Dify智能问数大模型Text2SQL流程编排从0到1完整过程
目的
本教程旨在展示怎么用Dify配置智能问数(自然语言方式提问,返回SQL结果)。
依赖
Dify 1.2.0
Ollama 0.7.0
大模型qwen3:8b、deepseek-r1:7b、 qwen2.5-coder:latest
先Dify在市场里下载Ollama插件
步骤
创建聊天流程
1、创建聊天编排chatflow,指定应用的名称。
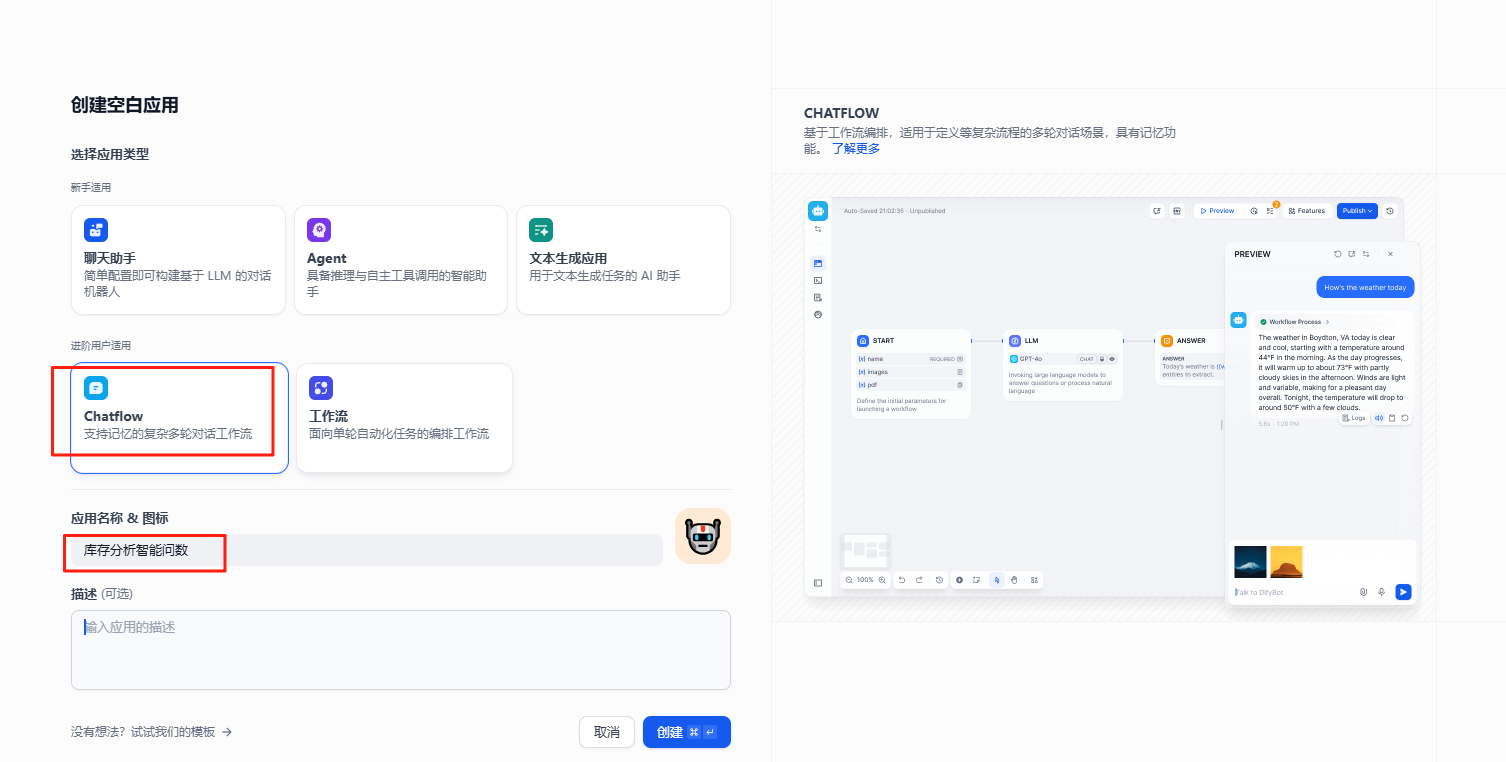
新增时间插件
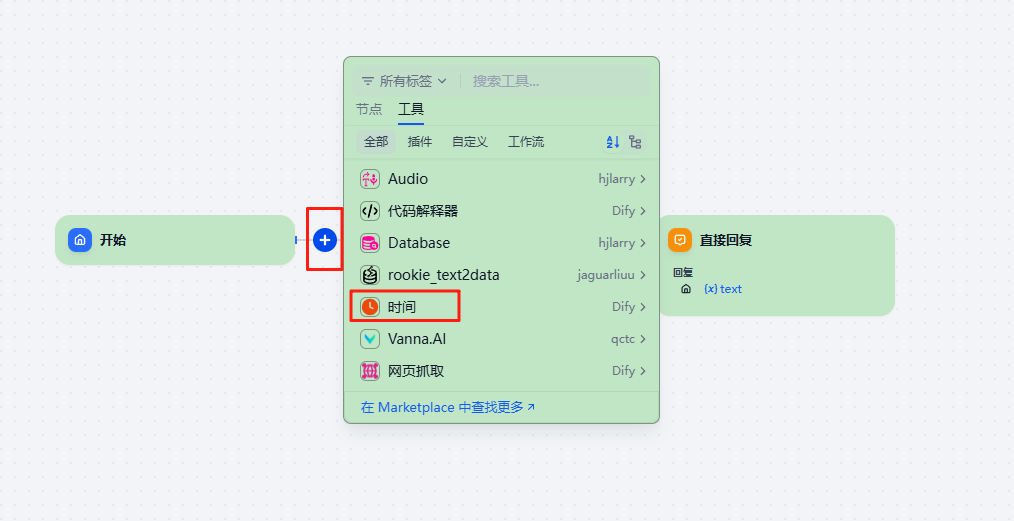
2、点击默认的流程中开始和LLM节点的加号 “+”新增选择工具里的“时间”插件。
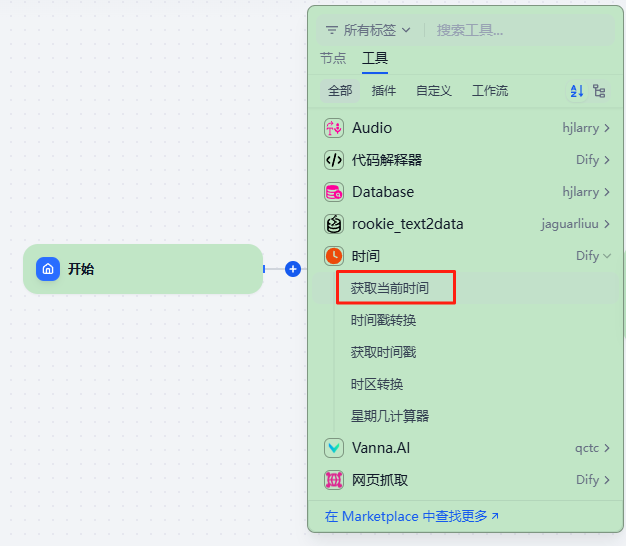
选择时间里的获取当前时间。
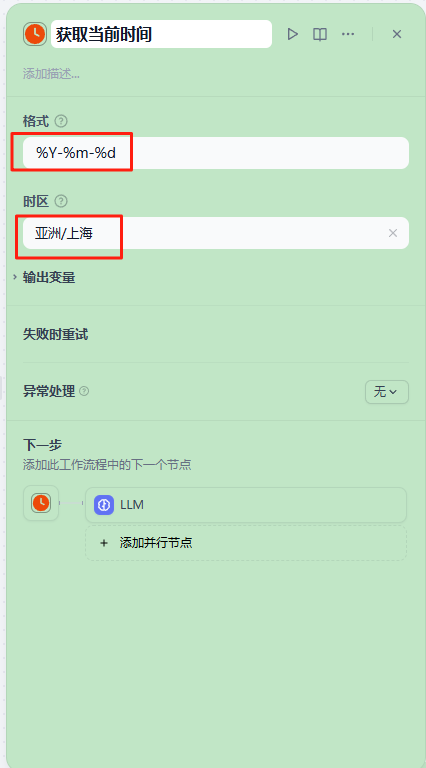
点击“获取当前日期”节点,修改时间格式和时区分别为:
%Y-%m-%d
亚洲/上海
配置LLM
如果当前Dify没有配置“模型供应商”,需点击右上角用户,然后点击“设置”
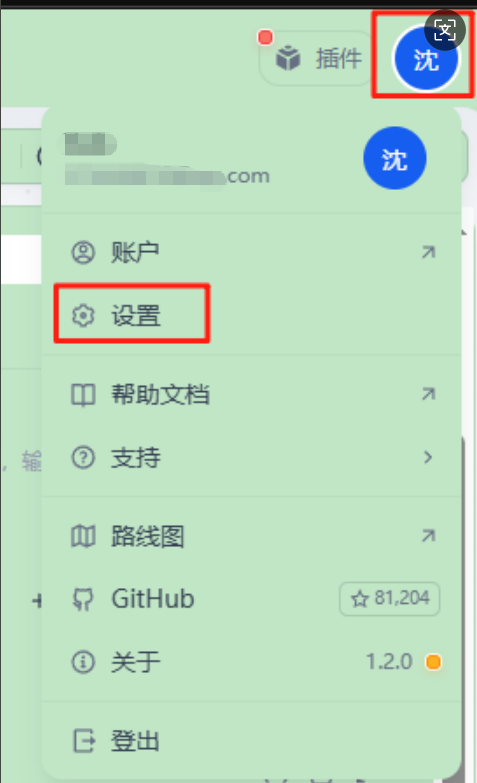
选中模型供应商,点击添加模型,
输入模型名称 qwen3:8b,基础URL http://host.docker.internal:11434,
注:基础URL可改为实际地址,当前环境是Ollama装在windows上,dify在WSL里的docker镜像内。
后点击保存。
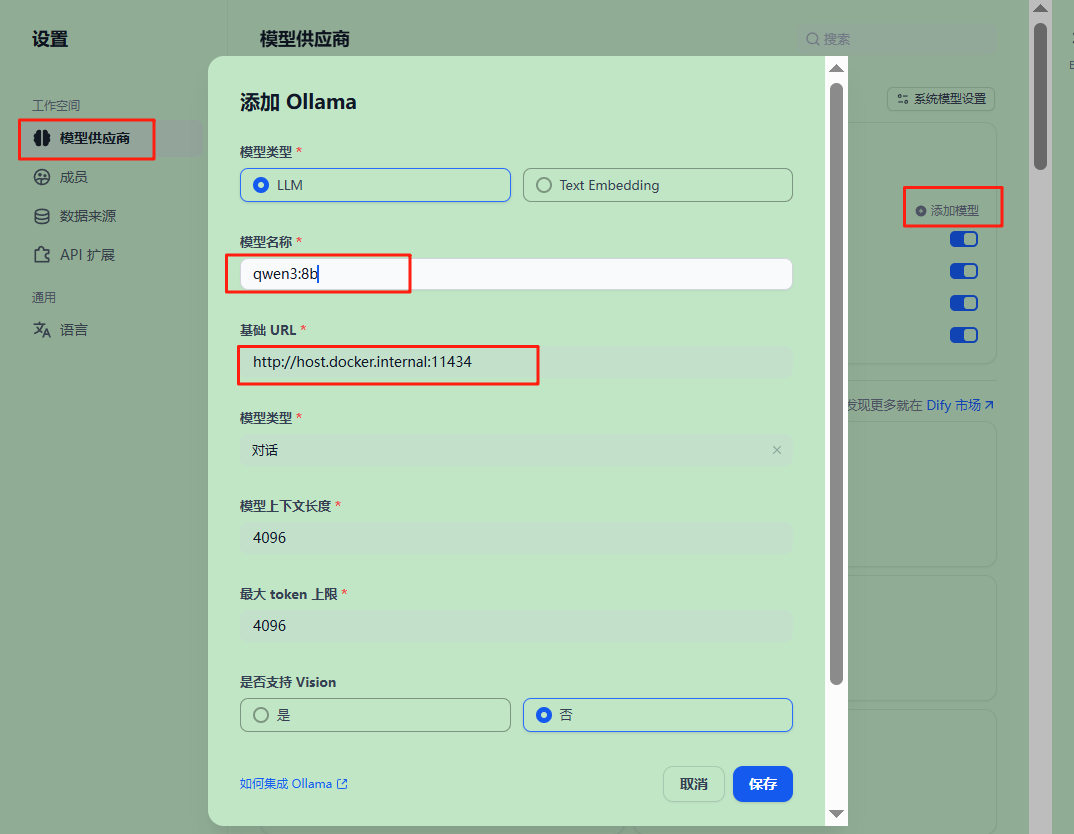
如果LLM已经配置好,可以从模型下拉框里选择配置的大模型。如qwen2.5-coder:latest
配置System提示词
详细内容见下:
## 角色
你是一位精通MySQL数据库SQL查询语句的专家。
## 任务
根据提供的数据库的表结构,将用户输入的内容转换为MySQL数据库的SQL查询语句,函数用Mysql里的函数。
## 数据库的表结构
商品表结构如下:
CREATE TABLE t_product (
id INT PRIMARY KEY AUTO_INCREMENT COMMENT '商品ID',
name VARCHAR(50) NOT NULL COMMENT '商品名称',
unit VARCHAR(10) NOT NULL COMMENT '单位'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='商品表';
仓库表结构如下:
CREATE TABLE t_warehouse (
id INT PRIMARY KEY AUTO_INCREMENT COMMENT '仓库ID',
name VARCHAR(50) NOT NULL COMMENT '仓库名称'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='仓库表';
库存表结构如下:
CREATE TABLE t_inventory (
id INT PRIMARY KEY AUTO_INCREMENT COMMENT '记录ID',
product_id INT NOT NULL COMMENT '商品ID,关联product_id表的id',
