MonkeyOCR: 基于结构-识别-关系三元组范式的文档解析
MonkeyOCR采用结构-识别-关系(SRR)三元范式,既简化了模块化方法的多工具流程,又避免了使用大型多模态模型处理整页文档的低效问题。
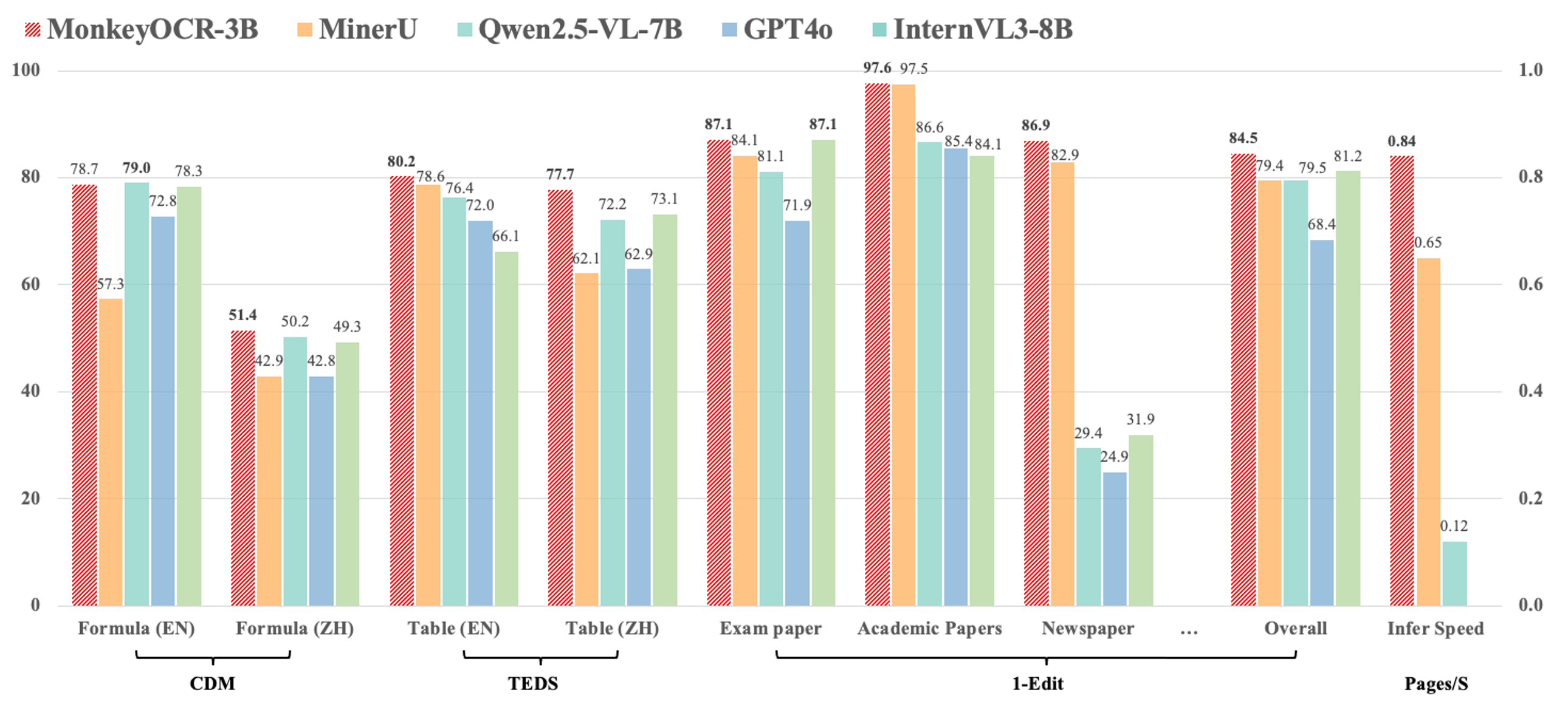
- 相比基于流程的MinerU方法,我们的方案在九类中英文文档上平均提升5.1%,其中公式识别提升15.0%,表格识别提升8.6%;
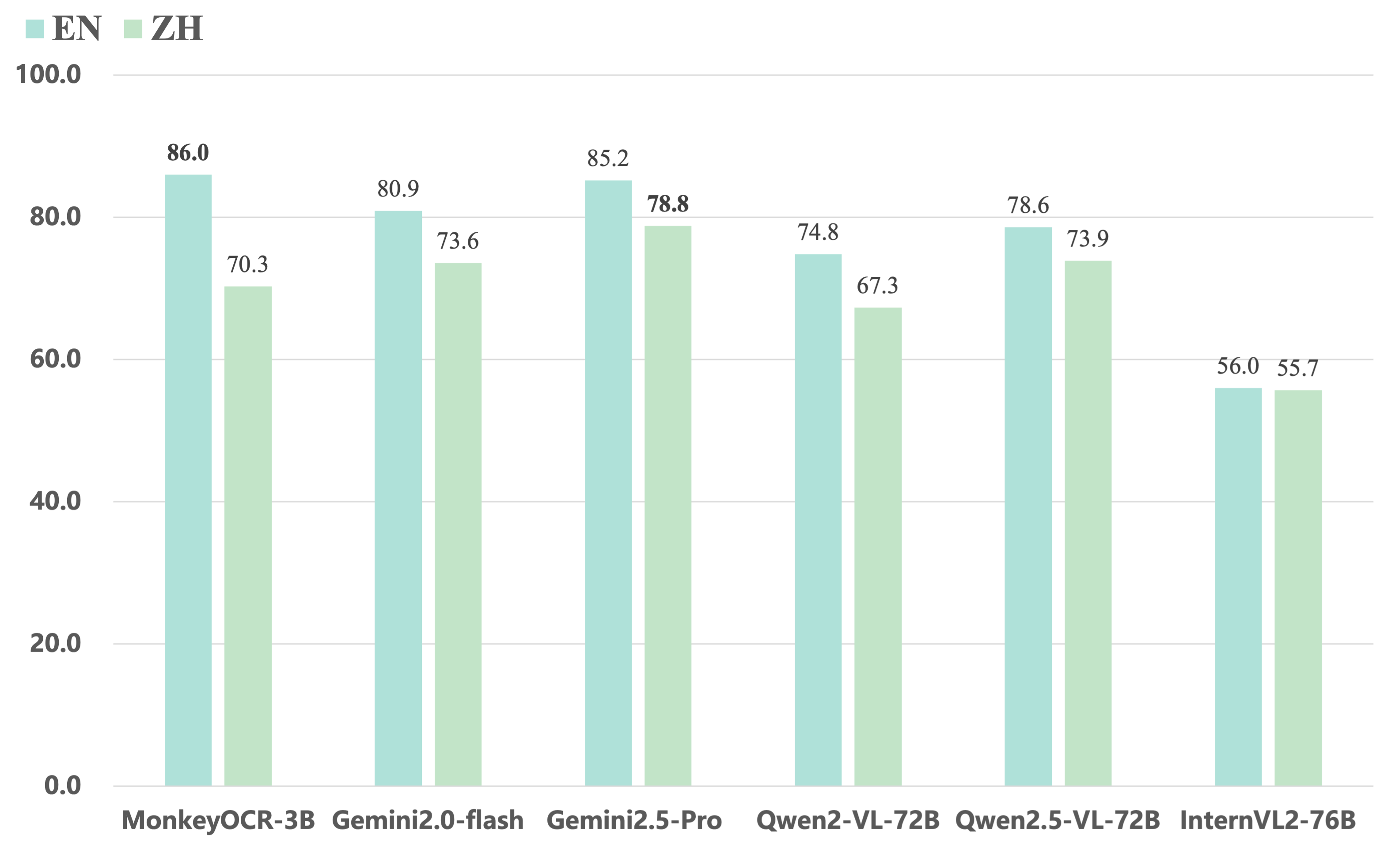
- 相比端到端模型,我们30亿参数的模型在英文文档上取得最佳平均性能,超越Gemini 2.5 Pro和Qwen2.5 VL-72B等模型;
- 在多页文档解析场景,我们的方法处理速度达0.84页/秒,优于MinerU(0.65)和Qwen2.5 VL-7B(0.12)。
MonkeyOCR目前暂不支持拍摄文件,但我们会在后续更新中持续改进,敬请期待!当前我们的模型部署在单张GPU上,因此如果太多用户同时上传文件,可能会出现“该应用当前繁忙”的情况。我们正在积极支持Ollama等部署方案,力求为更多用户提供更流畅的使用体验。另外请注意,演示页面上显示的处理时间不只是计算时间,还包括结果上传等开销,在流量高峰期可能会更长。MonkeyOCR、MinerU和Qwen2.5 VL-7B的推理速度是在H800 GPU上测得的。
新闻
2025.06.05 🚀 我们发布了MonkeyOCR,支持解析各类中英文文档。
快速入门
- 安装MonkeyOCR
conda create -n MonkeyOCR python=3.10
conda activate MonkeyOCRgit clone https://github.com/Yuliang-Liu/MonkeyOCR.git
cd MonkeyOCR# Install pytorch, see https://pytorch.org/get-started/previous-versions/ for your cuda version
