[蓝桥杯]填字母游戏
填字母游戏
题目描述
小明经常玩 LOL 游戏上瘾,一次他想挑战 K 大师,不料 K 大师说:
"我们先来玩个空格填字母的游戏,要是你不能赢我,就再别玩 LOL 了"。
K 大师在纸上画了一行 nn 个格子,要小明和他交替往其中填入字母。
并且:
-
轮到某人填的时候,只能在某个空格中填入 L 或 O。
-
谁先让字母组成了"LOL"的字样,谁获胜。
-
如果所有格子都填满了,仍无法组成 LOL,则平局。
小明试验了几次都输了,他很惭愧,希望你能用计算机帮他解开这个谜。
输入描述
本题的输入格式为:
第一行,数字 nn(n<10n<10),表示下面有 nn 个初始局面。
接下来,nn 行,每行一个串,表示开始的局面。
比如:"******", 表示有 6 个空格。"L****", 表示左边是一个字母 L,它的右边是 4 个空格。
输出描述
要求输出 nn 个数字,表示对每个局面,如果小明先填,当 K 大师总是用最强着法的时候,小明的最好结果。
1 表示能赢;
-1 表示必输;
0 表示可以逼平。
输入输出样例
示例
输入
4
***
L**L
L**L***L
L*****L
输出
0
-1
1
1
运行限制
- 最大运行时间:3s
- 最大运行内存: 256M
总通过次数: 601 | 总提交次数: 737 | 通过率: 81.5%
难度: 困难 标签: 2017, 国赛, 博弈
填字母游戏:博弈论与记忆化搜索解法
🌟 算法思路
本问题是一个典型的博弈论问题,需要模拟小明和K大师的交替填字母过程。核心思路是DFS+记忆化搜索:
- 博弈状态分析:
- 当前玩家在空格处填L或O后,判断是否形成"LOL"
- 若形成则获胜;若填满未形成则平局;否则交给对手
- 必胜/必败态判断:
- 必胜态:存在一种走法使对手必败
- 必败态:所有走法都使对手必胜
- 平局:无空格且未形成LOL
- 记忆化优化:存储已计算局面结果,避免重复计算
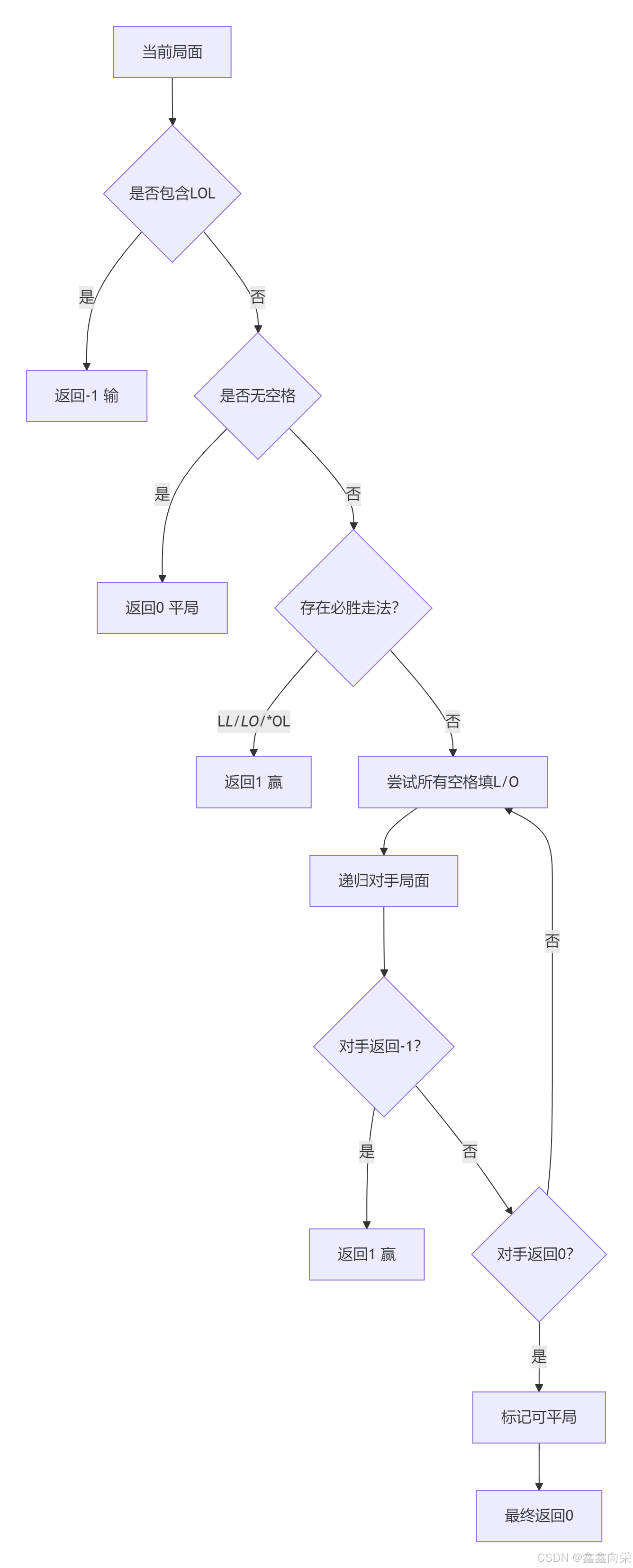
📝 算法步骤
-
局面预处理:
- 检查当前局面是否包含"LOL" → 返回-1
- 检查是否无空格 → 返回0
- 检查是否存在必胜走法(LL, LO, *OL) → 返回1
-
DFS搜索:
- 遍历每个空格位置
- 尝试填入L和O两种选择
- 递归计算对手局面的结果
- 回溯恢复局面
-
结果判定:
- 若存在使对手返回-1的走法 → 当前必胜(返回1)
- 若所有走法对手都返回1 → 当前必败(返回-1)
- 若存在平局可能 → 返回0
-
记忆化存储:
- 使用
unordered_map存储局面-结果映射 - 递归前查询,计算后存储
🧠 代码实现(C++)
#include <iostream> #include <unordered_map> #include <string> using namespace std;unordered_map<string, int> memo; // 记忆化存储int dfs(string s) {// 1. 记忆化查询if (memo.find(s) != memo.end()) return memo[s];// 2. 失败条件:出现LOLif (s.find("LOL") != string::npos) return memo[s] = -1;// 3. 平局条件:无空格且无LOLif (s.find('*') == string::npos) return memo[s] = 0;// 4. 必胜走法检测if (s.find("L*L") != string::npos || s.find("LO*") != string::npos || s.find("*OL") != string::npos) return memo[s] = 1;bool canDraw = false; // 平局标志// 5. 