product_name VARCHAR(50) NOT NULL COMMENT '商品名称(冗余)',
warehouse_id INT NOT NULL COMMENT '仓库ID,关联t_warehouse表的id',
quantity INT NOT NULL DEFAULT 0 COMMENT '库存数量',
FOREIGN KEY (product_id) REFERENCES t_product(id),
FOREIGN KEY (warehouse_id) REFERENCES t_warehouse(id),
UNIQUE KEY (product_id, warehouse_id) COMMENT '防止重复记录'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='库存表';
入库记录表结构如下:查询时,要加is_deleted = 0
CREATE TABLE t_stock_in (
id INT PRIMARY KEY AUTO_INCREMENT COMMENT '记录ID',
product_id INT NOT NULL COMMENT '商品ID,关联product_id表的id',
product_name VARCHAR(50) NOT NULL COMMENT '商品名称(冗余)',
warehouse_id INT NOT NULL COMMENT '仓库ID,关联t_warehouse表的id',
quantity INT NOT NULL COMMENT '入库数量',
operator VARCHAR(20) COMMENT '操作人',
batch_no VARCHAR(30) COMMENT '批次号',
create_time datetime(3) DEFAULT CURRENT_TIMESTAMP(3) COMMENT '入库时间',
is_deleted TINYINT(1) DEFAULT 0 COMMENT '删除标记:0-正常 1-已删除',
FOREIGN KEY (product_id) REFERENCES t_product(id),
FOREIGN KEY (warehouse_id) REFERENCES t_warehouse(id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='入库记录表';
## 系统参数
当前时间:
## 要求
1. 需要严格按照数据库的表结构来生成。
2. 将生成的SQL语句封装到一个JSON数组中,格式如下:
``` {
"sql": "SELECT product_id FROM t_inventory"
}
```
3. 确保SQL查询语法符合PostgreSQL语法。
4. 不返回思考过程和中间结果,给出最终的一个SQL
点击LLM节点右侧的“+”新增节点,这里选择“代码执行”,重命名节点为SQL提取。
配置“输入变量”为上一步LLM的输出text变量。
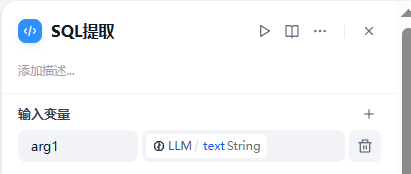
编写SQL提取代码
SQL提取的python代码,详见:
from typing import Dict, Any
import json
