IteraJudge-增量多维评判框架解读
1 概念解读
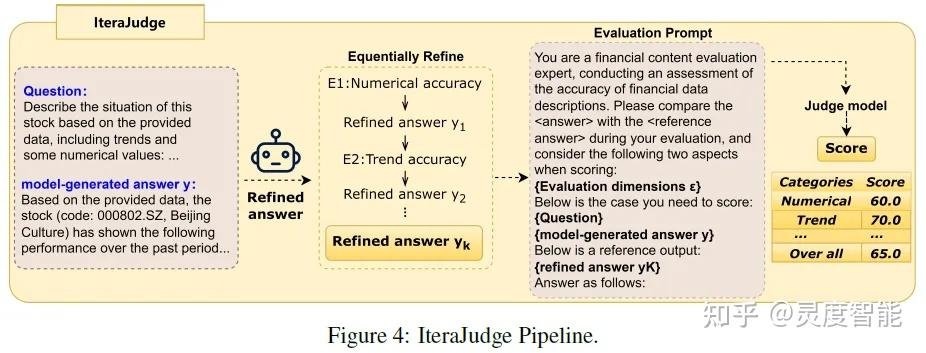
IteraJudge是BizFinBench测试集采用的迭代式评判框架,针对待测模型给出的初始答案,不直接进行打分,而是在多个维度精炼后作为质量基准,然后对初始答案进行打分,整个过程兼顾多个评估维度,使得打分更具信服力。
参考BizFinBench论文,针对初始答案y,IteraJudge的评判打分过程如下
1)基于LLM提示词在多个维度迭代式精炼初始答案y_0,每个维度对应独立的提示词。
2)保留最后一次精炼后的答案y_n,作为评估生成质量的基准答案。
3)将初始答案y_0,基准答案y_n输入评判模型,对初始答案y_0进行打分。
该过程为保持上下文一致性,需要确保所有步骤中明确保留用户问题q作为输入。
2. 案例解读
BizFinBench的github示例代码只在financial data description任务较完整应用了IteraJudge的迭代式精炼过程,具体为在指标数字和数字趋势描述2个维度对待测模型的初始答案进行精炼。
这里以eval_financial_description_revise.py为例,结合2阶段精炼提示词、评判提示词,解读IteraJudge的打分流程。
1)“指标数字”精炼提示词
输入为用户问题question,待测模型给出的初始答案answer。
评估标准为
**评估标准: **
<评估标准>
数据错用:<模型生成的输出>中的指标数字应该和<instruction>中的对应上,不应该出现指标错用、时间错用等情况,例如:从55.32增长到59.14描述成从55.24增长到58.32。
</评估标准>
输出为在指标数字维度对初始答案精炼后的结果,记录为y_1。
prompt_1='''请充当强大的修订者,根据以下评估标准修订 AI 助手对 instruction 生成的输出。如果模型生成的输出已足够好,则直接返回原始输出,无需任何修改或额外说明。
**instruction:**
<instruction>
{question}
</instruction>**评估标准: **
<评估标准>
数据错用:<模型生成的输出>中的指标数字应该和<instruction>中的对应上,不应该出现指标错用、时间错用等情况,例如:从55.32增长到59.14描述成从55.24增长到58.32。
</评估标准>**模型生成的输出:**
<模型生成的输出>
{answer}
</模型生成的输出>不要为您的响应提供任何解释。
仅输出完整的修订答案,而无需说任何其他内容。'''
2)“指标数字趋势描述”精炼提示词
输入为用户问题question,上次精炼后的结果y_1(对应提示词中的answer)。
评估标准为
**评估标准: **
<评估标准>
数据描述: 只需判断<模型生成的输出>中是否存在描述与具体数据相背的情况,如果有则得0分。例如:一连串数值越来越大,描述却是递减、两两比较错误,或最大、最小值判断错误、涨跌幅大于零说成下跌、主力资金小于零说成资金流入。当<instruction>中未取到数或取到的数据为空时,<模型生成的输出>中回答不能说该数据为0,如果有则得0分。
</评估标准>
输出为维度“数字描述趋势”精炼后的结果,这里记录为y_2,由于只有2级精炼,y_2在这里被作为最终的质量基准答案。
prompt_2='''请充当强大的修订者,根据以下评估标准修订 AI 助手对 instruction 生成的输出。如果模型生成的输出已足够好,则直接返回原始输出,无需任何修改或额外说明。
**instruction:**
<instruction>
{question}
</instruction>**评估标准: **
<评估标准>
数据描述: 只需判断<模型生成的输出>中是否存在描述与具体数据相背的情况,如果有则得0分。例如:一连串数值越来越大,描述却是递减、两两比较错误,或最大、最小值判断错误、涨跌幅大于零说成下跌、主力资金小于零说成资金流入。当<instruction>中未取到数或取到的数据为空时,<模型生成的输出>中回答不能说该数据为0,如果有则得0分。
</评估标准>**模型生成的输出:**
<模型生成的输出>
{answer}
</模型生成的输出>不要为您的响应提供任何解释。
仅输出完整的修订答案,而无需说任何其他内容。'''3)评判LLM提示词
输入为用户问题question,待测模型初始答案answer,最后一次精炼后的结果y_2(对应提示词中的ref_answer)。
评估标准为
