企业私有化部署DeepSeek实战指南:从硬件选型到安全运维——基于国产大模型的安全可控落地实践
一、部署前的战略评估与规划
私有化部署不仅是技术工程,更是企业数据战略的核心环节。需重点评估三方面:
1、业务场景适配性
适用场景:金融风控(需实时数据处理)、医疗诊断(敏感病历保护)、政务系统(合规性要求)等高隐私需求领域。
非必要场景:公开客服问答、营销文案生成等低风险任务建议采用API模式。
2、资源需求量化
计算规模:根据模型版本确定硬件基线(以DeepSeek-R1为例)
7B参数模型:单卡部署(RTX 3090/24GB显存)
67B参数模型:多卡集群(≥4×A100 80GB)
存储需求:模型权重文件(67B约90GB)+ 日志缓存空间(建议预留1TB SSD)
3、合规性框架搭建
需符合《数据安全法》第21条及《个人信息保护法》第39条要求,建立数据生命周期管理机制。部署前完成SBOM(软件物料清单)扫描,确保组件供应链安全。

二、硬件与基础设施配置方案
1、核心硬件选型标准(基于企业级生产环境验证):
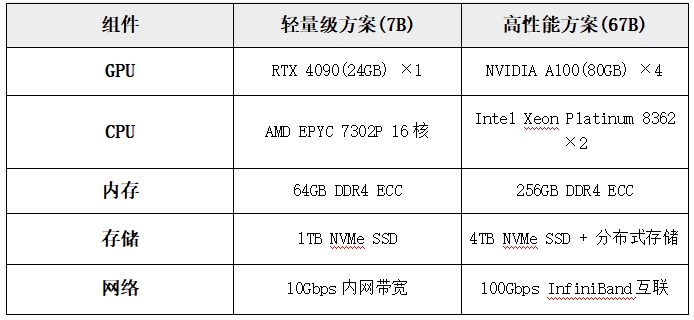
注:显存容量需≥模型参数×1.5(FP16精度),例如67B模型需≥100GB显存池。
2、环境配置要点
操作系统:Ubuntu 20.04 LTS(内核≥5.4)
驱动层:CUDA 11.7 + cuDNN 8.5(需与GPU驱动严格匹配)
虚拟化:推荐Docker容器化部署,隔离依赖环境
:dockerfile
复制
FROM nvidia/cuda:11.8.0-base
COPY ./deepseek-app /app
RUN pip install -r requirements.txt --index-url http://内部PyPI镜像
CMD ["python", "/app/api_server.py"]
三、模型获取与安全部署流程
1、Step 1 模型获取
在线拉取(适用可外网环境):
bash
复制
git lfs install
git clone https://huggingface.co/deepseek-ai/deepseek-llm-67b-base
离线分发(军工/金融等隔离场景):
通过OSS/SMB协议传输加密模型包(SHA256校验)
挂载至/mnt/models/deepseek-67b/
2、Step 2 推理引擎配置
基础框架:vLLM或Triton Inference Server
关键参数(config.json示例):
json
复制
{
"device_map": "auto",
"torch_dtype": "torch.float16",
"max_memory": {"0": "80GiB", "cpu": "256GiB"}
性能优化:
启用4-bit量化(降低50%显存):load_in_4bit=True
预热机制:启动后执行dummy prompt预加载KV Cache

四、实施流程与优化策略
1、标准化部署路径:
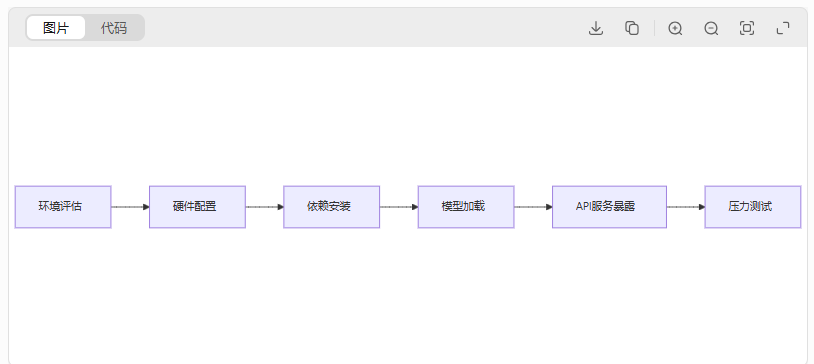
graph LR
A[环境评估] --> B[硬件配置]
B --> C[依赖安装]
C --> D[模型加载]
D --> E[API服务暴露]
E --> F[压力测试]
2、企业级优化方案:
高并发处理:
使用vLLM异步批处理(batch_size=32)提升吞吐量
通过Nginx负载均衡部署多实例
灾备设计:
每日增量备份模型权重至异地存储
基于Ansible实现配置自动化回滚
性能监控:
Prometheus采集GPU利用率/QPS
Grafana设置阈值告警(显存>90%时触发)
五、合规与安全体系构建
1、构建三级防护体系:


六、运维管理与持续迭代
1、版本升级
通过内网Harbor仓库管理Docker镜像版本
采用Canary发布策略:5%流量测试新模型→全量切换
2、模型迭代
反馈闭环:部署API回流通道收集bad cases
增量训练:每月更新领域知识库(医疗/法律等)
3、成本控制
使用Unsloth R1工具压缩模型体积(精度损失<2%)
弹性扩缩容:业务低谷期关闭50%推理节点
结语
DeepSeek私有化部署是企业构建AI核心能力的战略投资。成功关键在于:硬件配置与模型规模的精准匹配、安全合规的体系化设计、持续迭代的反馈机制。随着《生成式AI服务管理暂行办法》实施(2025年4月起),私有化部署将成为企业智能化转型的合规基线,建议优先采用模块化架构为未来升级预留空间。