主流消息队列对比
文章目录
- 🚀 主流消息队列面试题精选 | 技术面拿下MQ,就靠这一篇!
- 🔥 Kafka篇
- Q1: 详细分析Kafka的高吞吐量是如何实现的?
- 💡 标准答案
- 1️⃣ **顺序写入与零拷贝**
- 2️⃣ **分区并行处理**
- 3️⃣ **批量处理与压缩**
- 4️⃣ **页缓存与预读取**
- 🔍 面试官视角
- Q2: Kafka的ISR副本同步机制是什么?它如何保证数据一致性?
- 💡 标准答案
- 1️⃣ **ISR机制工作原理**
- 2️⃣ **数据一致性保证**
- 3️⃣ **一致性级别**
- 4️⃣ **ISR动态调整**
- 🔍 面试官视角
- 🔥 RocketMQ篇
- Q1: RocketMQ的事务消息是如何实现的?它解决了什么问题?
- 💡 标准答案
- 1️⃣ **事务消息实现原理**
- 2️⃣ **解决的问题**
- 3️⃣ **应用场景**
- 🔍 面试官视角
- Q2: RocketMQ如何保证顺序消息的可靠投递?
- 💡 标准答案
- 1️⃣ **顺序消息类型**
- 2️⃣ **顺序消息实现原理**
- 3️⃣ **顺序消息的可靠性保障**
- 4️⃣ **适用场景**
- 🔍 面试官视角
- 🔥 RabbitMQ篇
- Q1: 详细解释RabbitMQ的Exchange类型及其路由机制?
- 💡 标准答案
- 1️⃣ **Direct Exchange(直接交换机)**
- 2️⃣ **Fanout Exchange(扇出交换机)**
- 3️⃣ **Topic Exchange(主题交换机)**
- 4️⃣ **Headers Exchange(头交换机)**
- 🔍 面试官视角
- Q2: RabbitMQ的死信队列和延迟队列是什么?如何实现?
- 💡 标准答案
- 1️⃣ **死信队列(Dead Letter Queue)**
- 2️⃣ **延迟队列(Delayed Queue)**
- 3️⃣ **死信队列与延迟队列的应用**
- 🔍 面试官视角
- 🔥 Pulsar篇
- Q1: Pulsar的分层存储架构有什么优势?与传统消息队列有何不同?
- 💡 标准答案
- 1️⃣ **Pulsar的分层存储架构**
- 2️⃣ **与传统消息队列的区别**
- 3️⃣ **分层存储的优势**
- 🔍 面试官视角
- Q2: Pulsar的多租户支持有哪些特性?如何实现资源隔离?
- 💡 标准答案
- 1️⃣ **多租户架构**
- 2️⃣ **资源隔离机制**
- 3️⃣ **存储隔离**
- 4️⃣ **网络隔离**
- 5️⃣ **多租户最佳实践**
- 🔍 面试官视角
- 📚 总结
🚀 主流消息队列面试题精选 | 技术面拿下MQ,就靠这一篇!
📢 前言:各位技术小伙伴们好!今天我要带大家深入剖析主流消息队列的核心知识点,并以面试题的形式呈现。这些题目都是我从数百场技术面试中精选出来的高频问题,掌握它们,让你在面试中脱颖而出!
🔥 Kafka篇
Q1: 详细分析Kafka的高吞吐量是如何实现的?
👉 点击查看答案💡 标准答案
Kafka的高吞吐量主要通过以下几个核心设计实现:
1️⃣ 顺序写入与零拷贝
- 顺序写入:Kafka将消息追加到分区末尾,利用了磁盘的顺序读写特性,比随机访问快数百倍
- 零拷贝:使用
sendfile系统调用,数据直接从磁盘文件复制到网卡缓冲区,避免了用户态与内核态的多次切换
// 传统数据复制流程
public void traditionalCopy(FileInputStream in, OutputStream out) throws IOException {byte[] buffer = new byte[4096];int bytesRead;while ((bytesRead = in.read(buffer)) != -1) {out.write(buffer, 0, bytesRead);}
}
// 经过4次上下文切换和4次数据复制// 零拷贝(Java NIO实现)
public void zeroCopy(FileChannel inChannel, WritableByteChannel outChannel) throws IOException {inChannel.transferTo(0, inChannel.size(), outChannel);
}
// 减少为2次上下文切换和1次数据复制
2️⃣ 分区并行处理
- 主题被分为多个分区,分布在不同的Broker上
- 生产者和消费者可以并行处理不同分区的数据
- 分区数量可以超过Broker数量,实现更细粒度的并行
// 配置示例:创建具有多个分区的主题
const topicConfig = {'num.partitions': 32, // 分区数量'replication.factor': 3, // 副本因子'min.insync.replicas': 2 // 最小同步副本数
};
3️⃣ 批量处理与压缩
- 批量发送:生产者会将多条消息打包成一个批次发送,减少网络开销
- 批量消费:消费者一次获取多条消息,提高处理效率
- 数据压缩:支持Gzip、Snappy、LZ4等压缩算法,减少网络传输和存储开销
// 生产者批处理配置
Properties props = new Properties();
props.put("bootstrap.servers", "broker1:9092,broker2:9092");
props.put("batch.size", 16384); // 批次大小,单位字节
props.put("linger.ms", 5); // 等待时间,即使批次未满
props.put("compression.type", "lz4"); // 压缩算法
4️⃣ 页缓存与预读取
- 利用操作系统的页缓存,避免JVM GC的影响
- 顺序读取时,操作系统会自动预读取数据到内存
- 消费者经常能直接从内存读取数据,而非磁盘
🔍 面试官视角
优秀的回答不仅要列举Kafka高吞吐量的实现机制,还应该:
- 解释每种机制的工作原理和优化点
- 能够结合代码或配置示例说明如何利用这些特性
- 讨论这些机制在不同场景下的权衡
- 了解这些优化带来的潜在问题和解决方案
Q2: Kafka的ISR副本同步机制是什么?它如何保证数据一致性?
