空间数据分析和空间统计工具库PySAL入门
空间数据分析是指利用地理信息系统(GIS)技术和空间统计学等方法,对空间数据进行处理、分析和可视化,以揭示数据之间的空间关系和趋势性,为决策者提供有效的空间决策支持。空间数据分析已经被广泛运用在城市规划、交通管理、环境保护、农业种植、自然资源管理等领域,成为现代社会中重要的数据分析手段。
1. PySAL空间数据分析工具库介绍
1.1. 概况
当涉及空间数据分析和空间统计时,PySAL(Python Spatial Analysis Library)是一个常用的 Python 库,它提供了丰富的空间数据分析工具和统计方法。PySAL是一个基于Python进行探索性空间数据分析的开放源码库,是由亚利桑那州立大学GeoDa Center for Geospatial Analysis and Computation赞助的社区项目,以下是其主要特点和功能:
-
空间数据结构: PySAL 提供了用于表示空间数据的数据结构,例如点、线、面等几何对象,以及空间权重矩阵、空间连接图等。这些数据结构可以方便地用于空间数据的存储、处理和分析。
-
空间权重矩阵: PySAL 支持多种空间权重矩阵的构建和处理,包括 Queen、Rook、Distance 等不同类型的空间权重矩阵。这些权重矩阵可以用于衡量空间数据中地理单元之间的空间关联程度。
-
空间自相关分析: PySAL 提供了用于计算莫兰指数、Getis-Ord 统计量等空间自相关指标的工具,用于评估空间数据中的空间相关性和集聚模式。
-
空间回归分析: PySAL 支持空间回归模型的构建和分析,包括空间滞后模型、空间误差模型等,用于探索空间数据中的空间依赖关系和空间异质性。
-
空间聚类分析: PySAL 提供了用于空间聚类分析的工具,例如 DBSCAN、K-means 等算法,用于发现空间数据中的集群和簇。
-
空间插值和空间可视化: PySAL 支持空间插值方法的应用,用于估计空间数据在未观测位置的值。此外,PySAL 还提供了用于空间数据可视化的工具,如地图绘制、空间图层叠加等。
PySAL 是一个功能强大且灵活的空间数据分析工具库,适用于地理信息系统、城市规划、环境科学、社会学等领域的空间数据分析和空间统计研究。通过使用 PySAL,可以更好地理解空间数据的特征和规律,支持空间决策和规划的制定。
1.2. 开源库构成
在 PySAL(Python Spatial Analysis Library)中,lib、explore、model 和 viz 是不同模块,各自提供了一些功能:
-
lib(Library):
lib模块提供了一些核心的功能和工具,用于空间数据的处理、空间权重矩阵的构建、空间距离计算等基本操作。- 在
lib模块中,你可以找到用于处理空间数据的数据结构、空间权重矩阵的构建方法、空间距离的计算函数等。
-
explore(Exploratory Spatial Data Analysis):
explore模块提供了用于探索性空间数据分析的工具和方法,包括莫兰指数、Getis-Ord 统计量等空间自相关指标的计算方法。- 使用
explore模块,你可以进行空间自相关分析、空间集群分析等,从而了解空间数据中的空间模式和空间关联性。
-
model(Spatial Econometrics Models):
model模块提供了一些空间计量经济学模型的实现,包括空间回归模型、空间滞后模型等。- 使用
model模块,你可以构建和估计空间计量经济学模型,用于分析空间数据中的空间依赖关系和空间异质性。
-
viz(Visualization):
viz模块提供了用于空间数据可视化的工具和方法,包括地图绘制、空间图层叠加、空间数据的可视化效果等。- 使用
viz模块,你可以将空间数据在地图上进行可视化展示,直观地呈现空间数据的分布特征和空间关联性。
这些模块提供了 PySAL 中常用的功能和工具,可以帮助你进行空间数据分析、空间统计和空间建模等任务。你可以根据自己的需求选择适合的模块和方法来处理和分析空间数据。
开源地址:https://github.com/pysal/pysal。
1.3. 核心模块libpysal
libpysal是Python空间分析库核心库,它提供了四个模块,构成了PySAL系列的空间分析工具:
- 空间权重: libpysal.weights
- 输入和输出:libpysal.io
- 计算几何学:libpysal.cg
- 内置示例数据集 libpysal.examples
开源地址:https://github.com/pysal/。
2. PySAL安装
我在windows10环境中,直接使用pip安装。
