RAG-Gym:一个用于优化带过程监督的代理型RAG的统一框架
传统RAG架构依赖于静态检索,这限制了它们在需要顺序信息检索的复杂问题上的有效性。而代理型推理和搜索提供了一种更具适应性的方法,但大多数现有方法都严重依赖于提示工程。
为了解决这个问题,本文[1]介绍了RAG-Gym,这是一个通过在每个搜索步骤进行细致的过程监督来增强信息检索代理的统一优化框架。
主要贡献如下:
- 介绍了RAG-Gym,这是一个用于优化带过程监督的代理型RAG的统一框架。
- 提出了ReSearch,这是一种新颖的代理架构,它将答案推理和搜索相结合,实现了超越现有基线的最新性能。
- 证明了使用训练有素的过程奖励模型作为验证器可以显著提高搜索代理的性能。
- 提供了对代理型RAG中过程监督来源、奖励模型的可转移性以及扩展规律的全面分析。
RAG-Gym框架
i) 概述
- RAG-Gym将知识密集型问答任务表述为嵌套马尔可夫决策过程(MDP)。
- 通过在每个时间步骤随机采样动作候选,并使用外部注释者选择最佳动作来收集过程奖励数据。
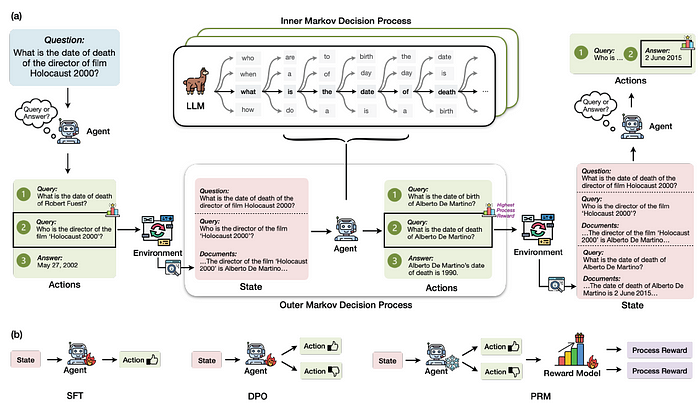
- 在RAG-Gym中实现了不同的过程监督方法。
ii) 知识密集型问答作为嵌套MDP
外层MDP旨在将各种语言代理设计推广到知识密集型问题上,其过程如下:
a) 状态空间S
- 在每个时间步骤t,状态st∈S包括原始问题Q和信息检索历史Ht。表示为:st=(Q,Ht),其中Ht={(q1,D1),…,(qt−1,Dt−1)}是信息检索查询q1,…,qt−1及其对应的由环境返回的文档D1,…,Dt−1的历史记录。
- 状态空间S是所有可能状态的集合:
S = I × P ( A q × D ) ∗ × A p S = I \times \mathcal{P}(A_q \times D)^* \times A_p S=I×P(Aq×D)∗×Ap
其中I是问题空间,Aq是所有可能搜索查询的空间,D是所有文档的空间。
b) 动作空间A
- 在每个时间步骤t,动作at可以是一个搜索查询或对原始问题的预测答案。
- 因此,我们定义动作空间A=Aq∪Ap,其中Aq是所有可能查询的集合,Ap表示可能答案的集合。
c) 信息检索环境
- RAG-Gym中外层MDP的环境由一个信息检索(IR)系统驱动,该系统以搜索查询qt作为输入,并返回一组相关文档Dt作为输出。
- IR系统可以表示为从Aq到P(D)的映射,其中P(D)是D的幂集。
- 检索过程由底层文本检索器和特定检索设置(例如,返回的文档数量)决定。
d) MDP工作流程
- 对于给定的问题Q,MDP从初始状态s1=(Q,∅)开始。在每个步骤t,从代理的策略πf(θ)(·|st)中采样at,其中πf(θ):S→Δ(A)定义了给定状态的动作分布。
- 代理的策略包括θ,表示基础语言模型的参数,以及一个代理特定的函数f,表示如何利用基础LLM策略。
- 然后通过追加(qt,Dt)来更新历史记录至Ht+1,状态转换为st+1=(Q,Ht+1)。否则,如果at∈Ap,则当前剧集被视为完成,MDP终止。
e) 奖励