👉 点击查看答案💡 标准答案
ISR(In-Sync Replicas)是Kafka保证数据一致性的核心机制,它动态维护一组与Leader副本保持同步的副本列表。
1️⃣ ISR机制工作原理
- 定义:ISR是Leader副本和所有与Leader保持"同步"的Follower副本的集合
- 同步标准:Follower副本必须满足两个条件才能在ISR中:
- 与Zookeeper保持会话活跃(心跳正常)
- 在
replica.lag.time.max.ms时间内向Leader拉取过消息(默认10秒)
// Kafka配置示例
properties.put("min.insync.replicas", "2"); // 最小ISR数量
properties.put("replica.lag.time.max.ms", "10000"); // Follower落后Leader的最大时间
2️⃣ 数据一致性保证
- HW(High Watermark):ISR中所有副本都已复制的位置,消费者只能看到HW之前的消息
- LEO(Log End Offset):每个副本的日志末端位置
- Leader选举:当Leader宕机时,只有ISR中的副本才有资格被选为新Leader
分区日志示意图:Leader: m1 m2 m3 m4 m5 m6 m7 m8 <- LEO(8)|vHW(5)Follower1: m1 m2 m3 m4 m5 m6 <- LEO(6)
Follower2: m1 m2 m3 m4 m5 <- LEO(5)消费者只能看到m1-m5的消息,m6-m8对消费者不可见
3️⃣ 一致性级别
Kafka提供三种一致性级别,通过acks参数控制:
- acks=0:生产者发送后不等待确认,可能丢数据,但吞吐量最高
- acks=1:Leader写入成功后确认,如Leader宕机可能丢数据
- acks=all/-1:ISR中所有副本写入成功后确认,提供最高的持久性保证
// 生产者配置不同的一致性级别
Properties props = new Properties();
// 最高持久性保证
props.put("acks", "all");
props.put("min.insync.replicas", 2); // 至少2个副本同步成功// 或平衡性能和可靠性
props.put("acks", "1");
4️⃣ ISR动态调整
- 当Follower落后Leader过多时,会被踢出ISR
- 当Follower追上Leader时,会被加回ISR
- ISR变化会记录到ZooKeeper中
🔍 面试官视角
优秀的回答应该:
- 清晰解释ISR、HW、LEO等概念及其关系
- 分析不同一致性级别的权衡
- 讨论ISR机制可能面临的挑战和解决方案
- 能够结合实际案例说明如何配置ISR相关参数
🔥 RocketMQ篇
Q1: RocketMQ的事务消息是如何实现的?它解决了什么问题?
