位置编码学习笔记
位置编码是transformer中的关键部分,解决了transformer对于序列中的单词顺序不敏感的问题。从为什么、是什么、怎么做来了解位置编码。
1. 为什么需要位置编码?
时序数据本身都隐式地包含了位置信息,但是不同模型的模型对于位置信息是否敏感不同。决定位置是否敏感,可以简单理解为如果更换时序序列的单词顺序,输出结果是否发生变化。如果发生了变化,如RNN、CNN,则是位置敏感的模型,如果没有发生变化,如transformer,则是位置不敏感的模型,需要额外引入位置编码。
2. 为什么transformer对位置不敏感?
transformer的核心机制是attention,transformer对位置不敏感,本质上是attention对位置不敏感。举例来说,一个句子,“我吃香蕉”,注意力机制会生成Q(“我”),Q(“吃”),Q(“香蕉”),K(“我”),K(“吃”),K(“香蕉”),V(“我”),V(“吃”),V(“香蕉”),无论单词顺序如何,输出的第一部分,Z(“我”)= (Q(“我”)· K(“我”))V(“我”)+(Q(“我”)· K(“吃”))V(“吃”)+(Q(“我”)· K(“香蕉”))V(“香蕉”),与顺序无关。因此,attention仅依赖于词与词之间的相似度来计算权重,无法区分不同顺序的句子,不具备处理序列顺序的能力。
3. 有哪些位置编码?
绝对位置编码和相对位置编码,固定位置编码和可学习位置编码
a. 绝对位置指的是每个单词在序列中的具体位置,如“我”是第一个单词。主要方法是对输入的嵌入向量增加位置编码嵌入,经典transformer使用正余弦位置编码,公式如下:
此外,还包括可学习的绝对位置编码,将位置编码嵌入设置为可学习参数。
b. 相对位置指的是单词与单词之间的距离,如“我”是“吃”的前面一个单词。主要在注意力计算时进行相对位置信息的融合,下面介绍两种方式,首先是可学习相对位置嵌入,b是sxs的矩阵,s代表序列长度,bi-j对应i和j之间的相对位置编码,以可学习的参数的形式呈现。
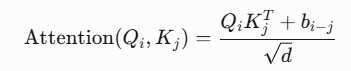
其次,是RoPE,LLama中采用,旋转位置编码。公式如下:
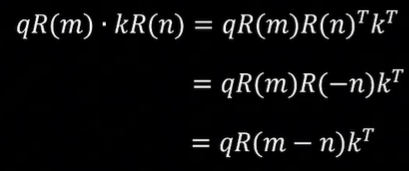
c. 为什么正余弦位置编码需要正余弦交替?因为正余弦交替则可以对PE(pos)进行线性变换获得PE(pos+k),因此包含了相对位置信息。