提升模型泛化能力:PyTorch的L1、L2、ElasticNet正则化技术深度解析与代码实现
神经网络训练过程中,模型优化与过拟合防控之间的平衡是一个核心挑战。过拟合的模型虽然在训练数据上表现优异,但由于其复杂性导致模型将训练数据集的特定特征作为映射函数的组成部分,在实际部署环境中往往表现不佳,甚至出现性能急剧下降的问题。
正则化技术是解决此类问题的有效方法。本文将深入探讨L1、L2和ElasticNet正则化技术,重点关注其在PyTorch框架中的具体实现。关于这些技术的理论基础,建议读者参考相关理论文献以获得更深入的理解。通过本文的学习,您将掌握神经网络正则化的必要性、L1、L2和ElasticNet正则化的理论工作机制,以及在PyTorch中实现这些正则化技术的具体方法。

正则化技术的必要性
神经网络的训练目标是建立输入变量向量x与目标变量y之间的映射关系。这种映射关系可以用数学函数f表示,即y = f(x)。
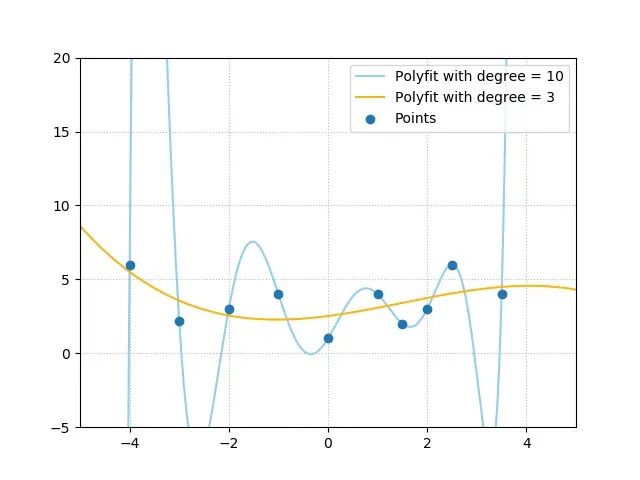
映射函数的特性取决于模型的设计和拟合方式。如下图所示,使用相同的输入数据点集合,我们构建了两种不同的映射函数。第一种是具有三个自由度的多项式拟合(黄线),第二种是具有十个自由度的多项式拟合(蓝线)。
在评估哪种映射更接近真实情况时,具有较少自由度的黄线映射通常更为合理。蓝线所示的极端拟合情况在实际应用中极不可能成立,这种过度拟合现象往往源于模型对数据集中异常值的过度敏感性。
神经网络的训练过程需要使用输入数据(x集合)为每个样本生成预测结果(对应的y集合)。网络中的可训练参数协同工作以逼近真实的映射关系y = f(x),生成的逼近函数记为ŷ = f(x)。
在前向传播和模型优化过程中,我们无法预知模型将学习到类似黄线的合理映射还是类似蓝线的过拟合映射。模型仅基于损失函数的最小化进行学习,这可能导致学习到不理想的过拟合映射。
除了Dropout这一常用的正则化机制外,主要的正则化方法包括三种类型:L1正则化(也称为Lasso正则化)通过将所有权重的绝对值添加到损失函数中实现;L2正则化(也称为Ridge正则化)通过将所有权重的平方值添加到损失函数中实现;ElasticNet正则化则以加权方式组合L1和L2正则化。
接下来我们将详细研究每种正则化方法,并提供在PyTorch中的具体实现示例。
PyTorch中L1正则化的实现
在使用基于PyTorch的分类器进行二元交叉熵损失计算时,实现L1正则化需要将以下数值添加到损失函数中:
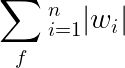
其中n表示权重参数的总数,通过遍历所有权重参数,计算每个权重值w_i的绝对值并求和得到L1正则化项。
L1正则化损失的计算公式为:
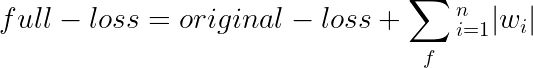
这里的
original_loss
表示原始的二元交叉熵损失,但该方法几乎适用于任何损失函数。
以下是PyTorch中L1正则化的完整实现方案。我们定义了一个继承自PyTorch
nn.Module
类的
MLP
类,并在该类中添加了
compute_l1_loss
函数,用于计算特定可训练参数的绝对值之和。在训练循环中,我们指定L1权重系数,收集所有参数,计算L1损失,并在误差反向传播之前将其添加到损失函数中。同时,在输出统计信息时显示损失的L1分量。
importos
importtorch
fromtorchimportnn
fromtorchvision.datasetsimportMNIST
fromtorch.utils.dataimportDataLoader
fromtorchvisionimporttransforms classMLP(nn.Module): ''' 多层感知器。 ''' def__init__(self): super().__init__() self.layers=nn.Sequential( nn.Flatten(), nn.Linear(28*28*1, 64), nn.ReLU(), nn.Linear(64, 32), nn.ReLU(), nn.Linear(32, 10) ) defforward(self, x): '''前向传播''' returnself.layers(x) defcompute_l1_loss(self, w): returntorch.abs(w).sum() if__name__=='__main__': # 设置固定的随机数种子 torch.manual_seed(42) # 准备MNIST数据集 dataset=MNIST(os.getcwd(), download=True, transform=transforms.ToTensor()) trainloader=torch.utils.data.DataLoader(dataset, batch_size=10, shuffle=True, num_workers=1) # 初始化MLP mlp=MLP() # 定义损失函数和优化器 loss_function=nn.CrossEntropyLoss() optimizer=torch.optim.Adam(mlp.parameters(), lr=1e-4) # 运行训练循环 forepochinrange(0, 5): # 训练5个epoch # 打印当前epoch print(f'Starting epoch {epoch+1}') # 