LUFFY(路飞): 使用DeepSeek指导Qwen强化学习
论文标题
Learning to Reason under Off-Policy Guidance
论文地址
https://arxiv.org/pdf/2504.14945
代码地址
https://github.com/ElliottYan/LUFFY
作者背景
上海人工智能实验室,西湖大学,南京大学,香港中文大学
动机
目前大模型的后训练方法有 SFT 和 RL 两种形式,前者强调模仿,后者强调探索。两类后训练方法各有千秋,基于模仿的训练能够快速调整模型的行为模式,但这种调整很可能流于表面而非真正掌握解题策略;基于探索的训练能够使模型自行找出奖励最高的行为策略,但受限于基础模型本身的能力,探索时很可能只是反复尝试当前已掌握的行为模式,难以利用全新的思路去解决问题,实践中我们也经常遇到RL训练进入瓶颈的问题

于是作者希望结合“模仿”与“探索”两种学习方式,让模型自主探索解题策略的同时,也有机会模仿外部强模型的行为模式,从而使大模型获得超越其初始认知边界的推理能力
本文方法
本文提出 LUFFY(Learning to reason Under oFF-policY guidance),核心思想是引入外部强模型(deepseek-R1)作为off-policy,与当前策略模型(on-policy)一同参与采样,从而指导 RL 进行更高效的学习,避免纯 on-policy 模型在面临复杂问题时迟迟探索不出有效策略
一、LUFFY流程与优化目标
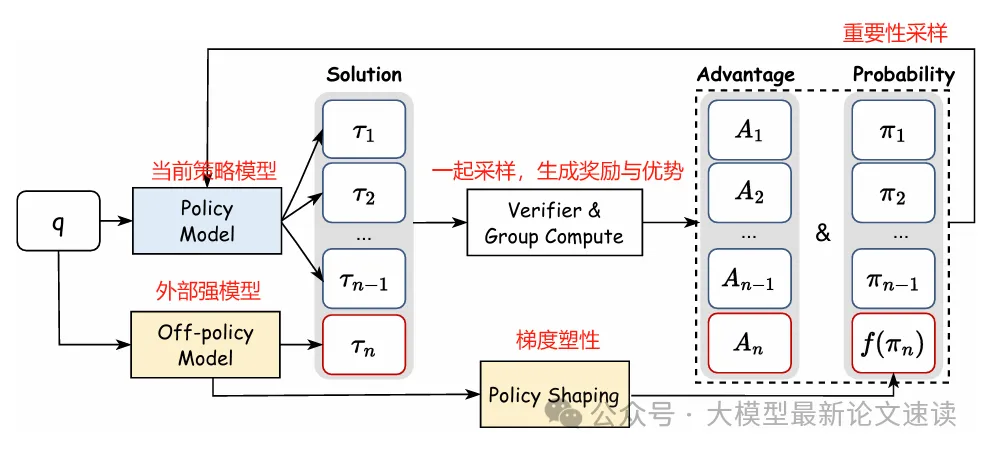
如上图所示,对于问题q,由当前策略模型与外部强模型共同采样一组输出,然后使用统一的奖励函数对所有采样评分(检查格式正确性与答案正确性)
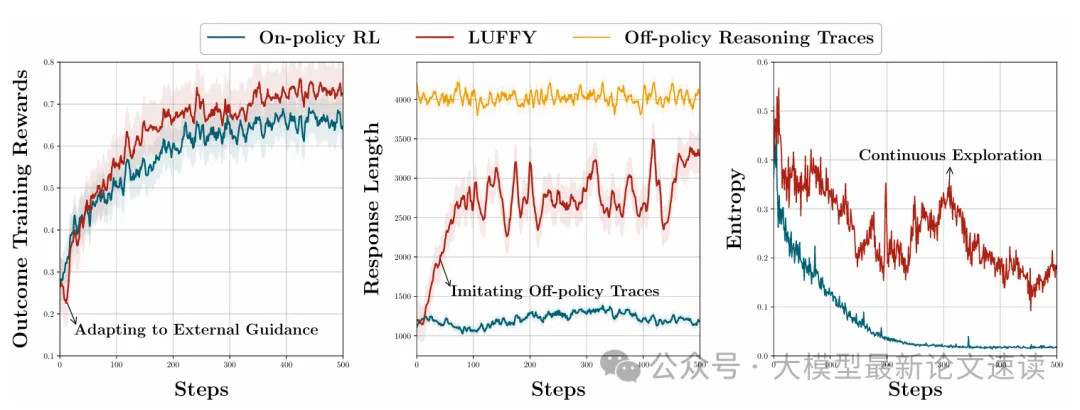
和标准GRPO一样,对所有回答的奖励分数做标准化作为优势,即高于均值的优势为正,低于均值的优势为负或较小。由于外部强模型采样得更少,只有当策略模型难以独立生成正确解时它才占据产生梯度的主导地位,一旦策略模型能够产生成功的推理轨迹, GRPO便开始鼓励自主探索
grpo算法通常需要进行重要性采样,因为它在策略更新过程中,使用旧策略上采样的数据去预估新策略的期望回报

LUFFY中使用了off-policy模型,更需要进行这一校准,其优化目标如下所示:

