深入了解NIO的优化实现原理
网络 I/O 模型优化
网络通信中,最底层的就是内核中的网络 I/O 模型了。随着技术的发展,操作系统内核的网络模型衍生出了五种 I/O 模型,《UNIX 网络编程》一书将这五种 I/O 模型分为阻塞式 I/O、非阻塞式 I/O、I/O 复用、信号驱动式 I/O 和异步 I/O。每一种 I/O 模型的出现,都 是基于前一种 I/O 模型的优化升级。
最开始的阻塞式 I/O,它在每一个连接创建时,都需要一个用户线程来处理,并且在 I/O 操 作没有就绪或结束时,线程会被挂起,进入阻塞等待状态,阻塞式 I/O 就成为了导致性能 瓶颈的根本原因。
那阻塞到底发生在套接字(socket)通信的哪些环节呢?
在《Unix 网络编程》中,套接字通信可以分为流式套接字(TCP)和数据报套接字 (UDP)。其中 TCP 连接是我们最常用的,一起来了解下 TCP 服务端的工作流程(由于 TCP 的数据传输比较复杂,存在拆包和装包的可能,这里我只假设一次最简单的 TCP 数据
传输):
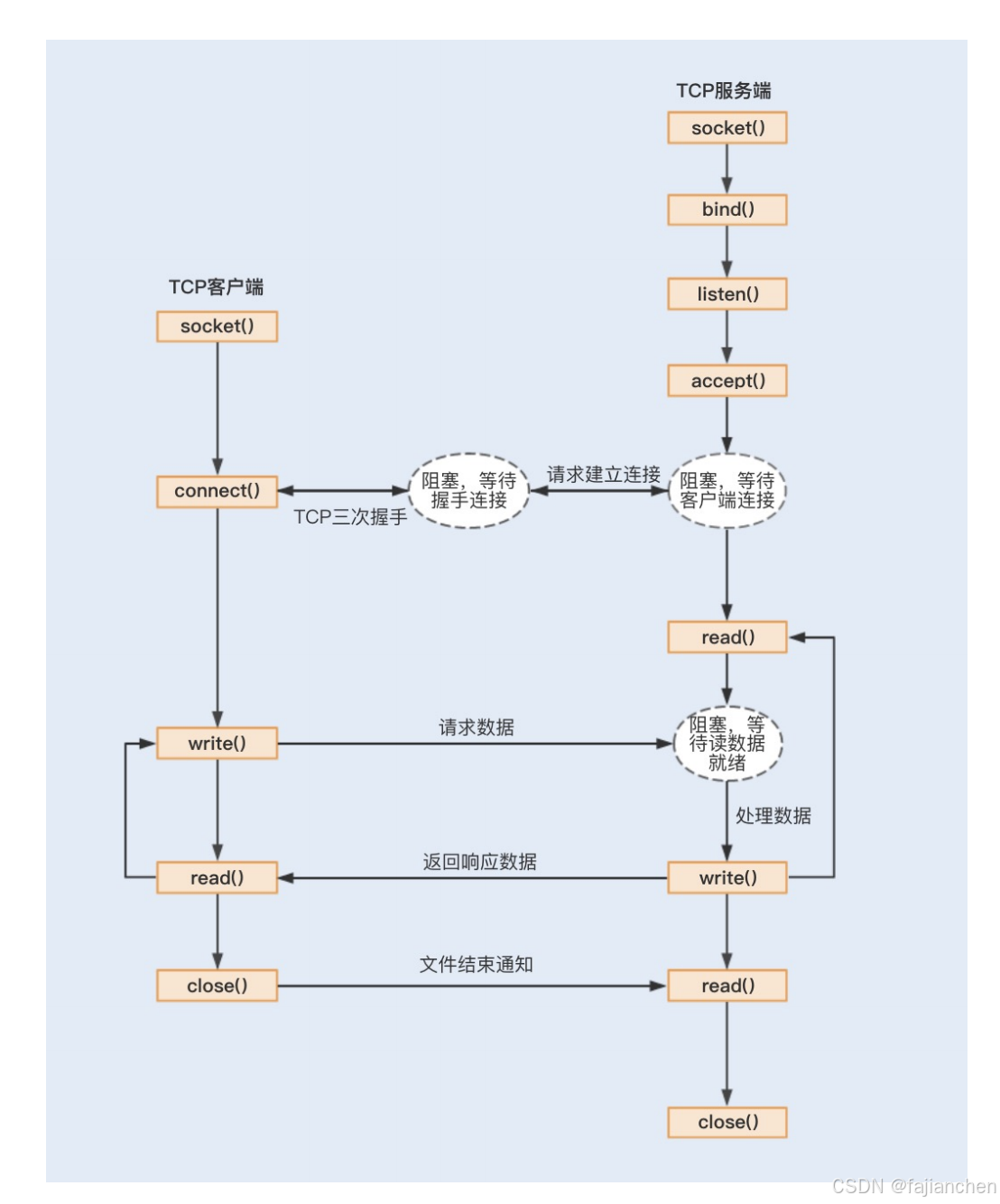
首先,应用程序通过系统调用 socket 创建一个套接字,它是系统分配给应用程序的一个 文件描述符; 其次,应用程序会通过系统调用 bind,绑定地址和端口号,给套接字命名一个名称; 然后,系统会调用 listen 创建一个队列用于存放客户端进来的连接;最后,应用服务会通过系统调用 accept 来监听客户端的连接请求。 当有一个客户端连接到服务端之后,服务端就会调用 fork 创建一个子进程,通过系统调用 read 监听客户端发来的消息,再通过 write 向客户端返回信息。
非阻塞式 I/O
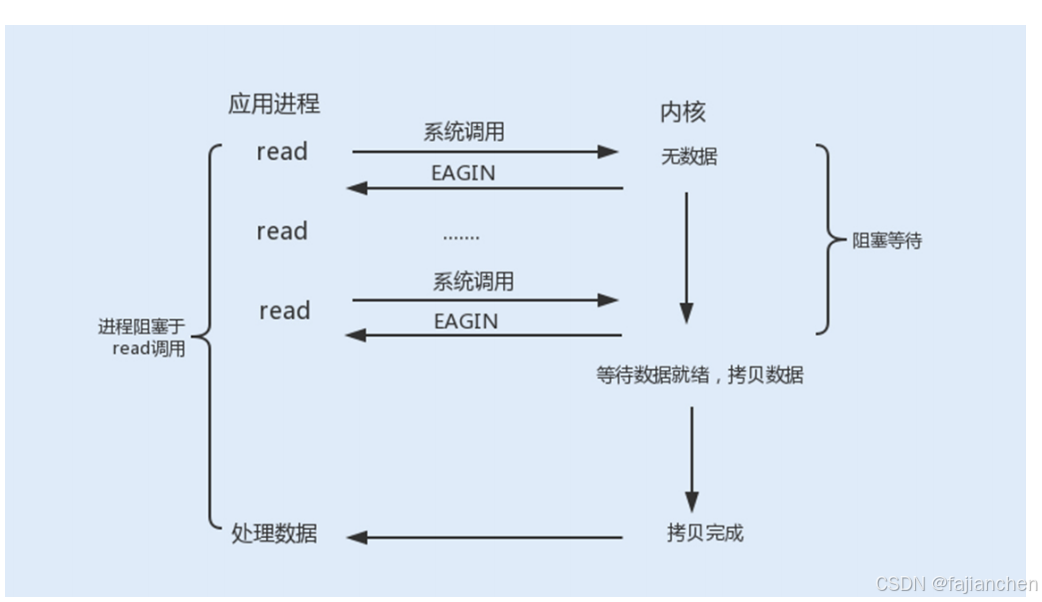
