深入解析与解决方案:处理Elasticsearch中all found copies are either stale or corrupt未分配分片问题
目录
引言
1 问题诊断深入分析
1.1 错误含义深度解析
1.2 获取详细的诊断信息
2 解决方案选择与决策流程
2.1 可用选项全面对比
2.2 推荐处理流程与决策树
3 具体操作步骤详解
3.1 优先尝试 - 分配最新副本(最低风险)
3.2 中等风险方案 - 分配过时主分片
3.3 最后手段 - 分配空主分片
4 操作后验证与数据恢复
4.1 分片状态监控
4.2 数据完整性验证
5 预防措施
5.1 集群配置优化
5.2 监控与告警体系
5.3 备份策略设计
6 高级故障排查技巧
6.1 分片数据修复工具
6.2 深入分析translog
6.3 集群一致性检查
7 结语
引言
在Elasticsearch集群运维过程中,分片未分配是一个常见但棘手的问题。其中,"cannot allocate because all found copies of the shard are either stale or corrupt"这一错误信息表明集群检测到所有可用分片副本都存在数据问题。本文将深入分析这一问题的本质,提供详细的诊断方法,并给出从低风险到高风险的完整解决方案以及预防措施。
1 问题诊断深入分析
1.1 错误含义深度解析
"all found copies are either stale or corrupt"错误表明Elasticsearch无法为特定分片找到可用的数据副本进行分配。我们需要深入理解其中的两个关键术语:
stale(过时)副本:
- 指副本数据不是最新的,可能缺少最近的变更
- 通常发生在网络分区或节点长时间离线后重新加入集群时
- 过时副本可能缺少部分事务日志(translog)中的操作
- 在分布式系统中,根据CAP理论,这属于一致性(consistency)问题
corrupt(损坏)副本:
- 指物理存储的数据已损坏,无法正常读取
- 可能由磁盘故障、文件系统错误或ES进程异常终止导致
- 损坏可能发生在Lucene索引文件或translog文件中
- 通常伴随I/O错误或校验和失败的日志记录
根本原因分析:
- 集群无法找到一个可用的、数据完整的副本作为数据源
- 可能由于多个节点同时故障导致复制组(replica set)完全失效
- 长时间GC停顿可能导致多个副本被标记为stale
- 磁盘故障可能导致多个副本同时corrupt
1.2 获取详细的诊断信息
