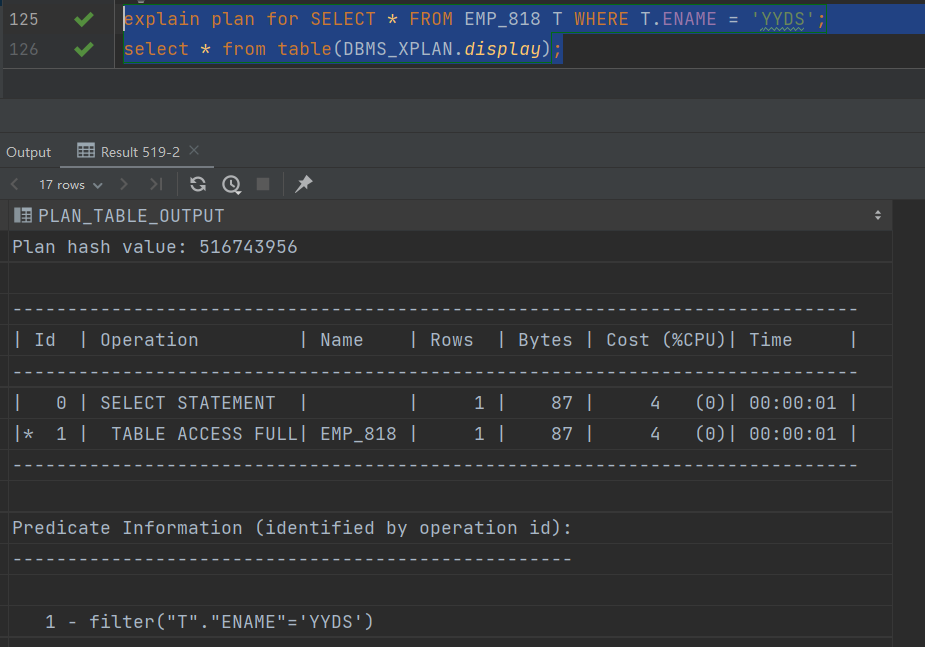
或者选中SQL,右键,点击Explain Plan
四、索引相关面试题
1.什么时候该创建索引
1. 如果表中的某些字段经常被作为查询的条件出现时,就应该考虑为该列创建索引。
2. 经常作为 关联/分组/排序 的字段也是可以考虑在这些字段上创建索引。
3. 索引不是越多越好,会降低数据的写入效率,不超过6个
有一条基本的准则是:
当任何单个查询要查询的行数少于或者等于整个表行数的10%时,索引就非常有用。
2.主键字段和唯一索引的区别(面试题)
主键字段是非空的,唯一索引的字段可以存在空值,并且是多行为空也可以
他们的共同点就是只要有数据,那么数据就是唯一的
3.索引失效的情况
索引失效就是在 WHERE 后面用到了索引字段,但是没有走索引扫描,走的是全表扫描
1.隐式转换
由于表的字段 tu_mdn 定义为 varchar2(20),但在查询时把该字段作为number类型,以where条件传给Oracle,这样会导致索引失效。
错误的例子:select * from test where tu_mdn=13333333333;
正确的例子:select * from test where tu_mdn='13333333333';
2.对索引列进行运算(+,-,*,/,! 等)
3.使用Oracle内部函数导致索引失效,对于这样情况应当创建基于函数的索引
错误的例子:select * from test where round(id,2)=10.00; 说明此时id的索引已经不起作用了
正确的例子:首先建立函数索引,create index test_id_fbi_idx on test(round(id,2));
然后 select * from test where round(id,2)=10; 这时函数索引起作用了
4.WHERE后面使用 <> 、not in 、not exists、!=
SELECT * from EMP_818 t WHERE T.EMPNO <> /*not in 、not exists、!=*/ 1;SELECT * from EMP_728 t WHERE T.EMPNO BETWEEN 1 AND 10;5.like "%_" 百分号在前(可采用在建立索引时用 reverse(columnName)这种方法处理)
CREATE INDEX UNI_EMPNO_JOB_1 ON EMP_818(reverse(JOB));SELECT * FROM EMP_818 T WHERE T.JOB LIKE '%AAA';SELECT REVERSE('1234') FROM dual;6.未遵循最左原则
单独引用复合索引里非第一位置的索引列。应总是使用索引的第一个列,如果索引是建立在多个列上,只有在它的第一个列被where子句引用时,优化器才会选择使用该索引。
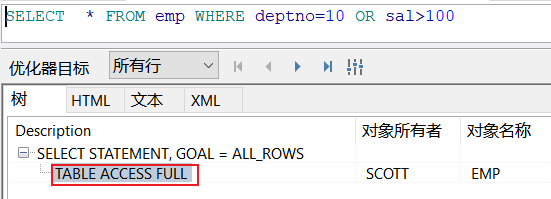
CREATE INDEX UNI_EMPNO_JOB_1 ON EMP_818(JOB,DEPTNO); SELECT * FROM EMP_818 WHERE DEPTNO=30; ---用了索引第二个位置的字段作为查询条件,导致索引失效7.OR 导致索引失效
4.索引的优缺点
4.1索引的优点
1.加速查询:通过索引快速定位数据,减少磁盘I/O,提升查询效率。
2.排序/分组优化:若查询涉及排序或分组字段,索引可避免额外排序操作。
3.唯一性约束:唯一索引可确保数据唯一性(如主键索引)。
4.2索引的缺点
1. 空间占用:索引本身需存储,占用额外磁盘空间(尤其是大表)。
2. 写入性能下降:插入、更新、删除数据时需维护索引,增加CPU和I/O开销。
3. 维护成本:索引过多会导致维护复杂,可能影响数据库整体性能。
4. 查询优化陷阱:错误使用索引(如字段类型不匹配、低区分度字段)可能导致优化器不选择索引,反而降低性能。