MySQL学习之---索引
一、没有索引的表:没有目录的书
1、具象化MySQL的库和表:
MySQL分为服务端和客户端 。
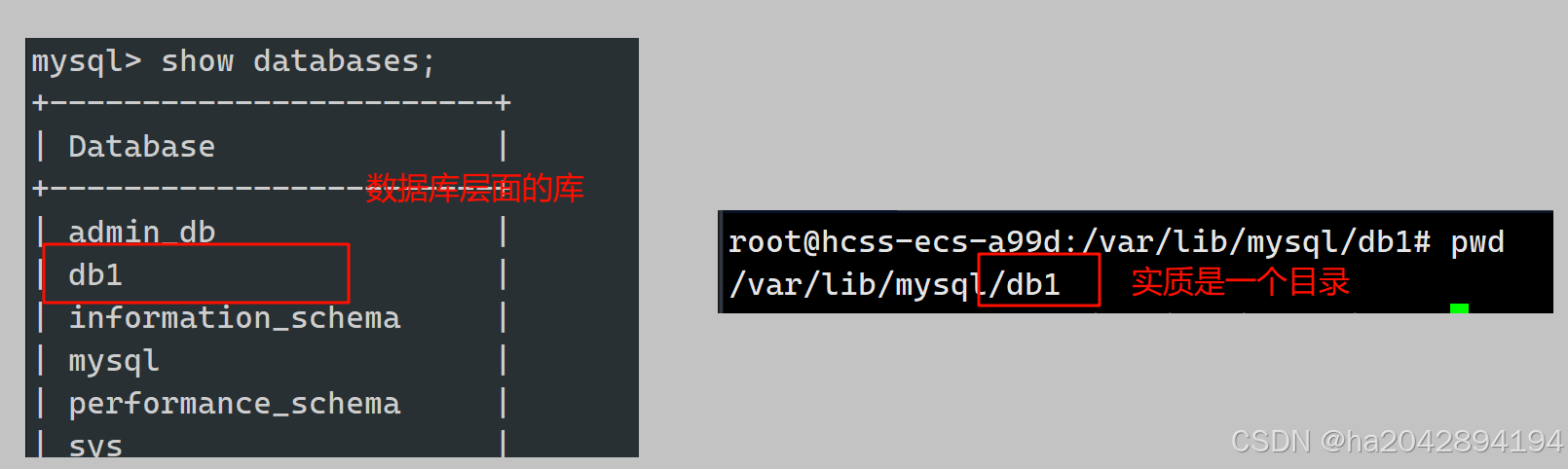
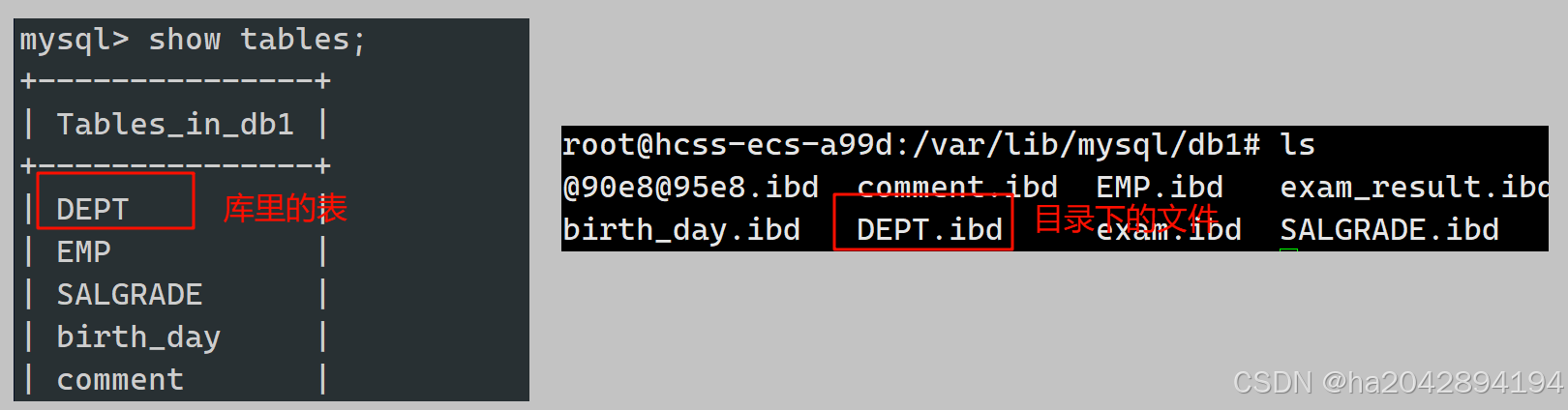
- 当我们在MySQL软件里(即客户端)创建一个库时,实质是像服务端发送一个新建目录的信号。
- 当我们在一个库里创建一个表时,实质是向服务端发送一个在目录下新建文件的信号。
- 而MySQL属于应用层,本质还是一个受操作系统管辖的进程,因此最后有操作系统来创建和管理相应的目录(库)和文件(表)。
---------------------------------------------------------------------------------------------------------------------------------
下面是抽象的库和表在具体操作系统文件里的对应关系:
2、直接查询表内的数据:
有了一张库里面的表后,首先是插入数据 。在增删查改这四种表操作里,频率最高的就是查找,因此查找操作的效率就很大程度上觉得了一个数据库的效率。
可是当表内的数据量到达一定程度后,学过数据结构的经历告诉我们,倘若是无脑便利,那效率必定崩盘!!!