为了更好地模拟外部强模型的行为,作者最终移除了梯度裁剪
二、梯度塑形
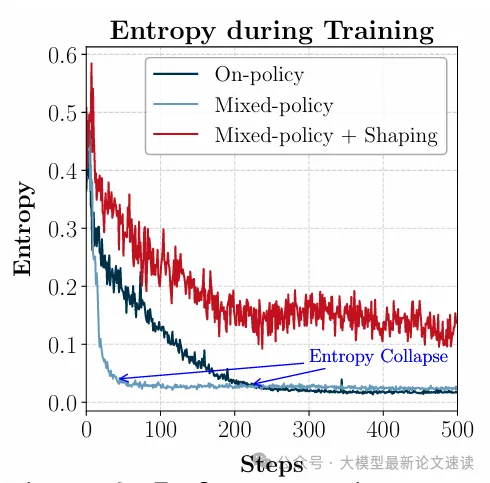
作者发现,直接按照上述流程将外部强模型引入RL训练后,尽管利用重要性采样加速了收敛,但模型表现出低熵、探索行为明细变少。这是因为策略模型在模仿外部模型时,对不同概率的token存在偏差,即策略模型倾向于强化那些【同时常见于 onPolicy 分布与 offPolicy 分布的token】,忽略了【不常见于 OnPolicy 分布的 token】,即便这些token在offPolicy中出现概率很高。如此一来,模型便忽略了这部分体现强模型关键推理能力的低概率token
教师正在认真纠正学生的错误想法,但学生只想着“求同存异”,迅速理解了老师的思想与自己的共同之处,而没关注到老师的独特之处
为了解决这一问题,作者提出了“梯度塑形”方法,本质上便是根据 token 不同的概率对梯度进行加权。具体地,作者使用了 f(x)=γ/(γ+x) 这一变换函数(γ为超参数,实验中取0.1),其函数图像为:
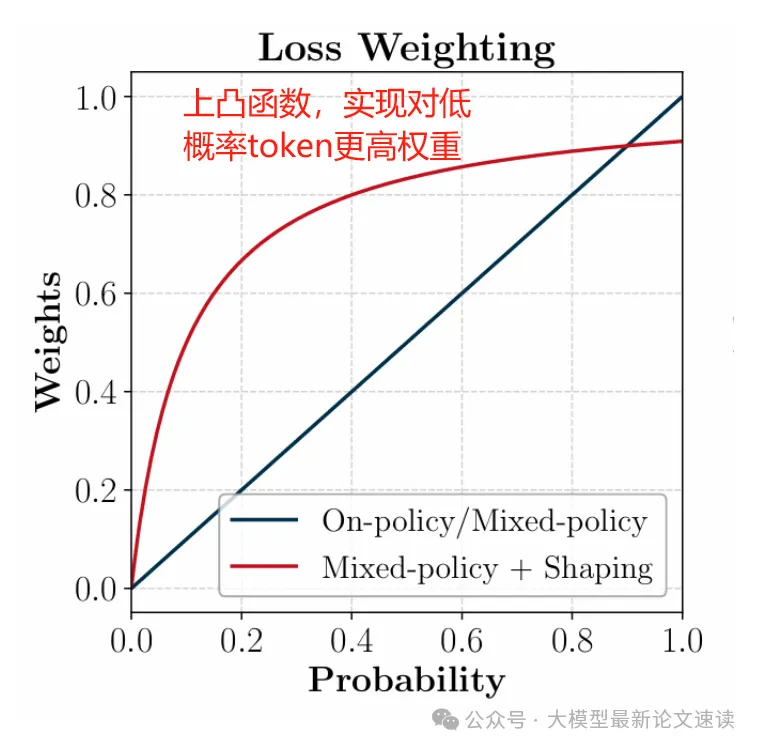
