8.1.排序的基本概念
一.前言:
1.排序算法的基本概念:
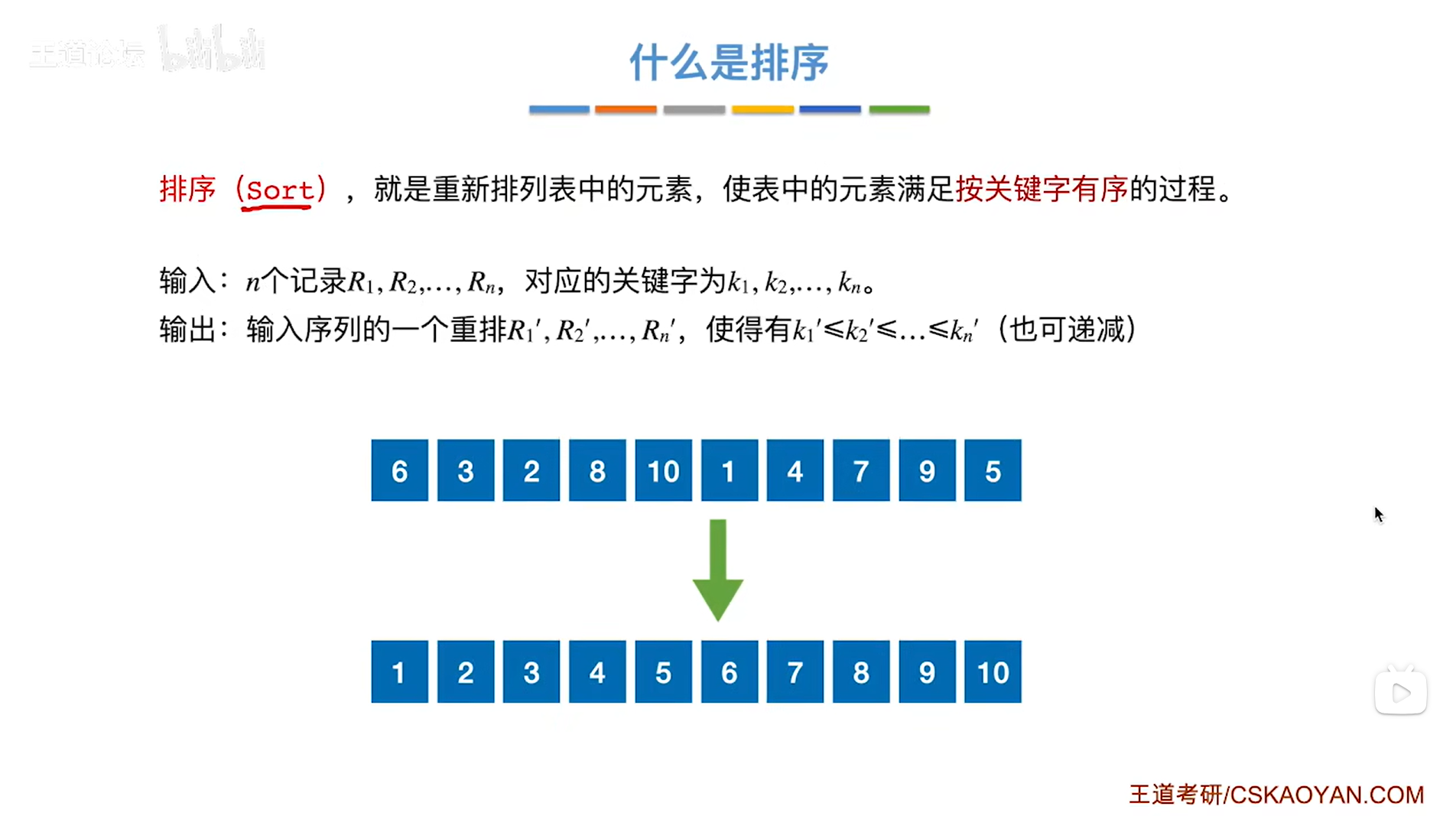
如上图,
所谓排序,就是把杂乱无章的一堆数据元素按照一定的规则如递增重新排列一遍,
总而言之经过排序算法之后,要保证最终的一堆的数据元素的关键字是有序的,在之前的章节中说过(详情见"7.1.查找的基本概念"),各个数据元素的关键字是唯一的,但在排序算法中难免会遇到关键字相同的情况,
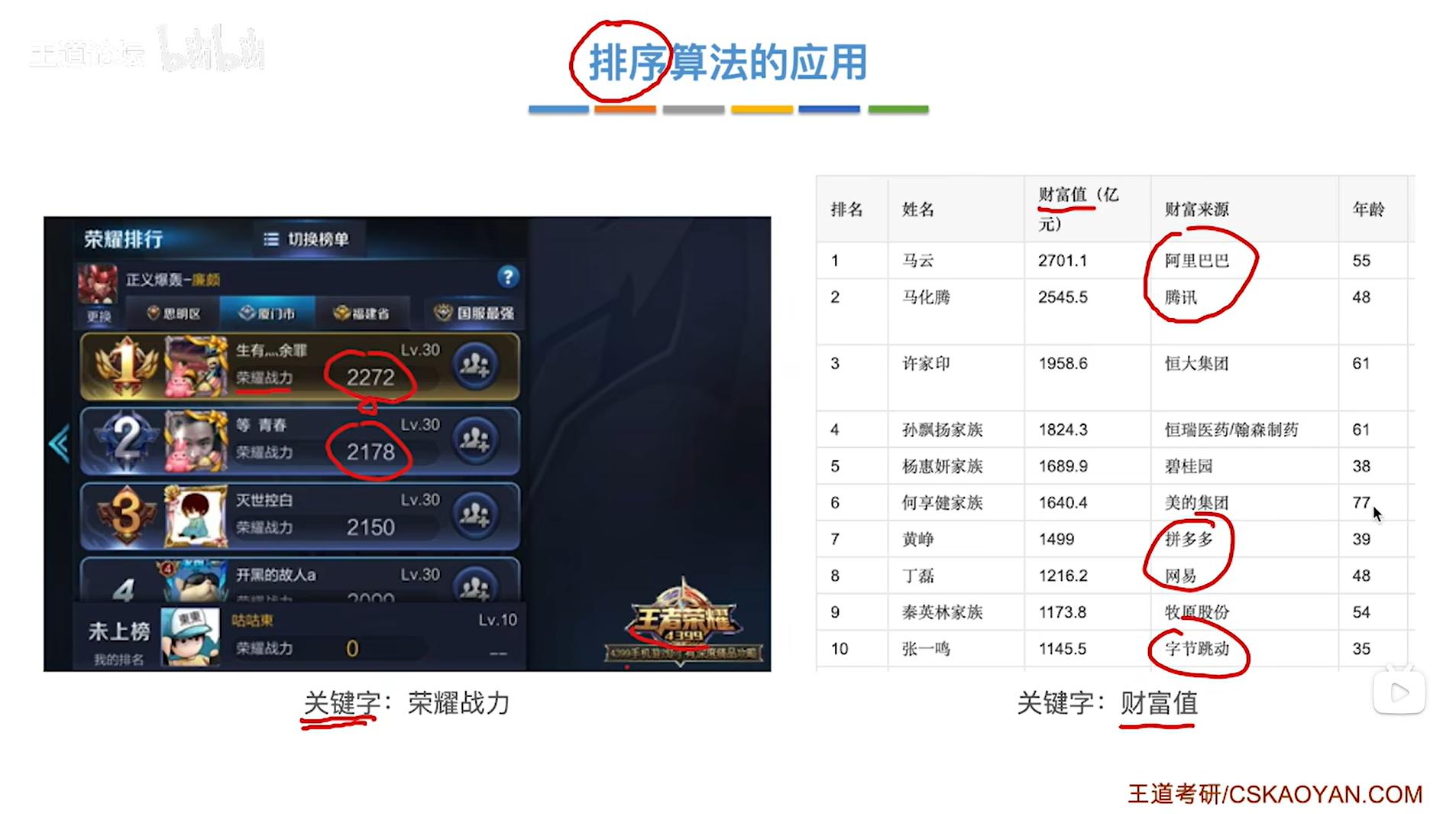
比如王者荣耀里的荣耀战力排行榜,其中荣耀战力的值为关键字,荣耀战力会遇到相同的情况;
