【C++11新特性】
文章目录
- 类型推导(auto/decltype)
- 序列for循环
- lamdba表达式
- 构造函数
- 委托构造函数
- 继承构造函数
- array&forward_list
- array容器
- forward_list
- 垃圾回收机制
- C++没有垃圾回收机制的原因:
- 垃圾回收算法种类
- 正则表达式
- 符号
- 速记理解技巧
- 校验数字的表达式
- 校验字符的表达式
- 特殊需求表达式
- 应用
- 智能指针
- unique_ptr
- shared_ptr智能指针
- make_shared函数
- waek_ptr
- nullptr&constexpr
- nullptr关键字
- constexpr关键字
- 共享内存
- std::unordered_set
- 关联容器 unordered_map
- function函数对象
- atomic_flag应用
- condition_variable
- 异常处理Exception
- std::thread多线程
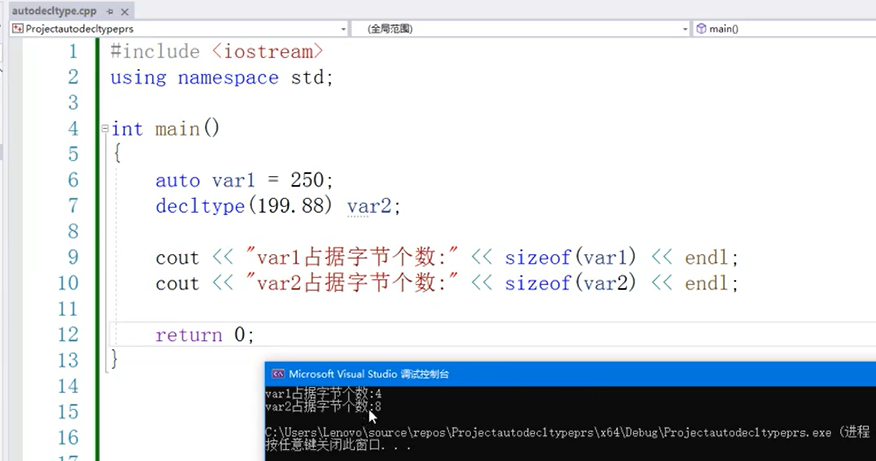
类型推导(auto/decltype)
语法
auto 变量名称=值;
decltype(表达式) 变量名称[=值]
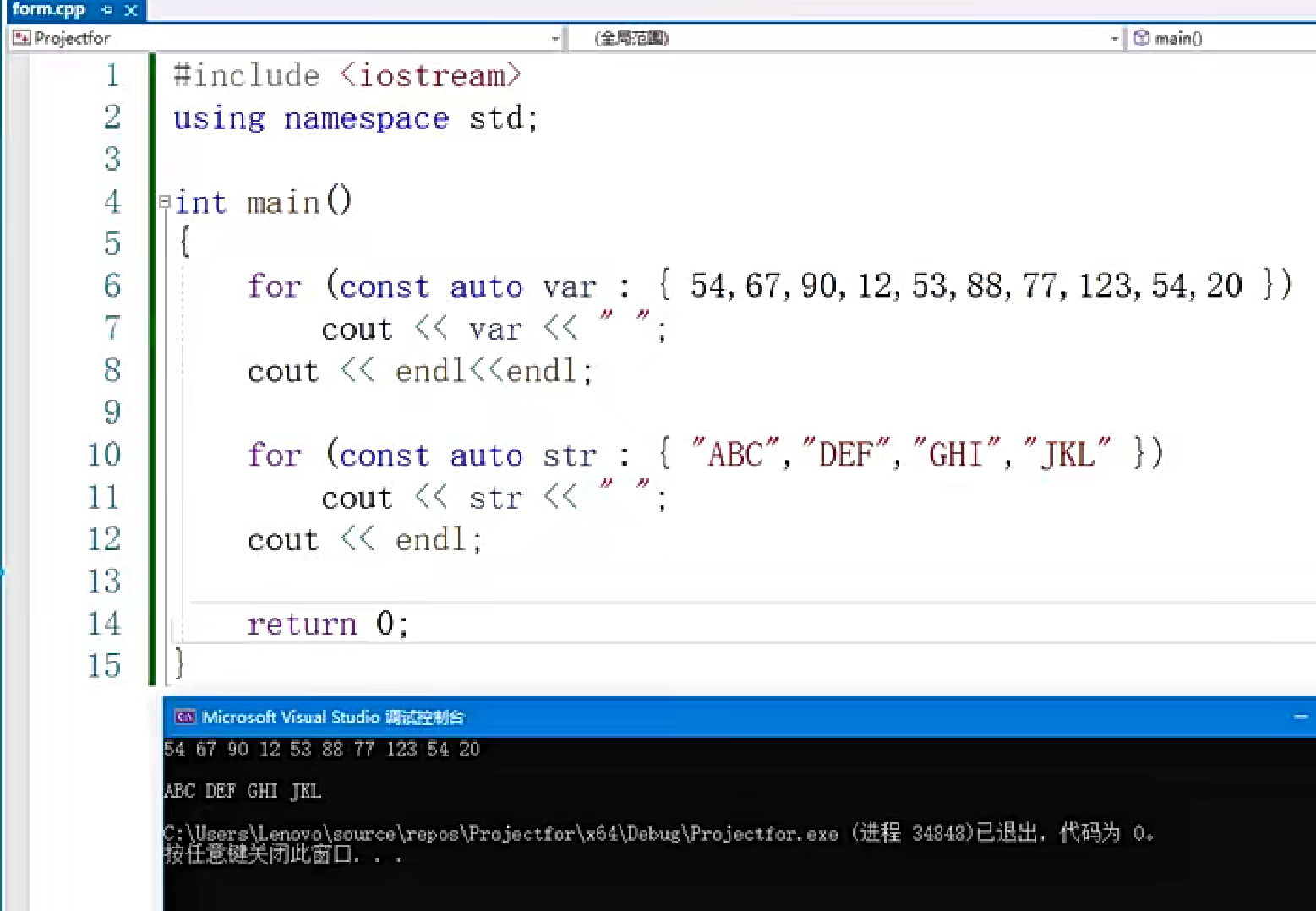
序列for循环
可以遍历数组、容器、string字符串以及由begin/end函数定义的序列
使用auto关键字自动推导遍历元素的类型,无需显式声明
lamdba表达式
定义:用于定义并创建匿名的函数对象,主要目的是简化编程工作
特点:是C++11标准引入的重要特性,可以直接在代码中定义临时函数
应用场景:常用于STL算法中作为回调函数,如排序、查找等操作
语法
[捕获列表](参数列表) mutable exception->return type {函数体}
- 捕获列表:用于捕获外部变量,指定哪些外部变量可以在lambda体内使用
- 参数列表:与普通函数参数列表类似,定义lambda表达式接收的参数
- mutable指示符:决定是否允许修改捕获的变量(默认不允许)
- 异常说明:指定lambda表达式可能抛出的异常类型
- 返回类型:使用->指定返回类型(可省略,编译器会自动推导)
- 函数体:包含lambda表达式的实际执行代码
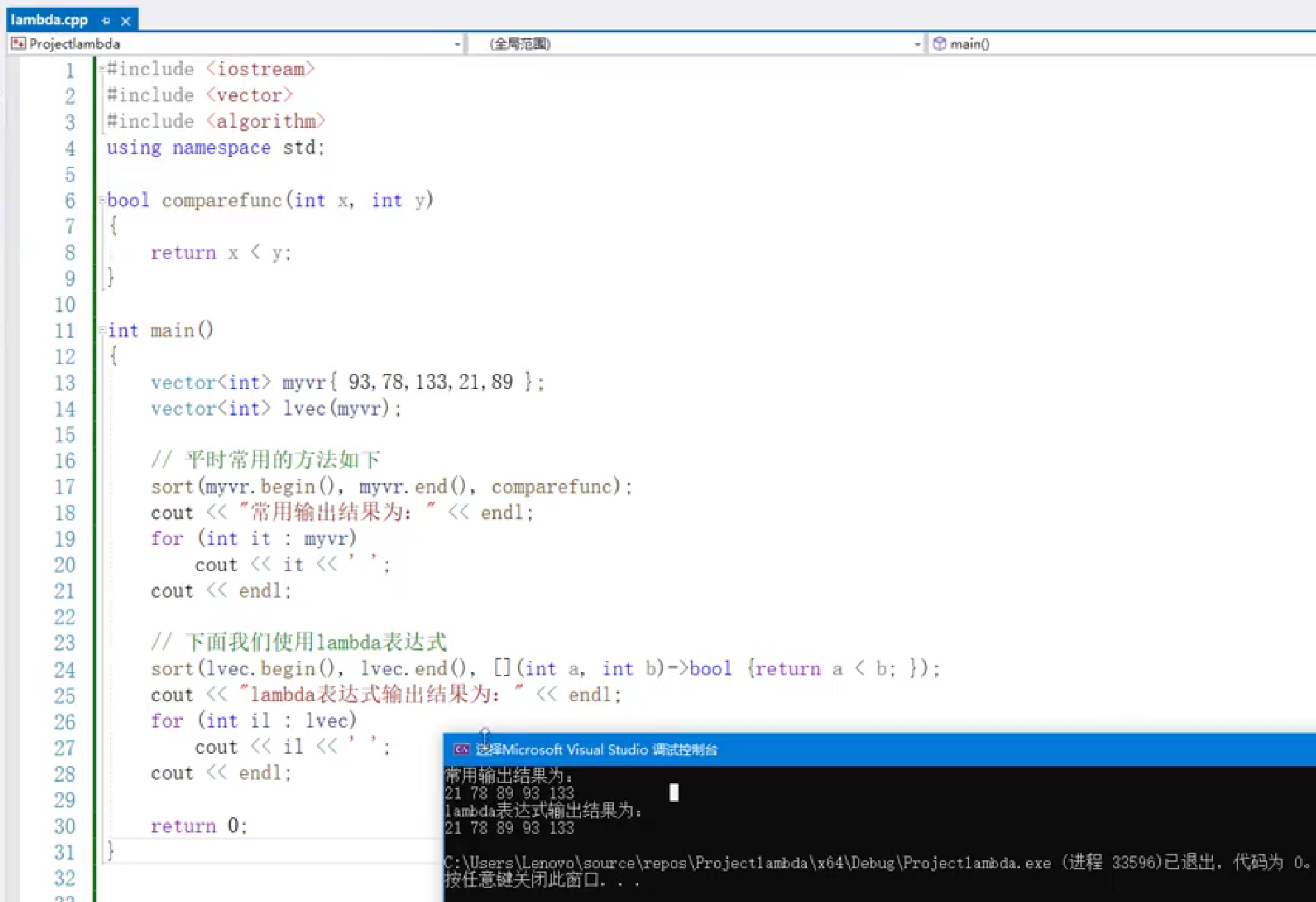
传统方法:
先定义比较函数
bool comparefunc(int x, int y) { return x < y; }
然后调用
sort(myvr.begin(), myvr.end(), comparefunc)
lambda表达式方法:
直接内联定义比较逻辑:
sort(lvec.begin(), lvec.end(), [](int a, int b)->bool { return a < b; })
构造函数
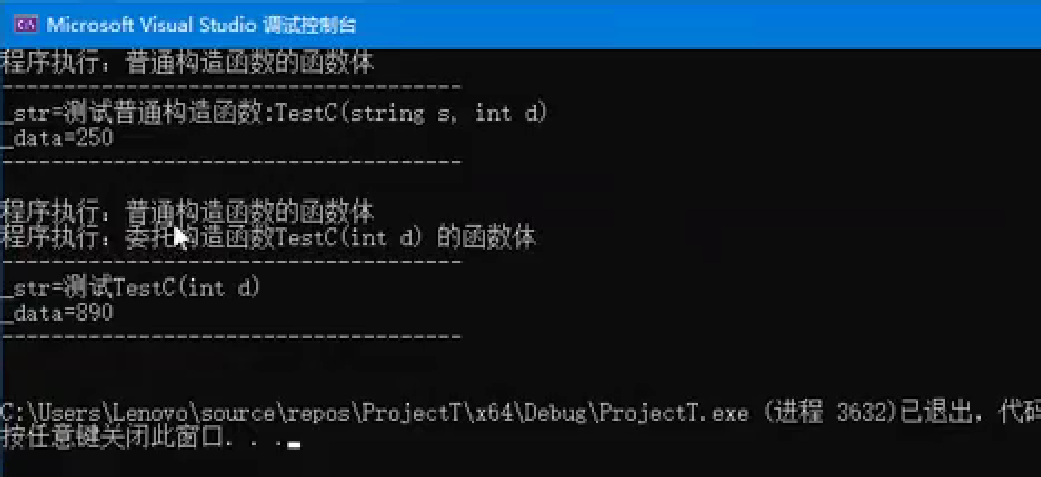
普通构造函数和委托构造函数区别
共同点:两者都包含成员初始化值列表和函数体结构
核心区别:
- 参数限制:委托构造函数的成员初始化值列表只能包含一个参数,且必须是同类的其他构造函数
- 执行顺序:当被委托构造函数的函数体有代码时,会先执行完被委托构造函数的代码,再返回执行委托构造函数的代码
- 禁止递归:构造函数不能委托给自身,否则会导致无限递归
委托构造函数
#include <iostream>
#include <string>
using namespace std;
// 创建一个类
class TestC {
public:// 普通构造函数TestC(string s, int d): _data(d), _str(s){cout << "程序执行:普通构造函数TestC(string s, int d)" << endl;}// 委托构造函数TestC(int d): TestC("测试TestC(int d)", d){cout << "程序执行:委托构造函数TestC(int d) 的函数体" << endl;}void printdata() const{cout << "------------------------" << endl;cout << "_str=" << _str << endl;cout << "_data=" << _data << endl;cout << "------------------------" << endl << endl;}
private:int _data;string _str;
};
int main()
