【大模型01---Flash Attention】
文章目录
- Flash-Attention
- 来龙去脉
- 主要特点
- 总结
Flash-Attention
本文主要是对Flash-Attention的浅薄理解做一下记录,文中不免错误,请各位不吝赐教。
想学习细节请看视频:视频讲解
来龙去脉
随着大模型参数量和数据量的快速增长,其对显存和计算速度提出了很高的要求(淦,怎么开始写论文了),说白了,就是当句子长度变长的时候,自注意力计算出来的值需要存储 N 2 N^2 N2,也就是时间复杂度和空间复杂度都随着句子长度的增长,以 O ( N 2 ) O(N^2) O(N2)增长,那么怎么缓解这个问题呢?之前很多方法,比如稀疏注意力机制,通过降低整体的计算量,来加快训练速度,但是这种做法往往会损失一定的精度。Flash-Attention从另一个角度来进行优化——数据从内存读取的速度。它发现真正计算速度被限制的原因是读取的太慢了。我们首先来看一下GPU的结构:

这里的SRAM为片上内存,读写速度块,但是内存小,HBM就是我们说的显存,比如40G,80G的,但是速度相对较慢。传统的Attention的计算需要不断的从HBM里读取,存储,有些中间结果,都是先存储到HBM 里,再进行读取(因为要计算梯度),这里他又两个bound,一种叫做计算型bound,比如大矩阵乘法等,一种是Memory bound,比如softmax,dropout等等,所以这里传统的Attention导致的问题,其实就是这里的Memory bound,通过将计算结果进行融合,也叫kernal融合,进行优化。
主要特点
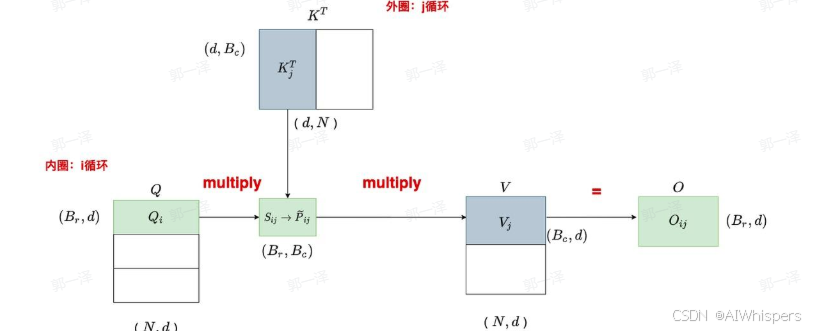
- Falsh-Attention在计算Attention的时候采用了分块的技术,也就是将Q,K,V分块,加载到SRAM上,然后通过融合的kernal计算输出一个部分的O,以及一些辅助的变量,所以降低了访问HBM的次数,从而加快了计算速度。
- 同时,由于不在需要存储一些中间结果,所以降低了显存,将显存复杂度从 O ( N 2 ) O(N^2) O(N2)降低到 O ( N ) O(N) O(N).
- 另一个特点是精确计算,其结果和原生的Attention的结果是等价的。

但是这里存在的一个问题是:分块计算的O,是真实的O吗,分块计算的注意力分数,是真实的注意力分数吗?不是,因为softmax分母是全局的和,这里要提一下,由于softmax中,指数操作容易造成FP16溢出,所以采用safe softmax的做法,即减去一个全局最大值,使每一项落在【0,1】的范围里。
为了和传统的Attention的输出一致,这里采用一种写法,如图所示,就是存储每一块的分数的最大值,然后再融合的时候,给每一项乘以一个额外的因子,从而抵消掉局部的影响。

总结
一张图完事!