Nature子刊|ChatNT:生物多模态LLM破壁者!统一DNA/RNA/蛋白质分析的对话式AI
语言模型正在蓬勃发展,为对话代理提供动力,帮助人类解决一系列任务。最近,这些模型被扩展到支持更多模式,包括视觉、音频和视频,在包括医疗保健在内的多个领域展示了令人印象深刻的能力。尽管如此,对话式代理在生物学领域仍然受到限制,因为它们还不能完全理解生物序列。
近日,英国人工智能公司InstaDeep团队在《Nature Machine Intelligence》发表了一篇研究论文《A multimodal conversational agent for DNA, RNA and protein tasks》,该研究提出了一种对话模型——ChatNT。ChatNT能用英语一次性解决所有任务,并能泛化到未见过的问题。此外,研究团队还从 DNA、RNA 和蛋白质中整理出了一组更具生物相关性的指令任务,涵盖多个物种、组织和生物过程。在这些任务上,ChatNT 的性能与最先进的专门方法不相上下。
一、问题提出
生物学领域的高通量测序技术产生了海量的基因组、转录组和蛋白质组数据,但现有的深度学习模型存在两大局限性:
-
任务专用性:当前的基础模型(如Nucleotide Transformer)需针对每个任务单独微调,导致模型碎片化,无法跨任务泛化。
-
交互壁垒:生物学家通常缺乏编程能力,而现有模型缺乏自然语言交互界面,限制了其实际应用。
二、解决方案
研究团队提出了ChatNT(Chat Nucleotide Transformer),一种多模态对话代理,通过以下创新解决上述问题:
-