{TestC obj1("测试普通构造函数:TestC(string s, int d)", 250);obj1.printdata();TestC obj2(890);obj2.printdata();return 0;
}
继承构造函数
基本概念:在C++中,构造函数不能被继承,因为构造函数不能是虚函数。但可以通过特定手段实现类似继承的效果。
实现方式:使用using关键字可以让派生类"继承"基类的构造函数,这是C++11标准引入的特性。
#include <iostream>
using namespace std;struct A {void func(double d) {cout << "基类A:" << d << endl << endl;}
};struct B : A {using A::func; // C++11标准当中利用using关键字特点,是构造函数可以被“继承”。void func(int i) {cout << "派生类B:" << i << endl << endl;}
};int main() {A a;a.func(78);B b;b.func(87);return 0;
}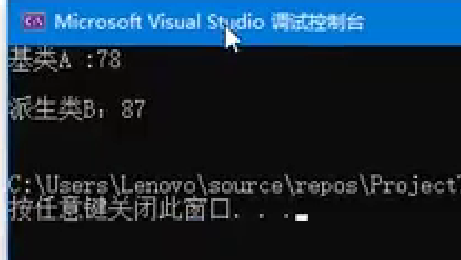
构造函数继承不是真正的继承,而是通过using声明引入基类构造函数.
派生类必须显式使用using声明才能使用基类构造函数.
派生类可以重载基类构造函数,提供不同参数版本的实现.
array&forward_list
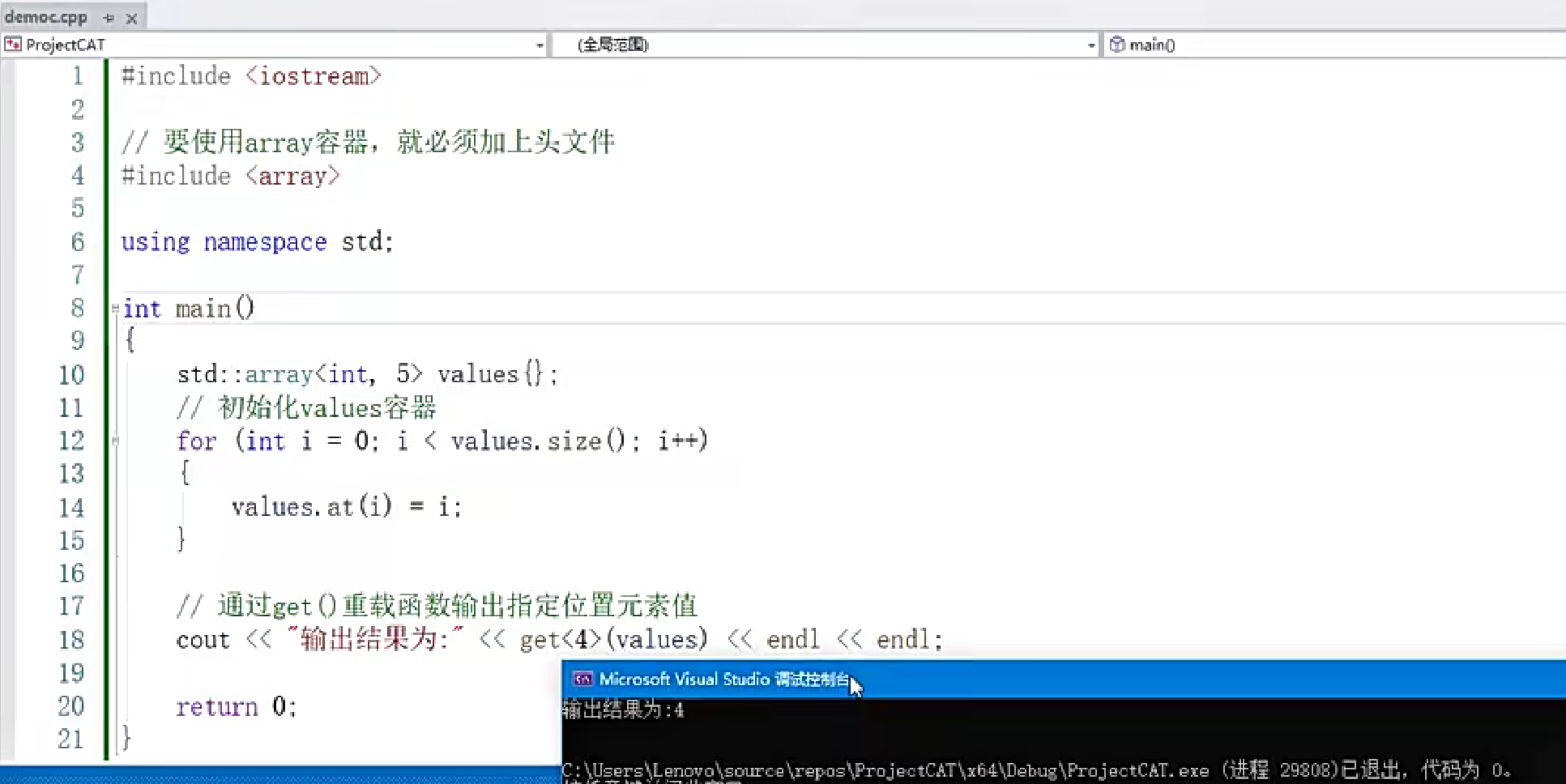
array容器
固定大小: 大小固定无法动态扩展或收缩,只能替换或访问元素
常用函数: 包含end()、begin()、read()、size()、importing()等成员函数
头文件: 必须包含#include
初始化: 使用std::array<int,5> values{}声明包含5个int元素的数组
元素访问: 通过at()方法访问元素,注意下标从0开始
输出元素: 使用get<4>(values)获取第5个元素(索引从0开始)
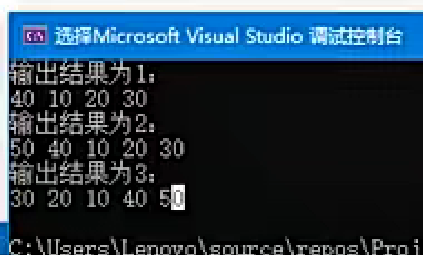
forward_list
链表类型: 使用单向链表实现,而list容器使用双向链表
常用函数: 包含begin()、end()、cbgin()、cend()、importing()、marks()、size()、front()等
头文件: 必须包含
#include <forward_list>
插入元素:
使用emplace_front()在链表前端插入元素
使用emplace_after()在指定位置后插入元素
反转操作: 通过reverse()方法反转链表顺序
#include <iostream>
#include <forward_list>
using namespace std;int main()
{std::forward_list<int> values{10, 20, 30};values.emplace_front(40);cout << "输出结果1为:" << endl;for (auto it = values.begin(); it != values.end(); it++){cout << *it << " ";}cout << endl;values.emplace_after(values.before_begin(), 50);cout << "输出结果2为:" << endl;for (auto it = values.begin(); it != values.end(); it++){cout << *it << " ";}cout << endl;value.reverse();cout << "输出结果3为:" << endl;for (auto it = values.begin(); it != values.end(); it++){cout << *it << " ";}cout << endl;
}
垃圾回收机制
C++没有垃圾回收机制的原因:
系统开销: 垃圾回收所带来的系统开销不符合C++标准高效的特性,不适合做底层工作。
耗内存: C++设计时的内存环境非常少,垃圾回收机制需要占用很多内存,可能耗尽内存。
替代方法: C++有析构函数、智能指针和引用技术等管理资源释放的方法,对垃圾回收(GC)的需求不迫切。
没有共同基类: 没有统一的垃圾回收机制标准。
垃圾回收算法种类
-
引用计数算法
- 算法原理: 每个对象计算指向它的指针数量,当指针指向自己时计数值增加一,删除指向自己的指针时计数值减一。计数值为零时,对象可以被安全销毁释放。
-
标记-清除算法
- 算法原理: 依赖于对所有活动对象进行一次全局遍历来确定哪些对象可以回收。从根结点出发,找到所有可以到达的对象,除此之外的其他不可到达的对象就是垃圾对象,可以被回收。
-