再比如财富排行榜,其中每个人的财富值就是关键字,财富值也会遇到相同的情况,如下图:
2.排序算法的评价指标:
Ⅰ.时间复杂度与空间复杂度:
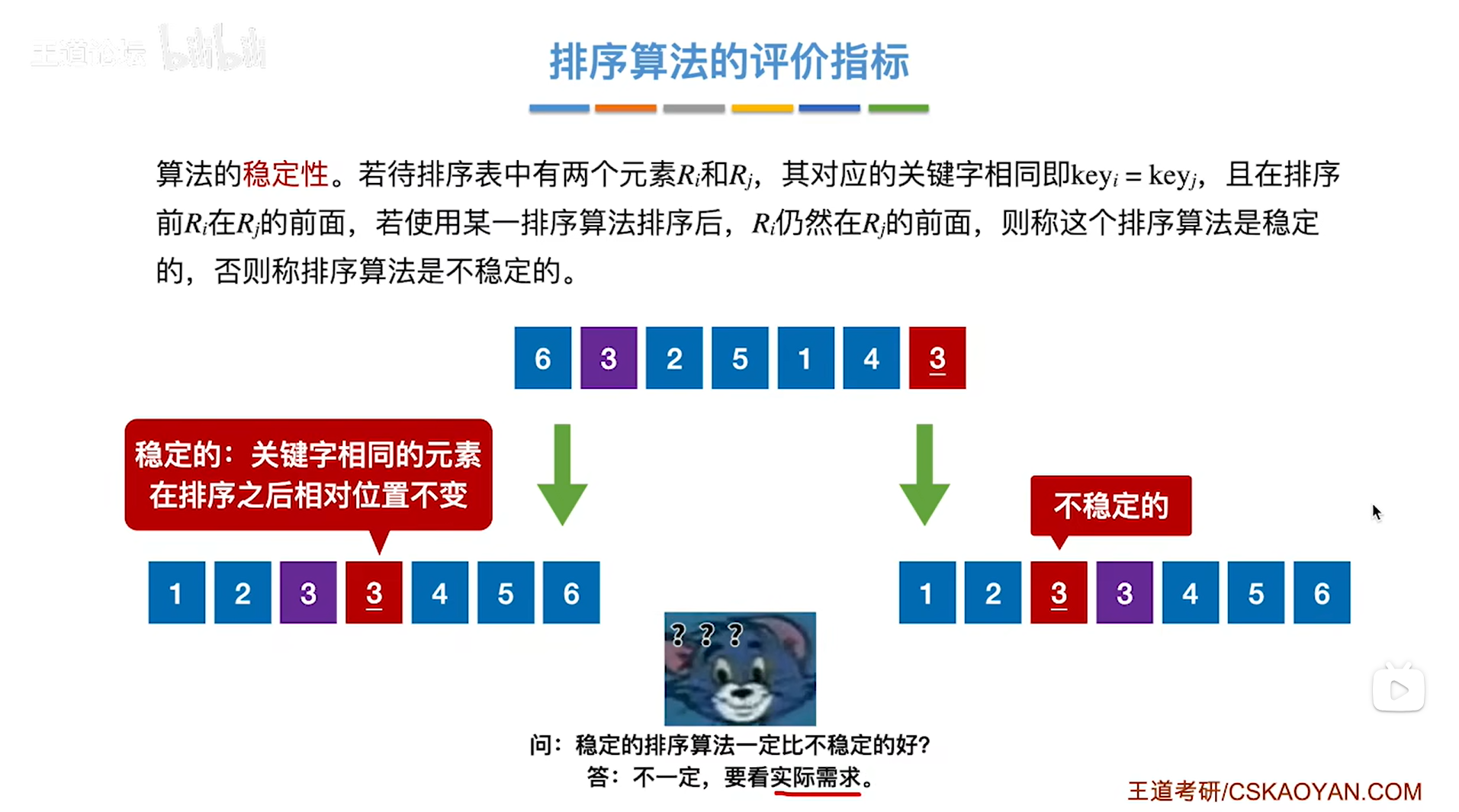
Ⅱ.排序算法的稳定性:
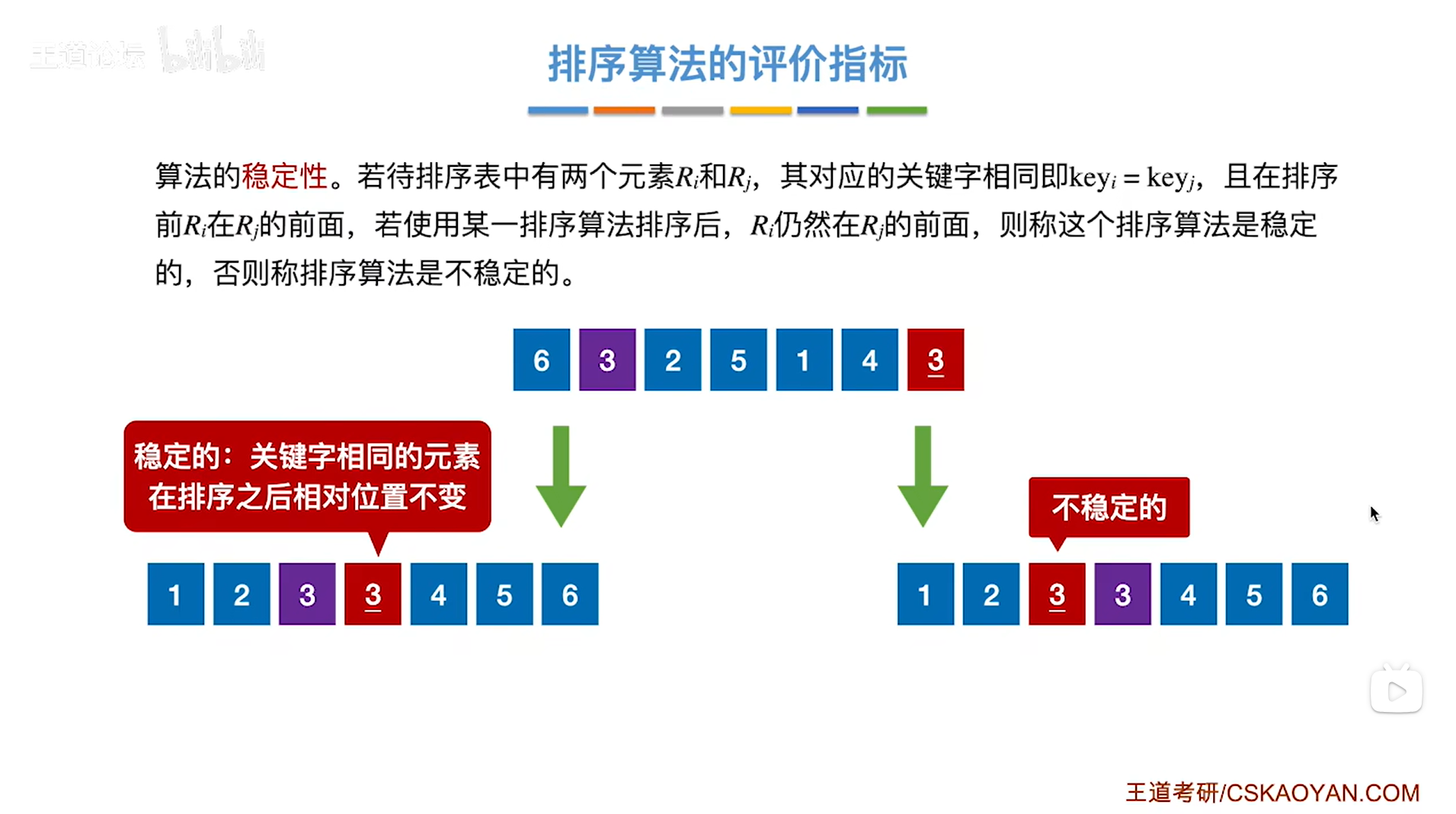
以上述图片为例,
假如有一堆数据元素6、3(1号)、2、5、1、4、3(2号),其中包含了关键字相同的两个数据元素即3(1号)和3(2号),在未排序之前3(1号)在3(2号)之前,
经过排序算法的处理之后,得到的排序序列为1、2、3(1号)、3(2号)、4、5、6,其中3(1号)在3(2号)之前,会发现3(1号)和3(2号)相对位置没有发生改变,也就是关键字相同的两个数据元素的相对位置相比于排序之前未发生改变;
但也有可能在某些排序算法之后得到的排序序列为1、2、3(2号)、3(1号)、4、5、6,其中3(1号)在3(2号)之后,会发现3(1号)和3(2号)相对位置发生了改变,也就是关键字相同的两个数据元素的相对位置相比于排序之前发生了改变->
因此如果经过排序算法的处理之后,关键字相同的某几个数据元素的相对位置相比于排序之前未发生改变,那这样的排序算法就是稳定的排序算法,
但如果经过排序算法的处理之后,关键字相同的某几个数据元素的相对位置相比于排序之前发生了改变,那这样的排序算法就是不稳定的排序算法。
Ⅲ.思考:稳定的排序算法一定比不稳定的好?