- 使用_cluster/allocation/explainAPI获取深入诊断信息:
curl -u 'es_user:es_user_passwd' -X GET "集群节点ip:9200/_cluster/allocation/explain?pretty" -H "Content-Type: application/json" -d'
{"index": "index_name","shard": 分片ID,"primary": true
}'- 响应中需要特别关注的字段:
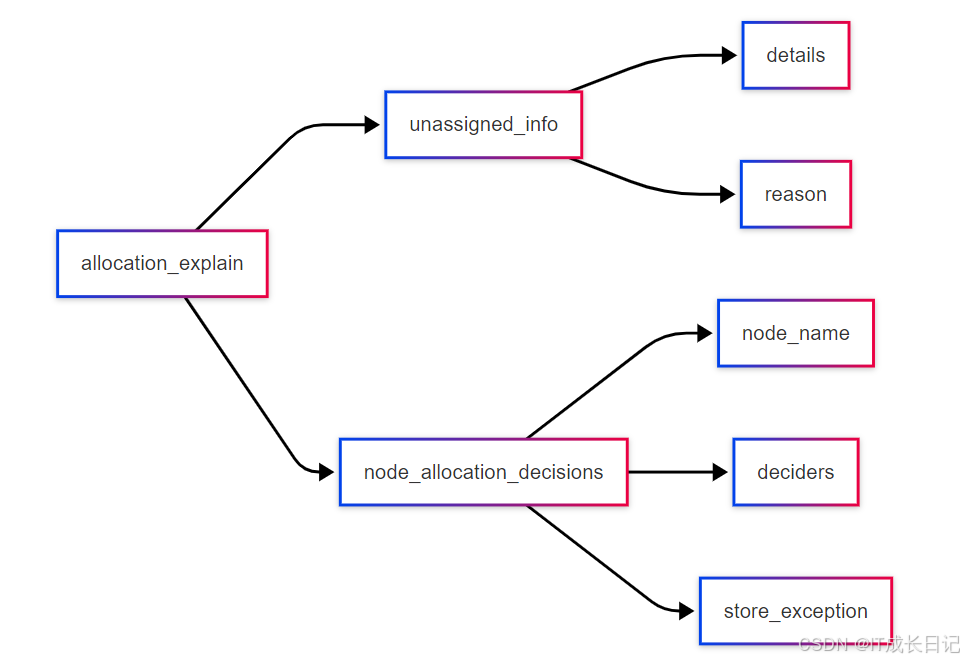
关键字段解释:
- unassigned_info.details:提供具体损坏/过时的技术细节
- node_allocation_decisions:展示各节点的分配决策过程
- store_exception:如果有数据损坏,这里会包含具体的存储异常信息
- deciders:显示影响分配决策的各种因素和权重
2 解决方案选择与决策流程
2.1 可用选项全面对比
| 方案 | 适用条件 | 数据风险 | 恢复速度 | 后续影响 | 命令 |
| 从最新副本恢复 | 有部分可用副本 | 无风险 | 快 | 无 | allocate_replica |
| 使用旧数据重建 | 有stale副本可用 | 可能丢失最新数据 | 中等 | 需重建索引 | allocate_stale_primary |
| 完全重建空分片 | 所有副本不可用 | 完全丢失该分片数据 | 快 | 需全量重建 | allocate_empty_primary |
| 从快照恢复 | 有可用快照 | 无风险 | 慢 | 需暂停写入 | restore_snapshot |
2.2 推荐处理流程与决策树
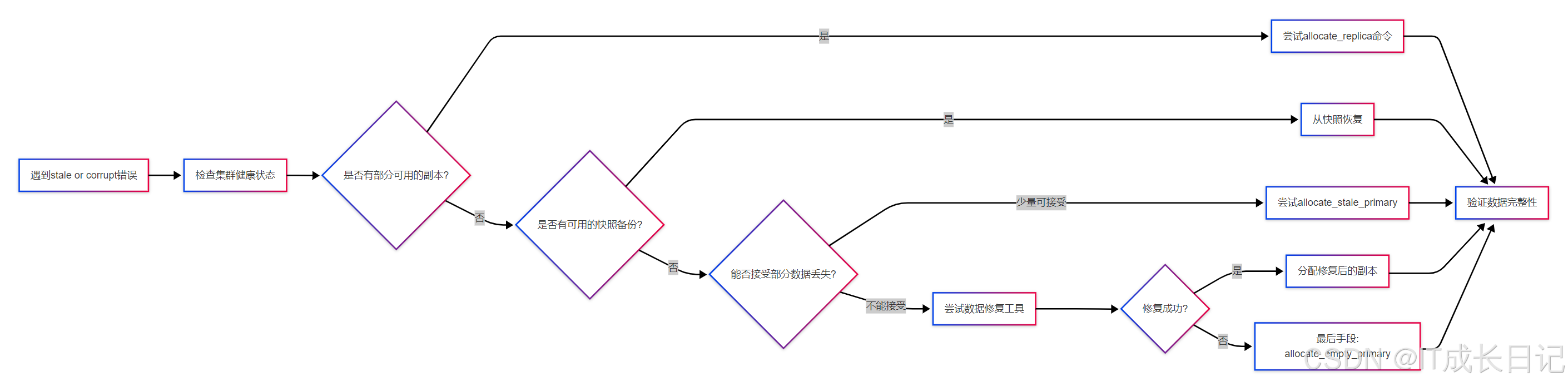
流程说明:
- 首先确认集群整体状态,排除全局性问题
- 检查是否有部分副本仍可用,优先使用最低风险方案
- 次优选择是从快照恢复,虽然耗时但能保证数据完整
- 在无快照情况下,评估业务对数据丢失的容忍度
- 尝试使用Elasticsearch工具修复损坏数据(如lucene工具)
- 最后才考虑创建空分片,这会完全丢失该分片数据
3 具体操作步骤详解
3.1 优先尝试 - 分配最新副本(最低风险)
- 步骤1:全面检查分片状态
curl -u 'es_user:es_user_passwd' -X GET "集群节点ip:9200/_cat/shards?v&h=index,shard,prirep,state,node,unassigned.reason,store" | grep -v STARTED关键列解释:
- store:显示分片存储状态,可能包含"corrupt"标记
- unassigned.reason:具体未分配原因
- 步骤2:识别最佳候选节点
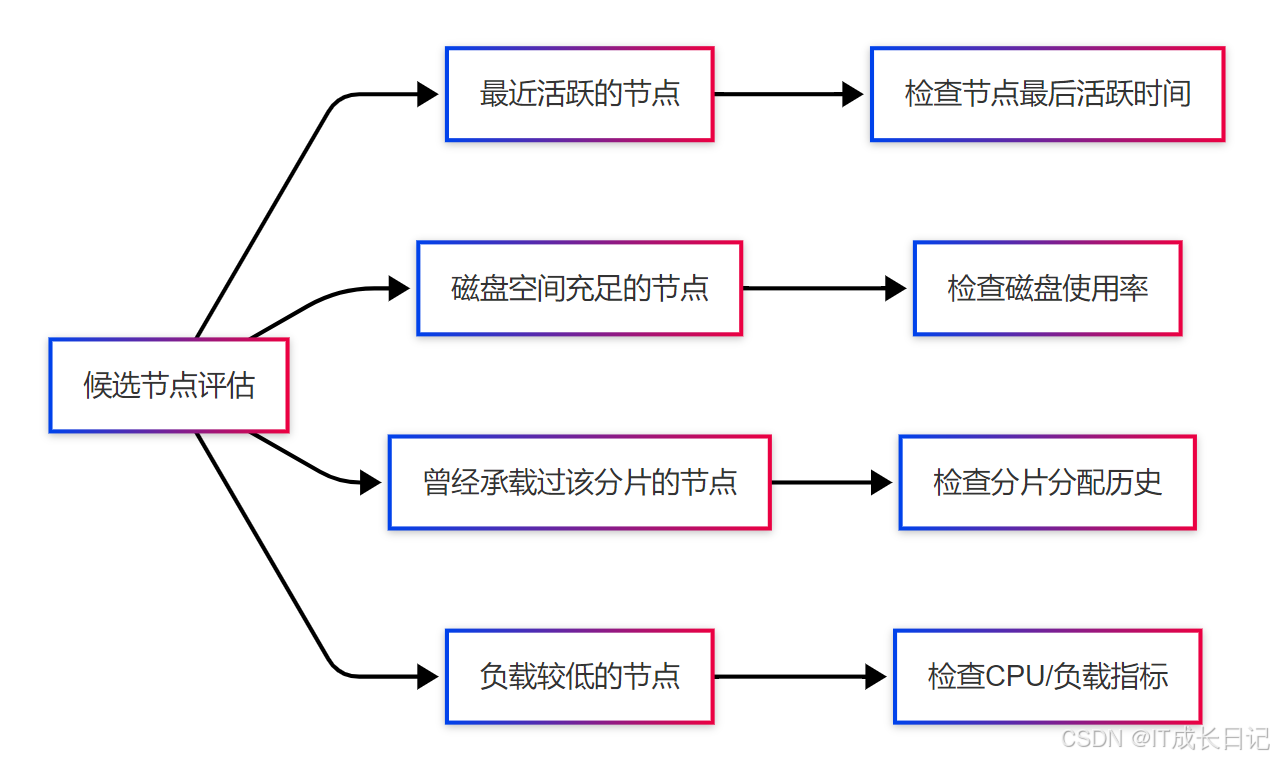
- 步骤3:执行副本分配
curl -u 'es_user:es_user_passwd' -X POST "集群节点ip:9200/_cluster/reroute?retry_failed=true&pretty" -H "Content-Type: application/json" -d'
{"commands": [{"allocate_replica": {"index": "index_name","shard": 0,"node": "集群节点"}}]
}'参数优化建议:
- 添加"retry_failed": true让集群自动重试失败操作
- 对于大分片,可设置"timeout": "1h"避免超时
3.2 中等风险方案 - 分配过时主分片
适用场景:
- 确认存在stale副本但无最新副本
- 可以接受丢失最近部分数据更新
操作步骤:
- 确认可以接受数据丢失:
curl -u 'es_user:es_user_passwd' -X GET "集群节点ip:9200/index_name/_stats?level=shards" | jq '.indices[].shards."0"'- 执行stale主分片分配:
curl -u 'es_user:es_user_passwd' -X POST "集群节点ip:9200/_cluster/reroute?pretty" -H "Content-Type: application/json" -d'
{"commands": [{"allocate_stale_primary": {"index": "index_name","shard": 未分配分片id,"node": "集群节点","accept_data_loss": true}}]
}'- 数据同步过程
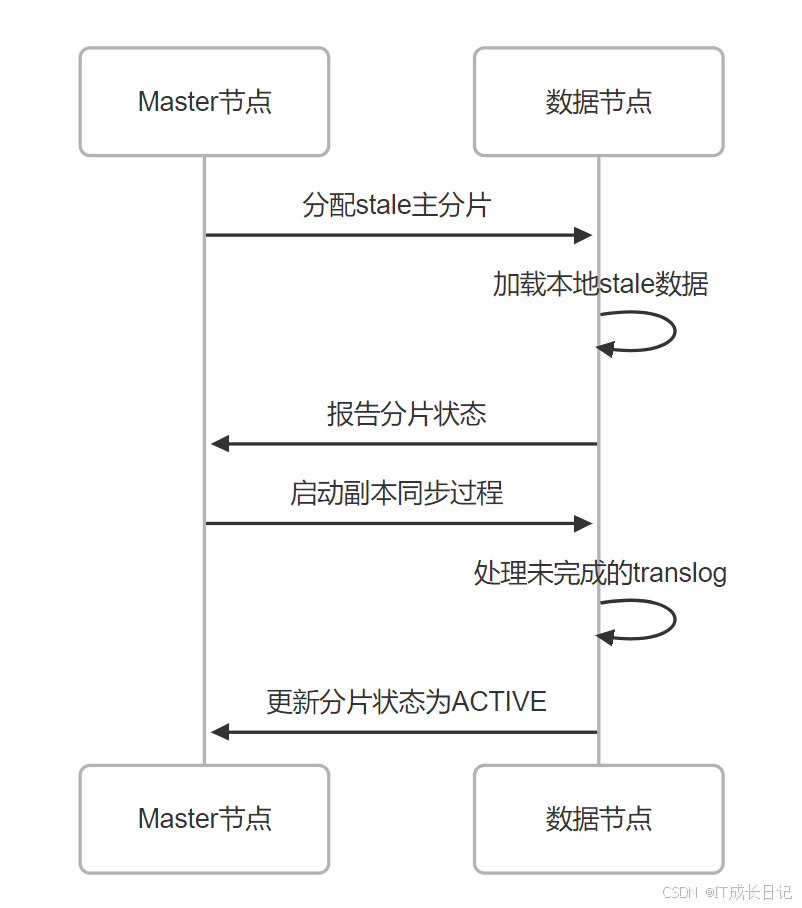
3.3 最后手段 - 分配空主分片
风险警告:
- 将完全丢失该分片所有数据
- 可能导致索引不一致
- 应该作为最后选择
执行步骤:
- 确认所有副本确实不可用:
curl -u 'es_user:es_user_passwd' -X GET "集群节点ip:9200/_cluster/allocation/explain?pretty" -H "Content-Type: application/json" -d'
{"index": "index_name","shard": 未分配分片id,"primary": true
}' | grep -e "corrupt" -e "stale"- 创建空主分片:
curl -u 'es_user:es_user_passwd' -X POST "集群节点ip:9200/_cluster/reroute?pretty" -H "Content-Type: application/json" -d'
{"commands": [{"allocate_empty_primary": {"index": "index_name","shard": 未分配分片id,"node": "集群节点","accept_data_loss": true}}]
}'
- 重建索引数据:
- 如果是时间序列数据,可能从其他系统重新导入
- 如果是业务数据,需要从源系统重新索引
4 操作后验证与数据恢复
4.1 分片状态监控
- 实时监控命令:
watch -n 1 'curl -u 'es_user:es_user_passwd' -s "集群节点ip:9200/_cat/shards/index_name?v&h=index,shard,prirep,state,node,docs|sort -k2,2n"'4.2 数据完整性验证
- 文档数量比对:
# 获取历史文档数(如果有监控数据)
# 当前文档数
curl -u 'es_user:es_user_passwd' -s "集群节点ip:9200/index_name/_count?pretty" | jq '.count'# 各分片文档数分布
curl -u 'es_user:es_user_passwd' -s "集群节点ip:9200/index_name/_stats/docs" | jq '.indices[].primaries.docs.count'- 字段统计验证:
curl -u 'es_user:es_user_passwd' -X POST "集群节点ip:9200/index_name/_field_stats?fields=timestamp,user_id&level=cluster"- 抽样数据检查:
curl -u 'es_user:es_user_passwd' -X GET "集群节点ip:9200/index_name/_search?size=100&q=*:*&sort=timestamp:desc"5 预防措施
5.1 集群配置优化
- 索引设置建议:
{"index": {"number_of_replicas": 2,"unassigned.node_left.delayed_timeout": "10m","recovery.retention_lease.period": "30m","translog.durability": "async","translog.sync_interval": "10s"}
}- 分片分配感知配置:
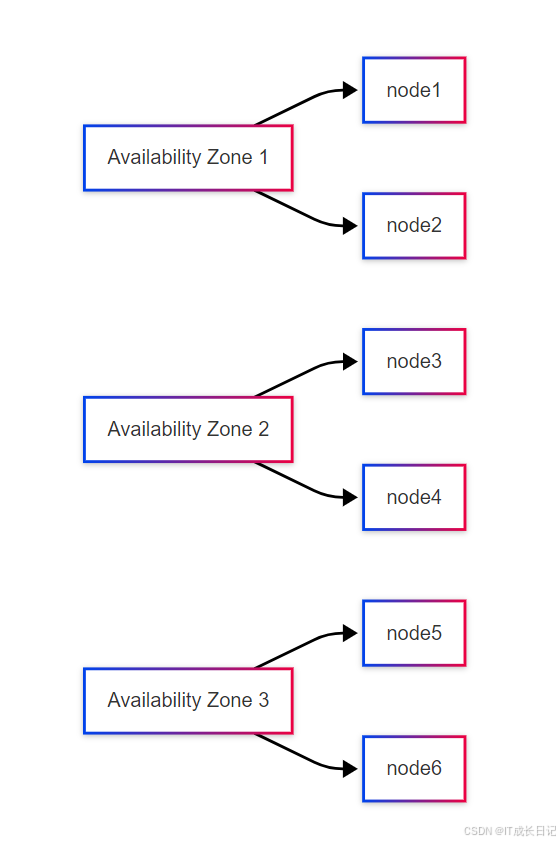
- 配置命令:
curl -u 'es_user:es_user_passwd' -X PUT "集群节点ip:9200/_cluster/settings" -H "Content-Type: application/json" -d'
{"persistent": {"cluster.routing.allocation.awareness.attributes": "az","cluster.routing.allocation.awareness.force.az.values": "zone1,zone2,zone3"}
}'5.2 监控与告警体系
关键监控指标:
- cluster_health_status: 红/黄/绿状态
- unassigned_shards: 未分配分片数
- pending_tasks: 挂起的集群任务
- data_nodes: 存活数据节点数
推荐告警规则:
- 任何UNASSIGNED分片持续5分钟以上
- 集群状态为RED超过1分钟
- 节点离开集群超过3分钟未恢复
- 磁盘使用率超过85%
5.3 备份策略设计
- 多级备份架构:
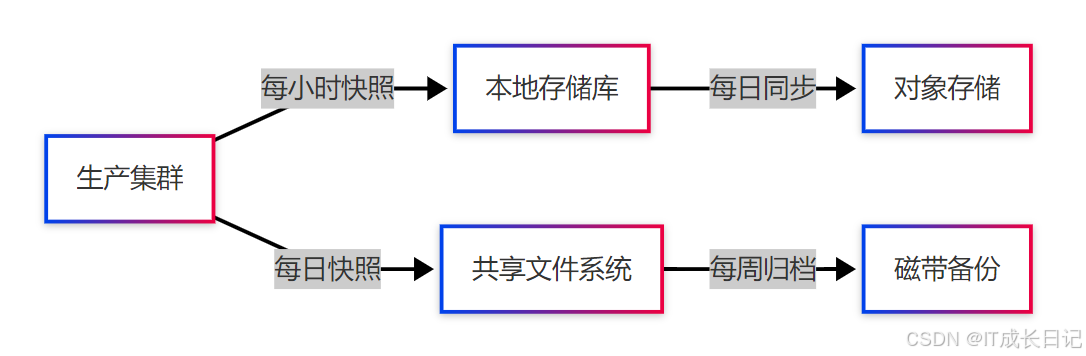
- 自动化快照策略:
# 创建快照策略
curl -u 'es_user:es_user_passwd' -X PUT "集群节点ip:9200/_slm/policy/daily-snapshots" -H "Content-Type: application/json" -d'