遍历DataLoader获取训练数据 fori, datainenumerate(trainloader, 0): # 获取输入数据和标签 inputs, targets=data # 梯度清零 optimizer.zero_grad() # 执行前向传播 outputs=mlp(inputs) # 计算原始损失 loss=loss_function(outputs, targets) # 计算L1正则化损失分量 l1_weight=1.0 l1_parameters= [] forparameterinmlp.parameters(): l1_parameters.append(parameter.view(-1)) l1=l1_weight*mlp.compute_l1_loss(torch.cat(l1_parameters)) # 将L1损失分量添加到总损失中 loss+=l1 # 执行反向传播 loss.backward() # 执行优化步骤 optimizer.step() # 打印训练统计信息 minibatch_loss=loss.item() ifi%500==499: print('Loss after mini-batch %5d: %.5f (of which %.5f L1 loss)'% (i+1, minibatch_loss, l1)) current_loss=0.0 # 训练完成 print('Training process has finished.')
PyTorch中L2正则化的实现
L2正则化在PyTorch中同样可以便捷地实现。与L1正则化不同,L2正则化计算权重值的平方而非绝对值。具体而言,我们将\sum_{i=1}^{n} w_i^2添加到损失函数中。以下示例展示了在PyTorch中应用L2正则化的具体方法:
importos
importtorch
fromtorchimportnn
fromtorchvision.datasetsimportMNIST
fromtorch.utils.dataimportDataLoader
fromtorchvisionimporttransforms classMLP(nn.Module): ''' 多层感知器。 ''' def__init__(self): super().__init__() self.layers=nn.Sequential( nn.Flatten(), nn.Linear(28*28*1, 64), nn.ReLU(), nn.Linear(64, 32), nn.ReLU(), nn.Linear(32, 10) ) defforward(self, x): '''前向传播''' returnself.layers(x) defcompute_l2_loss(self, w): returntorch.square(w).sum() if__name__=='__main__': # 设置固定的随机数种子 torch.manual_seed(42) # 准备MNIST数据集 dataset=MNIST(os.getcwd(), download=True, transform=transforms.ToTensor()) trainloader=torch.utils.data.DataLoader(dataset, batch_size=10, shuffle=True, num_workers=1) # 初始化MLP mlp=MLP() # 定义损失函数和优化器 loss_function=nn.CrossEntropyLoss() optimizer=torch.optim.Adam(mlp.parameters(), lr=1e-4) # 运行训练循环 forepochinrange(0, 5): # 训练5个epoch # 打印当前epoch print(f'Starting epoch {epoch+1}') # 遍历DataLoader获取训练数据 fori, datainenumerate(trainloader, 0): # 获取输入数据和标签 inputs, targets=data # 梯度清零 optimizer.zero_grad() # 执行前向传播 outputs=mlp(inputs) # 计算原始损失 loss=loss_function(outputs, targets) # 计算L2正则化损失分量 l2_weight=1.0 l2_parameters= [] forparameterinmlp.parameters(): l2_parameters.append(parameter.view(-1)) l2=l2_weight*mlp.compute_l2_loss(torch.cat(l2_parameters)) # 将L2损失分量添加到总损失中 loss+=l2 # 执行反向传播 loss.backward() # 执行优化步骤 optimizer.step() # 打印训练统计信息 minibatch_loss=loss.item() ifi%500==499: print('Loss after mini-batch %5d: %.5f (of which %.5f l2 loss)'% (i+1, minibatch_loss, l2)) current_loss=0.0 # 训练完成 print('Training process has finished.')