答案:不一定,这个要根据实际需求来判断。
如果应用场景中对排序算法的稳定性没有要求,那么可以选择不稳定的排序算法,也可以选择稳定的排序算法;
如果应用场景中所有的数据元素的关键字都不可能重复,此时稳定的排序算法和不稳定的排序算法的排序结果都是一样的,那么稳定的排序算法和不稳定的排序算法都可以选择->
所以稳定的排序算法是否一定比不稳定的排序算法更好,这个不能一概而论。
二.排序算法的分类:
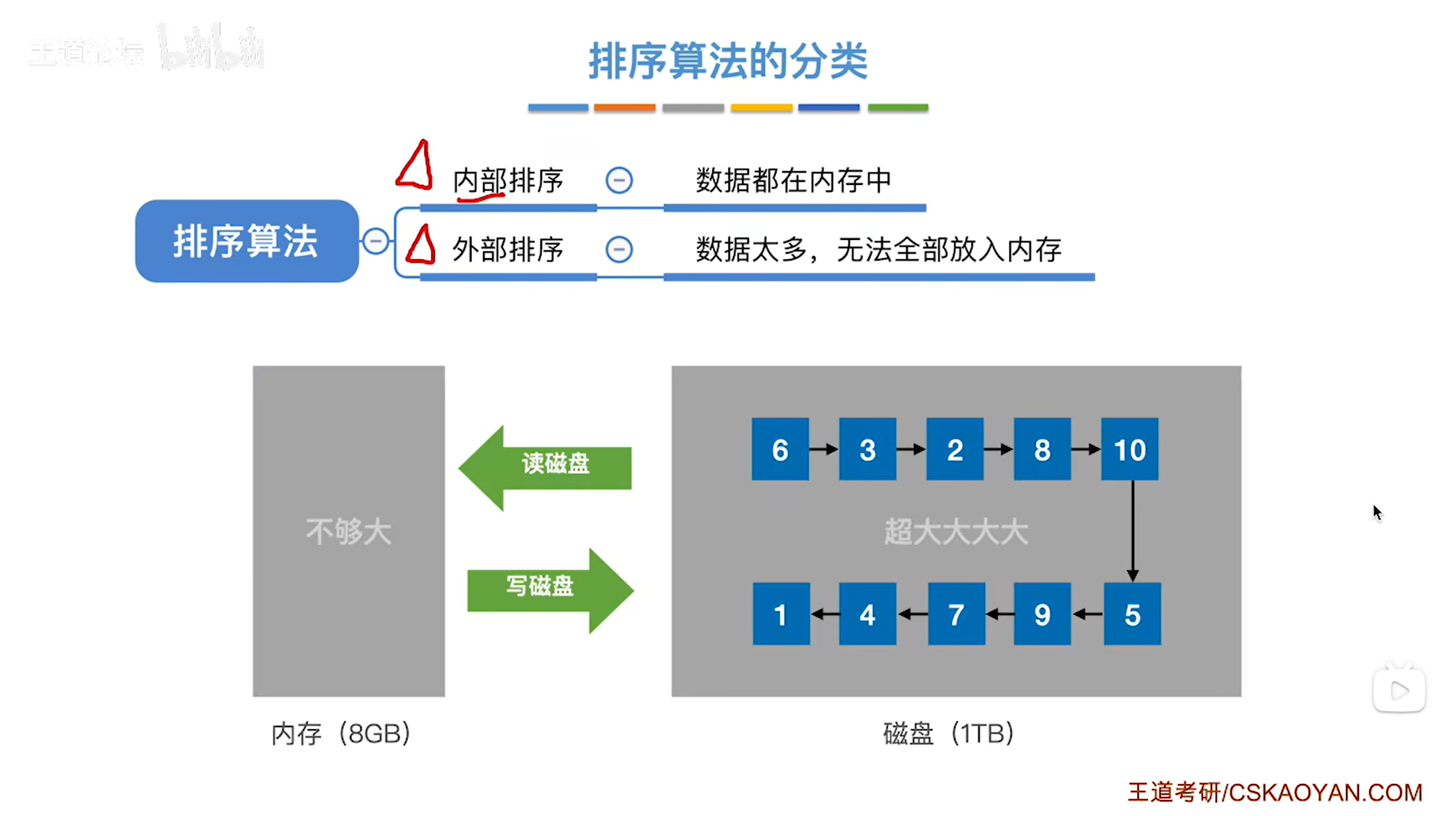
1.内部排序:
如上图,
内部排序指的是可以把所有的需要排序的数据全部放入内存当中,