- 对于外层MDP,剧集的奖励由最终预测的正确性决定。
- 状态-动作对(st,at)的即时奖励为:
r ( s t , a t ) = { 1 , if a t ∈ A p and the final answer is correct 0 , otherwise r(s_t, a_t) = \begin{cases} 1, & \text{if } a_t \in A_p \text{ and the final answer is correct} \\ 0, & \text{otherwise} \end{cases} r(st,at)={1,0,if at∈Ap and the final answer is correctotherwise
- 代理在外层MDP中的目标是在轨迹上最大化预期累积奖励:
max θ E τ ∼ π f ( θ ) [ ∑ t = 1 T γ t − 1 r ( s t , a t ) ] \max_{\theta} \mathbb{E}_{\tau \sim \pi_f(\theta)} \left[ \sum_{t=1}^{T} \gamma^{t-1} r(s_t, a_t) \right] θmaxEτ∼πf(θ)[t=1∑Tγt−1r(st,at)]
iii) 通过过程监督改进搜索代理
通过引入过程奖励,RAG-Gym能够更有效地调整LLM,使标记生成与高质量搜索行为保持一致。
a) 过程奖励数据收集
- 数据收集流程从轨迹采样开始,语言代理根据当前策略生成一系列动作。
- 在轨迹的每个步骤中,会提出多个候选动作,并根据预定义的评估标准选择最佳动作。
- 采用基于排名的评估框架,而不是分配数值分数,以确保一致性。
- 然后执行选定的动作,轨迹转换到下一个状态。
- 这个过程会反复迭代,直到轨迹终止。
- 为了确保质量,只有最终答案正确的轨迹才会被保留,这由结果奖励来确定。
b) 使用过程监督调整代理
(1) 监督式微调(SFT)
- 使用过程奖励中选择的动作来训练语言代理。
- 正式来说,SFT的目标是最小化给定状态下所选动作的负对数似然:
min θ − ∑ ( s t , a t ) ∈ D log π f ( θ ) ( a t ∣ s t ) \min_{\theta} -\sum_{(s_t, a_t) \in D} \log \pi_f(\theta)(a_t | s_t) θmin−(st,at)∈D∑logπf(θ)(at∣st)
其中D是带有过程奖励标记的状态-动作对的数据集。
(2) 直接偏好优化(DPO)
- 引入了一个对比学习框架,既包括所选动作也包括未选动作。
- 过程奖励数据被重新表述为偏好对(a+t,a−t),其中a+t是首选动作,a−t是相对于st的次优选动作。DPO目标是最小化以下损失:
min θ − ∑ ( s t , a t + , a t − ) ∈ D log π f ( θ ) ( a t + ∣ s t ) π f ( θ ) ( a t + ∣ s t ) + π f ( θ ) ( a t − ∣ s t ) \min_{\theta} -\sum_{(s_t, a^+_t, a^-_t) \in D} \log \frac{\pi_f(\theta)(a^+_t | s_t)}{\pi_f(\theta)(a^+_t | s_t) + \pi_f(\theta)(a^-_t | s_t)} θmin−(st,at+,at−)∈D∑logπf(θ)(at+∣st)+πf(θ)(at−∣st)πf(θ)(at+∣st)
(3) 过程奖励建模(PRM)
- 训练一个单独的奖励模型rϕ(st,at),根据收集的数据预测过程奖励。
- 目标是最小化对比损失,评估首选动作相对于次优选动作的质量:
min ϕ − ∑ ( s t , a t + , a t − ) ∈ D log r ϕ ( s t , a t + ) r ϕ ( s t , a t + ) + r ϕ ( s t , a t − ) \min_{\phi} -\sum_{(s_t, a^+_t, a^-_t) \in D} \log \frac{r_{\phi}(s_t, a^+_t)}{r_{\phi}(s_t, a^+_t) + r_{\phi}(s_t, a^-_t)} ϕmin−(st,at+,at−)∈D∑logrϕ(st,at+)+rϕ(st,at−)rϕ(st,at+)
推理与搜索(ReSearch)代理
推理与搜索(ReSearch)代理在一个统一的、以答案为导向的框架中整合了推理和搜索。
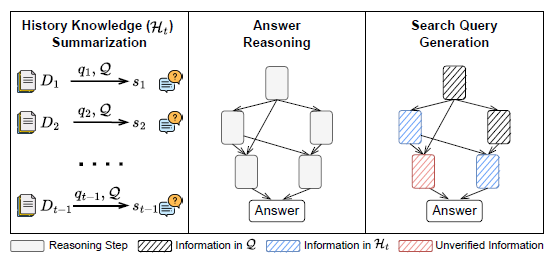
i) 历史知识总结
- 给定状态st,其中包含原始问题Q和历史Ht={(q1,D1),…,(qt−1,Dt−1)},代理首先将检索到的文档总结为对应查询的结构化回应,形成精炼的知识表示H′t:
H′t={(q1,m1),…,(qt−1,mt−1)}
- 总结步骤过滤掉了无关信息,缓解了长文本处理的挑战,使代理能够在构建答案时专注于最相关的事实。
ii) 答案推理
- 使用这个精炼的知识H′t,代理进行结构化推理,推断出问题的候选答案。
- 然后它会检查推理步骤,并判断所有主张是否都基于历史记录得到了充分的支持。
- 如果代理确定答案推理中的所有主张都得到了检索到的证据的支持,它就会将答案作为最终动作输出。
- 否则,它会识别出未经验证的主张,这些是没有足够理由支持的陈述,基于现有证据。
iii) 搜索查询生成
- 未经验证的主张成为生成下一个搜索查询的基础,该查询专门设计用于检索缺失的信息。
- 从这个查询中检索到的文档被添加到Ht中,然后重复推理过程,直到所有主张都得到验证或检索预算耗尽。
结果
i) 过程监督方法的比较
- 下表显示了使用Llama-3.1–8B-Instruct实现的各种代理及其在RAG-Gym中使用不同过程监督方法调整的版本的性能
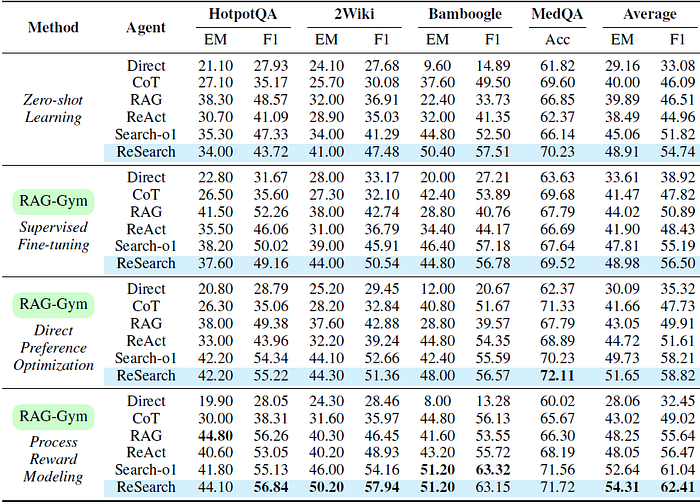
- 与零样本学习(ZSL)基线相比,过程监督在所有代理中都一致地提高了性能,证明了其在增强中间推理和查询生成方面的有效性。