👉 点击查看答案💡 标准答案
RocketMQ的事务消息解决了分布式事务中的"消息投递与本地事务的一致性"问题,实现了最终一致性。
1️⃣ 事务消息实现原理
RocketMQ事务消息的实现基于两阶段提交(2PC)的变种,具体流程如下:
- 发送半消息(Half Message):消息先发送到Broker,但标记为"暂不可消费"
- 执行本地事务:生产者执行本地数据库事务
- 提交或回滚事务:根据本地事务结果,向Broker发送commit或rollback命令
- 事务状态回查:如果因网络问题未收到提交或回滚命令,Broker会定期回查生产者
// RocketMQ事务消息示例代码
TransactionMQProducer producer = new TransactionMQProducer("transaction_producer_group");
producer.setNamesrvAddr("127.0.0.1:9876");// 设置事务监听器
producer.setTransactionListener(new TransactionListener() {@Overridepublic LocalTransactionState executeLocalTransaction(Message msg, Object arg) {try {// 执行本地事务,如数据库操作String sql = "INSERT INTO orders(id, user_id, amount) VALUES(?, ?, ?)";jdbcTemplate.update(sql, orderId, userId, amount);// 本地事务成功return LocalTransactionState.COMMIT_MESSAGE;} catch (Exception e) {// 本地事务失败return LocalTransactionState.ROLLBACK_MESSAGE;}}@Overridepublic LocalTransactionState checkLocalTransaction(MessageExt msg) {// 回查本地事务状态String orderId = msg.getKeys();boolean exists = jdbcTemplate.queryForObject("SELECT COUNT(1) FROM orders WHERE id = ?", new Object[]{orderId}, Integer.class) > 0;return exists ? LocalTransactionState.COMMIT_MESSAGE : LocalTransactionState.ROLLBACK_MESSAGE;}
});producer.start();// 发送事务消息
Message msg = new Message("TopicTest", "TagA", "KEY" + orderId, ("Hello RocketMQ " + orderId).getBytes());
TransactionSendResult sendResult = producer.sendMessageInTransaction(msg, null);
2️⃣ 解决的问题
- 分布式事务一致性:确保本地事务与消息发送要么都成功,要么都失败
- 最终一致性保证:即使系统崩溃或网络异常,通过回查机制也能最终达到一致状态
- 业务解耦:将复杂的分布式事务问题简化为本地事务+消息发送
3️⃣ 应用场景
- 订单-库存系统:下单减库存,确保订单创建与库存扣减的一致性
- 账户转账:确保转出账户扣款与转入账户入账的一致性
- 积分系统:用户消费后积分增加,确保消费记录与积分增加的一致性
🔍 面试官视角
优秀的回答应该:
- 清晰描述事务消息的工作流程
- 解释事务消息如何解决分布式事务问题
- 分析事务消息的优缺点和适用场景
- 能够结合代码示例说明如何使用事务消息
- 讨论可能的异常情况及处理方法
Q2: RocketMQ如何保证顺序消息的可靠投递?
👉 点击查看答案💡 标准答案
RocketMQ通过特殊的消息发送机制和消费模式来保证顺序消息的可靠投递。
1️⃣ 顺序消息类型
RocketMQ支持两种顺序:
- 全局顺序:某个Topic下的所有消息都按照严格的先入先出(FIFO)顺序进行发布和消费
- 分区顺序:保证同一个分区(队列)内的消息顺序,不同分区间不保证顺序
2️⃣ 顺序消息实现原理
-
发送端保证:
- 使用MessageQueueSelector选择同一个队列
- 同一业务ID(如订单ID)的消息发送到同一队列
- 发送者内部使用锁机制保证同一队列的消息顺序发送
-
Broker端保证:
- 单一队列由单一线程处理
- 使用CommitLog顺序写入
-
消费端保证:
- 顺序消费模式(ConsumeOrderlyContext)
- 消费者从同一队列读取消息时使用锁机制
- 消费失败时支持定时重试,而不是立即重试
// 生产者发送顺序消息示例
DefaultMQProducer producer = new DefaultMQProducer("order_producer_group");
producer.setNamesrvAddr("127.0.0.1:9876");
producer.start();// 订单ID
String orderId = "ORDER_20231101001";// 订单状态变更消息列表
List<Message> messages = new ArrayList<>();
messages.add(new Message("OrderTopic", "CREATE", orderId, "订单创建".getBytes()));
messages.add(new Message("OrderTopic", "PAY", orderId, "订单支付".getBytes()));
messages.add(new Message("OrderTopic", "SHIP", orderId, "订单发货".getBytes()));
messages.add(new Message("OrderTopic", "FINISH", orderId, "订单完成".getBytes()));// 使用选择器确保同一订单的消息发送到同一队列
for (Message msg : messages) {producer.send(msg, new MessageQueueSelector() {@Overridepublic MessageQueue select(List<MessageQueue> mqs, Message msg, Object arg) {String id = (String) arg;// 根据订单ID哈希选择队列,确保同一订单的消息进入同一队列int index = Math.abs(id.hashCode()) % mqs.size();return mqs.get(index);}}, orderId);
}// 消费者顺序消费示例
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("order_consumer_group");
consumer.setNamesrvAddr("127.0.0.1:9876");
consumer.subscribe("OrderTopic", "*");// 注册顺序消费监听器
consumer.registerMessageListener(new MessageListenerOrderly() {@Overridepublic ConsumeOrderlyStatus consumeMessage(List<MessageExt> msgs, ConsumeOrderlyContext context) {// 设置自动提交,默认为truecontext.setAutoCommit(true);for (MessageExt msg : msgs) {try {// 处理消息String orderId = msg.getKeys();String orderStatus = new String(msg.getBody());System.out.println("处理订单: " + orderId + ", 状态: " + orderStatus);// 业务处理...} catch (Exception e) {// 消费失败,稍后重试return ConsumeOrderlyStatus.SUSPEND_CURRENT_QUEUE_A_MOMENT;}}// 消费成功return ConsumeOrderlyStatus.SUCCESS;}
});consumer.start();
3️⃣ 顺序消息的可靠性保障
- 发送失败重试:默认重试2次,可配置
- 故障转移:Broker故障时,消息可从slave读取,但可能短暂影响顺序
- 消费失败处理:顺序消费模式下,消费失败会暂停队列一段时间再重试,而不是立即消费下一条
4️⃣ 适用场景
- 订单状态流转:创建→支付→发货→完成
- 金融交易流程:下单→清算→结算
- 库存变更:预占→扣减→释放
🔍 面试官视角
优秀的回答应该:
- 区分全局顺序和分区顺序的概念和适用场景
- 详细解释顺序消息在生产、存储、消费各环节的保障机制
- 分析顺序消息可能面临的挑战(如性能、可用性)
- 能够结合代码示例说明如何正确使用顺序消息
🔥 RabbitMQ篇
Q1: 详细解释RabbitMQ的Exchange类型及其路由机制?