{"schedule": "0 30 2 * * ?", "name": "<daily-snap-{now/d}>","repository": "my_backup_repo","config": {"indices": ["*"],"ignore_unavailable": true,"include_global_state": false},"retention": {"expire_after": "30d","min_count": 5,"max_count": 50}
}'6 高级故障排查技巧
6.1 分片数据修复工具
- Lucene索引检查工具:
# 在ES节点上执行
sudo -u elasticsearch /usr/share/elasticsearch/bin/elasticsearch-shard \-d /var/lib/elasticsearch/nodes/0/indices/your_index/0/index \-s /tmp/shard_recovery- 修复流程:
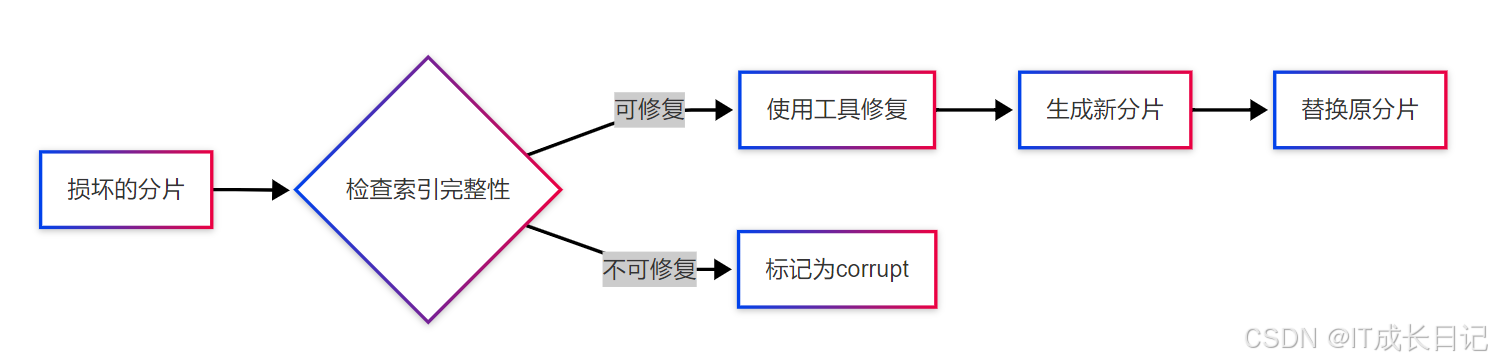
6.2 深入分析translog
- translog操作检查:
curl -u 'es_user:es_user_passwd' -X GET "集群节点ip:9200/your_index/_stats/translog?pretty"关键指标解释:
- uncommitted_operations: 未提交到Lucene的操作数
- size_in_bytes: translog当前大小
- earliest_last_modified_age: 最旧操作存在时间
6.3 集群一致性检查
- 使用_cat/recovery API:
curl -u 'es_user:es_user_passwd' -s "集群节点ip:9200/_cat/recovery/your_index?v&h=index,shard,time,type,stage,source_node,target_node,files_percent" | sort -k3,3恢复过程监控指标:
- files_percent: 文件复制进度
- translog_percent: translog恢复进度
- total_time: 恢复已耗时
7 结语
处理"all found copies are either stale or corrupt"错误需要谨慎权衡数据完整性和服务可用性。记住,预防胜于治疗,健全的监控体系、合理的副本策略和可靠的备份方案才是避免此类问题的根本之道。
最终建议处理原则:
- 从最低风险方案开始尝试
- 每次操作后充分验证
- 记录所有操作步骤和结果
- 事后进行根本原因分析
- 根据教训优化集群配置