计算机系统结构第5章-线程级并行
多处理机的概述
自20世纪50年代末、60年代初出现第一批晶体管计算机以来,单处理器性能的增长速度在1986年至2003年期间达到最高峰。之后,摩尔定律放缓,豋纳德缩放比例定律失效
2006年开始,功耗墙问题导致处理器频率极限约为4GHz
-分类
MIMD已成为通用多处理机系统结构的选择,原因:
MIMD具有灵活性;MIMD可以充分利用商品化微处理器在性能价格比方面的优势
分类:
集中式共享存储器结构
分布式存储器多处理机
集中式共享存储器结构:
最多由几十个处理器构成。处理器共享一个集中式的物理存储器
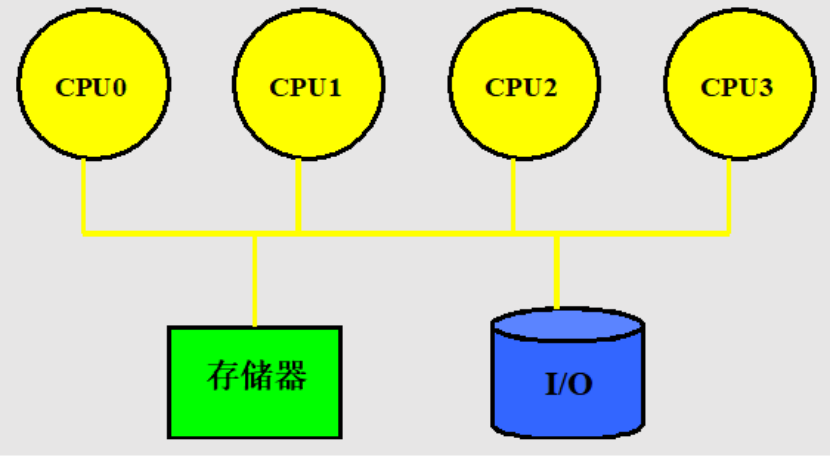
也叫做SMP,UMP
SMP机器(Symmetric shared-memory MultiProcessor)对称多处理器
对称:所有处理器都能够平等的访问存储器
(现有的多核心芯片都是SMP)
UMA机器(Uniform Memory Access) 一致存储器访问
一致:所有处理器访问存储器的延迟都是一致的
分布式存储器多处理机
存储器在物理上是分布的。
每个结点包含:处理器,存储器,I/O,互连网络接口
在许多情况下,分布式存储器结构优于集中式共享存储器结构。
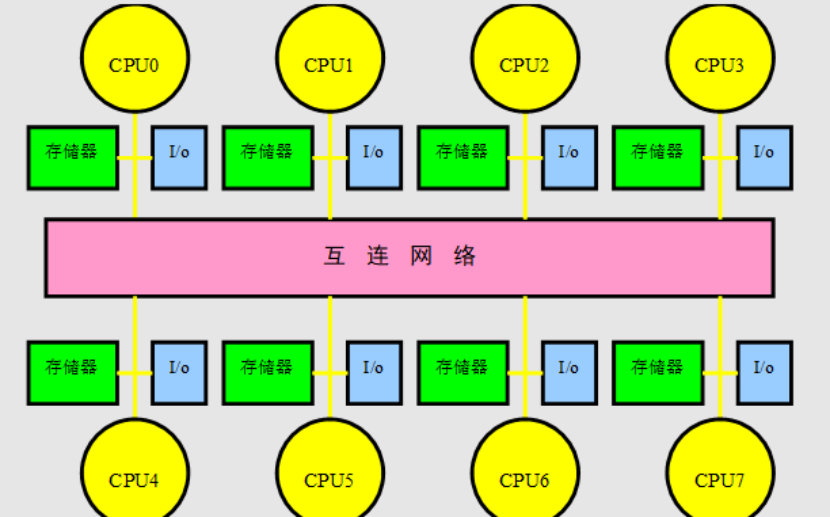
将存储器分布到各结点的优点
如果大多数的访问是针对本结点的局部存储器,则可降低对存储器和互连网络的带宽要求;
对本地存储器的访问延迟时间小。
缺点
处理器之间的通信较为复杂,且各处理器之间访问延迟较大。
簇:超级结点
每个结点内包含个数较少(例如2~8)的处理器;
处理器之间可采用另一种互连技术(例如总线)相互连接形成簇。
存储器系统结构:
大规模多处理机中存储器在物理上分布在各个处理节点中,但是在逻辑地址空间的组织方式及处理器之间通信的实现方法上,有两种方案:
1,共享地址空间
物理上分离的所有存储器作为一个统一的共享逻辑空间进行编址,任何一个处理器可以访问该共享空间中的任何一个单元(如果它具有访问权),而且不同处理器上的同一个物理地址指向的是同一个存储单元。
别称:DSM,NUMA
分布式共享存储器系统,允许多个处理器或节点共享同一逻辑地址空间的存储器