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pysal
3. 空间数据分析案例
本文使用PySAL在线教程中探索莫兰指数可视化案例,其数据集为Guerry 。
Guerry 数据集是由法国统计学家 André-Michel Guerry 在 1833 年创建的。该数据集包含了法国各个行政区的社会经济数据,包括人口统计、犯罪率、教育水平等指标。这些数据被用来分析社会现象,并成为统计学和社会科学研究中的经典数据集之一。
Guerry 数据集最著名的用途是在统计图表的历史上,它被用来展示了统计图表中数据之间的相关性。这个数据集的独特之处在于,它是早期社会科学研究中首次采用统计方法来分析社会现象的尝试之一,对后来的社会科学研究产生了深远影响。
3.1. 数据项解释
这个表中各列的含义如下:
| 序号 | 名称 | 说明 |
|---|---|---|
| 1 | dept | 部门(部门的标识符或名称) |
| 2 | Region | 地区(部门所在地区的标识符或名称) |
| 3 | Dprtmnt | 部门(部门的标识符或名称,与 ‘dept’ 列可能表示相同的信息) |
| 4 | Crm_prs | 犯罪人数(人口中的犯罪人数) |
| 6 | Litercy | 识字率(人口中的识字率) |
| 7 | Donatns | 慈善捐款(人均慈善捐款数额) |
| 8 | Infants | 婴儿死亡率(婴儿的死亡率) |
| 9 | Suicids | 自杀率(自杀的比率) |
| 10 | MainCty | 主要城市(部门所在的主要城市或城镇) |
| 11 | Wealth | 财富指数(部门或地区的财富水平) |
| 12 | Commerc | 商业指数(部门或地区的商业繁荣程度) |
| 13 | Clergy | 牧师数目(部门或地区的牧师数量) |
| 14 | Crm_prn | 犯罪率(犯罪率的另一种表示方式) |
| 15 | Infntcd | 婴儿死亡数目(婴儿的死亡数量) |
| 16 | Dntn_cl | 慈善捐款类别(慈善捐款的具体类别) |
| 17 | Lottery | 彩票支出(彩票支出的金额或比率) |
| 18 | Desertn | 遗弃(地区的遗弃现象或问题) |
| 19 | Instrct | 指导(教育或指导资源的可用性) |
| 20 | Prsttts | 圣职人员(地区的宗教或教堂官员数量) |
| 21 | Distanc | 距离(部门或地区之间的距离) |
| 22 | Area | 面积(部门或地区的面积大小) |
| 23 | Pop1831 | 人口(1831年的人口数量) |
| 24 | geometry | 几何数据(可能是地理空间数据中的几何信息) |

3.2. 数据获取
Guerry 数据集不在默认的安装包和github中,需要远程下载。
import libpysal
# Downloading Remote Datasets
balt_url = libpysal.examples.get_url('Guerry')
balt_url
获取地址为:'https://geodacenter.github.io/data-and-lab//data/guerry.zip'。手工下载此压缩包,解压到Guerry文件夹中。
3.3. 实验之旅
%matplotlib inlineimport matplotlib.pyplot as plt
from libpysal.weights.contiguity import Queen
from libpysal import examples
import numpy as np
import pandas as pd
import geopandas as gpd
import os
import splotgdf = gpd.read_file('Guerry/Guerry.shp')
# 输出数据见上表
gdf
y = gdf['Donatns'].values
w = Queen.from_dataframe(gdf)
w.transform = 'r'
这段代码涉及地理空间数据分析的基本步骤,以下是对每行代码的解释:
-
y = gdf['Donatns'].values:- 这一行从地理数据框架(geodataframe)
gdf中选择了名为 ‘Donatns’ 的列,并将其转换为 NumPy 数组(array)。 - 这样做是为了提取感兴趣的变量(在这种情况下是慈善捐款)以便进行进一步的分析和建模。
- 这一行从地理数据框架(geodataframe)
-
w = Queen.from_dataframe(gdf):- 这一行使用