加入梯度塑形后,训练过程中策略模型的熵始终保持在一个较高的状态,即具有更好的探索能力,并且有效避免了 Entropy Collapse
实验结果
基于 Qwen2.5-Math-7B 模型,在OpenR1-Math-220k上进行训练,外部强模型使用DeepSeek-R1,在6个常用的数学推理基准上测试
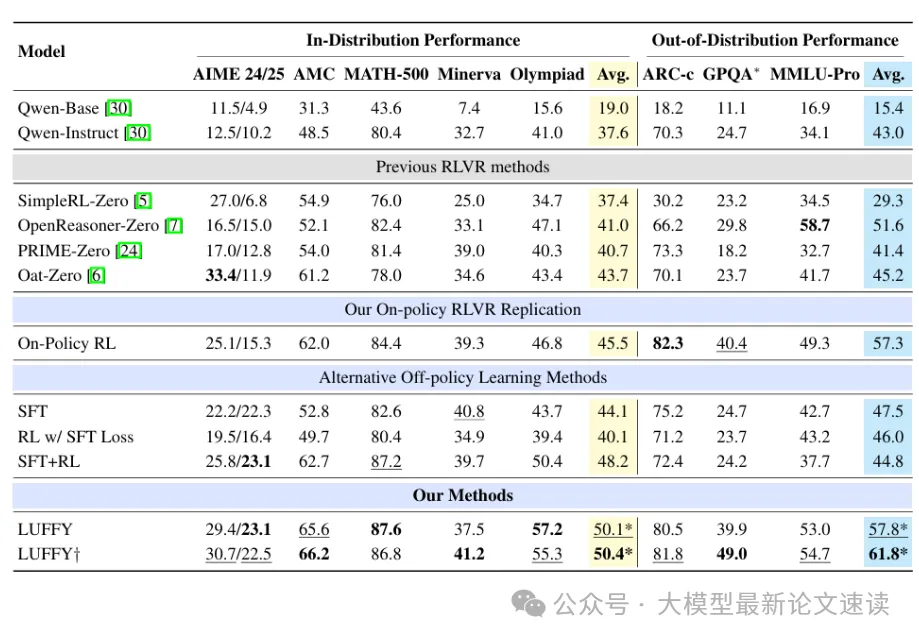
可见 LUFFY 方法全面超越了各类on-policy与off-policy方法
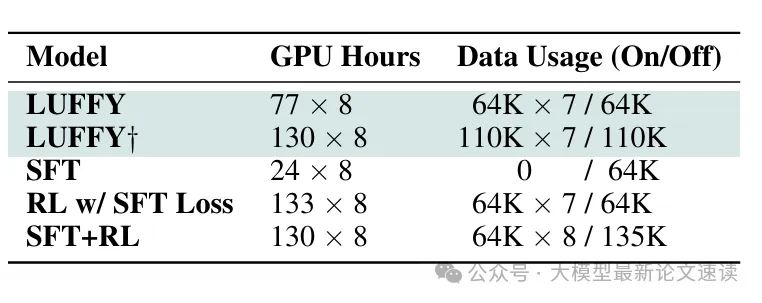
实验各策略的资源开销对比
其他模型实验结果
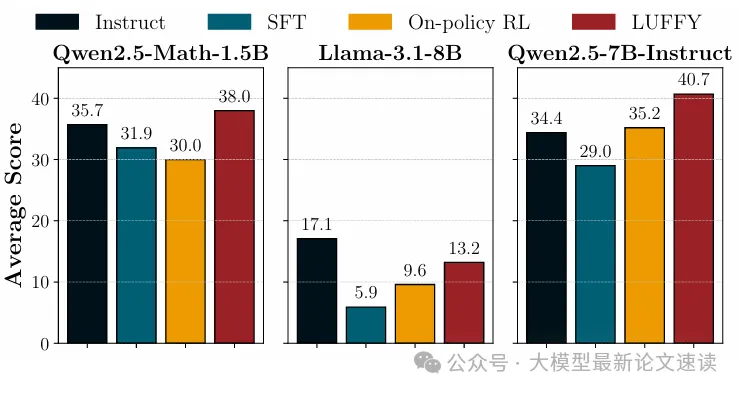
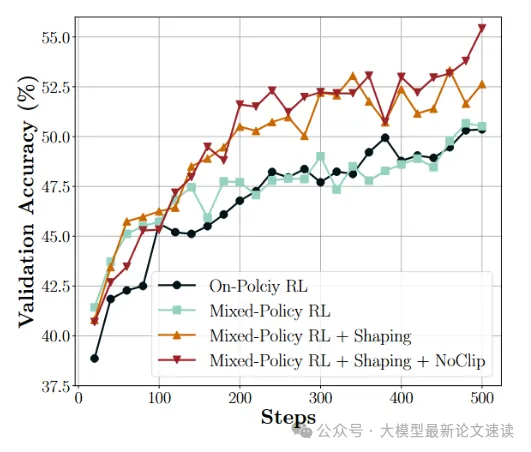
LUFFY与on-policy RL训练动态对比
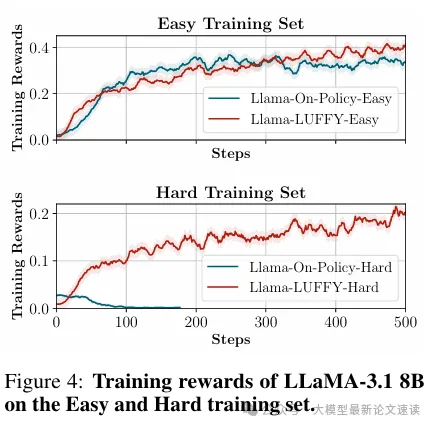
LUFFY 在困难问题上能够问答训练,而on-policy 方法崩溃
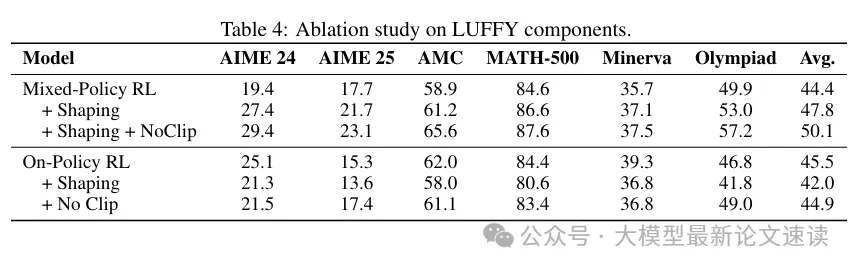
各组件消融实验