请你评估时将<answer>与<reference answer>进行比较,同时考虑以下两个方面进行打分:
1. 数据错用:<answer>中的指标数字应该和<question>中的对应上,不应该出现指标错用、时间错用等情况,例如:从55.32增长到59.14描述成从55.24增长到58.32。
2. 数据描述: 只需判断<answer>中是否存在描述与具体数据相背的情况,如果有则得0分。例如:一连串数值越来越大,描述却是递减、两两比较错误,或最大、最小值判断错误、涨跌幅大于零说成下跌、主力资金小于零说成资金流入。当<question>中未取到数或取到的数据为空时,<answer>中回答不能说该数据为0,如果有则得0分。
| 分数 | 描述 |
| ------- | ------------------------------------------------------------ |
| **100** | 完全正确。趋势描述和数据描述的均完全正确,且语言流程,无幻觉。 |
| **60** | 部分错误。数据趋势描述正确,但数据值描述错误,例如从55.32增长到59.14描述成从55.24增长到58.32。 |
| **0** | 错误较多。数据趋势描述错误即不得分,例如数据趋势是越来越大,描述是递减。 |
输出为评判模型对待测模型初始答案answer的打分结果,以及打分依据。
prompt_judge='''你是一个金融内容评测专家,正在进行金融数据描述准确性的评估。请你评估时将<answer>与<reference answer>进行比较,同时考虑以下两个方面进行打分:1. 数据错用:<answer>中的指标数字应该和<question>中的对应上,不应该出现指标错用、时间错用等情况,例如:从55.32增长到59.14描述成从55.24增长到58.32。2. 数据描述: 只需判断<answer>中是否存在描述与具体数据相背的情况,如果有则得0分。例如:一连串数值越来越大,描述却是递减、两两比较错误,或最大、最小值判断错误、涨跌幅大于零说成下跌、主力资金小于零说成资金流入。当<question>中未取到数或取到的数据为空时,<answer>中回答不能说该数据为0,如果有则得0分。| 分数 | 描述 || ------- | ------------------------------------------------------------ | | **100** | 完全正确。趋势描述和数据描述的均完全正确,且语言流程,无幻觉。 || **60** | 部分错误。数据趋势描述正确,但数据值描述错误,例如从55.32增长到59.14描述成从55.24增长到58.32。 || **0** | 错误较多。数据趋势描述错误即不得分,例如数据趋势是越来越大,描述是递减。 |### 以下是你需要评分的案例:<question>{question}</question><answer>{answer}</answer>### 以下是一个参考输出:<reference answer>{ref_answer}</reference answer>### 要求:返回结果以json格式展示,参考:{"评分分数":"xx","描述": "xxxx"}### 回答如下:
'''.strip()整个打分过程考虑了“指标数字”和“数字趋势描述”2个维度,相比直接对answer打分更具信服力。
reference
---
1. BizFinBench: A Business-Driven Real-World Financial Benchmark for Evaluating LLMs
https://arxiv.org/pdf/2505.19457
2. BizFinBench. https://github.com/HiThink-Research/BizFinBench.git
https://github.com/HiThink-Research/BizFinBench.git
3. IteraJudge示例代码和测试数据
https://github.com/HiThink-Research/BizFinBench/blob/main/benchmark_code/BizFinBench/eval_financial_description_revise.py
https://github.com/HiThink-Research/BizFinBench/blob/main/datasets/Financial_Data_Description.jsonl