NUMA 架构中,处理器访问本地内存的速度比访问远程内存(其他处理器关联的内存 )速度更快。
2,独立地址空间
把每个结点中的存储器编址为一个独立的地址空间,不同结点中的地址空间之间是相互独立的。
整个系统的地址空间由多个独立的地址空间构成
每个结点中的存储器只能由本地的处理器进行访问,远程的处理器不能直接对其进行访问。
可以把每个处理器-存储器看做一个单独的计算机,这种机器多以集群存在
通信机制:
1,共享存储器通信机制:
共享地址空间的计算机系统采用,处理器之间是通过用load和store指令对相同存储器地址进行读/写操作来实现的。
2,消息传递通信机制:
多个独立地址空间的计算机采用 ,通过处理器间显式地传递消息来完成。
远程消息传递机制:
远程进程调用(RPC):发送消息,请求传递数据或对数据进行操作.目的处理器接收到消息以后,执行相应的操作或代替远程处理器进行访问,并发送一个应答消息将结果返回。
1,同步:
请求处理器发送一个消息后一直要等到应答结果才继续运行
2,异步:
数据发送方知道别的处理器需要数据,通信也可以从数据发送方来开始,数据可以不经请求就直接送往数据接受方。
共享存储器通信的主要优点
1,与常用的对称式多处理机使用的通信机制兼容。
2,易于编程,同时在简化编译器设计方面也占有优势。
3,采用大家所熟悉的共享存储器模型开发应用程序,而把重点放到解决对性能影响较大的数据访问上。
4,当通信数据量较小时,通信开销较低,带宽利用较好。
5,可以通过采用Cache技术来减少远程通信的频度,减少了通信延迟以及对共享数据的访问冲突。
消息传递通信机制的主要优点:
1,硬件较简单。
2,通信是显式的,因此更容易搞清楚何时发生通信以及通信开销是多少。
3,显式通信可以让编程者重点注意并行计算的主要通信开销,使之有可能开发出结构更好、性能更高的并行程序。
4,同步很自然地与发送消息相关联,能减少不当的同步带来错误的可能性。
5,可在支持上面任何一种通信机制的硬件模型上建立所需的通信模式平台。
在共享存储器上支持消息传递相对简单。
在消息传递的硬件上支持共享存储器就困难得多。所有对共享存储器的访问均要求操作系统提供地址转换和存储保护功能,即将存储器访问转换为消息的发送和接收。
