从0开始学习R语言--Day19--连续变量的相关性检验
昨天我们学习了分类变量的检验方法,今天我们来看看连续性变量的相关性检验方法。
Pearson
一般来说,person适用于两个变量之间满足线性的单调关系,像我们常说的单调递增或单调递减,且我们的变量是连续且正态分布的。简单来说,就是变量拥有无限的可能性,比如身高可能是160.1,160.9,185.32等等,且大部分的值都在平均值附近(比如一个城市成年男性的平均身高)。听起来似乎很简单,但有时候可以有助于帮我们判断数据里是否有异常值,因为pearson对非线性的关系和异常值很敏感(毕竟所画的图不再是直线),从而可以在数据分析前进行数据清洗。
以下是一个应用例子:
# 生成线性相关数据
set.seed(42)
height <- rnorm(100, mean = 170, sd = 10)
weight <- 0.6 * height + rnorm(100, mean = 0, sd = 5)# 计算Pearson相关
pearson_test <- cor.test(height, weight, method = "pearson")
print(pearson_test)# 可视化
library(ggplot2)
ggplot(data.frame(height, weight), aes(x = height, y = weight)) +geom_point() +geom_smooth(method = "lm", se = FALSE) +ggtitle(paste("Pearson相关 r =", round(pearson_test$estimate, 2))) +theme_minimal()输出:
Pearson's product-moment correlationdata: height and weight
