JPA将大数据量的Excel文件导入到数据库中
在日常的数据处理中,经常碰到Excel的数据,需要将Excel的数据导入到数据库中。
Excel数据的预处理
将sheet分拆为不同的文件
如果一个文件中有太多的sheet,在处理的时候,对计算机的内存要求很高,为了避免内存崩溃。预先将每个sheet分拆带不同的文件
合并单元格拆分
将Excel的合并单元格取消。选择有合并单元格的列,通过点击 合并后居中。
所有的合并单元格列都会自动填充到每一行中
新建SpringBoot项目
可以通过start.aliyun.com的模板来创建

pom文件如下
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.example</groupId><artifactId>dbexcel</artifactId><version>0.0.1-SNAPSHOT</version><name>dbexcel</name><description>dbexcel</description><properties><java.version>1.8</java.version><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding><spring-boot.version>2.6.13</spring-boot.version></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-jdbc</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-jpa</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-jdbc</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>com.mysql</groupId><artifactId>mysql-connector-j</artifactId><scope>runtime</scope></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency>
<!-- <dependency>-->
<!-- <groupId>org.apache.poi</groupId>-->
<!-- <artifactId>poi-ooxml</artifactId>-->
<!-- <version>5.2.3</version>-->
<!-- </dependency>--><dependency><groupId>org.apache.poi</groupId><artifactId>poi</artifactId><version>5.2.3</version></dependency><dependency><groupId>org.apache.poi</groupId><artifactId>poi-ooxml</artifactId><version>5.2.3</version></dependency><dependency><groupId>cn.hutool</groupId><artifactId>hutool-all</artifactId><version>5.8.20</version> <!-- 使用最新版本 --></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency></dependencies><dependencyManagement><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-dependencies</artifactId><version>${spring-boot.version}</version><type>pom</type><scope>import</scope></dependency></dependencies></dependencyManagement><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.8.1</version><configuration><source>1.8</source><target>1.8</target><encoding>UTF-8</encoding></configuration></plugin><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><version>${spring-boot.version}</version><configuration><mainClass>com.example.dbexcel.DbexcelApplication</mainClass><skip>true</skip></configuration><executions><execution><id>repackage</id><goals><goal>repackage</goal></goals></execution></executions></plugin></plugins></build></project>
新建Entity
@Entity(name = "datameta")
@Data
public class Datameta {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)private Long id;@Column(length = 50)private String 区域;private String 数源单位;