import redef main(arg1: str) -> Dict[str, Any]:"""从JSON字符串中提取SQL语句并返回结构化字典参数:arg1: 包含SQL语句的输入字符串返回:包含以下可能键的字典:- result: 提取到的SQL语句(可能为None)- status: 执行状态(success/error)- error: 错误描述(仅status为error时存在)- raw_extract: 原始提取内容(调试用)"""response = {"result": None}try:# 尝试解析外层JSONtry:data = json.loads(arg1)except json.JSONDecodeError:data = None# 优先从结构化数据中查找if isinstance(data, dict):# 从text字段的代码块中提取if 'text' in data:code_blocks = re.findall(r'```json\n(.*?)\n```',data['text'],re.DOTALL)for block in code_blocks:try:inner_data = json.loads(block.strip())if isinstance(inner_data, dict) and 'sql' in inner_data:response.update({"result": inner_data['sql']})return responseexcept json.JSONDecodeError:continue# 直接检查sql字段if 'sql' in data:response.update({"result": data['sql']})return response# 兜底方案:原始字符串正则匹配sql_pattern = r'"sql"\s*:\s*"((?:\\"|[^"])*)"'match = re.search(sql_pattern, arg1, re.DOTALL)if match:# 处理转义字符raw_sql = match.group(1).replace('\\"', '"')response.update({"result": raw_sql,})return responsereturn responseexcept Exception as e:response.update({"error": f"Processing error: {str(e)}","raw_extract": arg1[:100] + "..." if len(arg1) > 100 else arg1})return response定义输出变量为result
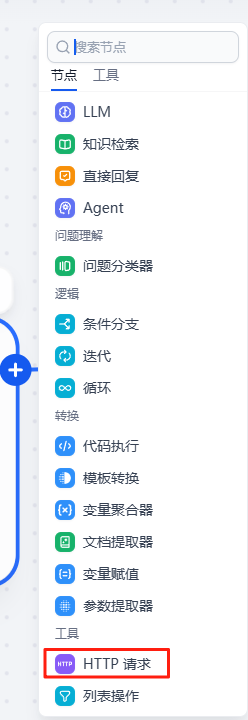
新增HTTP请求
该请求是执行数据库用,点击SQL提取节点右侧“+”号,新增工具“HTTP请求”
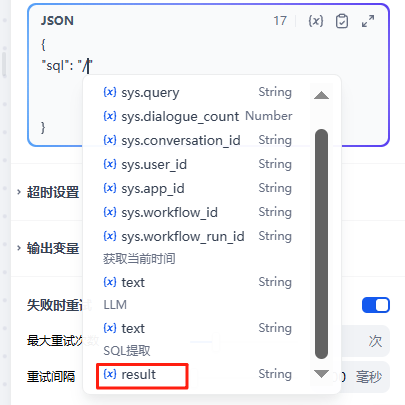
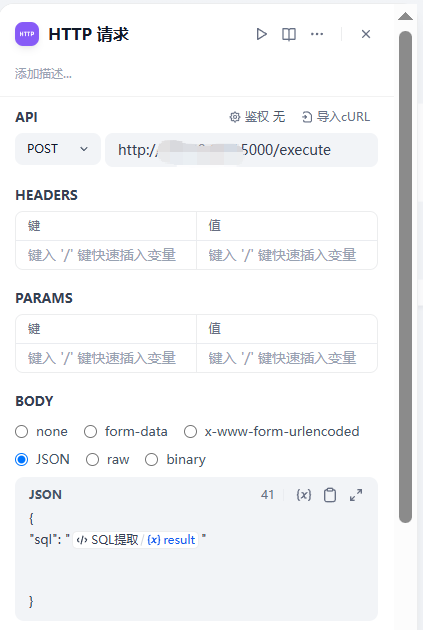
配置请求类型、URL地址和参数
这里如POST
URL:http://172.20.10.10:5000/execute
参数输入/并选择SQL提取里的result:
{
"sql": "/"
}
新增直接回复
http请求节点后边点“+”新增直接回复节点
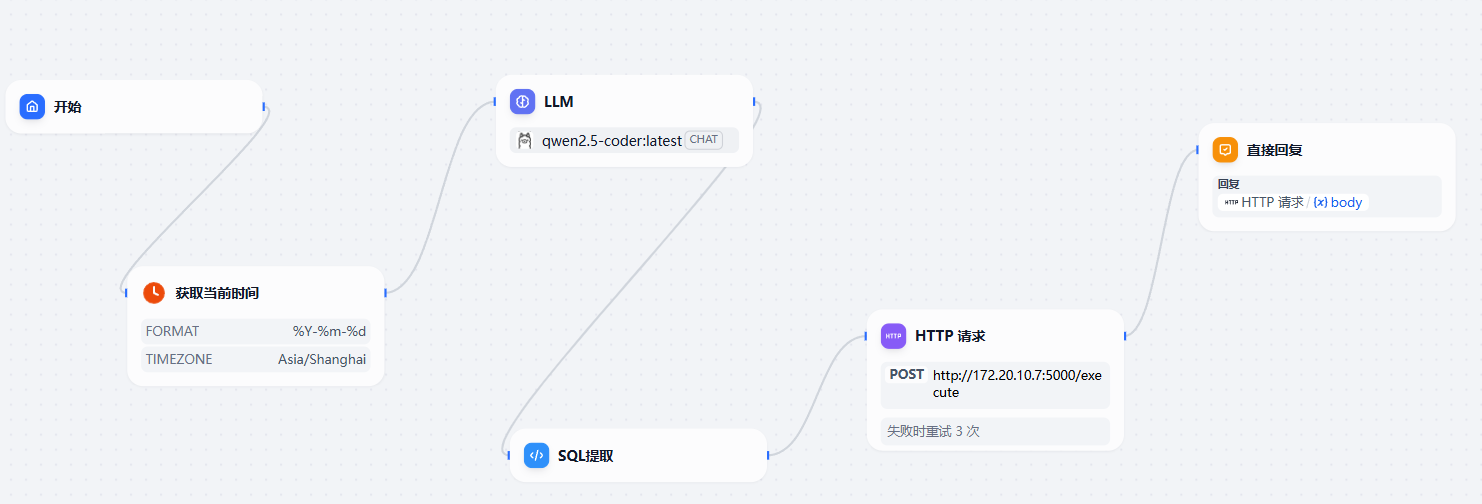
完整流程
附录
from flask import Flask, request, jsonify