其实就像我们生活中随处可见的书籍一样,如果每次查找内容都只能一页一页的翻,效率肯定得不到保障,所以就有了书的目录。因此如果想要快速地定位到表内的数据,也可以通过类似于书签的方式,快速地定位到目标内容的区间,从而实现高效查找——它就是索引。
二、硬件到软件的数据流:
在了解索引之前,让我们一步一步,从硬件到软件,慢慢的推演。
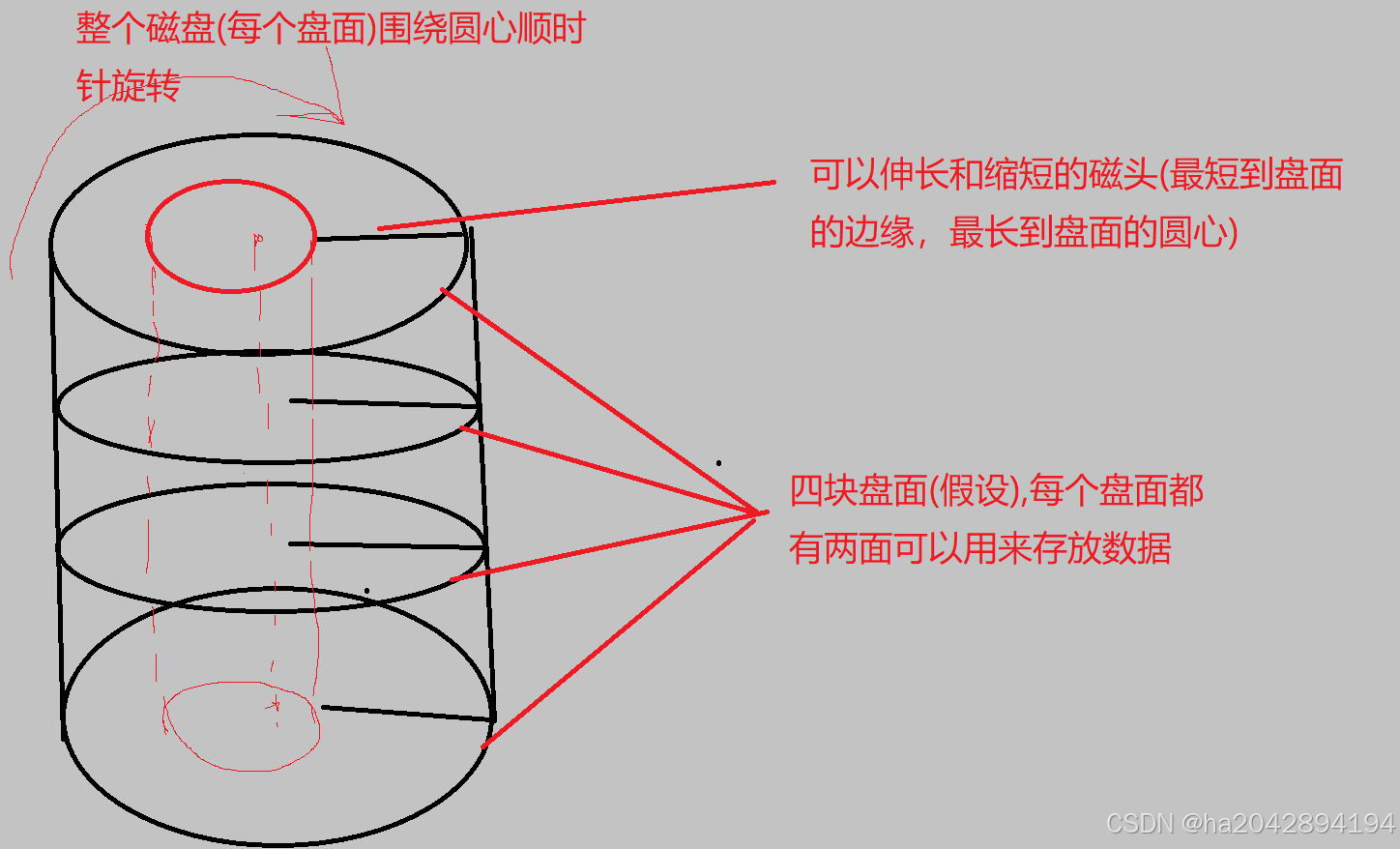
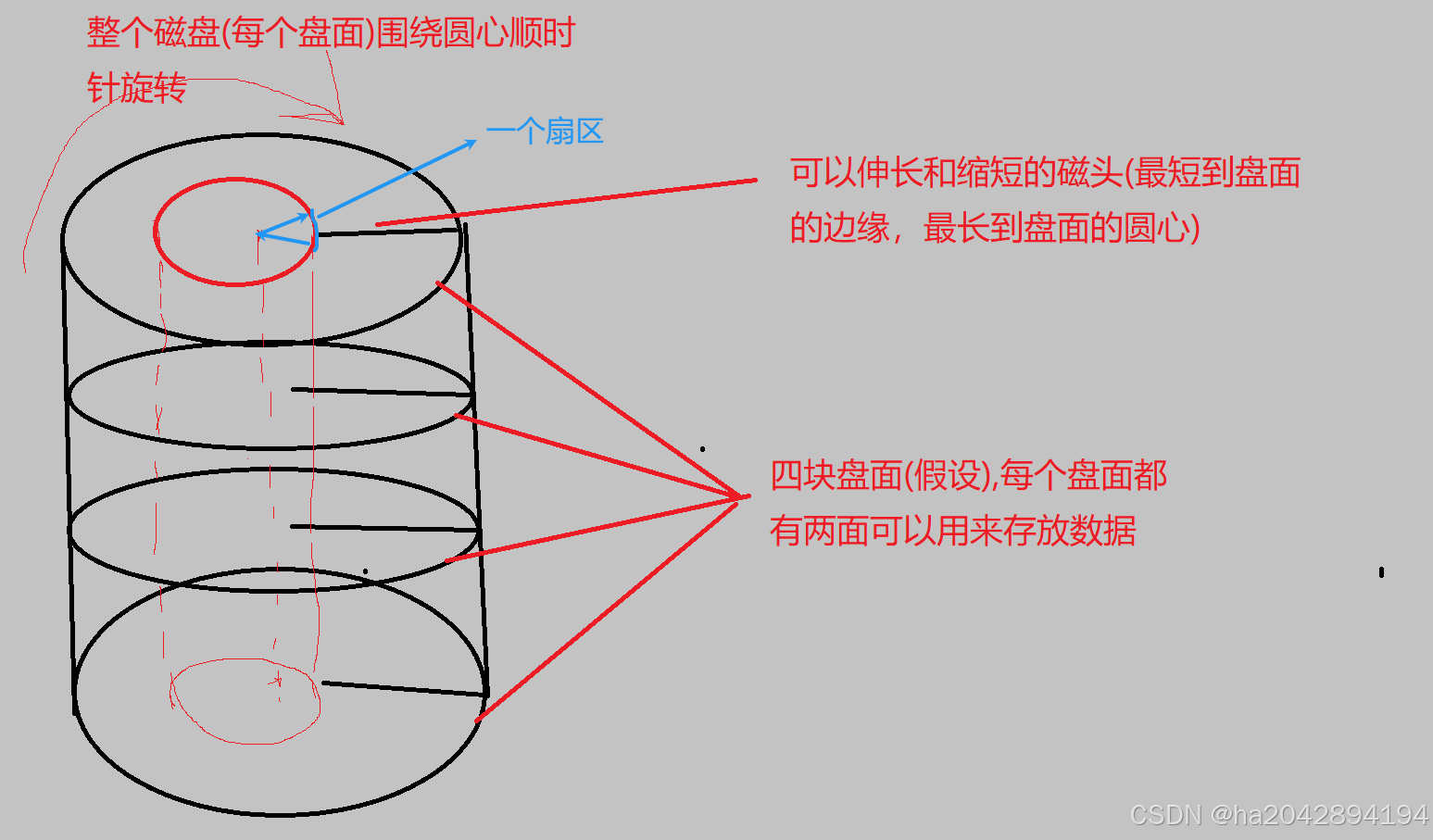
1,磁盘的存储单元——扇区:
对于磁盘(这里指机械硬盘),可以想象出许多了小圆盘堆叠在一起,每一个圆盘的两边都可以存储数据,磁盘本身可以转动,另外,每个磁盘的两面都分别有一个可以来回沿着磁盘半径移动的磁头。
下面是一个简略的磁盘的概念图(抽象到只有我和本来就了解的人能看明白哈哈哈哈):
-----------------------------------------------------------------------------------------------------------------------------
其中,磁头的来回伸缩和盘面的旋转就可以定位出一个扇区——磁盘的最小存储单元(最传统和经典的一个扇区512比特)。
2,内存的交互单元 ——块:
磁盘设计出来是为了存储数据的,而CPU处理完数据后需要通过内存作为中转站,最后写入磁盘。所以和磁盘打交道的是内存,但是内存和磁盘的最小传输单位并不是一个扇区(太小了!!!),而是一个——块(4kb,即8个扇区)。
之所以内存不使用一个扇区的大小为单位来和磁盘交互,除了效率上的考量外,也是为了进行磁盘硬件设计和内存软件层设计的解耦合。
自此,即便有了更先进的磁盘技术(已经有啦),磁盘一个扇区的大小突破了512比特,依然不会影响内存所期待的一个块——4KB的交互单位,只不过一个块可以用更少的扇区来满足罢了。
3,MySQL的交互单元——page:
那MySQL作为和数据强相关的软件,又会以多大的存储单元、什么样的交互方式将数据持久化存储到磁盘呢?答案是一个page!!!