节点拷贝算法
- 算法原理: 把整个堆分成两个半区,GC的过程就是把一些存活的对象从一半拷贝到另一半。在下一次回收时,两个半区可以互换角色。移动结束后,更新对象的指针引用。
正则表达式
概念:正则表达式(Regular Expression)又称规则表达式,用于检索、替换符合特定模式的文本
符号
-
组成元素:
- 普通字符:大小写字母和数字
- 元字符:具有特殊含义的符号(如等)
-
元字符功能:
\:转义字符(如\n匹配换行符,\匹配\)
^:匹配字符串开头
$:匹配字符串结尾
.:匹配除换行符外的任意字符
速记理解技巧
- 基础字符:
.、[]、^、$是所有语言支持的基础正则符号 - 等价概念:
? 等价于 {0,1}
* 等价于 {0,}
+ 等价于 {1,}
\d 等价于 [0-9]
\D 等价于 [^0-9]
\w 等价于 [A-Za-z0-9]
\W 等价于 [^A-Za-z0-9]
校验数字的表达式
- 基础数字:
^[0-9]*$ - n位数字:
^\d{n}$ - m-n位数字:
^\d{m,n}$ - 带小数数字:
- 非零开头最多两位小数:
^([1-9][0-9]*)+(.[0-9]{1,2})?$ - 正负数带1-2位小数:
^(-)?\d+(.\d{1,2})?$
- 非零开头最多两位小数:
- 特殊格式:
- 有两位小数的正实数:
^[0-9]+(.[0-9]{2})?$ - 非零正整数:
^[1-9]\d*$
- 有两位小数的正实数:
校验字符的表达式
- 汉字:
^[\u4e00-\u9fa5]{0,}$ - 英文数字组合:
- 基础形式:
^[A-Za-z0-9]+$ - 长度限制:
^[A-Za-z0-9]{4,40}$
- 基础形式:
- 特殊组合:
- 数字字母下划线:
^\w+$ - 中文英文数字(不含符号):
^[\u4E00-\u9FA5A-Za-z0-9]+$
- 数字字母下划线:
- 禁止字符:如禁止输入~:
[^~]+
特殊需求表达式
- Email地址:
^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$ - 域名:
[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(\.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+\.? - 手机号码:
^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\d{8}$ - 身份证号:
15/18位数字:^\d{15}|\d{18}$
短身份证(含X结尾):^([0-9]){7,18}(x|X)?$ - 腾讯QQ号:
[1-9][0-9]{4,}(从10000开始) - 中国邮政编码:
[1-9]\d{5}(?!\d)(6位数字)
应用
#include <iostream>
#include <string>
#include <regex>int main(){std::regex string_reg("[1-9](\\d{5,11})");std::string strtest("1032");std::smatch matchresults;// 正则匹配if (std::regex_match(strtest, matchresults, string_reg)){std::cout << "Match:" << std::endl;// 输出表达式结果for (size_t i = 0; i < matchresults.size(); i++){std::cout << matchresults[i] << std::endl;}}else{std::cout << "Not Match:" << std::endl;}return 0;
}
模式定义:使用
std::regex类定义正则表达式模式,如std::regex string_reg("[1-9](\\d{5,11})")
匹配规则:示例模式[1-9](\\d{5,11})表示:
首位必须是1-9的数字
后跟5到11位数字(\d表示数字,{5,11}表示重复次数范围)
匹配函数:使用std::regex_match()进行完整匹配
- 参数1:待匹配字符串(如"1032")
- 参数2:匹配结果存储对象(std::smatch类型)
- 参数3:预定义的正则表达式对象
结果处理:
匹配成功返回true,失败返回false
可通过循环遍历matchresults获取所有匹配组
智能指针
C++11标准中的智能指针: C++11标准对智能指针进行了升级,提高了安全性和效率。主要包括shared_ptr、unique_ptr和weak_ptr三种。