import re
import logging
from logging.handlers import RotatingFileHandler
import configparser
import os
from datetime import datetime, dateapp = Flask(__name__)# 定义错误代码(数值类型)
SUCCESS = 0
MISSING_REQUEST = 1001
EMPTY_SQL = 1002
INVALID_QUERY_TYPE = 1003
DANGEROUS_SQL = 1004
EXECUTION_ERROR = 1005
ENDPOINT_NOT_FOUND = 1006
INTERNAL_ERROR = 1007
DB_CONFIG_NOT_FOUND = 1008
UNSUPPORTED_DB_TYPE = 1009 # 新增:不支持的数据库类型错误# 配置日志系统
log_handler = RotatingFileHandler('sql_service.log', maxBytes=1000000, backupCount=5)
log_formatter = logging.Formatter('%(asctime)s - %(levelname)s - %(message)s')
log_handler.setFormatter(log_formatter)
app.logger.addHandler(log_handler)
app.logger.setLevel(logging.INFO)# 读取数据库配置
config = configparser.ConfigParser()
config_file = 'config.ini'
if not os.path.exists(config_file):app.logger.error(f"Configuration file {config_file} not found")raise FileNotFoundError(f"Configuration file {config_file} not found")config.read(config_file,encoding='utf-8')# 存储所有数据库配置的字典
DB_CONFIGS = {}
# 默认配置名
DEFAULT_CONFIG = 'postgres'# 读取所有数据库配置节
for section in config.sections():try:db_type = config.get(section, 'db_type', fallback='postgres').lower()config_data = {'db_type': db_type,'host': config.get(section, 'host'),'user': config.get(section, 'user'),'password': config.get(section, 'password'),'database': config.get(section, 'database'),'port': config.get(section, 'port', fallback=''),}# 为不同数据库类型设置默认端口if not config_data['port']:if db_type == 'postgres':config_data['port'] = '5432'elif