也许是考虑到要尽可能减少内存和磁盘之间IO操作的次数,一个page的大小相比磁盘的扇区和内存的块更大——16KB。一个扇区就可以存放表内的一部分相关数据。
MySQL的一切操作都发生在内存中,不直接和磁盘打交道。具体来说,当一个MySQL进程创建,就会向操作系统申请一块较大的内存空间,一般称为——buffpool。如果要对磁盘内的数据进行持久化存储和修改,就通过相关算法及时的将buffpool里的内容刷新到磁盘。
如果想要管理所有表内数据,就需要存在很多page,但是在查找具体数据时就会面临效率问题——遍历查找绝对不可行。如何解决查找的效率问题,这就是下面要探讨的内容。
三、innoDB下的存储引擎解决方案:
1、B+树:
提前总结一下,innoDB的整个存储结构就是一个B+树,其特点如下:
- 以索引作为每个节点的主要内容。
- 只有叶子结点不仅存索引,还存放内容。
- 逻辑层面上最底层的叶子结点又使用链表的结构连接起来。
---------------------------------------------------------------------------------------------------------------------------------
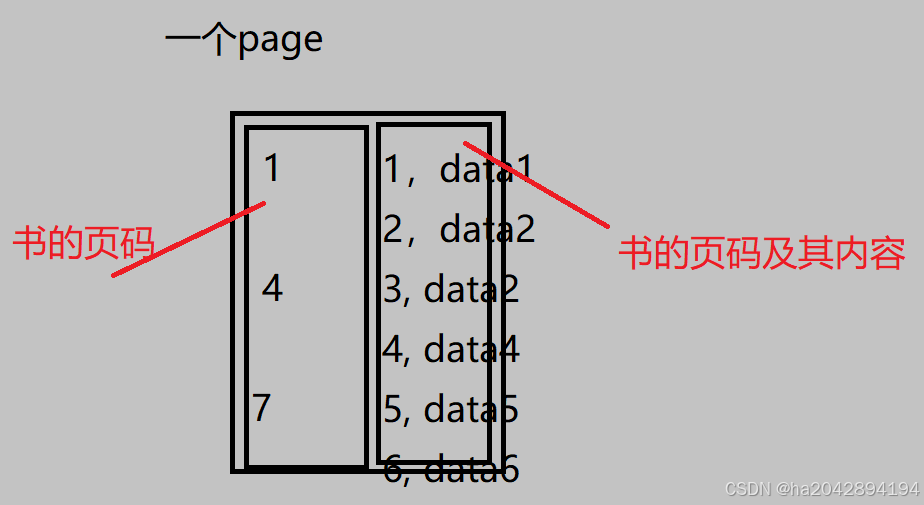
首先,一个page里可以存放不止一条的数据条目。如果不加特殊处理,在查找时就只能低效率的遍历,所以效仿现实生活中书籍对目录的应用——消耗少部分纸张用作目录来实现高效定位内容。
假设一个表里存放的是书本的页码及其对应的页内容 ,那就可以把整本书的页数分成多个页码区间,单独在用链表组织起来;
下图中可以看到,如果要查找页码为6的内容,不用1、2、3……的一个一个遍历,而是通过左侧的页码来快速确定是在4-7之间,从而省去了对1-4之前数据的遍历,提升了效率(当然,这里篇幅限制数据量比较小,所以页码的划分范围也不大,没那么直观).
---------------------------------------------------------------------------------------------------------------------------------
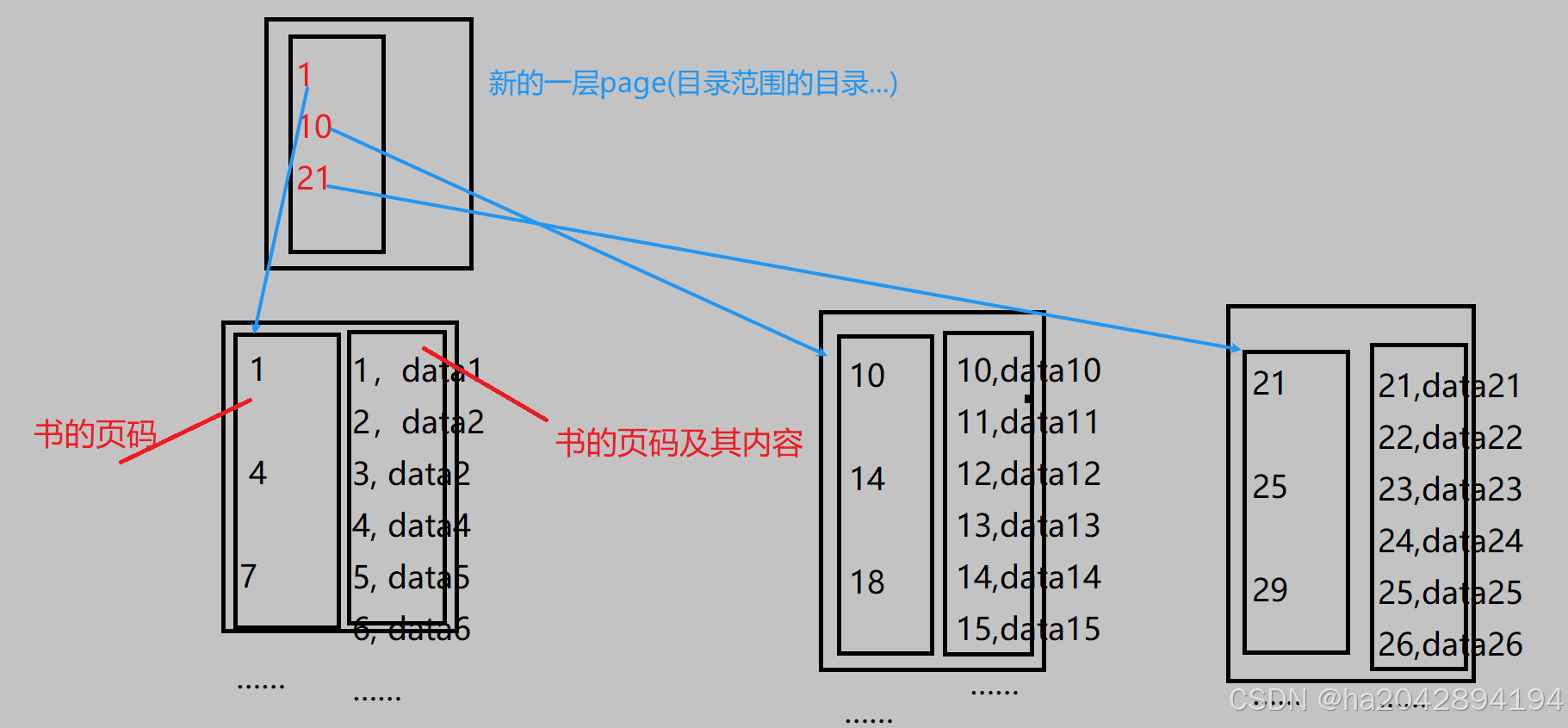
其次 , 一个page也才16KB,所以必定需要多个page才能满足正常情况下的数据存储需求.此时问题就来了——一个page内的快速查找不用愁了,那如果有多个page,岂不是还得想办法快速确认目标元素在哪个page才行?