shared_ptr: 共享智能指针,多个shared_ptr可以共享同一个对象,最后一个shared_ptr析构时,对象会被自动删除。unique_ptr: 独占智能指针,确保一个对象只有一个unique_ptr拥有,避免重复删除。weak_ptr: 弱引用智能指针,用于解决shared_ptr循环引用问题,不控制对象的生命周期。
头文件名称: memory:这是包含智能指针的头文件,使用智能指针时需要包含此头文件。
unique_ptr
概念: unique_ptr是一种独占指针,它独占内存资源,不支持拷贝和赋值。
特性: 在某一时刻,只能有一个unique_ptr指向一个给定的对象。
#include <iostream>
#include <memory>using namespace std;int main()
{//创建一个指向整数的unique_ptr,并初始化为24。std::unique_ptr<int> p1(new int(24));cout << "*p1=" << *p1 << endl << endl;//指针转移//使用std::move将p1的所有权转移给p2。//此时,p1变为空,p2指向原p1指向的内存。std::unique_ptr<int> p2 = std::move(p1);cout << "*p2=" << *p2 << endl << endl;p2.reset(); // 显式释放内存p1.reset();//尝试释放p1指向的内存(此时p1为空,此操作无效)。std::unique_ptr<int> p3(new int(250));//将p3重新绑定到一个新的动态分配的整数对象,值为666。p3.reset(new int(666)); // 绑定动态对象cout << "*p3=" << *p3 << endl << endl;p3 = nullptrstd::unique_ptr<int> p4(new int(999));//释放p4对内存的控制权,但不释放内存本身,此时p指向原p4管理的内存。int* p = p4.release();cout << "*p=" << *p << endl;cout << "*p4=" << *p4 << endl << endl;delete p;return 0;
}
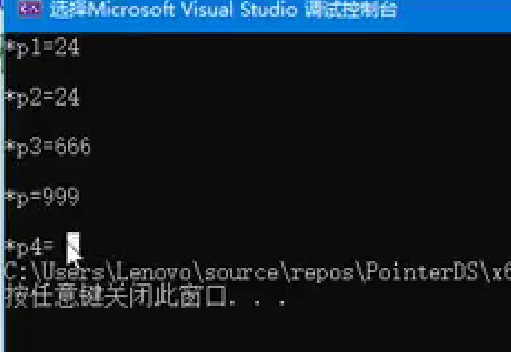
unique_ptr特性总结:
独占内存资源,不支持拷贝和赋值。
使用std::move可以转移所有权。
使用reset可以显式释放内存。
release只释放控制权,不释放内存,需手动delete释放内存。
shared_ptr智能指针
定义: shared_ptr是一种智能指针,允许多个shared_ptr实例共享同一个堆分配对象的内存。
特性:
(1)引用计数: shared_ptr通过引用计数技术记录有多少个shared_ptr共同指向同一个对象。
(2)自动释放: 一旦最后一个指向该对象的shared_ptr被销毁,即对象的引用计数变为零,该对象会自动释放内存。
(3)支持复制与赋值操作: shared_ptr·、支持复制操作,使得多个指针可以共享同一对象。
#include <iostream>
#include <memory>
using namespace std;
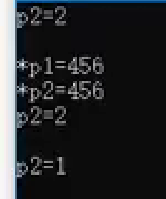
int main(){//创建了一个指向值为456的整数的shared_ptr。shared_ptr<int> pl(new int(456));// 使p2共享p1所指向的对象,此时引用计数为2。shared_ptr<int> p2 = pl;//输出引用计数,结果为2。cout << "p2=" << p2.use_count() << endl << endl;//分别输出p1和p2指向的值,均为456。cout << "*pl=" << *pl << endl;cout << "*p2=" << *p2 << endl;cout << "p2=" << p2.use_count() << endl << endl;//显式释放p1对共享对象的所有权,引用计数减1。pl.reset();//再次输出p2的引用计数,结果为1。cout << "p2=" << p2.use_count() << endl << endl;return 0;
}
make_shared函数
定义: make_shared函数是最安全的分配和使用动态内存的方法。
特性:
一次性分配: make_shared在动态内存中分配一个对象并返回指向该对象的shared_ptr,减少了内存分配失败的风险。
效率: 相比先使用new分配内存再创建shared_ptr,make_shared可以减少一次内存分配操作,提高效率。
waek_ptr