👉 点击查看答案💡 标准答案
RabbitMQ的Exchange是消息路由的核心组件,负责接收生产者发送的消息并根据路由规则将其转发到队列。
1️⃣ Direct Exchange(直接交换机)
- 路由机制:完全匹配路由键(Routing Key)
- 特点:一对一精确匹配,一个消息只会被路由到绑定键(Binding Key)与路由键完全相同的队列
- 适用场景:精确的消息分发,如日志级别路由(error、info、warning)
// JavaScript示例(使用amqplib)
const amqp = require('amqplib');async function setupDirectExchange() {const connection = await amqp.connect('amqp://localhost');const channel = await connection.createChannel();// 声明Direct交换机await channel.assertExchange('logs_direct', 'direct', {durable: true});// 创建队列const q = await channel.assertQueue('error_logs', {durable: true});// 绑定队列到交换机,只接收error级别的日志await channel.bindQueue(q.queue, 'logs_direct', 'error');// 发送消息channel.publish('logs_direct', 'error', Buffer.from('This is an error message'));
}
2️⃣ Fanout Exchange(扇出交换机)
- 路由机制:忽略路由键,广播到所有绑定的队列
- 特点:一对多,消息会被复制并路由到所有绑定的队列
- 适用场景:广播消息,如系统通知、实时更新
# Python示例(使用pika)
import pikaconnection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()# 声明Fanout交换机
channel.exchange_declare(exchange='broadcasts', exchange_type='fanout')# 创建临时队列
result = channel.queue_declare(queue='', exclusive=True)
queue_name = result.method.queue# 绑定队列到交换机(不需要路由键)
channel.queue_bind(exchange='broadcasts', queue=queue_name)# 发送消息
channel.basic_publish(exchange='broadcasts',routing_key='', # 路由键被忽略body='Broadcast message to all subscribers'
)
3️⃣ Topic Exchange(主题交换机)
- 路由机制:基于模式匹配的路由键
- 特点:使用通配符(*表示一个单词,#表示零个或多个单词)进行模式匹配
- 适用场景:基于多维度分类的消息路由,如地区.服务.级别
// Java示例(使用Spring AMQP)
@Configuration
public class RabbitConfig {@Beanpublic TopicExchange topicExchange() {return new TopicExchange("market_data");}@Beanpublic Queue usStocksQueue() {return new Queue("us_stocks_queue");}@Beanpublic Queue allTechStocksQueue() {return new Queue("tech_stocks_queue");}@Beanpublic Binding usStocksBinding(Queue usStocksQueue, TopicExchange topicExchange) {// 绑定美国股票队列,接收所有美国股票数据return BindingBuilder.bind(usStocksQueue).to(topicExchange).with("us.#"); // 匹配us.nyse.*, us.nasdaq.* 等}@Beanpublic Binding techStocksBinding(Queue allTechStocksQueue, TopicExchange topicExchange) {// 绑定科技股票队列,接收所有地区的科技股票return BindingBuilder.bind(allTechStocksQueue).to(topicExchange).with("*.*.tech"); // 匹配us.nasdaq.tech, eu.euronext.tech 等}
}// 发送消息
@Service
public class MarketDataService {@Autowiredprivate RabbitTemplate rabbitTemplate;public void sendStockUpdate(String stock, double price) {// 例如:发送特斯拉股票更新rabbitTemplate.convertAndSend("market_data", // 交换机名称"us.nasdaq.tech", // 路由键new StockUpdate("TSLA", price));}
}
4️⃣ Headers Exchange(头交换机)
- 路由机制:基于消息头属性而非路由键
- 特点:使用消息的headers属性进行匹配,可以指定x-match=all(全部匹配)或any(任一匹配)
- 适用场景:需要基于多个条件路由,且条件不适合放在路由键中
// C#示例(使用RabbitMQ.Client)
using RabbitMQ.Client;
using System.Collections.Generic;
using System.Text;var factory = new ConnectionFactory() { HostName = "localhost" };
using var connection = factory.CreateConnection();
using var channel = connection.CreateModel();// 声明Headers交换机
channel.ExchangeDeclare("headers_exchange", ExchangeType.Headers);// 声明队列
var queueName = channel.QueueDeclare().QueueName;// 绑定队列,要求同时匹配format=pdf和type=report
var bindingArgs = new Dictionary<string, object>
{{"format", "pdf"},{"type", "report"},{"x-match", "all"} // 要求所有条件都匹配
};channel.QueueBind(queueName, "headers_exchange", "", bindingArgs);// 发送消息
var messageProps = channel.CreateBasicProperties();
messageProps.Headers = new Dictionary<string, object>
{{"format", "pdf"},{"type", "report"},{"priority", "high"}
};channel.BasicPublish("headers_exchange","", // 路由键被忽略messageProps,Encoding.UTF8.GetBytes("Monthly Sales Report")
);
🔍 面试官视角
优秀的回答应该:
- 清晰解释各种Exchange类型的路由机制和特点
- 分析每种Exchange的适用场景和优缺点
- 能够结合代码示例说明如何使用不同类型的Exchange
- 讨论Exchange选择的考量因素(如性能、灵活性、复杂度)
Q2: RabbitMQ的死信队列和延迟队列是什么?如何实现?