比如自己写的程序中定义了一个int型数组,那自己定义的数组,由于数据量不是很大,所以这些数据都是可以放在内存当中,
因此对于这些数据的排序,就相对来说更简单一些。
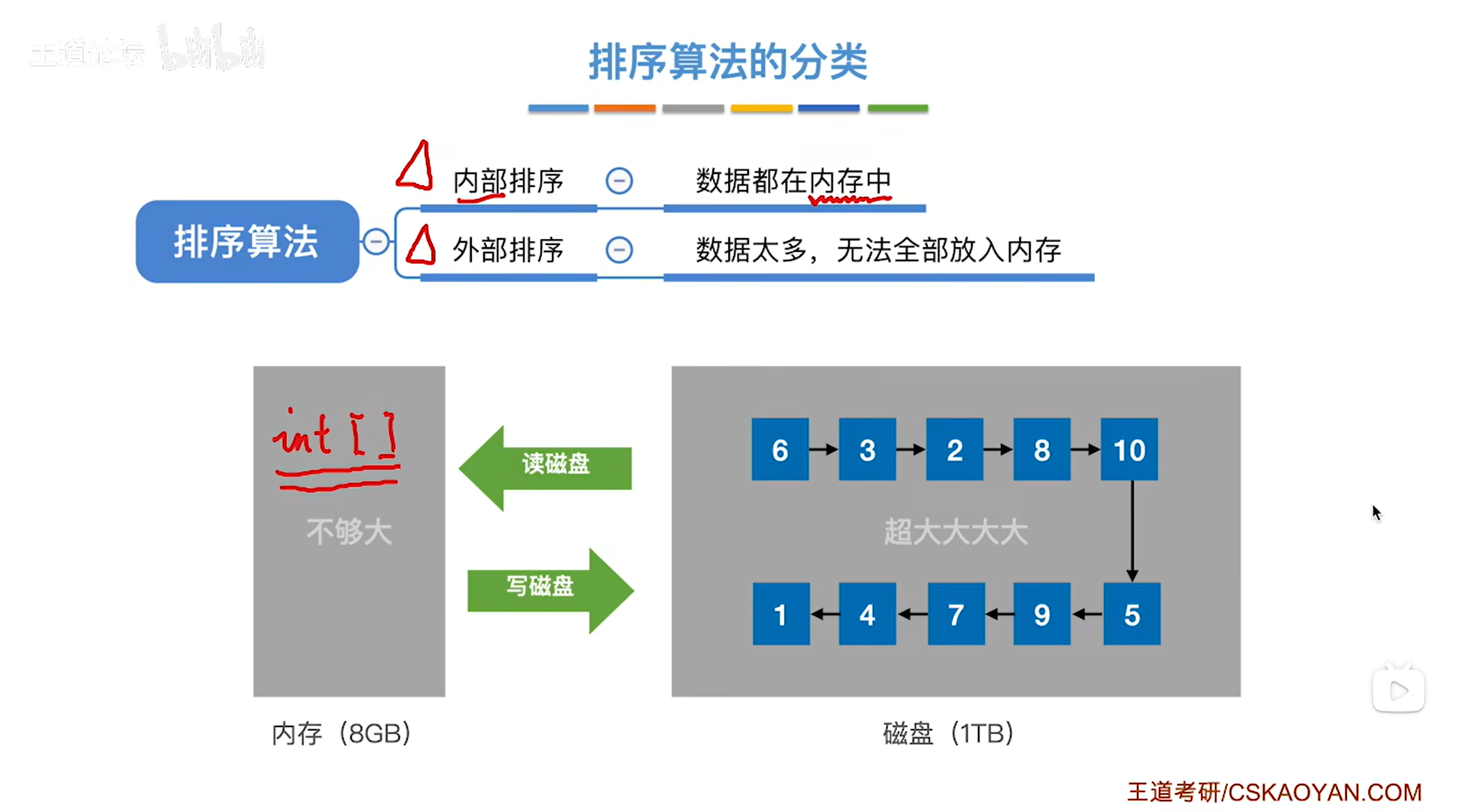
2.外部排序:
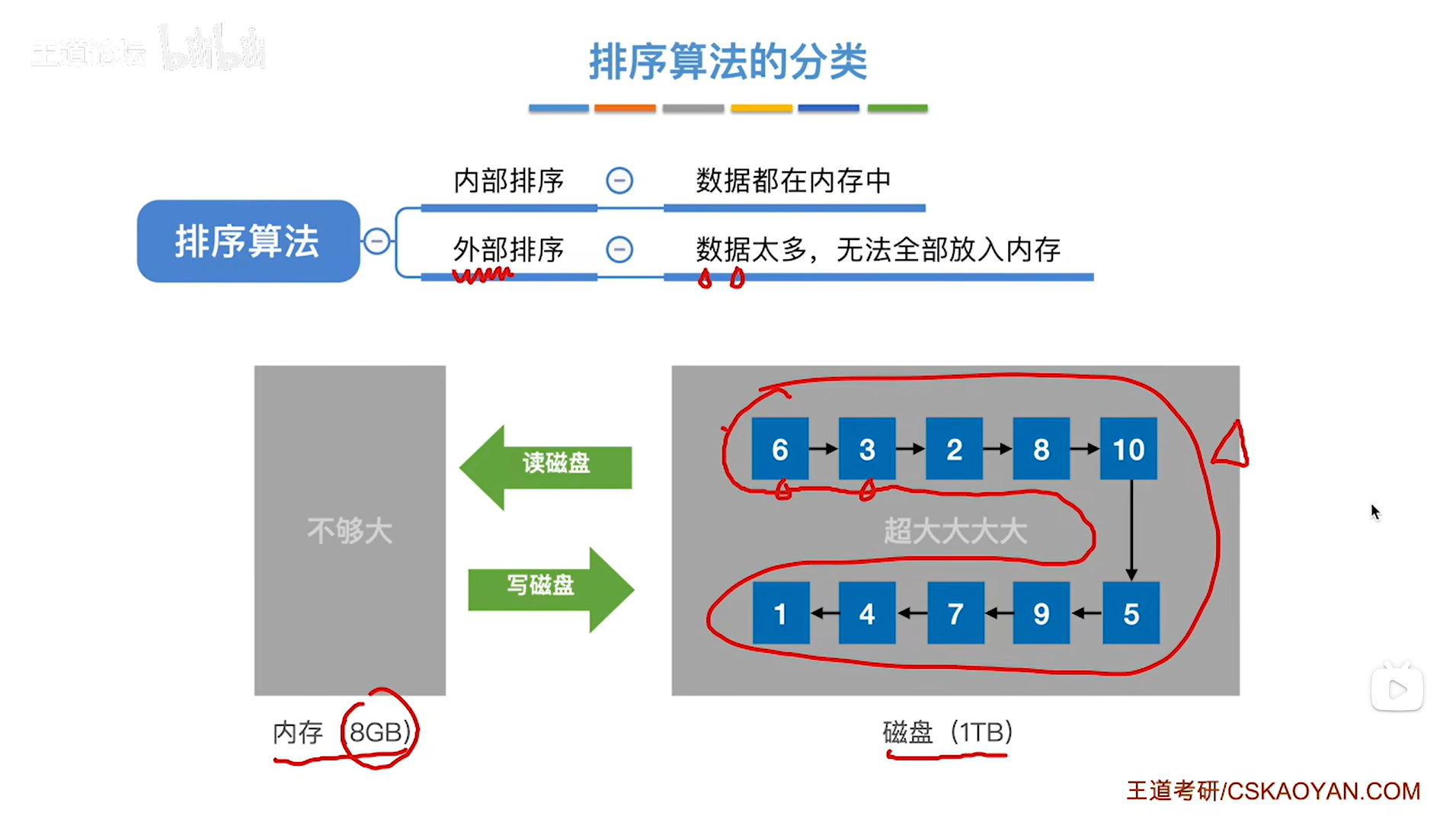
如上图,
有时会遇到要排序的数据元素的数据量很大的情况,此时无法全部放入内存中,但外存磁盘的容量通常很大,而内存相对来说要小一些,
比如有一个非常大的文件,这个文件的数据量远远超出了8GB即超出了内存容量,此时就没办法把文件里的所有数据全部一次性放入内存,这种情况下要对这个文件里的数据进行排序,就只能采取一部分一部分处理的策略。