计算机构成的两个基本要素:
点:
包括小到CPU内部的寄存器、ALU、控制器,到存储模块、外设,乃至多处理机的计算节点,都可以视为点;
互连网络:
按照一定拓扑结构和控制方式,将点连接起来。
系统内部的互联:
静态互连网络:指处理单元间有固定连接的一类网络,在程序执行期间,这种点到点的链接保持不变
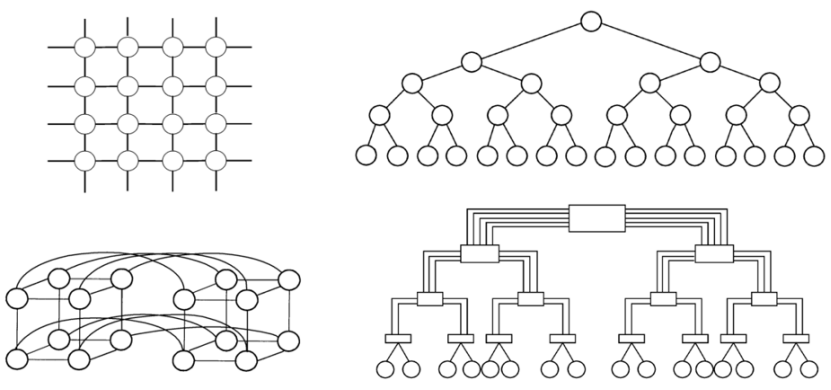
动态互连网络:由开关单元构成,可以按照应用程序的要求动态的改变连接组态。
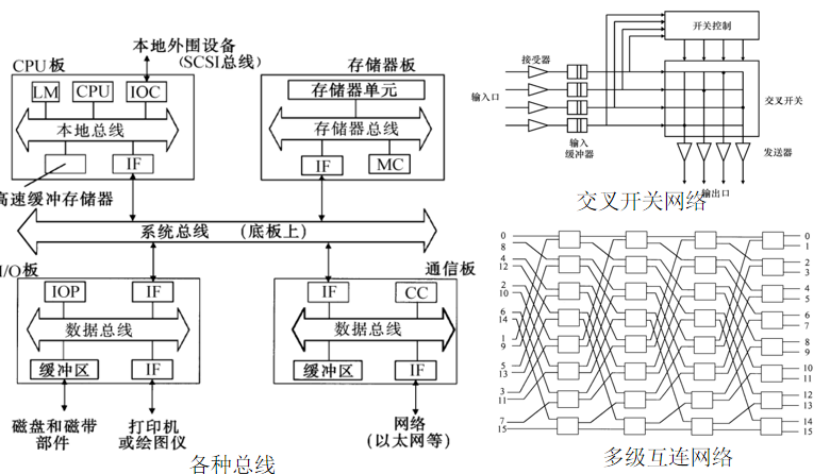
并行处理机体系结构分类:
PVP,Parallel Vector Processor,并行向量处理机
这样的系统中包含了少量的高性能的向量处理器VP,每个至少具有1 Gflops的处理能力;
存储器以兆字节每秒的速度向处理器提供数据。
向量处理器VP和共享存储模块通过高带宽的交叉开关网络互连;
这样的机器通常不使用高速缓存,而是使用大量的向量寄存器和指令缓冲器;
例如:Cray90、NECSX-4和我国的银河1号等都是 PVP。
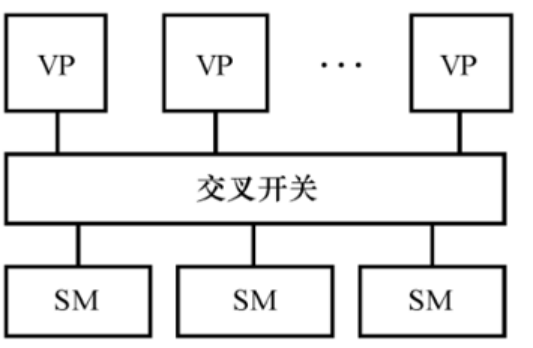
SMP,Symmetric Multiprocessor,对称多处理机
SMP系统使用商品微处理器(具有片上或外置高速缓存);
它们经由高速总线(或交叉开关)连向共享存储器和I/O;
这种机器主要应用于商务,例如数据库、在线事务处理系统和数据仓库等;
重要的是系统是对称的,每个处理器可等同的访问共享存储器、I/O设备和操作系统服务。正是对称,才能开拓较高的并行度;也正是共享存储,限制系统中的处理器不能太多(一般少于64个),同时总线和交叉开关互连一旦作成也难于扩展。
例如:IBM R50、SGI Power Challenge、DEC Alpha服务器8400和我国的曙光1号等都是这种类型的机器
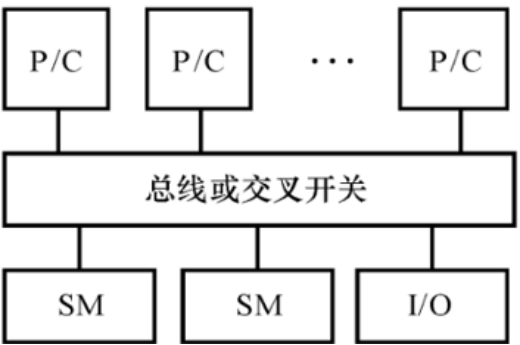
MPP,Massively Parallel Processor,大规模并行处理机
MPP一般是指超大型计算机系统;
处理节点采用商品微处理器;每个节点上有自己的局部存储器;采用高通信带宽和低延迟的互连网络(专门设计和定制的)进行节点互连;