统一任务框架:将DNA、RNA和蛋白质任务转化为“文本到文本”的指令形式,支持用户以自然语言提问(如“这段人类DNA序列是否包含启动子?”)。
-
多模态架构:结合DNA编码器(Nucleotide Transformer v2)与英文解码器(Vicuna-7b),通过投影层将生物序列嵌入到语言模型空间,实现跨模态理解。
-
零样本泛化:模型通过统一训练目标(交叉熵损失)同时学习27项任务,无需针对新任务重新训练。
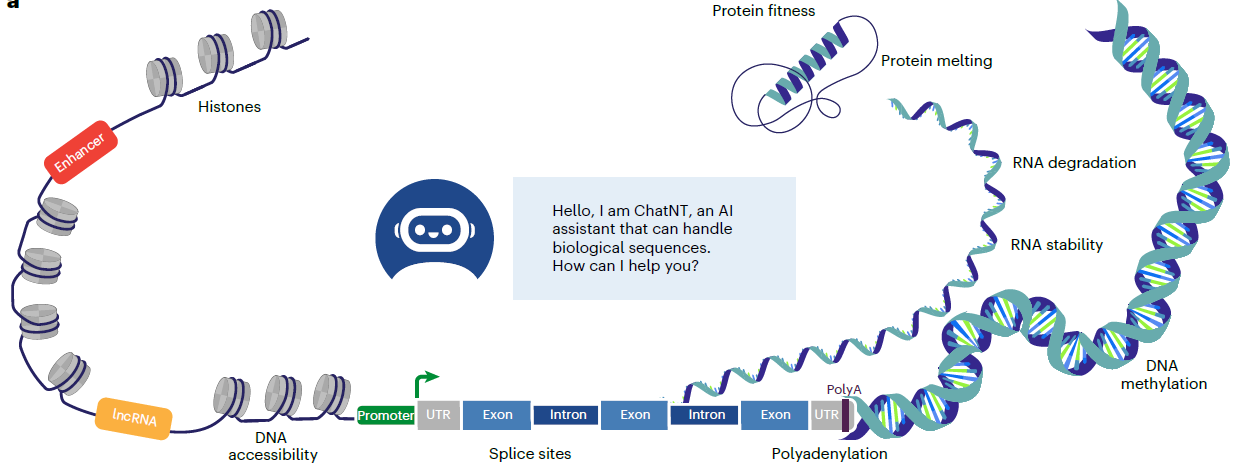
图1 chatNT可解决的下游生物序列
三、方法模型
-
架构设计:
-
DNA编码器:基于850个物种基因组预训练的Nucleotide Transformer v2,提取DNA序列特征。
-
英文解码器:冻结参数的Vicuna-7b(LLaMA微调版),保留自然语言生成能力。
-
动态投影层:创新性引入“问题感知”的Perceiver Resampler,根据用户指令动态提取DNA特征,避免信息瓶颈。
-
-
训练数据:
-
构建包含605M DNA token(36亿碱基对)和273M英文token的指令数据集,涵盖启动子识别、RNA降解率预测、蛋白质熔点等任务。
-
任务类型包括分类(如增强子检测)和回归(如polyA位点评分),覆盖人类、小鼠、植物等多物
-
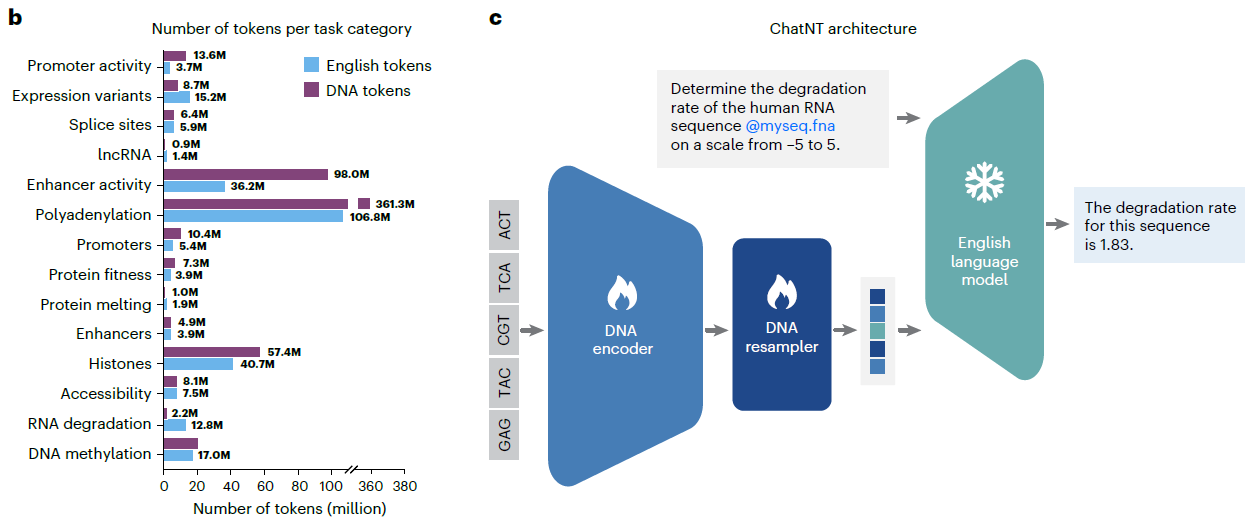
图2 chatNT模型训练流程
四、方法性能
-
基准测试:
-
在Nucleotide Transformer基准(18项任务)中,ChatNT平均马修斯相关系数(MCC)达0.77,超越原模型(0.69)。
-