故技重施就好,第一批page里保存的都是书的页码范围和具体的页码、内容,我们再加上一层page,用来存放第一层page里页码范围的起始页码。
从下图中可以看到:如果要访问递21页的内容,不需要从第一个page开始,而是直接从上面那一层:1、10、21。直接就定位到了第21页,省去了对存放1-20页里page的访问。
-------------------------------------------------------------------------------------------------------------------------------
当然了,以上只是为了解释基本原理画的草图,实际上不仅page内的内容要更多,一层里page的数量页更多。
同样的套路,当数据量进一步扩大,访问目录的目录也不够高效时,就像俄罗斯套娃一样再加上一层目录的目录的目录,效率就又高了。
图就不画了,总之就是一层一层的结构,越往上,一层里的元素就越少,因为对于页数的划分区间更大。
---------------------------------------------------------------------------------------------------------------------------------
2、B+树为啥好???
先抛结论:
- 效率高
- 空间利用率高
- 减少了内存和磁盘间磁盘的IO次数
-------------------------------------------------------------------------------------------------------------------------------
从效率角度来看:
B+树在逻辑结构上层数少,属于“矮胖型”,因此自上而下的层层选择,很快就定位到底层的叶子结点了。
从内存占用角度来看:
除了底层的叶子节点存储索引和数据外,其他节点都只用存放索引,从而大幅节省了空间。这也是其“矮胖型”结构的原因所在:倒数第二即往上的每个节点同样是16KB大小的page,单个页能容纳更多的索引项,从而降低了树的层级深度。
从IO效率角度来看:
这是最关键的,因为磁盘相对于内存和CPU来说实在是太慢了 ,所以只要减少了IO次数,那就达成了目的!!!
B+树的层数少,因此可以用更少的次数(更低的IO消耗)来确定节点范围;B+树的叶子结点全部用链表连接起来,因此找到一个节点,就可以顺带的找到前后的多个节点,免去了从小从根部遍历造成的IO需求。同时由于局部性原理的存在,我们访问数据时往往会紧挨着访问相邻元素。
--------------------------------------------------------------------------------------------------------------------------------
3、其他数据结构为啥不适合:
注意我的题目措辞 :是“不适合”,而非“不行”。下面先罗列将要提到的其他数据结构:
- 链表
- 二叉搜索树
- 红黑树
- 哈希
- B树
--------------------------------------------------------------------------------------------------------------------------------
链表的硬伤:
如果用链表,就变成了咱一开始谈到的遍历的效率难题,pass!!!
二叉搜索树的硬伤:
存在极端情况:叶子结点往一段延伸,最终形成N层的类链表结构,效率底下。
红黑树的局限性:
无法实现仅索引存储(叶子节点除外),导致存储空间利用率降低。上层节点存储数据会减少索引容量,可能增加树的高度。
哈希表的局限性:
仅仅查找单个数据时的确可以实现O(1)时间复杂度的高效查找,但面对范围查询时就捉襟见肘了。
B树的局限性:
叶子结点之间并非链式相连,无法利用局部性原理来实现临近的节点的快速访问。
四、索引的相关操作:
操作部分就简单了 , 先列举和索引相关的通用指令它 ,。:
- show index from (表名) \G 或者 show keys from (表名) \G ( 如果用key作为关键字,记得加上s变成keys!!!)
