redis集群
主从集群,主从复制
单点redis并发能力是有限的,想要进一步提高并发能力,需要搭建redis集群,实现读写分离。
一个主节点master,主要实现增删改操作,多个从节点实现读操作。
当主节点修改了数据,必须要将数据同步给其他从节点。
那么主节点将数据同步给其他从节点具体流程是什么?
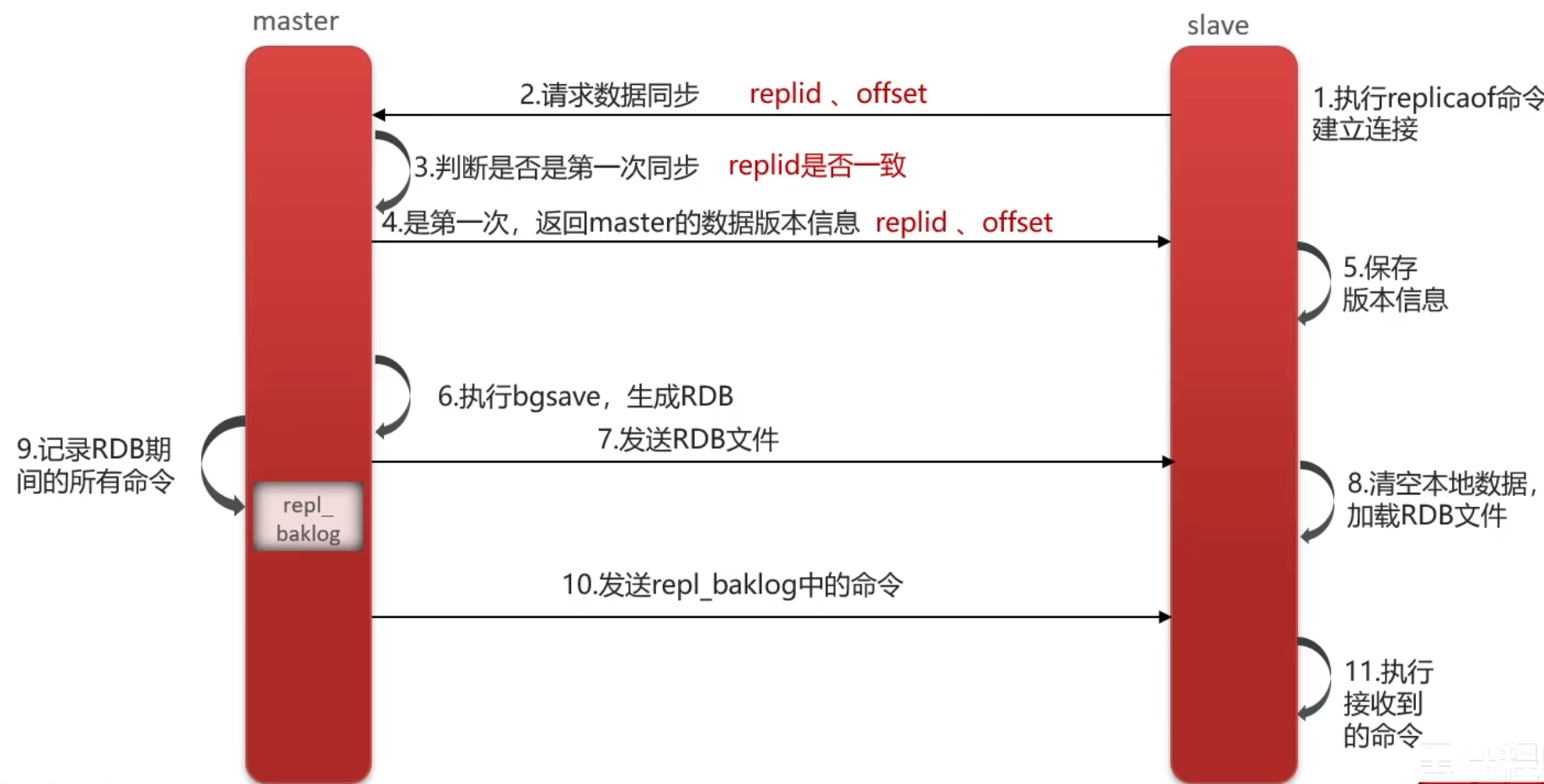
1,全量同步
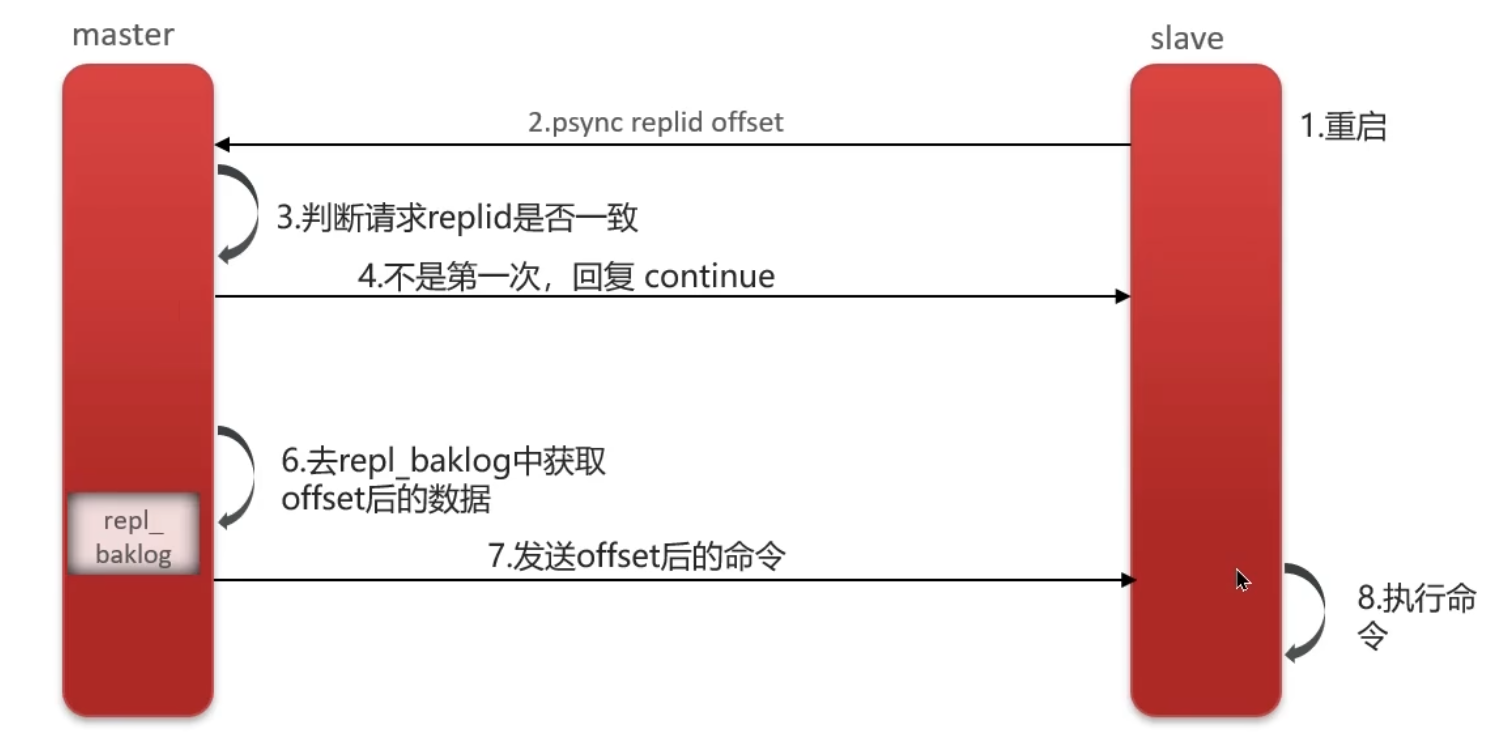
- 从节点执行replicaof命令,建立连接
- 从节点发送数据同步请求
- 主节点判断是否是第一次同步
- 是第一次,返回主节点数据版本信息
- 从节点保存版本信息
- 主节点执行 bgsave 生成 RDB 快照文件
- 主节点将 RDB 文件发送给从节点
- 从节点清空自身数据,加载接收到的 RDB 文件(由于在生成RDB文件时,有可能又有新命令来,所以还有下面的操作)
- 主节点将生成 RDB 期间的新写命令存入复制缓冲区repl_baklog(一个日志文件)
- RDB 加载完成后,主节点将缓冲区中的命令发送给从节点执行
两个关键概念

master如何判断slave是第一次请求?
从节点第一连接主节点时,会发送自己的replid和offset,主节点就会判断是否和自己的replid是否不一致,不一致就说明是第一次请求,vice versa。然后主节点将自己的replid发送给从节点。
同步数据时,如何确保,从节点同步刚好缺少的数据呢?
如果判断不是第一次连接,那就不会生成RDB文件,而是通过repl_baklog文件去同步数据
那怎么决定从repl_baklog文件读取多少文件呢,读的刚好是从节点缺的数据呢?
那就要用到offset信息。如果从节点offset值为50,主节点offset值为80,那就说明,50-80间的数据还没同步,那就同步50-80间的repl_baklog文件即可。
2,增量同步(发生在slave重启/后期数据变化)
- 初次同步完成后,主节点将每个写命令发送给从节点
- 从节点接收并执行这些命令,保持与主节点数据一致