三.内部排序与外部排序的设计注意点:
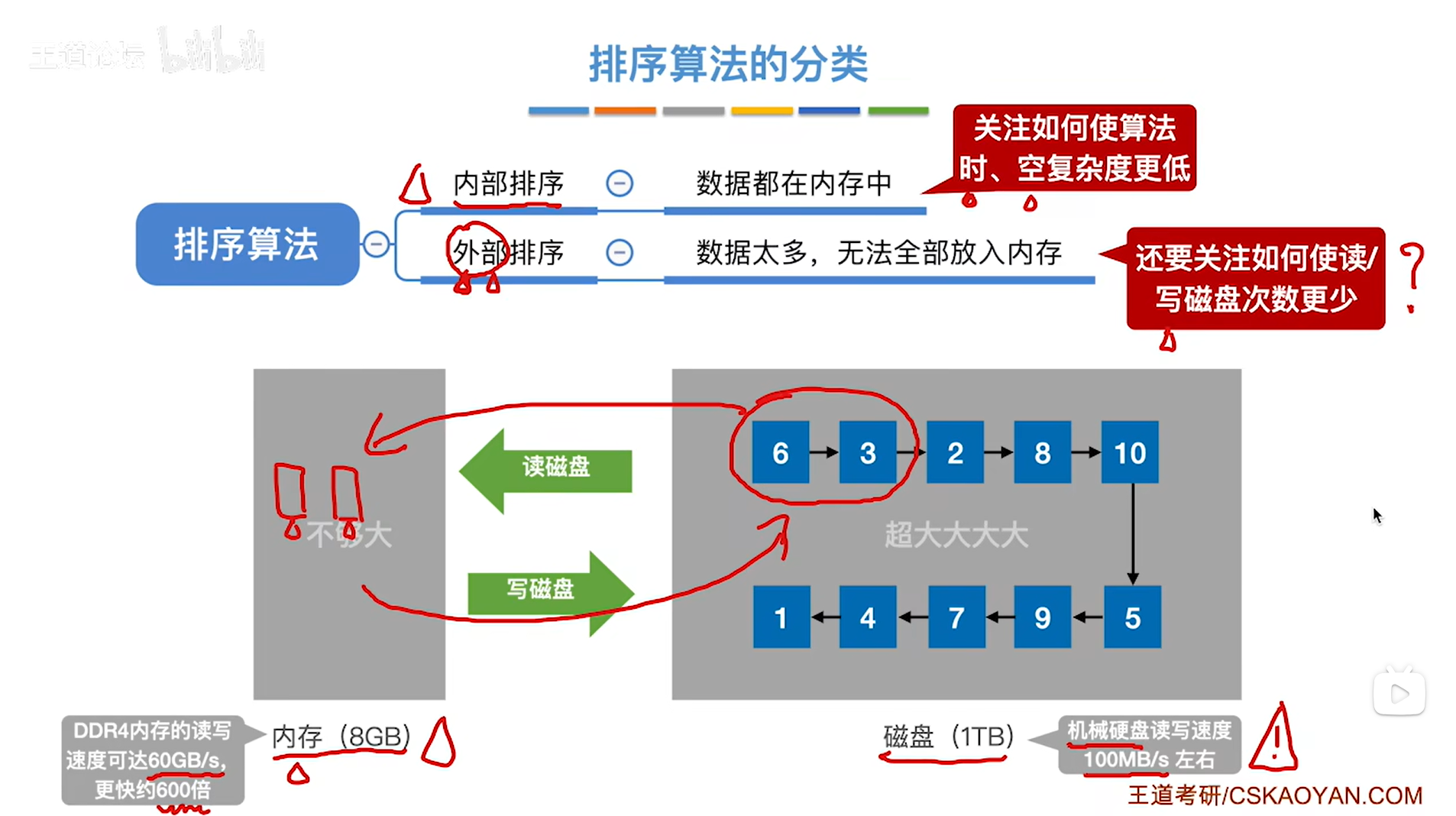
如上图,
对于内部排序,由于对数据的处理全部在内存中进行,而内存又是一个高速的设备,所以在设计内部算法的时候,往往更多地是关注算法的时间复杂度、空间复杂度是怎么样的;
对于外部排序,设计外部排序算法的时候,除了算法的时间复杂度与空间复杂度之外,还需要关注如何使得读写磁盘的次数更少,因为对于磁盘的读写速度往往很慢,比如对于一个机械硬盘来说,读写速度可以达到100兆字节每秒,相比之下内存的读写速度可以达到60GB/s,也就是比机械硬盘快600倍左右,如果要进行外部排序,就意味着要把磁盘当中存储的数