👉 点击查看答案💡 标准答案
1️⃣ 死信队列(Dead Letter Queue)
-
定义:无法被正常消费的消息会被路由到死信队列
-
产生死信的情况:
- 消息被拒绝(basic.reject/basic.nack)且requeue=false
- 消息过期(TTL到期)
- 队列达到最大长度
-
实现方式:通过设置队列的
x-dead-letter-exchange和x-dead-letter-routing-key参数
// Java实现死信队列
@Configuration
public class RabbitMQConfig {// 声明死信交换机@Beanpublic DirectExchange deadLetterExchange() {return new DirectExchange("dead.letter.exchange");}// 声明死信队列@Beanpublic Queue deadLetterQueue() {return QueueBuilder.durable("dead.letter.queue").build();}// 绑定死信队列到死信交换机@Beanpublic Binding deadLetterBinding() {return BindingBuilder.bind(deadLetterQueue()).to(deadLetterExchange()).with("dead.letter.routing.key");}// 声明业务队列,并配置死信参数@Beanpublic Queue businessQueue() {Map<String, Object> args = new HashMap<>();// 设置死信交换机args.put("x-dead-letter-exchange", "dead.letter.exchange");// 设置死信路由键args.put("x-dead-letter-routing-key", "dead.letter.routing.key");// 可选:设置消息过期时间(毫秒)args.put("x-message-ttl", 10000);// 可选:设置队列最大长度args.put("x-max-length", 1000);return QueueBuilder.durable("business.queue").withArguments(args).build();}
}
2️⃣ 延迟队列(Delayed Queue)
-
定义:消息发送后不会立即被消费,而是在指定时间后才能被消费
-
应用场景:
- 订单超时取消
- 定时任务调度
- 消息重试机制
-
实现方式一:TTL + 死信队列
// Node.js实现基于TTL和死信队列的延迟队列
const amqp = require('amqplib');async function setupDelayedQueue() {const connection = await amqp.connect('amqp://localhost');const channel = await connection.createChannel();// 声明死信交换机和队列(实际业务队列)await channel.assertExchange('actual.exchange', 'direct', {durable: true});const actualQueue = await channel.assertQueue('actual.queue', {durable: true});await channel.bindQueue(actualQueue.queue, 'actual.exchange', 'actual.routing.key');// 声明延迟交换机和队列await channel.assertExchange('delay.exchange', 'direct', {durable: true});const delayQueue = await channel.assertQueue('delay.queue', {durable: true,arguments: {// 