。。。
}
如果Excel中列很多,可能超出数据库单行的长度。需要修改length,从默认的varchar255 修改为实际的大小,如20或50不等。如果有值特别长的,可以修改为
@Column(columnDefinition = "text") private String 实施清单编码;
如修改为text之后,单行的长度就没有限制。
那么如何知道这个列中的记录最大长度,写一个类,计算每个字段的最大长度
package com.example.dbexcel;import java.lang.reflect.Field;
import java.util.List;
import java.util.HashMap;
import java.util.Map;public class FieldLengthAnalyzer {public static Map<String, Integer> analyzeMaxFieldLengths(List<?> dataList) throws IllegalAccessException {Map<String, Integer> maxLengthMap = new HashMap<>();if (dataList == null || dataList.isEmpty()) {return maxLengthMap;}Class<?> clazz = dataList.get(0).getClass();Field[] fields = clazz.getDeclaredFields();for (Field field : fields) {field.setAccessible(true); // 允许访问私有字段String fieldName = field.getName();int maxLen = 0;for (Object obj : dataList) {Object value = field.get(obj);if (value != null) {int len = value.toString().length();if (len > maxLen) {maxLen = len;}}}maxLengthMap.put(fieldName, maxLen);}return maxLengthMap;}
}
新建Controller层
设置调用方式
package com.example.dbexcel.excel;
import com.example.dbexcel.FieldLengthAnalyzer;
import com.example.dbexcel.demos.web.User;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.ModelAttribute;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.ResponseBody;import java.util.ArrayList;
import java.util.List;
import java.util.Map;
@Controller
public class DataController {// http://127.0.0.1:8080/data@Autowiredprivate DataJpaRepository dataJpaRepository;@Autowiredprivate DataService dataService;@RequestMapping("/data")@ResponseBodypublic String data() throws Exception {List<Datameta> datametaList = dataService.dirgetdata();printtoolarge(datametaList);int totalBatches = 10;int listSize = datametaList.size();int batchSize = (listSize + totalBatches - 1) / totalBatches; // 向上取整for (int i = 0; i < datametaList.size(); i += batchSize) {int end = Math.min(i + batchSize, listSize);List<Datameta> batch = datametaList.subList(i, end);dataJpaRepository.saveAll(batch);}System.out.println("保存完成");return "scuses";}private void printtoolarge(List<Datameta> dataList) throws IllegalAccessException {Map<String, Integer> maxFieldLengths = FieldLengthAnalyzer.analyzeMaxFieldLengths(dataList);for (Map.Entry<String, Integer> entry : maxFieldLengths.entrySet()) {if (entry.getValue() > 255) {System.out.println("字段: " + entry.getKey() + ", 最大长度: " + entry.getValue());}}}
}
访问的方式 http://127.0.0.1:8080/data
将excel的每一行读成一个POJO类。整个sheet读成List的集合。为了分批保存,每10个进行保存一次