pip install torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 --index-url https://download.pytorch.org/whl/cu124
pip install -e .
- 下载模型权重
从Huggingface下载我们的模型。
pip install huggingface_hubpython tools/download_model.py
你也可以从ModelScope下载我们的模型。
pip install modelscopepython tools/download_model.py -t modelscope
- 推理
# Make sure in MonkeyOCR directory
python parse.py path/to/your.pdf
# or with image as input
pyhton parse.py path/to/your/image
# Specify output path and model configs path
python parse.py path/to/your.pdf -o ./output -c config.yaml
输出结果
MonkeyOCR 生成三种类型的输出文件:
- 处理后的 Markdown 文件 (
your.md):最终解析的文档内容,采用 markdown 格式,包含文本、公式、表格等结构化元素。 - 版面分析结果 (
your_layout.pdf):在原始 PDF 上绘制的版面分析结果。 - 中间区块结果 (
your_middle.json):包含所有检测区块详细信息的 JSON 文件,包括:- 区块坐标和位置信息
- 区块内容及类型信息
- 区块间的关联信息
这些文件既提供最终格式化输出,也包含详细的中间结果,可用于进一步分析或处理。
4. Gradio演示
# 准备gradio运行环境
pip install gradio==5.23.3
pip install pdf2image==1.17.0# 启动演示
python demo/demo_gradio.py