db_type == 'mysql':config_data['port'] = '3306'DB_CONFIGS[section] = config_dataapp.logger.info(f"Database configuration '{section}' (Type: {db_type}) loaded successfully")except (configparser.NoOptionError, configparser.NoSectionError) as e:app.logger.error(f"Error in section {section}: {str(e)}")# 检查至少有一个有效配置
if not DB_CONFIGS:app.logger.error("No valid database configurations found")raise RuntimeError("No valid database configurations found")def is_select_query(sql):"""检查是否为SELECT查询语句"""# 移除注释(单行和多行)cleaned_sql = re.sub(r'--.*?$|/\*.*?\*/', '', sql, flags=re.DOTALL | re.MULTILINE).strip()# 检查是否以SELECT或WITH开头return cleaned_sql.lower().startswith(('select', 'with'))def validate_sql(sql):"""基础SQL验证(防止非查询操作)"""forbidden_keywords = ['insert', 'update', 'delete', 'drop', 'alter', 'create','truncate', 'grant', 'revoke', 'commit', 'rollback',# PostgreSQL 危险函数'pg_sleep', 'pg_read_file', 'pg_write_file', 'dblink',# MySQL 危险函数'sleep', 'load_file', 'into outfile', 'into dumpfile','master.', 'slave.', 'sys_exec', 'sys_eval']pattern = r'\b(' + '|'.join(forbidden_keywords) + r')\b'return not re.search(pattern, sql.lower(), re.IGNORECASE)def execute_query(sql, db_config_name):"""执行SQL查询并返回结果,自动格式化日期时间类型"""# 获取数据库配置db_config = DB_CONFIGS.get(db_config_name)if not db_config:return None, f"Database configuration '{db_config_name}' not found"db_type = db_config['db_type']try:if db_type == 'postgres':import psycopg2conn = psycopg2.connect(host=db_config['host'],user=db_config['user'],password=db_config['password'],dbname=db_config['database'],port=db_config['port'])conn.set_session(readonly=True)elif db_type == 'mysql':import mysql.connectorfrom mysql.connector import Errorconn = mysql.connector.connect(host=db_config['host'],user=db_config['user'],password=db_config['password'],database=db_config['database'],port=db_config['port'])# MySQL设置只读模式cursor = conn.cursor()cursor.execute("SET SESSION TRANSACTION READ ONLY")cursor.close()else:return None, f"Unsupported database type: {db_type}"cursor = conn.cursor()cursor.execute(sql)# 获取列名columns = [col[0] for col in cursor.description]# 处理结果并格式化日期字段results = []for row in cursor.fetchall():row_dict = {}for i, (col_name, value) in enumerate(zip(columns, row)):if isinstance(value, datetime):row_dict[col_name] = value.strftime('%Y-%m-%d %H:%M:%S')elif isinstance(value, date):row_dict[col_name] = value.strftime('%Y-%m-%d')else:# 处理MySQL的DECIMAL类型if hasattr(value, '__float__'):row_dict[col_name] = float(value)else:row_dict[col_name] = valueresults.append(row_dict)cursor.close()conn.close()return results, Noneexcept ImportError as e:error_msg = f"Database driver not installed for {db_type}: {str(e)}"app.logger.error(error_msg)return None, error_msgexcept Exception as e:# 捕获特定数据库错误if db_type == 'postgres':import psycopg2if isinstance(e, psycopg2.Error):return None, f"PostgreSQL error: {e.pgerror}"elif db_type == 'mysql':import mysql.connectorif isinstance(e, mysql.connector.Error):return None, f"MySQL error: {e.msg}"return None, f"Database error: {str(e)}"@app.route('/execute', methods=['POST'])