新建Service
在这个方法中,将excel导入到List集合中
后续可改造为接口化,每次调整的时候,就调整这个内容就可以。结果采用泛型 List<T> 的方式进行返回
package com.example.dbexcel.excel;
import org.apache.poi.ss.usermodel.Cell;
import org.apache.poi.ss.usermodel.Row;
import org.apache.poi.ss.usermodel.Sheet;
import org.apache.poi.ss.usermodel.Workbook;
import org.apache.poi.xssf.usermodel.XSSFWorkbook;
import org.springframework.stereotype.Service;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
@Service
public class DataService {public List<Datameta> dirgetdata(){List<Datameta> datametaList = new ArrayList<>();// 指定要遍历的目录路径String directoryPath = "d:\\sheet"; // 替换为你的实际目录路径// 创建File对象File directory = new File(directoryPath);// 获取目录下的所有文件和子目录File[] files = directory.listFiles();if (files != null) {for (File file : files) {if (file.isFile()) {System.out.println("文件: " + file.getName());datametaList.addAll(getAllData(file.getAbsolutePath()));} else if (file.isDirectory()) {System.out.println("目录: " + file.getName());}}} else {System.out.println("目录不存在或无法访问!");}return datametaList;}public List<Datameta> getAllData(String filePath) {List<Datameta> datametaList = new ArrayList<>();try {FileInputStream fis = new FileInputStream(filePath);//下面这句话,如果sheet太多,内存会崩溃Workbook workbook = new XSSFWorkbook(fis) ; // 创建工作簿// 获取第一个工作表Sheet sheet = workbook.getSheetAt(0);// 遍历行for (int rowIndex = 4; rowIndex <= sheet.getLastRowNum(); rowIndex++) {Row row = sheet.getRow(rowIndex);if (row != null) {Datameta datameta = new Datameta();datameta.set区域(row.getCell(0).getStringCellValue());datameta.set数源单位(row.getCell(1).getStringCellValue());datameta.set归集总量(getSafeNumericCellValue(row.getCell(40)));datameta.set来源sheet(filePath);datametaList.add(datameta);}}} catch(IOException e){e.printStackTrace();}return datametaList;}
//有些单元格为数字列,有数字,但有时候为null。采用如下安全的取数方式private double getSafeNumericCellValue(Cell cell) {if (cell == null) return 0.0;switch (cell.getCellType()) {case NUMERIC:return cell.getNumericCellValue();case STRING:String val = cell.getStringCellValue().trim();if (!val.isEmpty()) {try {return Double.parseDouble(val);} catch (NumberFormatException ignored) {}}default:return 0.0;}}
}
调整生成数据库列的顺序
新建 org.hibernate.cfg
在这个包下,重写PropertyContainer
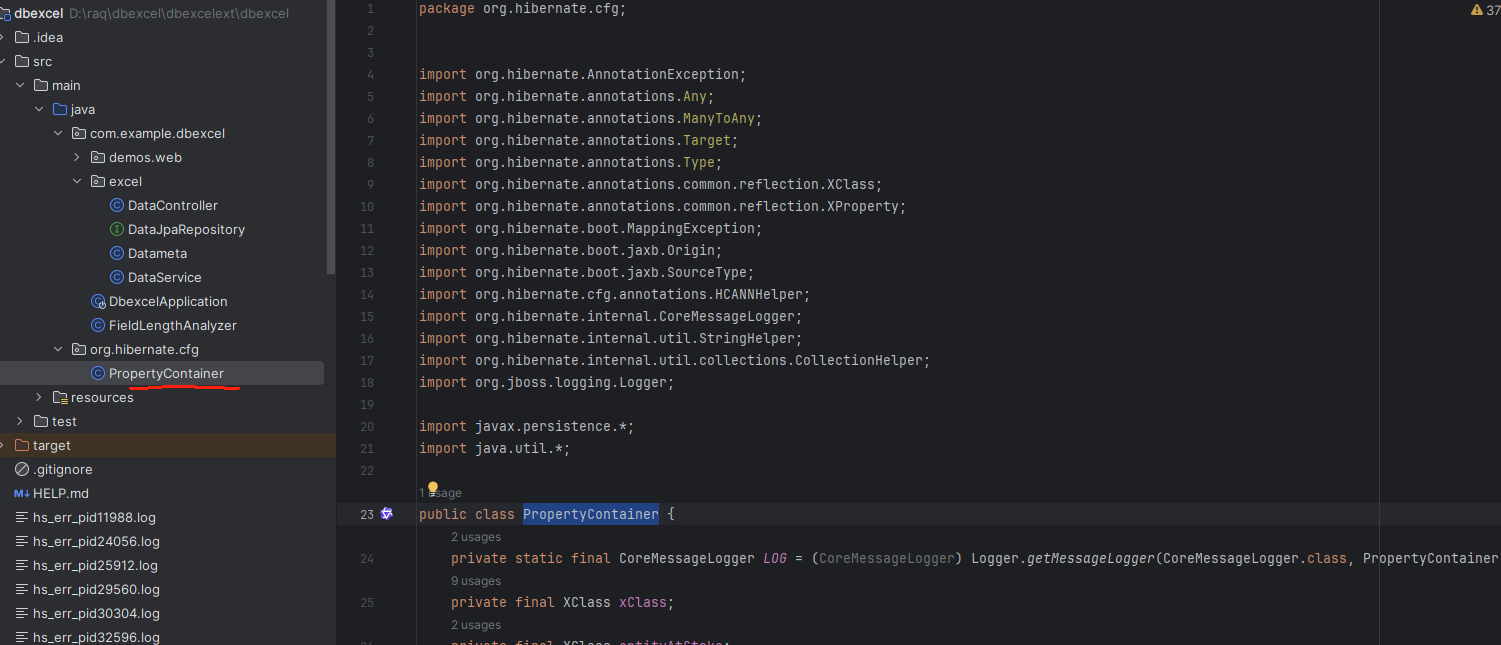
将 TreeMap替换为 LinkedHashMap;覆盖Hibernate的默认的实现方式。
这样就可以将Excel的顺序与类的顺序,数据库表中列的顺序保持一致。便于核对导入的数据
配置文件application.yml
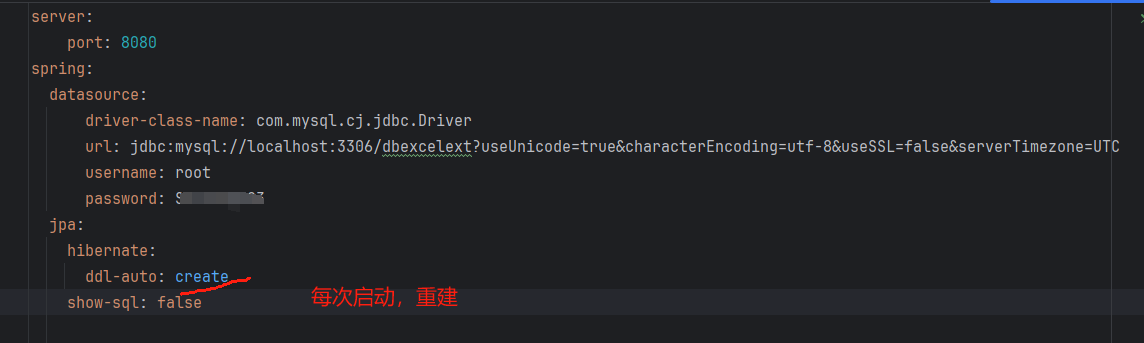
启动运行
http://127.0.0.1:8080/data
然后在数据库中,就导入数据写入到数据库中
本机程序的位置
后面有时间将其转入gitee中