- 在三种过程监督算法中,PRM总体上取得了最佳结果,与ZSL基线相比,最高提高了25.6%(ReAct;平均F1)。
ii) ReSearch与其他代理的比较
- 结果还表明,ReSearch在零样本学习设置以及带有过程监督的设置中都始终优于其他代理。
- 未经调整的ReSearch就实现了强大的零样本性能,证明了明确将答案推理与查询生成对齐的有效性。
- 使用过程奖励模型,ReSearch实现了最新性能,在不同数据集上平均EM得分为54.31%,平均F1得分为62.41%。
iii) 奖励模型的可转移性
- 下图突出了使用基于Llama-3.1–8B的过程奖励模型的ReSearch代理与GPT-4o-mini的性能提升
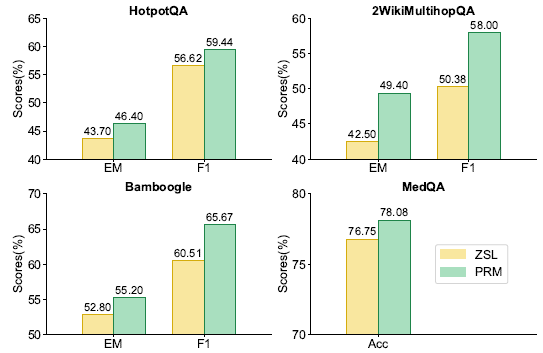
- 使用奖励模型进行动作选择在所有任务中都带来了持续的提升,证明了PRM在不同LLMs中有效选择高质量动作的可转移性。
分析
i) 不同奖励来源的比较
- 四位领域专家对200个MedQA问题进行了标注。在一个奖励模型上,用GPT-4o标注的剩余800个训练问题进行训练,将其偏好与领域专家的偏好进行了比较。
- 下表显示了MedQA中领域专家偏好与不同来源奖励估计之间的一致性
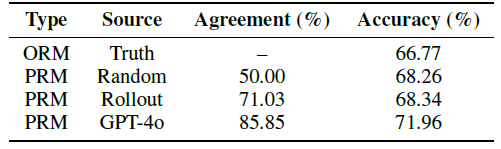
- 用GPT-4o标注训练的奖励模型与人类偏好达成了一致性最高(85.85%),显著优于Math-Shepherd中引入的基于rollout的方法(71.03%)。这表明GPT-4o标注与人类在这个背景下的推理和决策非常接近。
ii) 训练时间扩展
- 下图显示了使用不同数量训练样本调整的过程奖励模型的ReSearch代理的性能。
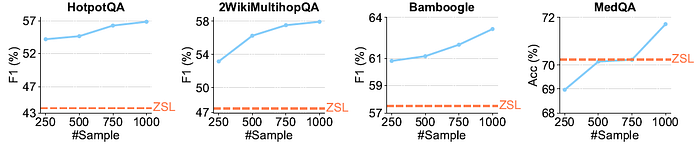
- 结果表明,随着训练样本数量的增加,ReSearch的性能有所提升,但随着样本规模的增长,收益趋于收敛。
iii) 推理时间扩展
- 下图显示了我们的推理时间扩展研究结果,以ReSearch作为测试代理。
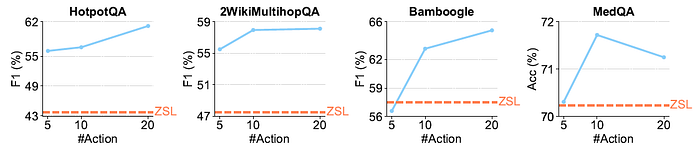
- 在多个基准测试中观察到一致的趋势,即增加采样动作的数量通常可以提高性能。
结论
- 介绍了RAG-Gym,这是一个通过过程监督优化推理和搜索代理的框架,并介绍了ReSearch,这是一种将答案推理与搜索查询生成统一起来的代理架构。
- 实验证明RAG-Gym在知识密集型任务上提高了搜索代理的性能,ReSearch始终优于基线。
- 证明了使用LLMs作为过程奖励评判员的有效性,训练有素的奖励模型在不同LLMs上的可转移性,以及ReSearch在训练和推理过程中的扩展模式。
论文:https://arxiv.org/abs/2502.13957
代码:https://github.com/RAG-Gym/RAG-Gym
参考文献:
- RAG-Gym: Optimizing Reasoning and Search Agents with Process Supervision by Xiong et al. arXiv:2502.13957