设置消息过期后转发到实际业务交换机'x-dead-letter-exchange': 'actual.exchange','x-dead-letter-routing-key': 'actual.routing.key'}});await channel.bindQueue(delayQueue.queue, 'delay.exchange', 'delay.routing.key');// 发送延迟消息(5秒后处理)const msg = 'Delayed message';channel.publish('delay.exchange', 'delay.routing.key', Buffer.from(msg), {expiration: '5000' // 5秒TTL});console.log(" [x] Sent '%s' with 5s delay", msg);
}
- 实现方式二:RabbitMQ延迟消息插件
# Python实现基于插件的延迟队列
import pika
import jsonconnection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()# 声明一个支持延迟的交换机(需要安装rabbitmq_delayed_message_exchange插件)
channel.exchange_declare(exchange='delay.plugin.exchange',exchange_type='x-delayed-message',arguments={'x-delayed-type': 'direct'}
)# 声明队列并绑定
channel.queue_declare(queue='delay.plugin.queue', durable=True)
channel.queue_bind(exchange='delay.plugin.exchange',queue='delay.plugin.queue',routing_key='delay.plugin.key'
)# 发送延迟消息
message = {'order_id': '12345', 'action': 'cancel_if_unpaid'}
headers = {'x-delay': 30000} # 30秒延迟channel.basic_publish(exchange='delay.plugin.exchange',routing_key='delay.plugin.key',body=json.dumps(message),properties=pika.BasicProperties(delivery_mode=2, # 持久化消息headers=headers)
)print(" [x] Sent order cancel message with 30s delay")
connection.close()
3️⃣ 死信队列与延迟队列的应用
-
死信队列应用:
- 异常消息处理和分析
- 消息重试机制
- 消息审计和问题排查
-
延迟队列应用:
- 订单超时关闭:下单后30分钟未支付自动取消
- 预约系统:提前10分钟发送提醒
- 限时优惠:优惠券到期前发送提醒
- 定时任务调度:定时生成报表、数据统计
🔍 面试官视角
优秀的回答应该:
- 清晰解释死信队列和延迟队列的概念和应用场景
- 详细说明实现方式和关键配置参数
- 分析不同实现方式的优缺点(如TTL+DLX vs 插件)
- 能够结合代码示例说明如何正确配置和使用
- 讨论可能遇到的问题和解决方案(如精确延迟、消息堆积等)
🔥 Pulsar篇
Q1: Pulsar的分层存储架构有什么优势?与传统消息队列有何不同?
👉 点击查看答案💡 标准答案
Pulsar的分层存储架构是其核心创新点,通过计算与存储分离的设计,解决了传统消息队列的多项痛点。
1️⃣ Pulsar的分层存储架构
-
BookKeeper层(存储层):
- 负责持久化存储消息数据
- 由多个Bookie节点组成
- 使用分布式日志实现高可靠性和高性能
-
Broker层(服务层):
- 处理客户端连接和请求
- 管理主题和订阅
- 协调消息的生产和消费
