[LLaVA] Visual Instruction Tuning
1、贡献
1)用language-only GPT-4从图像-文本对中生成多模态language-image指令微调数据
2)提出Large Language and Vision Assistant(LLaVA)框架,端到端的训练了连接vision encoder和LLM的大型多模态模型,用于图像和语言理解
3)构建了两个评估benchmark
2、指令遵循数据

1)text:captions + bounding boxes
2)数据来源:COCO images
3)类型(158K)
-> conversation(58K):只包含有确定回答的问题;关于图像中物体的类型、计数、动作、位置、相对位置关系

-> detailed description(23K):从list中任选一个问题

-> complex reasoning(77K):需要借助step-by-step推理过程才能回答
3、模型
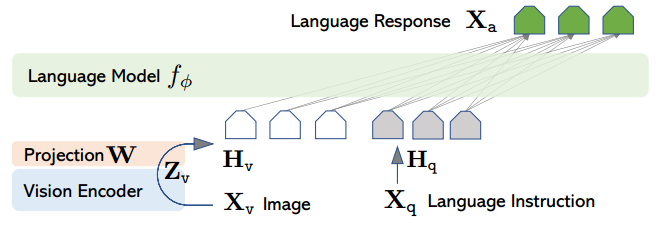
1)visual encoder:CLIP ViT-L/14(grid features before and after the last Transformer layer)
2)language decoder:Vicuna
3)pretrained LLM:LLaMA

4)训练
1)pre-training for feature alignment
a)CC3M,595K图像文本对
b)单轮对话:describe the image briefly

c)只训练W参数,固定其他参数,得到visual tokenizer
2)fine-tuning end-to-end
同时训练W参数和LLM参数,固定visual encoder
4、LLaVA-Bench
配对的图像、指令、详细标注
1)COCO-Val-2024,30 images
2)In-the-Wild,24 images,60 questions