据先读入内存,在内存中处理完毕之后再写回磁盘,这一读一写的过程有可能会因为机械硬盘的读写速度很慢而导致花费很多的时间,而一旦这些数据读入内存之后,由于内存的速度很快,所以对这些数据的处理不会消耗太多时间,所以在设计外部排序算法的时候也需要关注怎么使读写磁盘的次数更少。
四.总结:
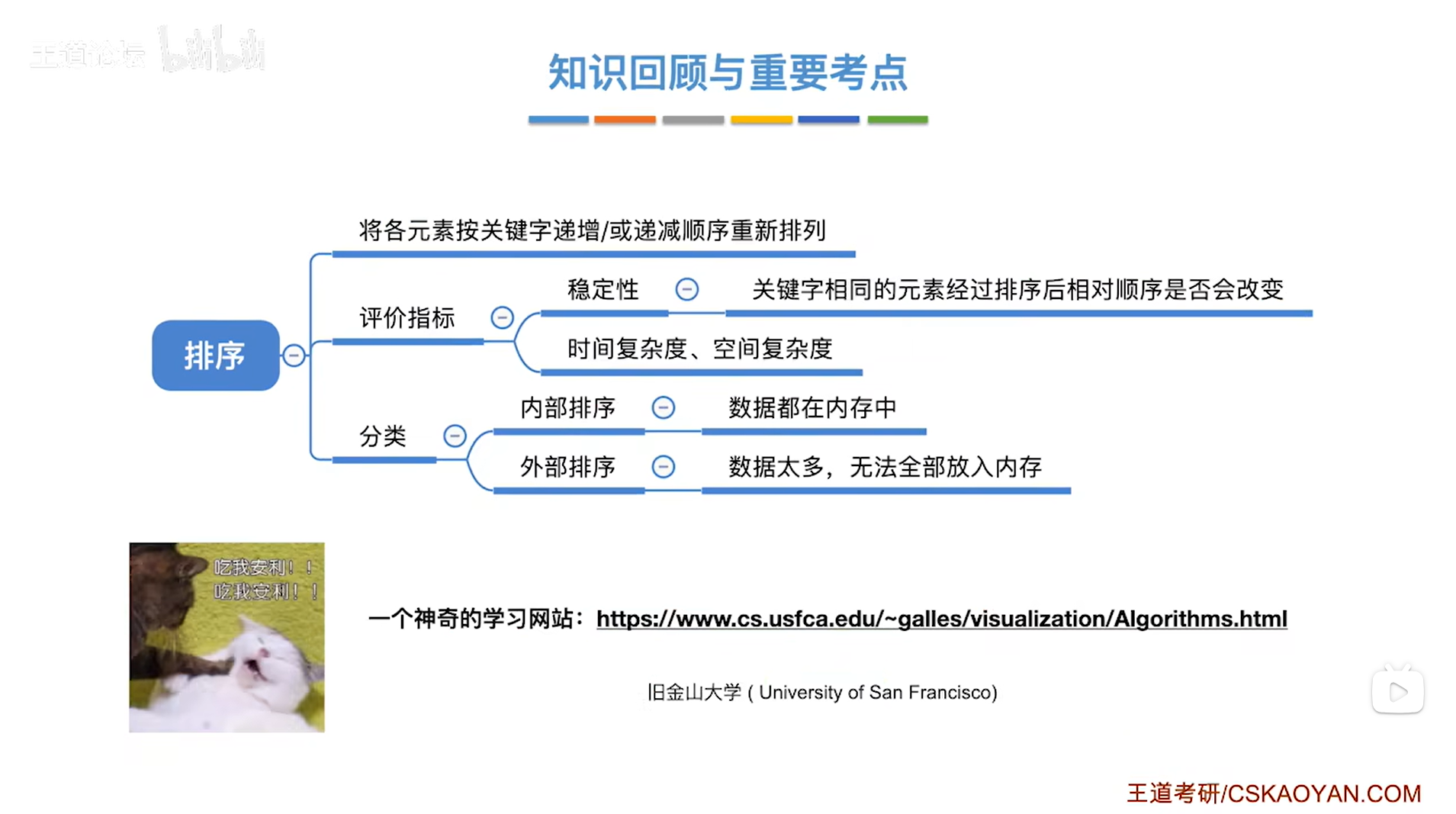
如上图,
有一个网站(电脑/手机上的浏览器都可以),来自于美国的旧金山大学,这个网站可以帮助我们可视化地理解很多算法,
如下图:
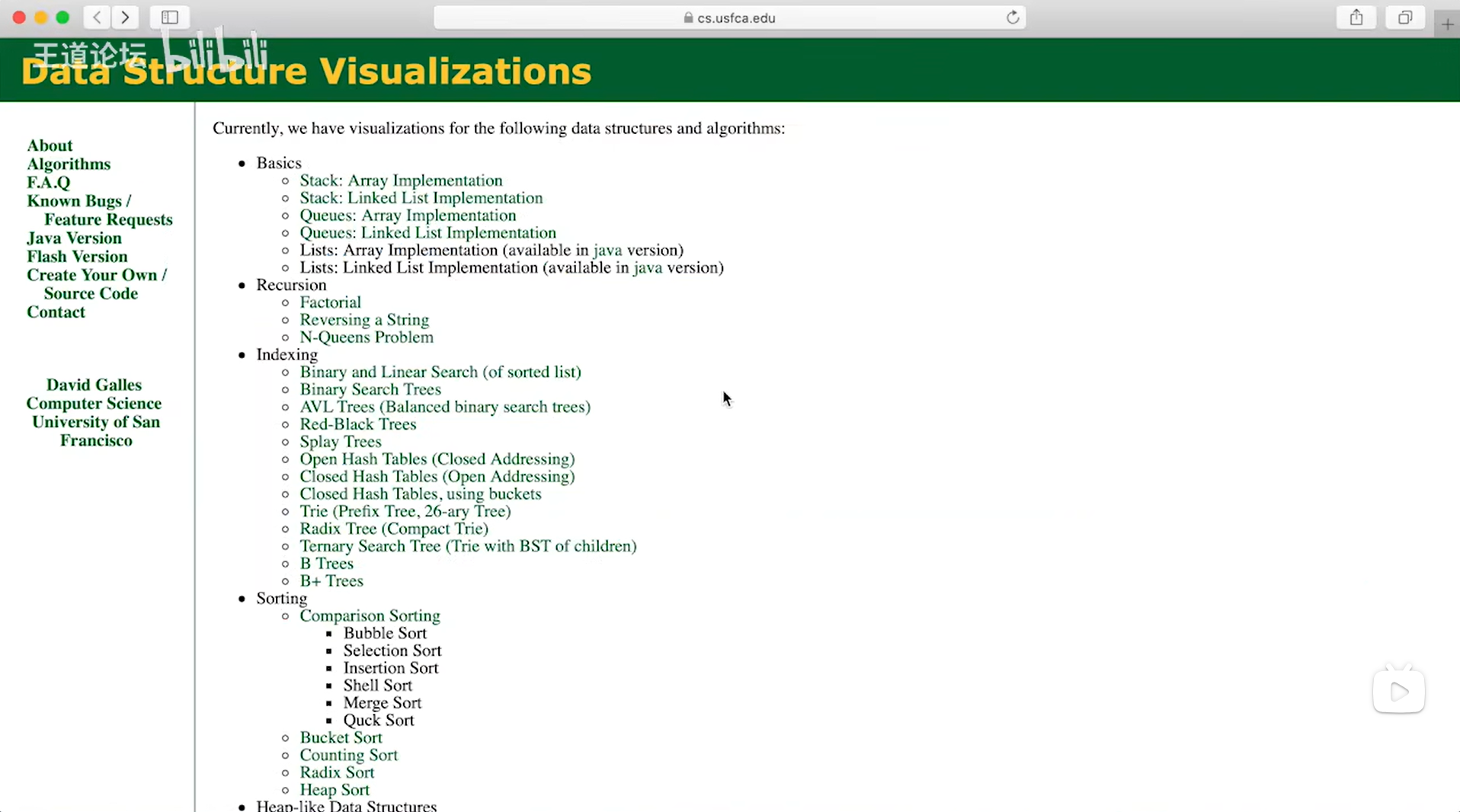
如上图,