t = 13.998, df = 98, p-value < 2.2e-16
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:0.7384722 0.8728963
sample estimates:cor
0.8164629 `geom_smooth()` using formula = 'y ~ x'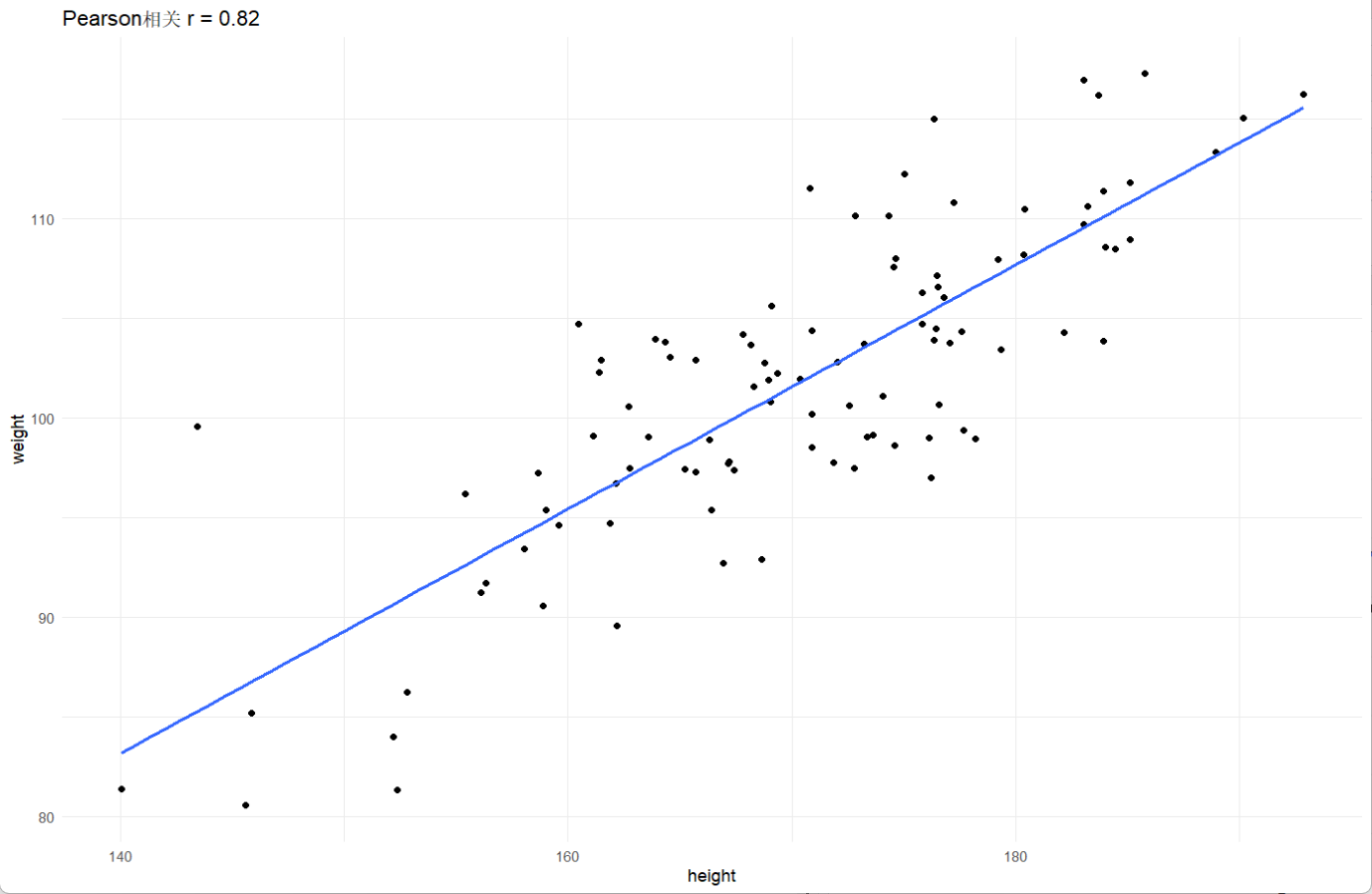
从结果可以分析得出,(r)为0.816很靠近1,说明身高与体重是强正相关;而p小于0.001且95%置信区间落在[0.738, 0.873],进一步地为强相关性的结论增强了说服力。
Spearman
与pearson不同的是,这个方法对数据没有那么多要求,且由于其会在分析前将数据转换为秩次(也就是转换为数据的大小排序),这样的好处是可以排除掉异常值的影响,因为不管异常值是极大还是极小,从大小排序来看,其都是第一或最后一个,不会以离散的身份出现在数据里。这样的数据特点,适合让我们分析他们的单调关系,同时不需要硬性规定其是线性变化的。适合应用于分析比如焦虑程度与睡眠质量、药物剂量与疗效高低、收入等级与幸福感指数等可以用排名量化的问题,要注意这里由于加入了秩次的处理方法,是没有数据的实际信息的。
以下是一个应用例子:
# 生成单调但非线性数据
set.seed(42)
income <- runif(100, 1000, 10000)
happiness <- log(income) + rnorm(100, mean = 0, sd = 0.3)# 计算Spearman相关
spearman_test <- cor.test(income, happiness, method = "spearman")
print(spearman_test)# 可视化