- show
---------------------------------------------------------------------------------------------------------------------
1、查询表索引:
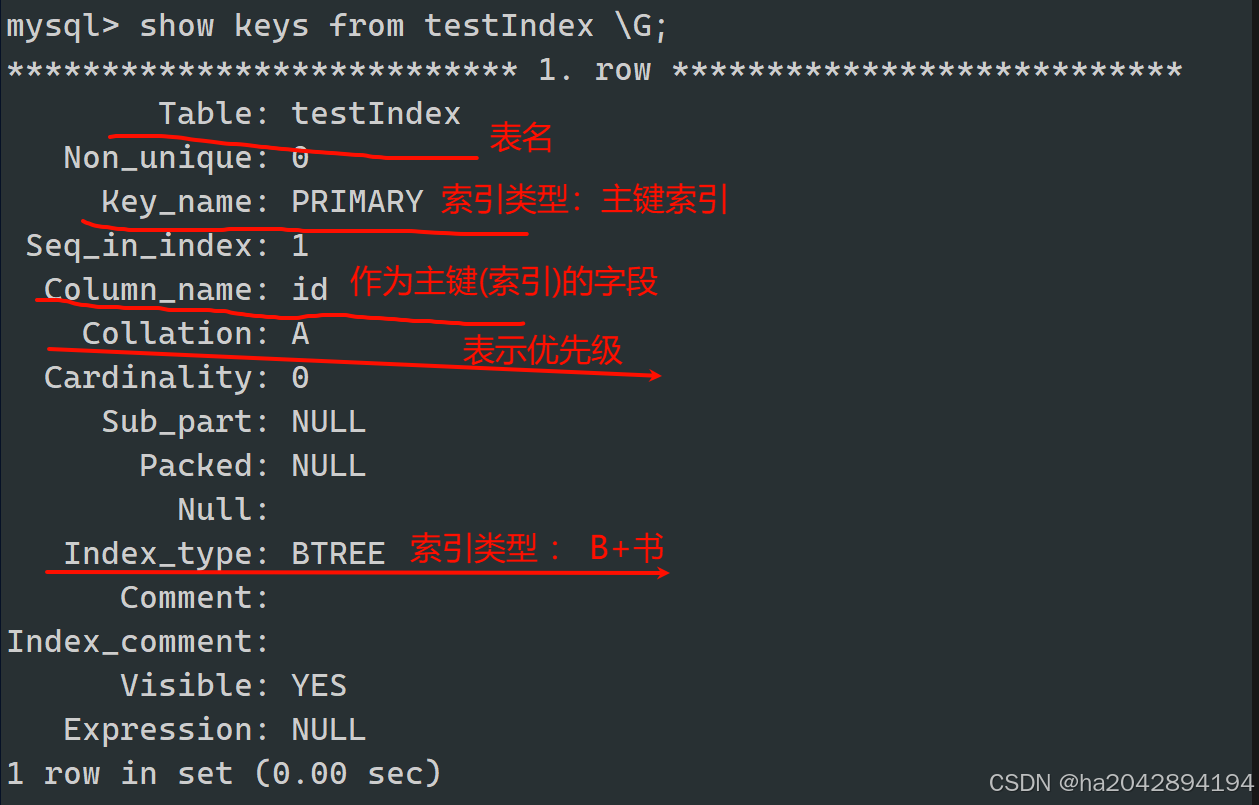
首先了解索引的查询是因为我们会发现 :之前咱们学过的主键约束天然的就是一种索引!!!
存在一个普通的testIndex表 ,先查询此表的索引情况:

接着为这个表添加一个主键:

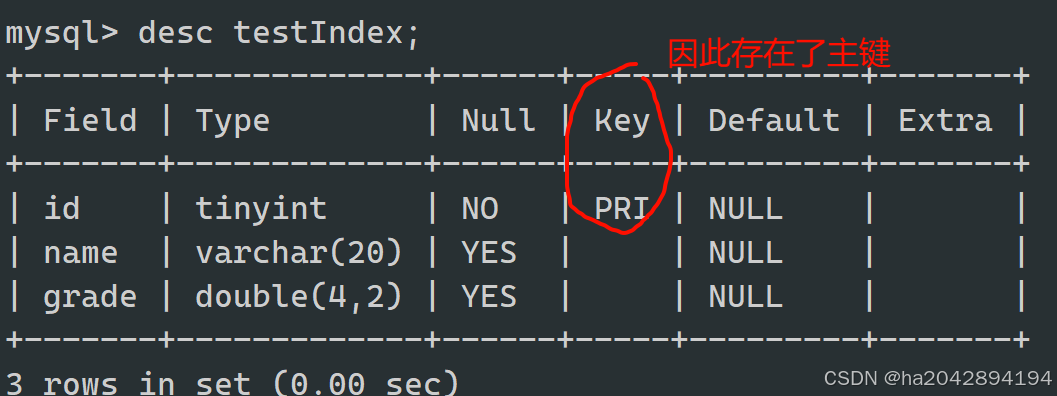
添加完主键后再一次查询这个表的索引,就会发现作为主键的字段同时也成为了索引!!!