比如Sorting就是关于排序算法的可视化模拟工具,点击Sorting里的某一项,
如下图:
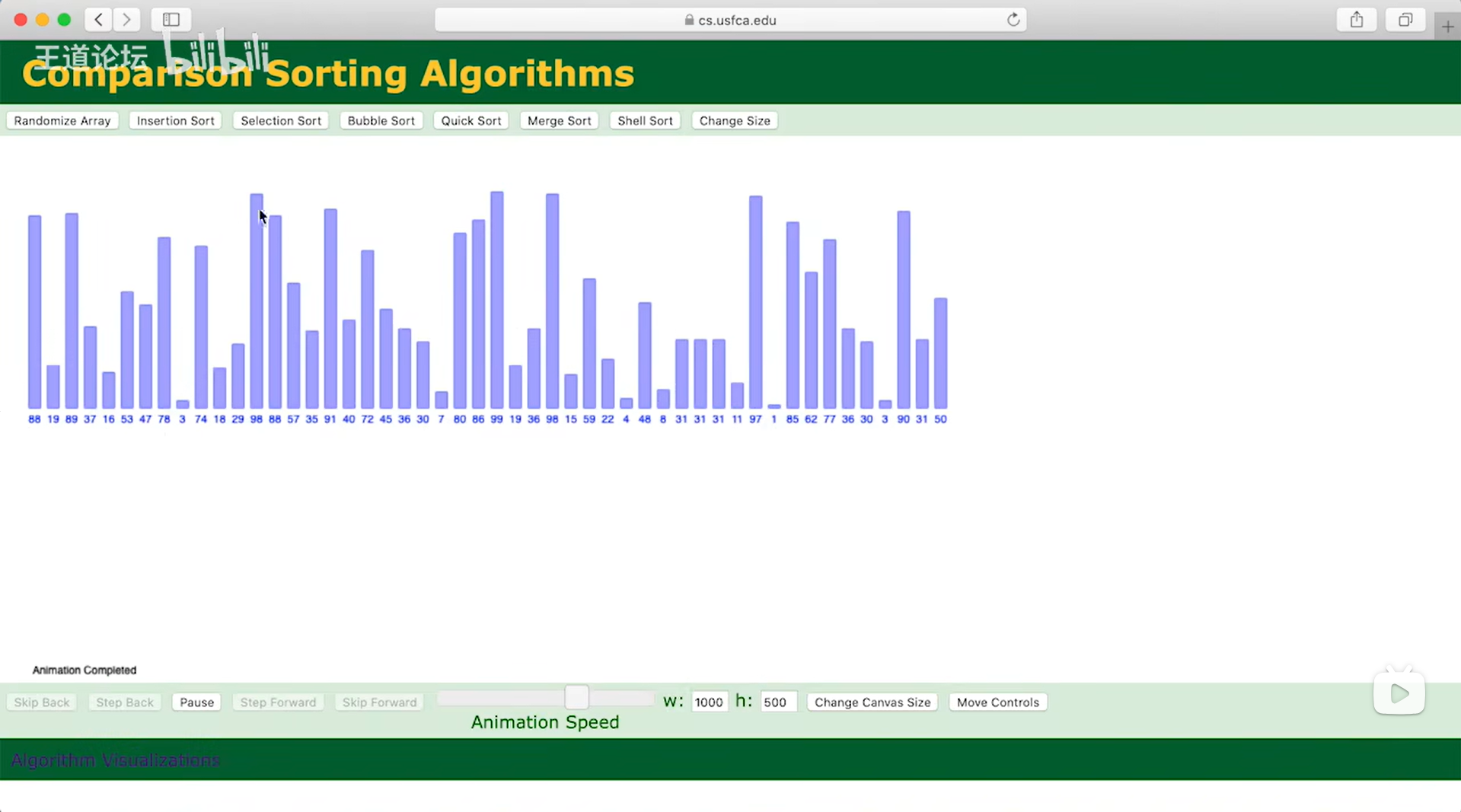
以上述图片为例,
自动生成了一个数组,数值就是每一个元素的关键字,竖条的高低就反映了关键字的大小,
左上角Randomize Array可用于随机重新生成一个数组,
如下图:
如上图,
假如此时想看冒泡排序,可以点击Bubble Sort,之后就会一步一步地演示这个算法的过程,中间下方的Animation Speed可用于改算法运行速度,如果感觉运行太快,可以点击下方的Pause暂停这个算法,
如下图:
如上图,
每点击一下Step Forward,算法才会往后运行一步。