LlamaIndex 工作流 上下文状态和流式传输事件
上下文(Context)状态
到目前为止,在我们的示例中,我们一直通过自定义事件的属性在各个步骤之间传递数据。这是一种强大的数据传递方式,但它也存在一些局限性。例如,如果你想在那些并非直接相连的步骤之间传递数据,你就需要通过中间的所有步骤来传递这些数据。这会使你的代码变得更难阅读和维护。
为避免这一问题,我们在工作流中的每个步骤都可以使用一个 Context(上下文) 对象。要使用它,只需在你的步骤函数中声明一个类型为 Context 的参数即可。以下是具体的做法:
我们需要一个新的导入内容,即 Context 类型:
from llama_index.core.workflow import (StartEvent,StopEvent,Workflow,step,Event,Context,
)现在,我们定义一个 start 事件,它会检查是否有数据已经被加载到上下文中。如果没有,它将返回一个 QueryAccountEvent,触发用于加载数据的 step_query_account步骤,并循环回到 start。
然后在 step_query_account中,我们可以直接从上下文中访问数据,而无需显式传递。在生成式 AI 应用中,这种方法对于加载索引和其他大型数据操作非常有用。
import asynciofrom llama_index.core.workflow import (StartEvent,StopEvent,Workflow,step,Event,Context,
)
from llama_index.utils.workflow import draw_all_possible_flowsclass QueryAccountEvent(Event):payload: strclass SaveAccountEvent(Event):payload: strclass AccountWorkflow(Workflow):@stepasync def start(self, ctx: Context, ev: StartEvent)-> QueryAccountEvent | SaveAccountEvent:# 从上下文中获取数据,获取账户信息db_account = await ctx.get("account", default=None)# 如果账户不存在,则从数据库中查询账户信息if db_account is None:return QueryAccountEvent(payload=f"{ev.payload}--->未查询到账户信息,执行查询节点: step_query_account")return SaveAccountEvent(payload=f"{ev.payload}--->从ctx中获取到了张三的账户,跳转到节点: step_save_account")@stepasync def step_query_account(self, ctx: Context, ev: QueryAccountEvent)-> StartEvent:"""查询张三账户信息"""await ctx.set("account", {"name": "张三", "balance": 0.0})return StartEvent(payload=f"{ev.payload}--->查询张三账户信息,并保证到ctx中,然后跳转到开始节点: start")@stepasync def step_save_account(self, ctx: Context, ev: SaveAccountEvent)-> StopEvent:account = await ctx.get("account")account['balance'] += 1000000000await ctx.set("account", account)return StopEvent(result=f"{ev.payload}--->工作流完成,账户信息: {account}")# 运行工作流
async def run_workflow():w = AccountWorkflow(timeout=10, verbose=False)result = await w.run(payload="给张三的账户打一个小目标")print(result)if __name__ == '__main__':asyncio.run(run_workflow())# 工作流可视化工具
draw_all_possible_flows(AccountWorkflow, filename="multi_step_workflow.html") # type: ignore运行结果:
给张三的账户打一个小目标--->未查询到账户信息,执行查询节点: step_query_account--->查询张三账户信息,并保证到ctx中,然后跳转到开始节点: start--->从ctx中获取到了张三的账户,跳转到节点: step_save_account--->工作流完成,账户信息: {'name': '张三', 'balance': 1000000000.0}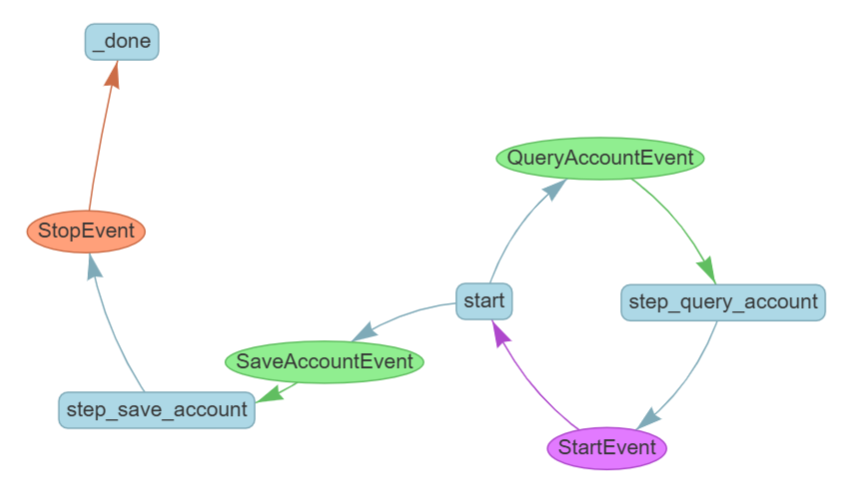
接下来,我们将学习如何从正在进行的工作流中流式传输事件。
流式传输事件
工作流可能会很复杂——它们被设计用来处理复杂的、有分支的、并发的逻辑——这意味着它们可能需要一定时间才能完全执行。为了给用户提供良好的体验,你可能希望在事件发生时通过流式传输事件来提供进度反馈。工作流在上下文(Context)对象上对此提供了内置支持。
为了完成这个任务,我们先引入所有需要的依赖项:
from llama_index.core.workflow import (StartEvent,StopEvent,Workflow,step,Event,Context,
)
import asyncio
from llama_index.llms.openai import OpenAI
from llama_index.utils.workflow import draw_all_possible_flows让我们为一个简单的三步工作流设置一些事件,并额外添加一个事件用于在执行过程中流式传输我们的进度:
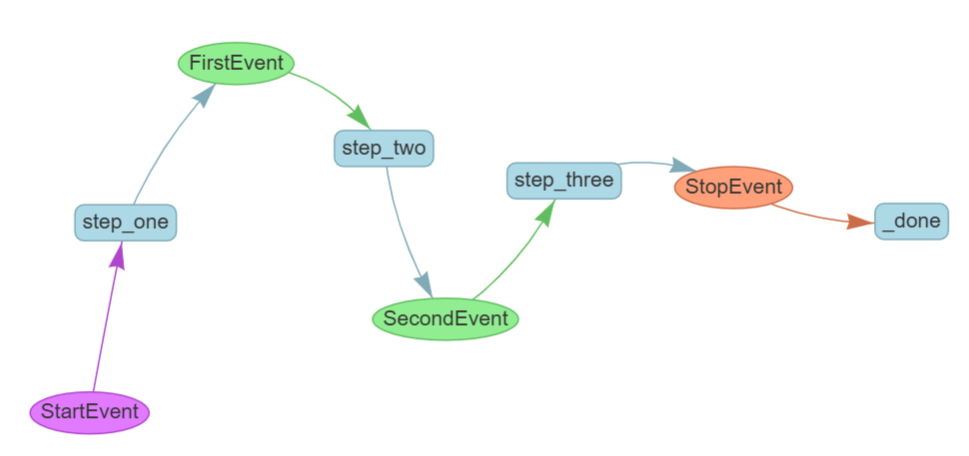
class FirstEvent(Event):first_output: strclass SecondEvent(Event):second_output: strresponse: strclass ProgressEvent(Event):msg: str然后定义一个会发送事件的工作流类:
class MyWorkflow(Workflow):@stepasync def step_one(self, ctx: Context, ev: StartEvent)-> FirstEvent:ctx.write_event_to_stream(ProgressEvent(msg='第一步正在进行中'))return FirstEvent(first_output="第一步完成")@stepasync def step_two(self, ctx: Context, ev: FirstEvent)-> SecondEvent:llms = MyLLMsClients.deepseek_client()generator = await llms.astream_complete("写两句关于春天的诗句")response = ""async for message in generator:response += message.delta# 允许工作流流式传输此段响应。ctx.write_event_to_stream(ProgressEvent(msg=str(response)))return SecondEvent(second_output="第二步完成,附上完整回复",response=str(response),)@stepasync def step_three(self, ctx: Context, ev: SecondEvent)-> StopEvent:ctx.write_event_to_stream(ProgressEvent(msg="第三步正在进行中"))return StopEvent(result="工作流完成")在 step_one 和 step_three 中,我们将单个事件写入事件流。在 step_two 中,我们使用 stream_complete 生成一个可迭代的生成器来获取大语言模型(LLM)的响应,然后在 LLM 返回给我们的每一块数据(大致每个词一块)时生成一个对应的事件,最后再将完整的结果返回给 step_three。
要实际获取这些输出,我们需要异步运行工作流并监听事件,如下所示:
async def run_workflow():w = MyWorkflow(timeout=60, verbose=True)handler = w.run(first_input="开始工作流")async for ev in handler.stream_events():if isinstance(ev, ProgressEvent):print(ev.msg)final_result = await handlerprint("最终结果:", final_result)if __name__ == '__main__':asyncio.run(run_workflow())run 会在后台运行工作流,而 stream_events 将提供写入事件流中的每一个事件。当流返回一个 StopEvent 时,事件流结束,之后你可以像往常一样获取工作流的最终结果。
完整代码
from llama_index.core.workflow import (StartEvent,StopEvent,Workflow,step,Event,Context,
)
import asyncio
from llama_index.llms.openai import OpenAI
from llama_index.utils.workflow import draw_all_possible_flowsfrom my_llms.MyLLMsClients import MyLLMsClientsclass FirstEvent(Event):first_output: strclass SecondEvent(Event):second_output: strresponse: strclass ProgressEvent(Event):msg: strclass MyWorkflow(Workflow):@stepasync def step_one(self, ctx: Context, ev: StartEvent)-> FirstEvent:ctx.write_event_to_stream(ProgressEvent(msg='第一步正在进行中'))return FirstEvent(first_output="第一步完成")@stepasync def step_two(self, ctx: Context, ev: FirstEvent)-> SecondEvent:llms = MyLLMsClients.deepseek_client()generator = await llms.astream_complete("写两句关于春天的诗句")response = ""async for message in generator:response += message.delta# 允许工作流流式传输此段响应。ctx.write_event_to_stream(ProgressEvent(msg=str(response)))return SecondEvent(second_output="第二步完成,附上完整回复",response=str(response),)@stepasync def step_three(self, ctx: Context, ev: SecondEvent)-> StopEvent:ctx.write_event_to_stream(ProgressEvent(msg="第三步正在进行中"))return StopEvent(result="工作流完成")async def run_workflow():w = MyWorkflow(timeout=60, verbose=True)handler = w.run(first_input="开始工作流")async for ev in handler.stream_events():if isinstance(ev, ProgressEvent):print(ev.msg)final_result = await handlerprint("最终结果:", final_result)if __name__ == '__main__':asyncio.run(run_workflow())# 工作流可视化工具
draw_all_possible_flows(MyWorkflow, filename="multi_step_workflow.html")运行结果:
Running step step_one
Step step_one produced event FirstEvent
Running step step_two
第一步正在进行中
Step step_two produced event SecondEvent
1. **"小桃灼灼柳鬖鬖,春色满江南。"**(黄庭坚《诉衷情》)
2. **"等闲识得东风面,万紫千红总是春。"**(朱熹《春日》) 两联皆以简练笔墨勾勒春景,一绘桃柳江南,一写东风烂漫,各具生机。
Running step step_three
Step step_three produced event StopEvent
第三步正在进行中
最终结果: 工作流完成流程图