2、添加表索引:
上面提到的添加主键也算是一种添加表索引的方式,但是下面我们系统的见识一下表索引的创建方式。
--------------------------------------------------------------------------------------------------------------------------
添加主键索引的三种方式(也就是添加主键):
create table testIndex(
id int primary key, //可以在字段定义时添加主键索引
name varchar(25),
grade double(4,2)
);create table testIndex(
id int,
name varchar(25),
grade double(4,2),
primary key(int) //可以单独用一个条primary key()来指明主键索引
);
//假设有一个不存在主键索引的testIndex表....alter table testIndex add primary key(id); //在表已经存在的情况下为指定的字段添加主键索引----------------------------------------------------------------------------------------------------------------------------
添加唯一键索引的三种方式:
create table testIndex(
id int ,
name varchar(25) unique, //在创建表的同时添加唯一键,也就是唯一键索引
grade double(4,2)
);create table testIndex(
id int ,
name varchar(25) ,
grade double(4,2) ,
unique(name) //在创建表是单独用一个字段来指明唯一键索引
);//假设有一个不存在唯一键索引的testIndex表....alter table testIndex add unique(name); //对一个已经创建了的表添加唯一键索引---------------------------------------------------------------------------------------------------------------------------
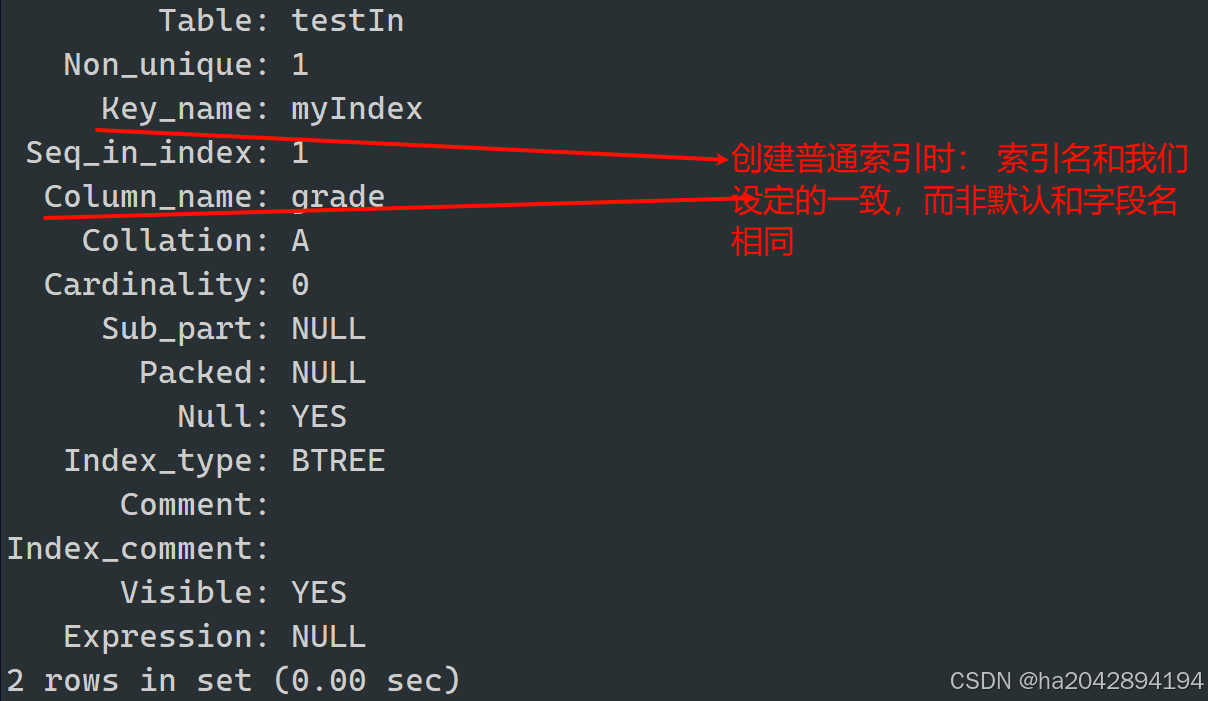
创建普通索引的方式:
像上面主键索引和唯一键索引都是我们在学习MySQL约束的时候学过的操作,只不过现在学到了索引的概念后,主键和唯一键在我们心里除了能保证字段唯一性,还有了加速查询的效用。
普通索引的创建和主键以及唯一键的创建既有相似的部分,同时也有他独特的部分。
create table testIndex(
id int ,