修复RTX 3090/4090等显卡的共享内存错误(可选)
我们的30亿参数模型可以在NVIDIA RTX 3090上高效运行。但使用LMDeploy作为推理后端时,在RTX 3090/4090显卡上可能会遇到兼容性问题,特别是以下错误:
triton.runtime.errors.OutOfResources: out of resource: shared memory可以通过以下补丁解决该问题:
python tools/lmdeploy_patcher.py patch
⚠️ 注意:该命令会修改你环境中LMDeploy的源代码。如需恢复修改,只需运行:
python tools/lmdeploy_patcher.py restore
特别感谢 @pineking 提供的解决方案!
切换推理后端(可选)
您可以通过以下步骤将推理后端切换至 transformers:
-
安装必要依赖(如尚未安装):
# install flash attention 2, you can download the corresponding version from https://github.com/Dao-AILab/flash-attention/releases/ pip install flash-attn==2.7.4.post1 --no-build-isolation -
打开 model_configs.yaml 文件
-
将 chat_config.backend 设置为 transformers
-
根据 GPU 内存容量调整 batch_size 以确保性能稳定
示例配置:
chat_config:backend: transformersbatch_size: 10 # Adjust based on your available GPU memory
基准测试结果
以下是我们模型在OmniDocBench上的评估结果。MonkeyOCR-3B使用DocLayoutYOLO作为结构检测模型,而MonkeyOCR-3B*使用我们训练的结构检测模型,在中文性能上有所提升。