def execute_sql():"""执行SQL的API端点"""data = request.get_json()if not data:app.logger.error("Empty request received")return jsonify({"success": False,"code": MISSING_REQUEST,"message": "Request body must be JSON","data": None}), 400sql = data.get('sql', '').strip()# 获取数据库配置名,默认为 'postgres'db_config_name = data.get('db_config', DEFAULT_CONFIG)# 验证输入if not sql:app.logger.error("Empty SQL statement received")return jsonify({"success": False,"code": EMPTY_SQL,"message": "SQL parameter is required","data": None}), 400# 检查数据库配置是否存在if db_config_name not in DB_CONFIGS:app.logger.error(f"Database configuration '{db_config_name}' not found")return jsonify({"success": False,"code": DB_CONFIG_NOT_FOUND,"message": f"Database configuration '{db_config_name}' not found","available_configs": list(DB_CONFIGS.keys())}), 400# 检查是否为SELECT查询if not is_select_query(sql):app.logger.warning(f"Non-SELECT query attempted: {sql}")return jsonify({"success": False,"code": INVALID_QUERY_TYPE,"message": "Only SELECT queries are allowed","sql_sample": sql[:100] + "..." if len(sql) > 100 else sql}), 400# 验证SQL安全性if not validate_sql(sql):app.logger.warning(f"Potential dangerous SQL detected: {sql}")return jsonify({"success": False,"code": DANGEROUS_SQL,"message": "SQL contains forbidden keywords","sql_sample": sql[:100] + "..." if len(sql) > 100 else sql}), 400# 执行查询results, error = execute_query(sql, db_config_name)if