name varchar(25) index , //注意!!!不能遮掩直接跟在字段后面用index定义索引
grade double(4,2)
);create table testIndex(
id int ,
name varchar(25) ,
grade double(4,2) ,
index(name) //想要在建表时一同用index添加索引,只能单独用一个字段来实现
);这个写法就比较特殊,不是用alter table,注意别和主键、唯一键索引的添加语法搞混了 。值得注意的是,这种创建索引的方式可以,也必须为索引定义一个名称,如下面的index_name:
//假设有一个不存在唯一键索引的testIndex表....create index index_name on testIndex(name); //这个index_name很关键 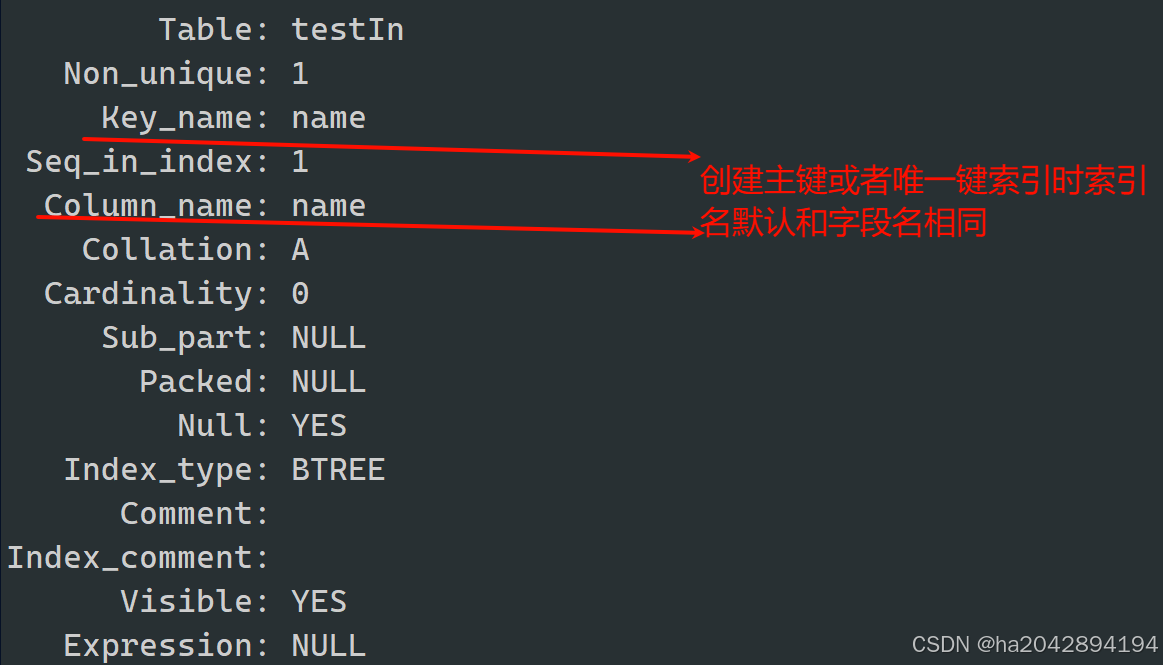
---------------------------------------------------------------------------------------------------------------------------------
3、删除索引:
主键索引的删除也就是先前学过的主键的删除,仅仅是唯一键和普通索引的删除略有不同。
主键索引和的删除:
//假设有一个存在主键索引的表testIndexalter table testIndex drop primary key; //删除主键索引唯一键索引和普通索引的删除:
//假设有一个存在主键索引的表testIndexalter table testIndex drop index index_name ; //删除指定名称的唯一键索引或普通索引, index_name是索引的名称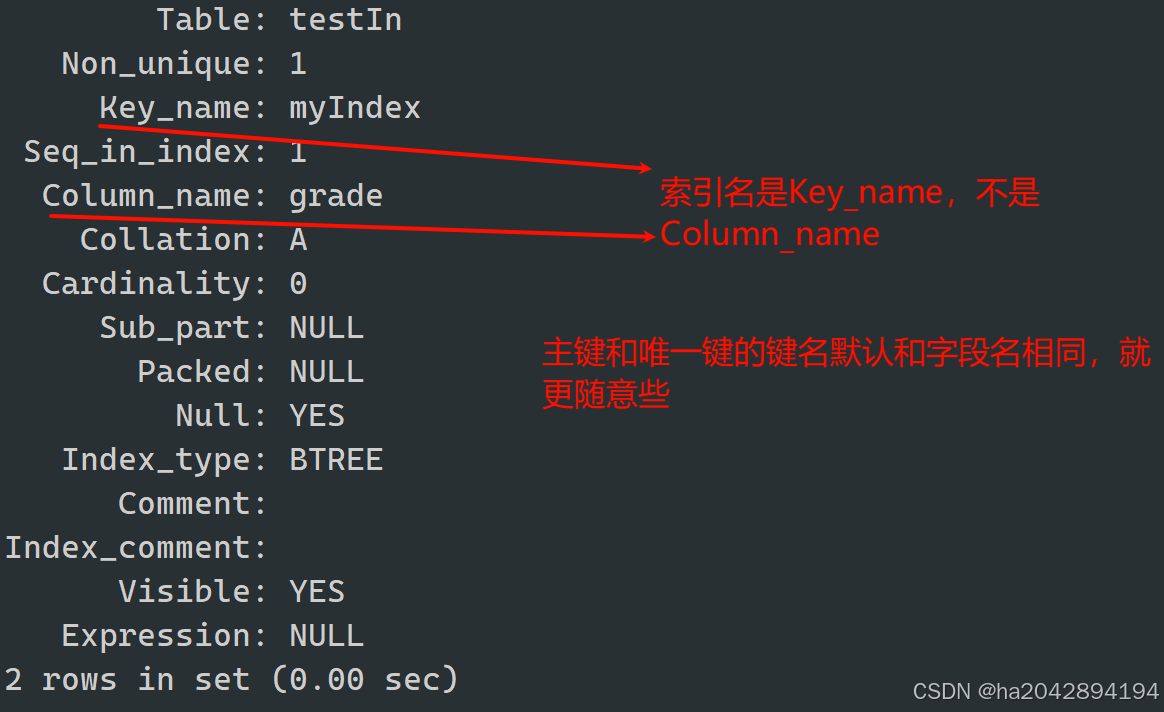
通过删除索引的操作可以看出,起始在MySQL里,只存在唯一键索引和其他索引。唯一键索引和普通索引没区别,只不过普通索引可以自定义索引名,更加灵活。
五、补充说明:
1、复合索引-》索引覆盖:
复合索引本身并不特殊,就是用多个字段共同组成一个索引。但是,由于innoDB存储引擎下的存储结构是B+树,当索引为复合索引时,一个page里面的元素链表中一个节点就有了两个值,于是可以通过索引元素来查找索引元素——这就是索引覆盖。
索引覆盖的意义:
- 对于每个索引,操作系统都会创建一颗B+树。然而,与主键索引不同的是,非主键索引的B+树叶子节点中仅存储索引而不包含实际数据。因此,当需要获取非主键索引对应的元素内容时,必须回访主键索引的B+树叶子节点。这一过程会导致额外的内存和磁盘IO操作,进而影响系统性能。
- 如果非主键索引是复合索引,此时索引本身就包含了多个值,于是对于这些值的查询就可以省去回访主键B+树节点的操作,从而减少了IO操作。但是要遵循索引最左匹配原则。
索引最左匹配原则的规则大致如下。