在27项生物任务中,其表现与专用模型相当(如APARENT2的RNA多聚腺苷化预测PCC=0.91 vs. 0.90)
-
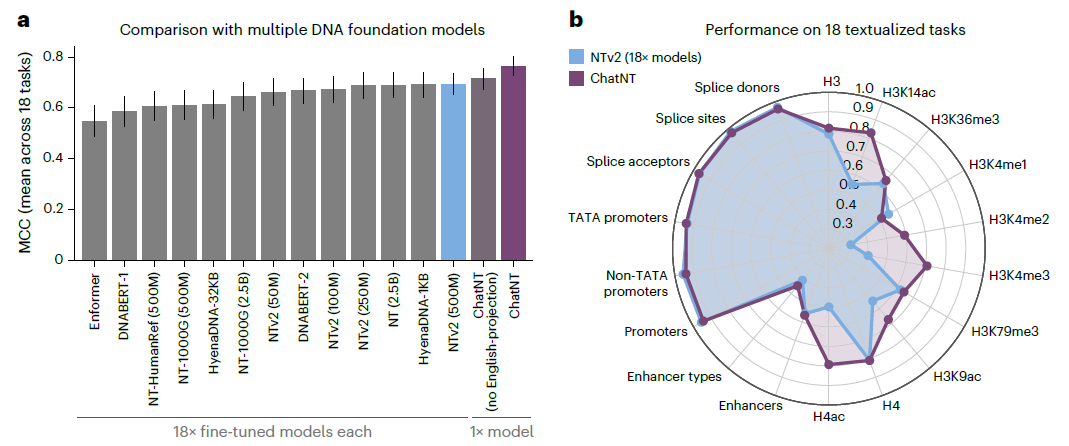
图3 chatNT与13种基因组学基础模型的性能比较
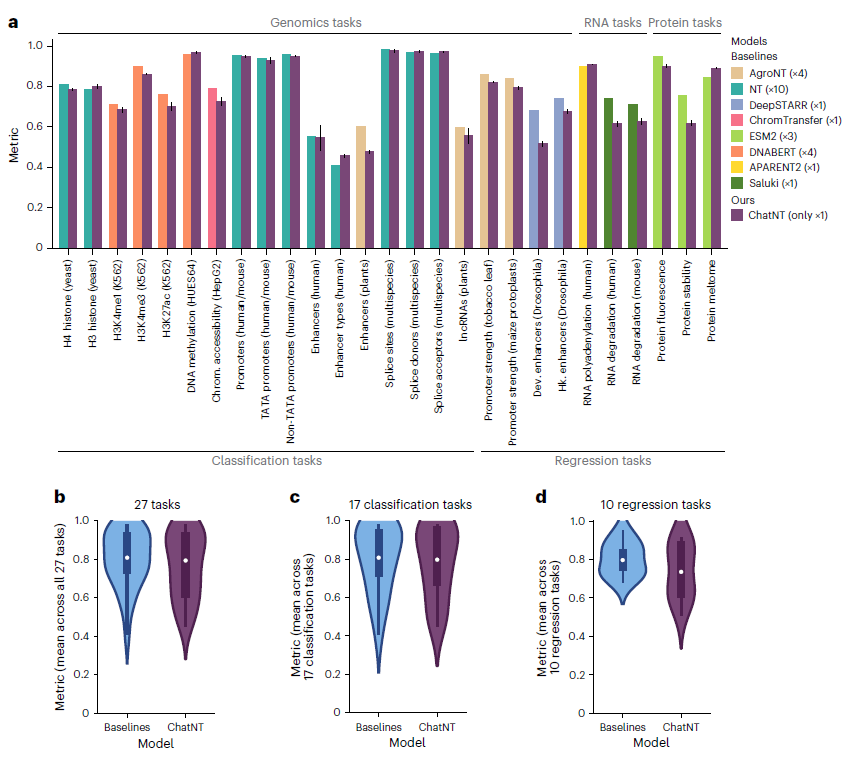
图4 在基因组学、转录组学和蛋白质组学任务中,比较 ChatNT与特定领域baseline的性能差别
-
关键优势:
-
多任务统一:单一模型解决DNA甲基化、RNA稳定性、蛋白质功能等跨领域任务。
-
生物可解释性:通过梯度分析显示模型依赖已知序列特征(如TATA-box基序、GT/AG剪接位点)。
-
置信度校准:提出基于困惑度的概率输出方法,使分类任务的预测可靠性显著提升(如染色质可及性任务校准后准确率与置信度对齐)。
-
-
局限性:
-
回归任务(如RNA降解率)性能略低于专用模型(PCC差10%),可能因训练数据不平衡。
-
植物增强子预测性能较弱,提示需优化编码器的跨物种表征能力。
五、结论与展望
ChatNT首次将多模态对话能力与生物序列分析结合,其核心贡献在于:
-
通用性:通过自然语言指令实现多任务统一建模,降低生物学家使用门槛。
-
可扩展性:框架支持未来整合RNA/蛋白质编码器(如ESM2),迈向全模态生物AI。
-
应用潜力:为基因变异影响评估、跨物种调控元件发现等场景提供新工具。
原文链接:
https://www.nature.com/articles/s42256-025-01047-1
模型链接:
https://huggingface.co/InstaDeepAI/ChatNT