- 无状态设计,便于水平扩展
-
ZooKeeper(元数据层):
- 存储集群元数据
- 管理Broker和Bookie的成员关系
- 处理领导者选举
-
Pulsar架构示意图:
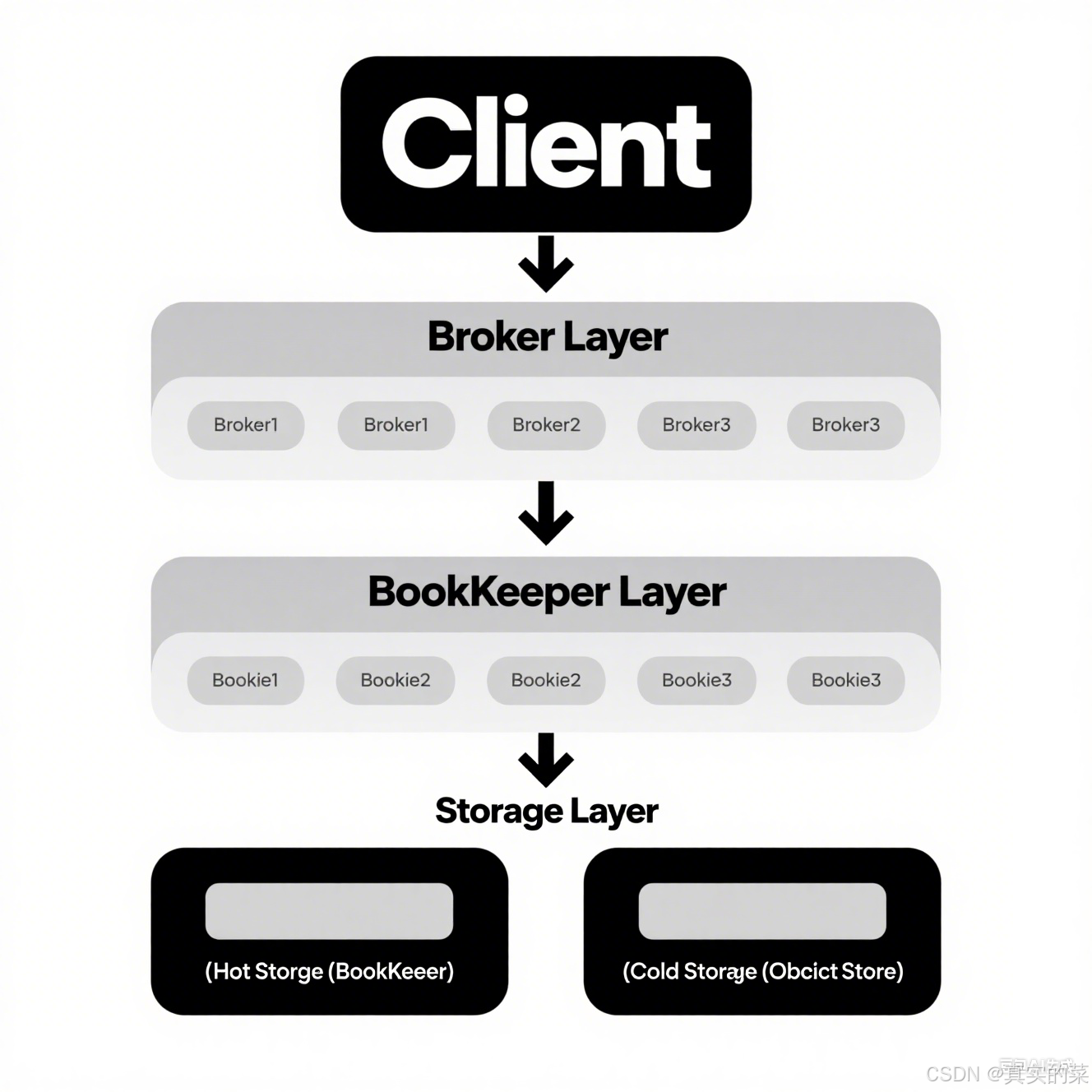
2️⃣ 与传统消息队列的区别
| 特性 | Pulsar | 传统消息队列(如Kafka) |
|---|---|---|
| 架构设计 | 计算与存储分离 | 计算与存储耦合 |
| 扩展性 | 计算层和存储层可独立扩展 | 扩展节点同时扩展计算和存储 |
| 数据均衡 | 自动均衡,无需数据迁移 | 分区再平衡需要数据迁移 |
| 多租户 | 原生支持多租户隔离 | 有限支持或需额外配置 |
| 存储扩展 | 支持分层存储(热/冷数据) | 通常只有单一存储层 |
| Broker故障 | 无状态Broker,快速恢复 | 有状态Broker,恢复较慢 |
3️⃣ 分层存储的优势
- 无限制的消息保留:
- 热数据保存在BookKeeper中
- 冷数据可卸载到对象存储(如S3、GCS)
- 支持按需加载历史数据
// Java示例:配置分层存储
Admin admin = PulsarAdmin.builder().serviceHttpUrl("http://localhost:8080").build();// 创建带有分层存储的命名空间
admin.namespaces().createNamespace("tenant/namespace");// 配置分层存储策略
NamespaceOffloadPolicies offloadPolicies = NamespaceOffloadPolicies.builder().offloadersDirectory("/pulsar/offloaders") // 卸载器目录.managedLedgerOffloadDriver("s3") // 使用S3作为冷存储.offloadThresholdInBytes(1024 * 1024 * 1024) // 1GB阈值.offloadDeletionLagInMillis(TimeUnit.DAYS.toMillis(7)) // 删除延迟.s3ManagedLedgerOffloadRegion("us-west-2").s3ManagedLedgerOffloadBucket("pulsar-offload-bucket").build();admin.namespaces().setOffloadPolicies("tenant/namespace", offloadPolicies);
-
弹性扩展:
- Broker层可根据连接和处理需求扩展
- 存储层可根据数据量扩展
- 避免资源浪费,优化成本
-
高可用性:
- Broker无状态,故障恢复快速
- 数据多副本存储在BookKeeper中
- 跨区域复制更简单
-
多租户支持:
- 租户和命名空间的层次化隔离
- 资源配额和限制
- 认证和授权机制
# Pulsar多租户配置示例
tenants:finance:adminRoles:- finance-adminallowedClusters:- us-west- us-eastmarketing:adminRoles:- marketing-adminallowedClusters:- us-westnamespaces:finance/transactions:retention:size: 100Gtime: 7dreplication:clusters:- us-west- us-eastmarketing/campaigns:retention:size: 50Gtime: 3dreplication:clusters:- us-west
🔍 面试官视角
优秀的回答应该:
- 清晰解释Pulsar的分层架构设计和各层职责
- 详细对比Pulsar与传统消息队列的架构差异
- 分析分层存储带来的具体优势和适用场景
- 能够结合配置示例说明如何利用分层存储特性
- 讨论分层架构可能带来的挑战和解决方案
Q2: Pulsar的多租户支持有哪些特性?如何实现资源隔离?