error:app.logger.error(f"SQL execution failed with config '{db_config_name}': {sql} | Error: {error}")return jsonify({"success": False,"code": EXECUTION_ERROR,"message": "SQL execution failed","details": error,"sql_sample": sql[:100] + "..." if len(sql) > 100 else sql,"db_config": db_config_name}), 400app.logger.info(f"SQL executed successfully with config '{db_config_name}': {sql}")# 构建标准化响应response_data = {"success": True,"code": SUCCESS,"message": "Query executed successfully","db_config": db_config_name,"db_type": DB_CONFIGS[db_config_name]['db_type'],"data": {"count": len(results),"results": results}}# 添加列名信息(如果有结果)if results:response_data["data"]["columns"] = list(results[0].keys())else:response_data["data"]["columns"] = []response_data["message"] = "Query executed successfully but returned no results"return jsonify(response_data), 200@app.errorhandler(404)
def not_found(error):app.logger.warning(f"Endpoint not found: {request.path}")return jsonify({"success": False,"code": ENDPOINT_NOT_FOUND,"message": "Endpoint not found","requested_path": request.path}), 404@app.errorhandler(500)
def internal_error(error):app.logger.error(f"Internal server error: {error}")return jsonify({"success": False,"code": INTERNAL_ERROR,"message": "Internal server error","details": str(error)}), 500if __name__ == '__main__':app.run(host='0.0.0.0', port=5000, debug=False)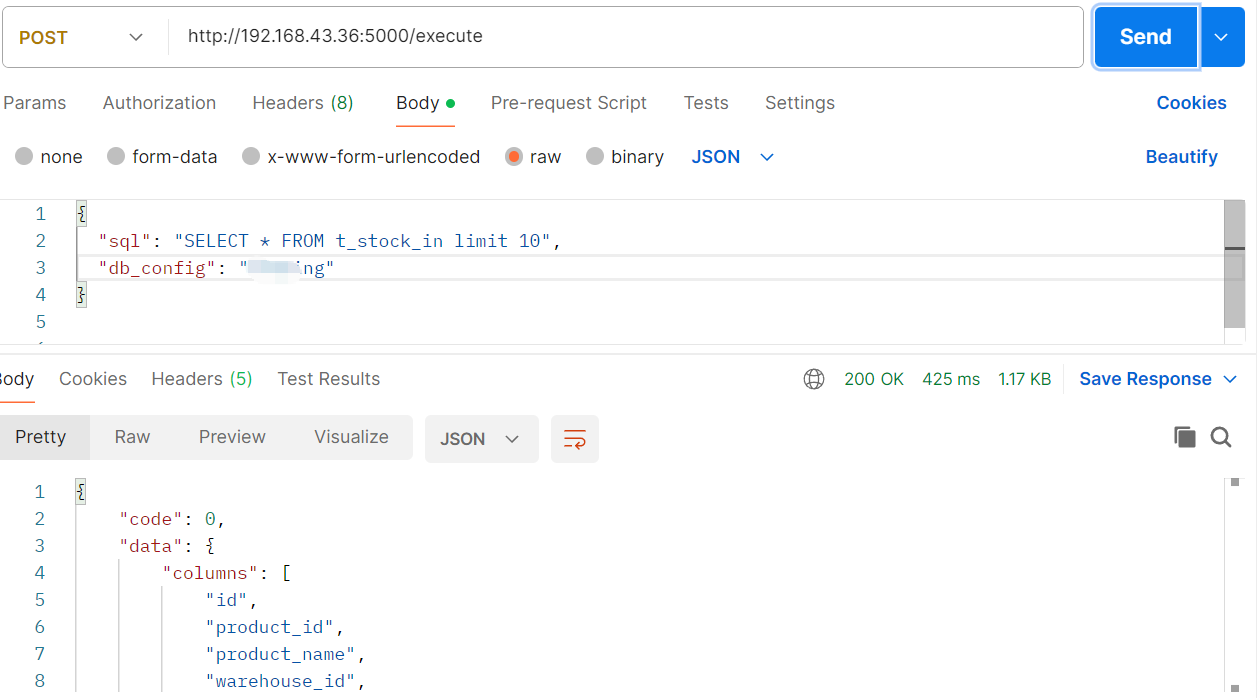
注:建表语句及提示词参考:https://blog.csdn.net/beilingcc/article/details/147162349