定义: weak_ptr是一种智能指针,配合shared_ptr而引入,用于协助shared_ptr的工作。
构造与析构: weak_ptr的构造和析构不会引起引用计数的增加或减少。
资源所有权: weak_ptr并不拥有资源的所有权,因此不能直接使用资源。
获取所有权: 可以从一个weak_ptr构造一个shared_ptr,以取得共享资源的所有权。
#include <iostream>
#include <memory>
using namespace std;
int main()
{shared_ptr<int> p1(new int(300));//p2作为p1的共享指针shared_ptr<int> p2 = p1;weak_ptr<int> wp = p1;//输出wp的引用计数,以及p1和p2指向的值。cout << "count=" << wp.use_count() << endl << endl;cout << "*p1=" << *p1 << endl;cout << "*p2=" << *p2 << endl;cout << endl;return 0;
}
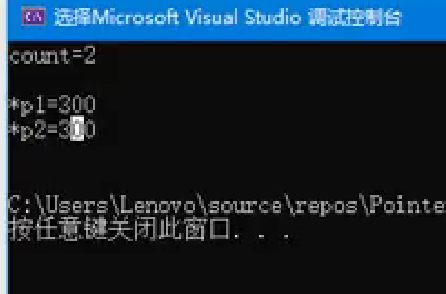
weak_ptr不能直接访问资源,必须通过构造shared_ptr来访问。
weak_ptr的存在不会影响shared_ptr的引用计数。
nullptr&constexpr
nullptr关键字
出现目的: nullptr关键字的出现是为了代替NULL,以避免二义性。
类型: nullptr的类型是std::nullptr_t,它能够隐式地转换为任何指针类型和成员指针类型。
比较操作: nullptr可以与指针进行相等或不等的比较。
constexpr关键字
作用: constexpr关键字用于定义常量表达式,要求在编译阶段就能确定其值。
应用场景: 常用于静态数组大小定义、容器大小指定等需要在编译期确定大小的场景。
#include <iostream>
using namespace std;int main(){int x = 400;int y = 2000;cout << "x=" << x << endl;constexpr int* p = &x;*p = 129;cout << "x=" << x << endl;// p = &y; 错误return 0;
}
constexpr指针指向的变量值在编译期确定,且指针本身为常量,不可修改其指向。
共享内存
核心概念:共享内存是进程间通信(IPC)的一种方式,允许多个进程访问同一块内存区域。
实现原理:通过将内存区域映射到不同进程的地址空间实现数据共享。
服务端程序:
(1)创建共享内存区域:使用CreateFileMapping函数创建共享内存
(2)内存映射:通过MapViewOfFile将共享内存映射到当前进程地址空间
(3)写入数据:使用strcpy将数据拷贝到共享内存区域
#include <iostream>
#include <Windows.h>
using namespace std;
#define BUF_SIZE 1024
int main()
{// 共享数据信息char szBuffer[] = "零声教育C/C++企业级项目实战课程";// 创建共享文件句柄HANDLE hmFile = CreateFileMapping(INVALID_HANDLE_VALUE, NULL,PAGE_READWRITE, 0, BUF_SIZE, L"LSEDU");// 映射LPVOID lpBase = MapViewOfFile(hmFile, FILE_MAP_ALL_ACCESS, 0, 0, BUF_SIZE);// 将数据拷贝到共享内存strcpy((char*)lpBase, szBuffer);cout << "\n服务器程序端:" << (char*)lpBase << endl << endl;// 线程挂起等待其他线程读取数据Sleep(20000);// 删除文件映射UnmapViewOfFile(lpBase);// 关闭内存映射文件对象句柄CloseHandle(hmFile);return 0;
}
需要定义缓冲区大小#define BUF_SIZE 1024
共享内存名称(如"LSEDU")必须唯一且客户端和服务端保持一致
操作完成后需要解除映射和关闭句柄
客户端程序:
(1)打开共享内存:使用OpenFileMapping打开已存在的共享内存
(2)内存映射:同样使用MapViewOfFile进行映射
(3)读取数据:从映射的内存区域读取数据
#include <iostream>
#include <Windows.h>