L2损失的替代实现方法
基于L2的权重衰减也可以通过在优化器中设置
weight_decay
参数来实现。
weight_decay (float*, 可选*) — 权重衰减 (L2惩罚) (默认值: 0)
PyTorch 文档
实现示例:
optimizer=torch.optim.Adam(mlp.parameters(), lr=1e-4, weight_decay=1.0)
PyTorch中ElasticNet正则化的实现
ElasticNet正则化可以通过PyTorch高效实现。该正则化方法本质上是L1和L2损失的加权组合,权重之和为1.0。具体而言,我们将以下表达式添加到损失函数中:
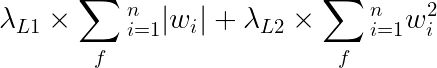
其数学表达式为:
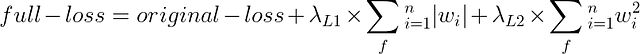
以下示例展示了在PyTorch中实现ElasticNet(L1+L2)正则化的具体方法。在这个实现中,MLP类提供了计算L1和L2损失的独立函数。在训练循环中,这两种损失以加权方式应用(权重分别为0.3和0.7)。在输出统计信息时,各损失分量也会显示在控制台中。
importos
importtorch
fromtorchimportnn
fromtorchvision.datasetsimportMNIST
fromtorch.utils.dataimportDataLoader
fromtorchvisionimporttransforms classMLP(nn.Module): ''' 多层感知器。 ''' def__init__(self): super().__init__() self.layers=nn.Sequential( nn.Flatten(), nn.Linear(28*28*1, 64), nn.ReLU(), nn.Linear(64, 32), nn.ReLU(), nn.Linear(32, 10) ) defforward(self, x): '''前向传播''' returnself.layers(x) defcompute_l1_loss(self, w): returntorch.abs(w).sum() defcompute_l2_loss(self, w): returntorch.square(w).sum() if__name__=='__main__': # 设置固定的随机数种子 torch.manual_seed(42) # 准备MNIST数据集 dataset=MNIST(os.getcwd(), download=True, transform=transforms.ToTensor()) trainloader=torch.utils.data.DataLoader(dataset, batch_size=10, shuffle=True, num_workers=1) # 初始化MLP mlp=MLP() # 定义损失函数和优化器 loss_function=nn.CrossEntropyLoss() optimizer=torch.optim.Adam(mlp.parameters(), lr=1e-4) # 运行训练循环 forepochinrange(0, 5): # 训练5个epoch # 打印当前epoch print(f'Starting epoch {epoch+1}') # 遍历DataLoader获取训练数据 fori, datainenumerate(trainloader, 0): # 获取输入数据和标签 inputs, targets=data # 梯度清零 optimizer.zero_grad() # 执行前向传播 outputs=mlp(inputs) # 计算原始损失 loss=loss_function(outputs, targets) # 指定L1和L2权重系数 l1_weight=0.3 l2_weight=0.7 # 计算L1和L2正则化损失分量 parameters= [] forparameterinmlp.parameters(): parameters.append(parameter.view(-1)) l1=l1_weight*mlp.compute_l1_loss(torch.cat(parameters)) l2=l2_weight*mlp.compute_l2_loss(torch.cat(parameters)) # 将L1和L2损失分量添加到总损失中 loss+=l1 loss+=l2 # 执行反向传播 loss.backward() # 执行优化步骤 optimizer.step() # 打印训练统计信息 minibatch_loss=loss.item() ifi%500==499: print('Loss after mini-batch %5d: %.5f (of which %.5f L1 loss; %0.5f L2 loss)'% (i+1, minibatch_loss, l1, l2)) current_loss=0.0 # 训练完成 print('Training process has finished.')
总结
本文深入探讨了神经网络正则化的重要性,详细分析了L1、L2和ElasticNet正则化的理论机制,并通过具体示例演示了这些技术在PyTorch中的实现方法。正则化技术是防止模型过拟合的关键手段,通过在损失函数中添加权重惩罚项,能够有效提升模型的泛化能力。
L1正则化通过权重的绝对值惩罚促进稀疏性,L2正则化通过权重的平方惩罚控制模型复杂度,而ElasticNet正则化则结合两者的优势,提供了更灵活的正则化策略。在实际应用中,选择合适的正则化方法和权重系数对于获得最佳的模型性能至关重要。
希望通过本文的学习,读者能够掌握在深度学习项目中应用正则化技术的方法,并理解其在提升模型性能中的重要作用。
https://avoid.overfit.cn/post/9848d169f0a74458b8dbec5591e8885e
作者:Francesco Franco