能扩放至成百上千乃至上万个处理器;
它是一种异步的MIMD机器,程序系由多个进程组成,每个都有其私有地址空间,进程间采用传递消息相互作用;
MPP的主要应用是科学计算、工程模拟和信号处理等以计算为主的领域。
例如:Intel Paragon、Cray T3E、IntelOption Red和我国的曙光-1000等都是这种类型的机器。
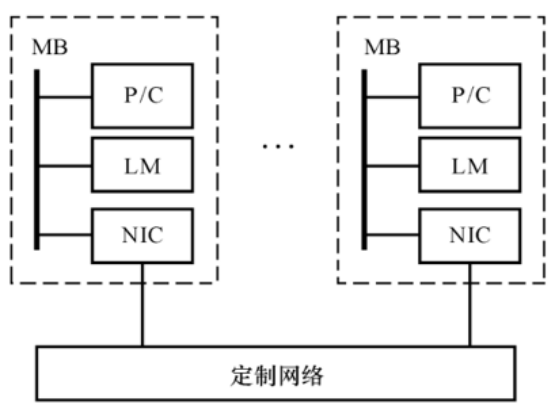
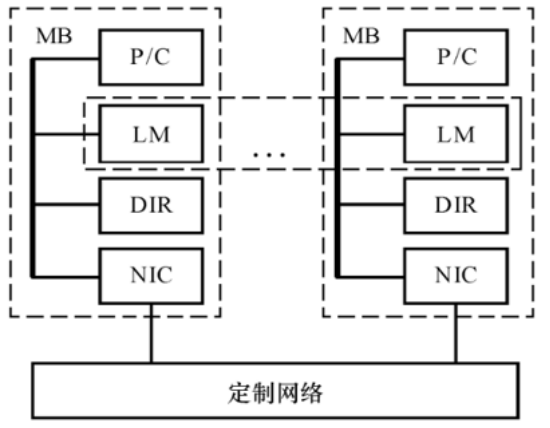
DSM,Distributed Shared Memory,分布式共享存储多处理机
物理上有分布在各节点中的局部存储器,但是对用户而言,系统硬件和软件提供了逻辑上单地址的编程空间。
高速缓存目录DIR用以支持分布高速缓存的一致性。
DSM相对于MPP的优越性是编程较容易
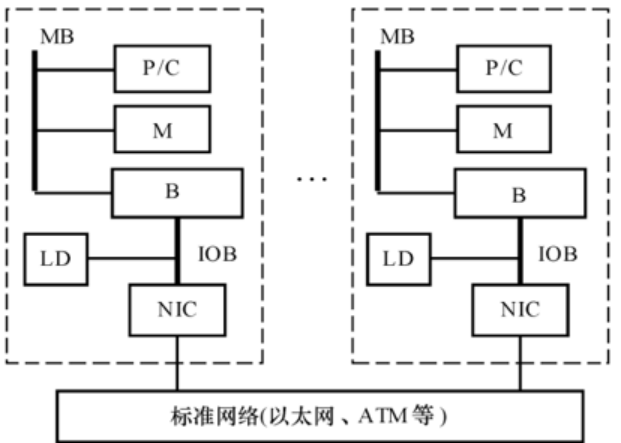
COW,Cluster of Workstations,工作站集群
在有些情况下,集群往往是低成本的变形的MPP;
COW的重要界线和特征是:
①COW的每个节点都是一个完整的工作站(不包括监视器、键盘、鼠标等),这样的节点有时叫作“无头工作站”,一个节点也可以是一台PC或SMP;
②各节点通过一种低成本的商品(标准)网络(如以太网、FDDI和ATM开关等)互连(有的商用机群也使用定做的网络);
③各节点内总是有本地磁盘,而MPP节点内却没有;
④节点内的网络接口是松散耦合到I/O总线上的,而MPP内的网络接口是连到处理节点的存储总线上的,因而可谓是紧耦合式的;
⑤一个完整的操作系统驻留在每个节点中,而MPP中通常只是个微核,COW的操作系统是工作站 UNIX,加上一个附加的软件层以支持单一系统映像、并行度、通信和负载平衡等。
-性能测试:并行处理的两个挑战:
1程序中的并行性有限;

比如:假设想用100个处理器达到80的加速比,求原计算程序中串行部分最多可占多大的比例?

得出并行比例:99.75%
2相对较大的通信开销
针对第二个挑战,多处理机之间的远程访问的延迟本来就很大,毋庸置疑的,现有的机器中,处理器之间的数据通信大约需要50~1000个时钟周期。