ggplot(data.frame(income, happiness), aes(x = income, y = happiness)) +geom_point() +geom_smooth(method = "loess", se = FALSE) +ggtitle(paste("Spearman相关 ρ =", round(spearman_test$estimate, 2))) +theme_minimal()输出:
Spearman's rank correlation rhodata: income and happiness
S = 18262, p-value < 2.2e-16
alternative hypothesis: true rho is not equal to 0
sample estimates:rho
0.890417`geom_smooth()` using formula = 'y ~ x'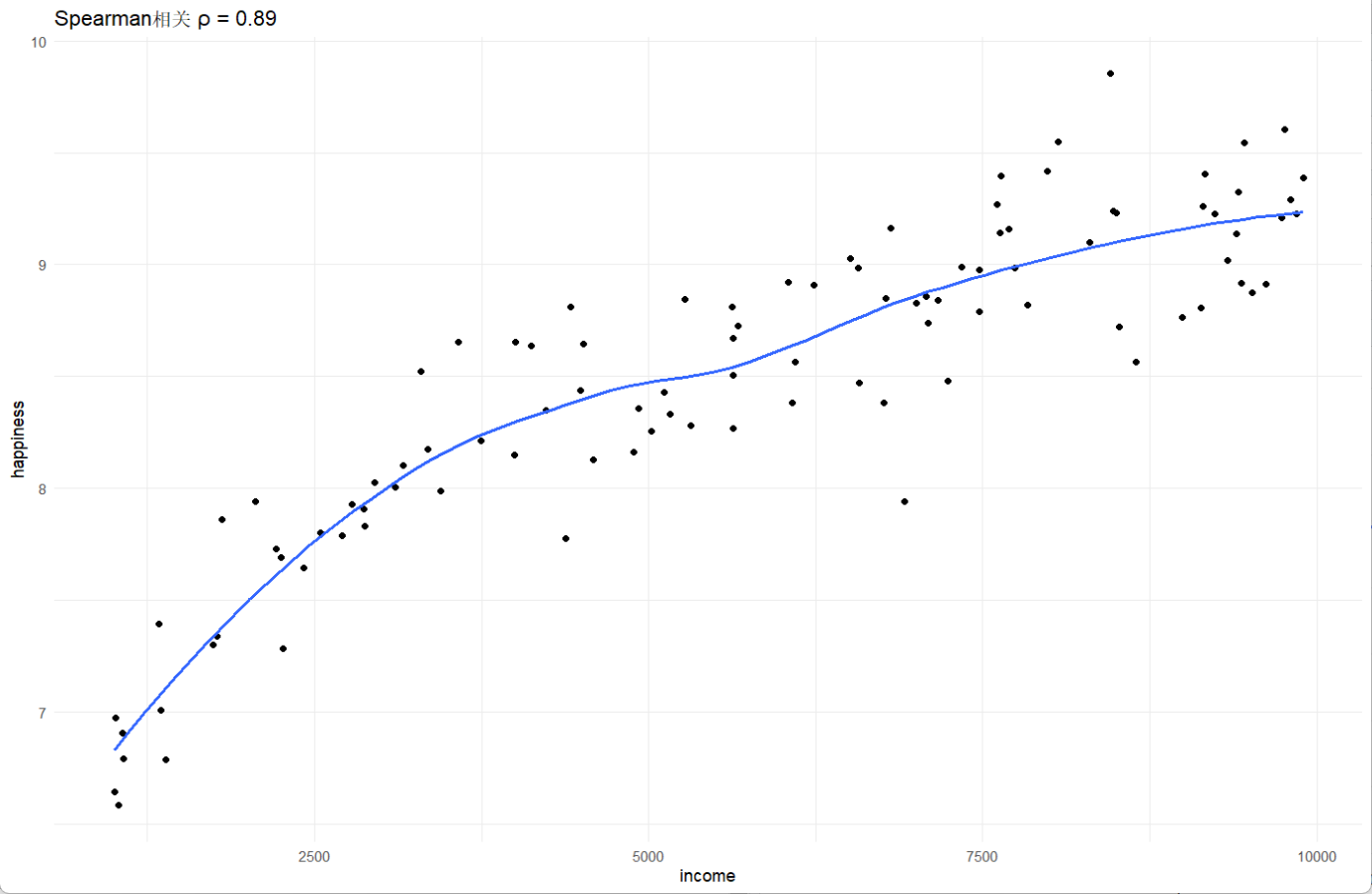
从结果可以看到,Spearman's rho (ρ)为0.89,说明两者是强相关性,处于一个很明显的单调递增,而p-value远小于0.05,说明相关性显著,两个变量不相关的假设不成立。
Kendall's Tau
与前两者不同的是,这个方法会有做对照实验的思想在。之所以会这样作是因为在这类方法的应用场景中,两类数据会有很多相同点,比如评估两位评委对参赛作品排名的一致性、比较新旧两种诊断方法对疾病严重程度的分类一致性、比较不同年份物种丰富度的排序变化等等,重在反映数据对的一致性比例。需要注意的是,由于这个方法是要对数据点进行一一对应比较,如果样本集数据量过大,计算的效率会很低。
以下是一个应用例子:
# 生成有序数据(可能有并列值)
set.seed(42)
judge1 <- sample(1:5, 50, replace = TRUE)