using namespace std;#define BUF_SIZE 1024int main(){HANDLE hmfile = OpenFileMapping(FILE_MAP_ALL_ACCESS, NULL, L"LSEDU");if (hmfile){LPVOID lpBase = MapViewOfFile(hmfile, FILE_MAP_ALL_ACCESS, 0, 0, 0);char szBuffer[BUF_SIZE] = {0};strcpy(szBuffer, (char*)lpBase);cout << "\n客户端程序端:" << szBuffer;UnmapViewOfFile(lpBase);CloseHandle(hmfile);}else{printf("\n打开共享内存失败,请检查操作。\n\n");}
}std::unordered_set
存储结构:采用哈希表方式实现的数据存储结构
排序特性:在插入元素时不会自动排序,与std::set形成主要区别
头文件:需要包含#include <unordered_set>
#include<iostream>
#include<string>
#include<set>
#include<unordered_set>
int main() {std::unordered_set<int> un_set;un_set.insert(23);un_set.insert(33);un_set.insert(12);un_set.insert(78);un_set.insert(99);std::cout << "\nunordered_set:" << std::endl;for(auto it : un_set) {std::cout << it << std::endl;}std::set<int> st;st.insert(23);st.insert(33);st.insert(12); st.insert(78);st.insert(99);std::cout << "\nunordered_set:" << std::endl;for(auto it : un_set) {std::cout << it << std::endl;}return 0;
}
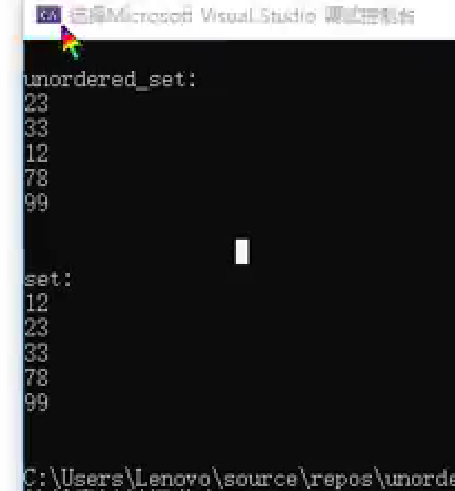
主要区别:
排序行为:std::set会自动对元素进行排序,而std::unordered_set不会
实现方式:set通常基于红黑树实现,unordered_set基于哈希表实现
性能差异:unordered_set的插入和查找操作平均时间复杂度为O(1)
关联容器 unordered_map
内部结构: 关联容器unordered_map内部采用的是哈希表结构。
特性:
关联性: 通过关键字(key)来检索对应的值,而不是通过绝对地址。
无序性: 使用哈希表存储,内部元素是无序的。
唯一性: 不存在两个键(key)相同的情况。
快速检索: 由于采用哈希表结构,具备快速检索的功能。
动态内存管理: 使用内存管理模型来动态管理所需的内存空间。
#include <iostream>
#include <string>
#include <unordered_map>
using namespace std;typedef unordered_map<string, string> strmap;strmap merge(strmap str1, strmap str2) {strmap temp(str1);temp.insert(str2.begin(), str2.end());return temp;
}int main() {strmap s1;strmap s2{{"apple", "red"}, {"lemon", "yellow"}};strmap s3{{"orange", "orange"}, {"strawberry", "red"}};strmap s4(s2); // 复制初始化strmap s5(merge(s3, s4)); // 移动初始化操作strmap s6(s5.begin(), s5.end()); // 范围初始化操作cout << "\n输出s6容器:\n";for (auto& x : s6) {cout << "" << x.first << ":" << x.second;}cout << endl;return 0;
}

function函数对象
本质定义:函数对象是指定义了operator()操作符的对象,通过类实现函数调用行为。
语法
class Fun {
public:void operator()() {// 操作语句}
};
核心特征:函数对象本质上是对象,但可以像函数一样被调用。
函数对象优势
状态保持:相比普通函数,函数对象可以拥有成员变量来保存状态。
执行效率:执行速度比函数指针更快,编译器可以进行更好的优化。