(这主要取决于通信机制、互连网络的种类和机器的规模)
例题:
假设有一台32台处理器的多处理机,对远程存储器访问时间为200ns。除了通信以外,假设所有其他访问均命中局部存储器。当发出一个远程请求时,本处理器挂起。处理器的时钟频率为2GHz,如果指令基本的CPI为0.5(设所有访存均命中Cache),求在没有远程访问的情况下和有0.2%的指令需要远程访问的情况下,前者比后者快多少?

所以要:提升并行性(选择更好的算法)and降低远程访问的延迟(系统结构和编程来实现)
在并行处理中,影响性能(负载平衡、同步和存储器访问延迟等)的关键因素常依赖于:
**应用程序的高层特性**(如数据的分配,并行算法的结构以及在空间和时间上对数据的访问模式等。)
依据应用特点可把多机工作负载大致分成两类:
单个程序在多处理机上的并行工作负载
多个程序在多处理机上的并行工作负载
反映并行程序性能的一个重要的度量:
计算与通信的比率
计算/通信比率随着处理数据规模的增大而增加;随着处理器数目的增加而减少。
(CPU多了,通信多了;数据处理多了,计算多了)
cache一致性问题*****:
一致性问题引入:
多个处理器共享一个存储器。当处理机规模较小时,这种计算机十分经济。但是近些年,能在一个单独的芯片上实现2~8个处理器核。他们支持对共享数据和私有数据的Cache缓存:私有数据供一个单独的处理器使用,而共享数据则是供多个处理器使用。
这就引入了一新的问题:Cache的一致性问题
概念:
允许共享数据进入Cache,就可能出现多个处理器的Cache中都有同一存储块的副本,当其中某个处理器对其Cache中的数据进行修改后,就会使得其Cache中的数据与其他Cache中的数据不一致。
比如:
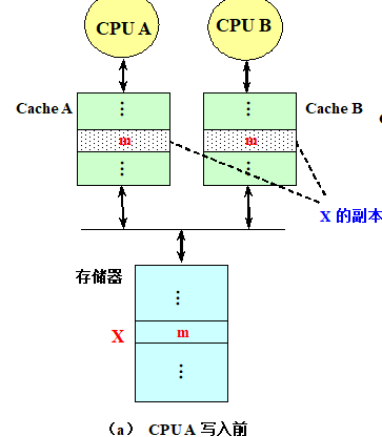
AB同时有X的副本,然后A对X修改,并且写回存储器,这时候B的数据就和存储器和A的不一样了
存储器的一致性:如果对某个数据项的任何读操作均可得到其最新写入的值,则认为这个存储系统是一致的。
去考虑存储系统的两个方面:
What: 读操作得到的是什么值(是和存储器一样?还是和存储器不一样的?)