👉 点击查看答案💡 标准答案
Pulsar的多租户支持是其核心优势之一,通过层次化的资源管理和隔离机制,实现了企业级的多租户能力。
1️⃣ 多租户架构
Pulsar采用三级层次结构实现多租户:
- 租户(Tenant):最高级别的资源隔离单位
- 命名空间(Namespace):租户内的逻辑分组
- 主题(Topic):命名空间内的消息通道
完整的主题名称格式:persistent://tenant/namespace/topic
多租户层次结构示例:租户: finance├── 命名空间: finance/transactions│ ├── 主题: persistent://finance/transactions/orders│ ├── 主题: persistent://finance/transactions/payments│ └── 主题: persistent://finance/transactions/refunds│└── 命名空间: finance/reporting├── 主题: persistent://finance/reporting/daily-summary└── 主题: persistent://finance/reporting/monthly-stats租户: marketing└── 命名空间: marketing/campaigns├── 主题: persistent://marketing/campaigns/email└── 主题: persistent://marketing/campaigns/social
2️⃣ 资源隔离机制
- 认证与授权:
- 支持多种认证机制(TLS、JWT、OAuth2等)
- 基于角色的访问控制(RBAC)
- 细粒度的权限管理(生产、消费、管理)
// Java示例:创建租户并分配角色
Admin admin = PulsarAdmin.builder().serviceHttpUrl("http://localhost:8080").authentication(AuthenticationFactory.token("admin-token")).build();// 创建租户并分配管理角色
TenantInfo tenantInfo = TenantInfo.builder().adminRoles(Set.of("finance-admin")) // 管理角色.allowedClusters(Set.of("us-west")) // 允许使用的集群.build();admin.tenants().createTenant("finance", tenantInfo);// 设置命名空间权限
admin.namespaces().grantPermissionOnNamespace("finance/transactions","finance-user",Set.of(AuthAction.produce, AuthAction.consume)
);
- 资源配额:
- 命名空间级别的消息吞吐量限制
- 存储空间配额
- 主题数量限制
# Pulsar资源配额配置示例
namespaces:finance/transactions:# 消息速率限制rate:in: 100MB # 入站限制out: 200MB # 出站限制# 存储配额storage:limit: 500GBpolicy: producer_exception# 主题数量限制max_topics_per_namespace: 1000# 消费者和生产者限制max_producers_per_topic: 100max_consumers_per_topic: 500max_consumers_per_subscription: 50
- 计算资源隔离:
- Broker负载均衡
- 命名空间绑定到特定Broker
- 租户级别的资源分配
3️⃣ 存储隔离
-
数据隔离:
- 不同租户的数据存储在不同的ledger中
- 支持租户级别的数据加密
-
存储策略:
- 命名空间级别的消息保留策略
- 分层存储配置(热/冷存储)
- 数据压缩策略
// Java示例:设置命名空间的存储策略
Admin admin = PulsarAdmin.builder().serviceHttpUrl("http://localhost:8080").build();// 设置消息保留策略
admin.namespaces().setRetention("finance/transactions",new RetentionPolicies(7 * 24 * 60, 100 * 1024) // 7天或100GB
);// 设置压缩策略
admin.namespaces().setCompactionThreshold("finance/transactions",1024 * 1024 * 1024L // 1GB
);// 设置分层存储策略
NamespaceOffloadPolicies offloadPolicies = NamespaceOffloadPolicies.builder().offloadThresholdInBytes(10 * 1024 * 1024 * 1024L) // 10GB.offloadDeletionLagInMillis(TimeUnit.DAYS.toMillis(30)) // 30天.build();admin.namespaces().setOffloadPolicies("finance/transactions", offloadPolicies);
4️⃣ 网络隔离
-
集群隔离:
- 租户可以限制在特定集群上
- 跨区域复制策略
-
网络资源控制:
- 带宽限制
- 连接数限制
5️⃣ 多租户最佳实践
-
租户设计:
- 基于业务部门或团队划分租户
- 避免过多租户导致管理复杂
-
命名空间设计:
- 基于应用或业务功能划分命名空间
- 合理设置资源配额和策略
-
监控与审计:
- 租户级别的资源使用监控
- 操作审计日志
- 异常行为告警
🔍 面试官视角
优秀的回答应该:
- 清晰解释Pulsar的多租户架构和层次结构
- 详细说明资源隔离的多个维度(认证授权、资源配额、存储隔离等)
- 能够结合配置示例说明如何实现多租户隔离
- 分析多租户带来的优势和可能的挑战
- 讨论多租户设计的最佳实践和注意事项
📚 总结
通过本文的面试题解析,我们深入探讨了Kafka、RocketMQ、RabbitMQ和Pulsar这四种主流消息队列的核心特性和实现原理。每种消息队列都有其独特的设计理念和适用场景:
- Kafka:以高吞吐量和持久性著称,适合日志收集、流处理等大数据场景
- RocketMQ:兼顾性能和功能,提供事务消息、顺序消息等企业级特性
- RabbitMQ:灵活的路由机制和丰富的交换机类型,适合复杂的消息路由场景
- Pulsar:创新的分层存储架构和多租户支持,适合云原生和混合工作负载
在面试中,不仅要了解这些消息队列的基本概念,还要深入理解其内部实现原理、性能特点和适用场景。希望这些面试题和答案能帮助你在技术面试中脱颖而出!
🔔 关注我,获取更多高质量技术面试题解析!如有问题,欢迎在评论区留言讨论!