类型特性:每个函数对象都有具体类型,可作为模板参数传递,容器类型也会因函数对象类型不同而变化。
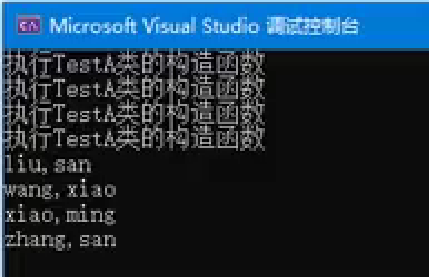
class TestA {
public:TestA(string lname, string fname) : _fname(fname), _lname(lname) {cout << "执行TestA类的构造函数\n";}string firstname() const { return _fname; }string lastname() const { return _lname; }
private:string _fname = nullptr;string _lname = nullptr;
};class TestB {
public:bool operator()(const TestA& t1, const TestA& t2) const {return t1.lastname() < t2.lastname() || (t1.lastname() == t2.lastname() && t1.firstname() < t2.firstname());}
};int main() {//创建了一个 set 集合,其中元素的类型是 TestA,排序规则由 TestB 类决定。set<TestA, TestB> sett;TestA t1("liu", "san");TestA t2("xiao", "ming");TestA t3("zhang", "san");TestA t4("wang", "xiao");sett.insert(t1);sett.insert(t2);sett.insert(t3);sett.insert(t4);for(auto i : sett) {cout << i.lastname() << ", " << i.firstname() << endl;}return 0;
}
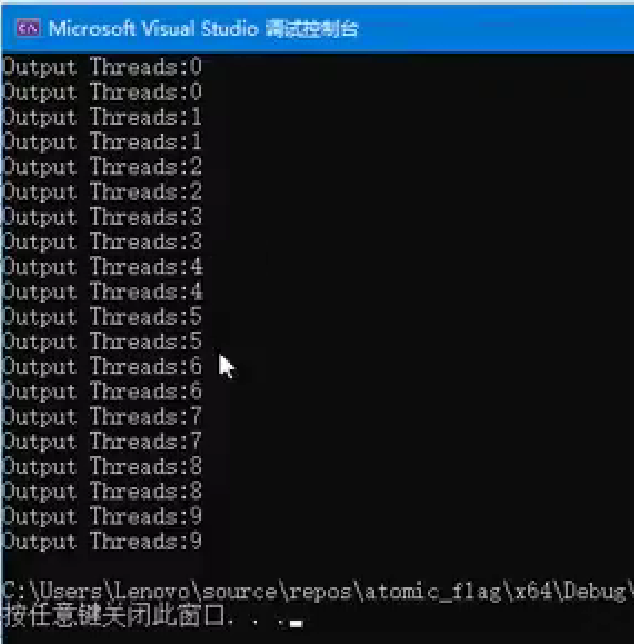
atomic_flag应用
std::atomic_flag是原子布尔类型,不同于所有std::atomic的特化
保证是免锁(lock-free)实现
不提供加载(load)或存储(store)操作
#include <iostream>
#include <atomic>
#include <vector>
#include <thread>// ATOMIC_FLAG_INIT->定义能以语句用于初始化操作,清除状态的初始化器
std::atomic_flag lock = ATOMIC_FLAG_INIT; // void FuncAt(int args){for (int i = 0; i < 10; i++){while (lock.test_and_set(std::memory_order_acquire)); // 获得锁std::cout << "Output Threads:" << i << std::endl;lock.clear(std::memory_order_release); // 释放锁}
}int main(){std::vector<std::thread> vct; // 创建一个线程向量for (int i = 0; i < 2; i++){vct.emplace_back(FuncAt, i); // 创建并启动线程,每个线程执行 FuncAt 函数}for (auto& t : vct){t.join(); // 等待所有线程完成}return 0;
}
condition_variable
同步机制:C++11标准中通过condition_variable实现多线程间的同步操作
阻塞机制:当条件不满足时,相关线程会被阻塞,直到其他线程修改条件后才会被唤醒
#include <iostream>
#include <thread>
#include <condition_variable>
#include <mutex>// 全局互斥锁,用于保护共享数据
std::mutex mx;
// 全局条件变量,用于线程间的同步
std::condition_variable scv;
// 全局标志位,用于指示线程是否可以继续执行
bool ready = false;// 打印线程ID的函数
void PrintID(int id){// 获取互斥锁std::unique_lock<std::mutex> lock(mx);// 如果标志位为false,则等待while (!ready){scv.wait(lock); // 当前线程被阻塞,当全局标志位变为true之后,才唤醒}std::cout << "Threads: " << id << std::endl;
}// 设置全局标志位并唤醒所有等待线程的函数