judge2 <- judge1 + sample(-1:1, 50, replace = TRUE)
judge2 <- pmin(pmax(judge2, 1), 5) # 限制在1-5范围内# 计算Kendall's Tau
kendall_test <- cor.test(judge1, judge2, method = "kendall")
print(kendall_test)# 可视化
library(ggbeeswarm)
ggplot(data.frame(judge1, judge2), aes(x = factor(judge1), y = judge2)) +geom_quasirandom(width = 0.2, alpha = 0.7) +stat_summary(fun = median, geom = "crossbar", width = 0.5, color = "red") +ggtitle(paste("Kendall's τ =", round(kendall_test$estimate, 2))) +labs(x = "评委1评分", y = "评委2评分") +theme_minimal()输出:
Kendall's rank correlation taudata: judge1 and judge2
z = 6.8568, p-value = 7.044e-12
alternative hypothesis: true tau is not equal to 0
sample estimates:tau
0.7938499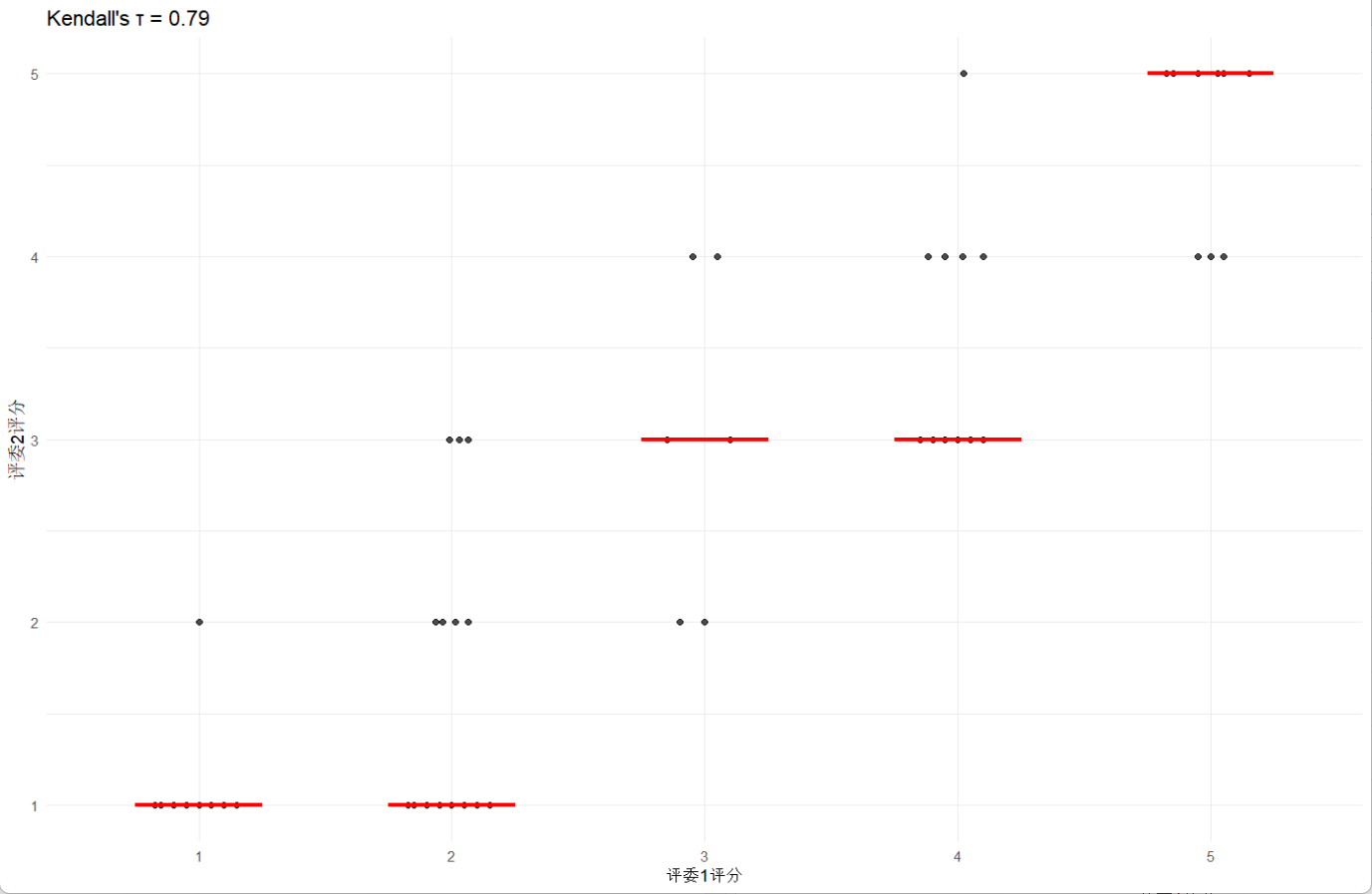
(τ)为0.794大于0.7,说明两位评委的打分高度一致;而z = 6.8568, p-value = 7.044e-12则说明结论的高度显著,说明评委打分之间是有关系的。