使用 fcntl 可以把以上三种操作都设置为非阻塞操作。如果没有数据返回,就会直接返回一 个 EWOULDBLOCK 或 EAGAIN 错误,此时进程就不会一直被阻塞。
当我们把以上操作设置为了非阻塞状态,我们需要设置一个线程对该操作进行轮询检查,这也是最传统的非阻塞 I/O 模型。
 零拷贝
零拷贝
在 I/O 复用模型中,执行读写 I/O 操作依然是阻塞的,在执行读写 I/O 操作时,存在着多 次内存拷贝和上下文切换,给系统增加了性能开销。
零拷贝是一种避免多次内存复制的技术,用来优化读写 I/O 操作。
在网络编程中,通常由 read、write 来完成一次 I/O 读写操作。每一次 I/O 读写操作都需 要完成四次内存拷贝,路径是 I/O 设备 -> 内核空间 -> 用户空间 -> 内核空间 -> 其它 I/O 设备
Linux 内核中的 mmap 函数可以代替 read、write 的 I/O 读写操作,实现用户空间和内核 空间共享一个缓存数据。mmap 将用户空间的一块地址和内核空间的一块地址同时映射到相同的一块物理内存地址,不管是用户空间还是内核空间都是虚拟地址,最终要通过地址映 射映射到物理内存地址。这种方式避免了内核空间与用户空间的数据交换。I/O 复用中的 epoll 函数中就是使用了 mmap 减少了内存拷贝。
在 Java 的 NIO 编程中,则是使用到了 Direct Buffer 来实现内存的零拷贝。Java 直接在 JVM 内存空间之外开辟了一个物理内存空间,这样内核和用户进程都能共享一份缓存数 据。这是在 08 讲中已经详细讲解过的内容,你可以再去回顾下。
推荐阅读
技术总体方案设计思路
Introduction to UML
业务幂等性技术架构体系