void RunFunc(){// 获取互斥锁std::unique_lock<std::mutex> lock(mx);// 设置全局标志位为trueready = true;// 唤醒所有等待线程scv.notify_all();
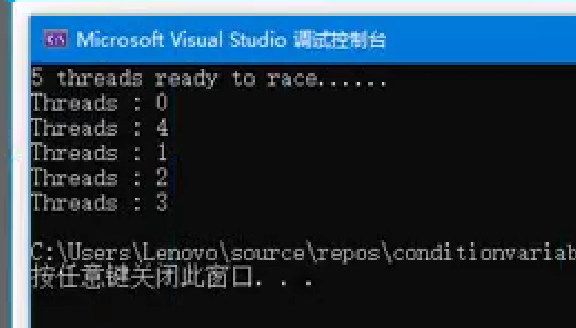
}int main(){// 创建5个线程std::thread thrs[5];for (int i = 0; i < 5; i++){// 启动线程,执行PrintID函数thrs[i] = std::thread(PrintID, i);}std::cout << "5 threads ready to race......\n";// 调用RunFunc函数,设置标志位并唤醒所有线程RunFunc();// 等待所有线程完成for (auto& t : thrs){t.join();}return 0;
}
join与detach的区别
join特性:
(1)原始线程会等待新线程执行完毕后再销毁线程对象
(2)适用于新线程使用共享变量的情况,避免产生异常
(3)可能造成性能下降(需要等待)
detach特性:
(1)新线程与原始线程分离独立运行
(2)适用于确定没有共享变量的情况
(3)若原始线程先结束可能造成未定义行为
选择原则:
(1)不确定时使用join保证安全
(2)确定无共享资源时使用detach提高性能
异常处理Exception
异常类继承体系:C++标准库中的异常类都从exception基类派生,包括bad_typeid、bad_cast、bad_alloc和ios_base::failure等。
自动抛出机制:即使程序中没有显式throw语句,遇到特定异常时系统也会自动抛出这些异常类的实例。
异常信息获取:所有异常类都包含what()成员函数,用于返回描述异常信息的字符串。
头文件依赖:使用这些异常类需要包含<stdexcept>头文件。
#include <iostream>
#include <stdexcept>
using namespace std;//基类TestA声明虚函数Func()
class TestA {
public:virtual void Func() {// Base class implementation}
};//派生类TestB公有继承TestA并实现disp()方法
class TestB : public TestA {
public:void disp() {cout<<"TestB OK."<<endl;}
};void dispObject(TestB& t) {try {TestB& tb = dynamic_cast<TestB&>(t);//在此转换若不安全,会抛出bad_cast异常tb.disp();} catch (bad_cast& e) {cerr << e.what() << endl;}
}int main() {TestB objb;dispObject(objb);return 0;
}
当传入TestA对象时:捕获bad_cast异常并输出错误信息
当传入TestB对象时:正常执行disp()方法输出"TestB OK."
std::thread多线程
#include <iostream>
#include <thread>
using namespace std;void ThreadFunc1() {cout << "ThreadFunc1()--A" << endl;this_thread::sleep_for(chrono::seconds(2));cout << "ThreadFunc2()--B" << endl;
}void ThreadFunc2(int args, string sp) {cout << "ThreadFunc1()--A" << endl;this_thread::sleep_for(chrono::seconds(7));cout << "ThreadFunc2()--B" << endl;
}int main() {//创建线程对象thread ths1(ThreadFunc1);thread ths2(ThreadFunc2, 10, "LS");//join():等待线程执行完成,示例中输出"join"标识ths1.join();cout << "join" << endl;//detach():分离线程使其独立运行,示例中输出"detach"标识ths2.detach();cout << "detach" << endl;
}
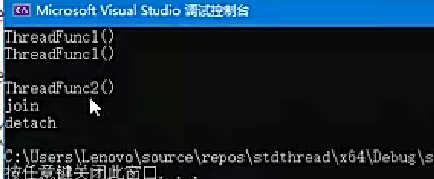
执行流程:
线程1输出"A"后休眠2秒
线程2输出"A"后休眠7秒
线程1完成输出"B"后执行join
线程2分离执行detach