尝试所有空格for (int i = 0; i < s.size(); i++) {if (s[i] == '*') {// 尝试填Ls[i] = 'L';int resL = dfs(s);s[i] = '*'; // 回溯if (resL == -1) // 对手输→当前赢return memo[s] = 1;if (resL == 0) canDraw = true;// 尝试填Os[i] = 'O';int resO = dfs(s);s[i] = '*'; // 回溯if (resO == -1) // 对手输→当前赢return memo[s] = 1;if (resO == 0) canDraw = true;}}// 6. 结果判定return memo[s] = (canDraw ? 0 : -1); }int main() {ios::sync_with_stdio(false);cin.tie(0);int n;cin >> n;cin.ignore(); // 清除换行符while (n--) {string board;getline(cin, board);memo.clear(); // 清空记忆化cout << dfs(board) << endl;}return 0; }📊 代码解析
-
核心函数
dfs:- 参数:当前局面字符串
- 返回值:1(赢)/0(平)/-1(输)
- 处理流程:
- 优先查记忆化表
- 判断终止条件(输/平/赢)
- 递归尝试所有走法
-
关键优化:
- 记忆化存储:
unordered_map实现O(1)查询 - 剪枝策略:
- 遇到必胜走法立即返回
- 对手返回-1时立即终止搜索
- 记忆化存储:
-
回溯机制:
s[i] = 'L'; // 修改局面 int res = dfs(s); // 递归 s[i] = '*'; // 回溯 -
🧪 实例验证
输入样例:
4 *** L**L L**L***L L*****L处理过程:
-
"***":- 无必胜走法 → 尝试填L/O
- 所有走法均导致平局 → 返回0
-
"L**L":- 填第一个
*为O →"LO*L"(形成LO*) - 填第二个
*为L →"L*LL"(形成*LL非LOL) - 对手在
"LO*L"填L →"LOL"→ 对手赢 → 返回-1
- 填第一个
-
"L**L***L":- 存在必胜走法:填第三位为O →
"L*OL***L"(形成*OL) - 立即返回1
- 存在必胜走法:填第三位为O →
-
"L*****L":- 填第三位为L →
"L*L***L"(形成L*L) - 立即返回1
- 输出:
0\n-1\n1\n1✓
- 填第三位为L →
-
⚠️ 注意事项
-
输入处理:
- 使用
cin.ignore()清除换行符 getline读取含空格的局面
- 使用
-
回溯关键:
- 修改字符串后必须恢复原状
- 避免局面状态污染
-
记忆化管理:
- 每组数据前清空
memo - 局面字符串为唯一键
- 每组数据前清空
-
边界情况:
- 空字符串(直接平局)
- 长度<3的字符串(无法形成LOL)
-
🔍 多方位测试点
测试类型 测试数据 预期结果 验证要点 必输局面 "L**L"-1 对手必胜走法检测 平局局面 "***"0 无空格处理 必胜局面 "L*L"1 必胜模式识别 长链局面 "L*****L"1 递归深度与性能 边界长度 "**"(长度2)0 短字符串处理 已含LOL "LOL**"-1 失败条件优先判断 记忆化重用 连续相同局面 快速返回 记忆化查询效率 混合局面 "*OL**L*"1 多位置必胜走法识别 💡 优化建议
-
模式识别优化:
// 扩展必胜模式检测 vector<string> winPatterns = {"L*L", "LO*", "*OL", "LOL*", "*LOL"}; for (const auto& pat : winPatterns) {if (s.find(pat) != string::npos) return memo[s] = 1; } -
迭代加深搜索:
- 设置最大递归深度
- 超时返回保守估计值
-
并行化处理:
#pragma omp parallel for for (int i = 0; i < s.size(); i++) {if (s[i] == '*') {// 并行尝试走法} } -
局面对称性优化:
- 识别对称局面(如
"L**L"对称) - 统一存储规范化局面
- 识别对称局面(如
- 使用