When: 什么时候才能将已写入的值返回给读操作
一致性需要满足的条件:
1-处理器P对单元X进行一次写之后又对单元X进行读,读和写之间没有其他处理器对单元X进行写,则P读到的值总是前面写进去的值。 (自己读)
2-处理器P对单元X进行写之后,另一处理器Q对单元X进行读,读和写之间无其他写,则Q读到的值应为P写进去的值。(别人读)
3-对同一单元的写是串行化的,即任意两个处理器对同一单元的两次写,从各个处理器的角度看来顺序都是相同的。(写串行化)
所以什么时候写才完成尼?直到所有的处理器均看到了写的结果,这个写操作才算完成;
还有一个需要注意的点:处理器的任何访存均不能改变写的顺序。就是说,允许处理器对读进行重排序,但必须以程序规定的顺序进行写。
实现一致性的方案:
共享数据的迁移:减少了对远程共享数据的访问延迟,也减少了对共享存储器带宽的要求。
共享数据的复制:不仅减少了访问共享数据的延迟,也减少了访问共享数据所产生的冲突。
一般情况下,小规模多处理机是采用硬件的方法来实现Cache的一致性。
实现一致性的两类协议****:
关键:跟踪记录共享数据块的状态
监听式协议********
每个Cache除了包含物理存储器中块的数据拷贝之外,也保存着各个块的共享状态信息。
Cache通常连在共享存储器的总线上,当某个Cache需要访问存储器时,它会把请求放到总线上广播出去,其他各个Cache控制器通过监听总线(它们一直在监听)来判断它们是否有总线上请求的数据块。如果有,就进行相应的操作。
目录式协议**********
物理存储器中数据块的共享状态被保存在一个称为目录的地方。
两种写的协议:
写作废协议:
在处理器对某个数据项进行写入之前,保证它拥有对该数据项的唯一的访问权。(作废其他的副本)
假设,一开始A,B,C对X进行了读入,放在了他们的cache中,然后A进行了修改,这时候就会B,C作废,然后把A写的新值写入A的cache,同时写入主存
写更新协议:
当一个处理器对某数据项进行写入时,通过广播使其他Cache中所有对应于该数据项的副本进行更新。
我们利用监听+写作废局里(写直达)举例:
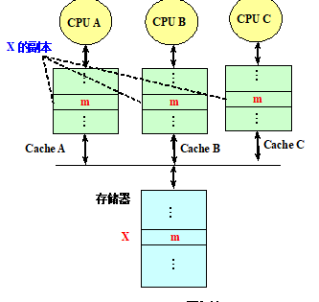
一开始,ABC都有X的副本,然后A会对X写入,这时候会先作废掉BC,然后写入内存
然后再看看监听协议With 写更新:
同样的情况,A要写p入X的时候,会广播p,让所有的有x的cpu进行一个更新,然后也要写回存储器X,(如果是写回法就不需要)
他们两个写的性能差异:
1:A对同一个数据多次写,中间无读操作:写更新协议需进行多次写广播操作,而写作废协议只需一次作废操作。
2:对A中的同一个块内的多个字进行写操作的时候,写更新协议会对每一个写操作都进行一次广播,而写作废只会第一次写的时候去作废(写作废针对cache块,写更新针对字,颗粒度更小)
3:如果是A写,B读,那么写更新会更快