Queen.from_dataframe方法从地理数据框架gdf中创建了一个 Queen 邻接权重矩阵(spatial weights matrix)。 - Queen 邻接权重矩阵描述了地理空间中各个区域之间的邻接关系,即哪些区域是相邻的。
- 这一行使用
-
w.transform = 'r':- 这一行设置了权重矩阵
w的转换方式为行标准化(row-standardized)。 - 行标准化是一种常见的操作,它将权重矩阵的每一行都除以该行的权重总和,以确保每个单位(即行)的权重之和为 1。
- 行标准化可以使权重矩阵更容易解释和应用,尤其在一些空间分析和空间统计方法中。
- 这一行设置了权重矩阵
from esda.moran import Moranw = Queen.from_dataframe(gdf)
moran = Moran(y, w)
moran.Iprint("Moran's I 值为:",moran.I)
print("随机分布假设下Z检验值为:",moran.z_rand)
print("随机分布假设下Z检验的P值为:",moran.p_rand)
print("正态分布假设下Z检验值为:",moran.z_norm)
print("正态分布假设下Z检验的P值为:",moran.p_norm)
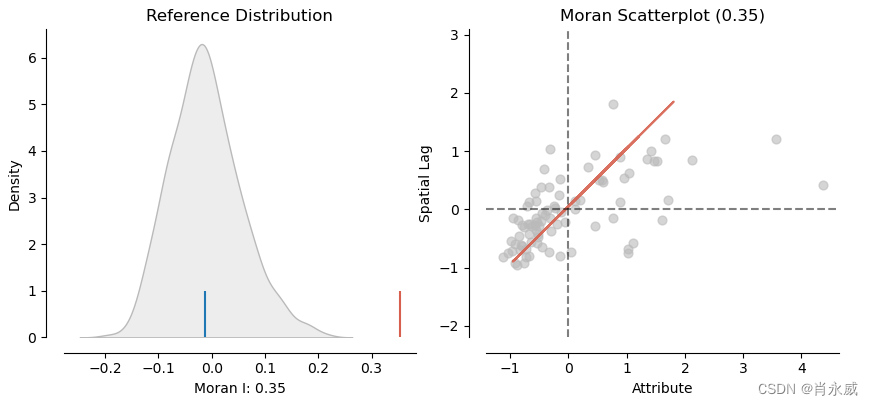
Moran's I 值为: 0.3533613255848606随机分布假设下Z检验值为: 5.378368837667692随机分布假设下Z检验的P值为: 7.516371034073079e-08正态分布假设下Z检验值为: 5.235533901743425正态分布假设下Z检验的P值为: 1.6450862400833017e-07
-
Moran’s I 值(0.3533613255848606):这是莫兰指数,用于衡量空间自相关的程度。它的取值范围在 -1 到 1 之间。如果值接近 1,则表示正的空间自相关(即相似的值聚集在一起),如果接近 -1,则表示负的空间自相关(即相异的值聚集在一起),如果接近 0,则表示没有空间自相关。
-
随机分布假设下Z检验值(5.378368837667692):这是基于随机分布假设进行的 Z 检验的统计值。它衡量了观察到的莫兰指数是否显著地不同于在随机分布情况下预期的值。较大的 Z 值表明观察到的空间自相关性更高。
-
随机分布假设下Z检验的P值(7.516371034073079e-08):这是 Z 检验的 p 值,表示观察到的莫兰指数在随机分布假设下的显著性水平。p 值越小,表明观察到的空间自相关性越显著。
-
正态分布假设下Z检验值(5.235533901743425):这是基于正态分布假设进行的 Z 检验的统计值。它类似于随机分布假设下的 Z 检验值,用于检验观察到的莫兰指数是否显著地不同于在正态分布情况下预期的值。
-
正态分布假设下Z检验的P值(1.6450862400833017e-07):这是 Z 检验的 p 值,表示观察到的莫兰指数在正态分布假设下的显著性水平。与随机分布假设下的 p 值一样,p 值越小,表明观察到的空间自相关性越显著。
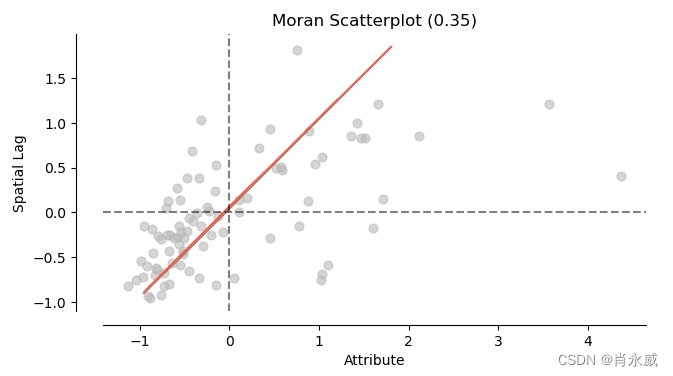
综合来看,莫兰指数值为 0.353 表明存在一定程度的正的空间自相关性,而随机分布假设下的 p 值和正态分布假设下的 p 值都非常小(小于 0.05),因此我们可以拒绝空间自相关性不存在的原假设,得出结论认为观察到的空间自相关性是显著的。
在这种情况下,莫兰指数 ( I = 0.353 ) 虽然不算非常大,但其所对应的 p 值非常小,远小于一般的显著性水平(比如 ( \alpha = 0.05 ))。这表示观察到的空间自相关性在统计上是显著的,即我们有足够的证据来拒绝空间自相关性不存在的原假设。
因此,显著性水平很低的 p 值表明我们对观察到的空间自相关性是非常有信心的,这增强了我们对结果的信任程度。
from splot.esda import moran_scatterplot
fig, ax = moran_scatterplot(moran, aspect_equal=True)
plt.show()
from splot.esda import plot_moranplot_moran(moran, zstandard=True, figsize=(10,4))
plt.show()
from splot.esda import plot_local_autocorrelation
plot_local_autocorrelation(moran_loc, gdf, 'Donatns')
plt.show()
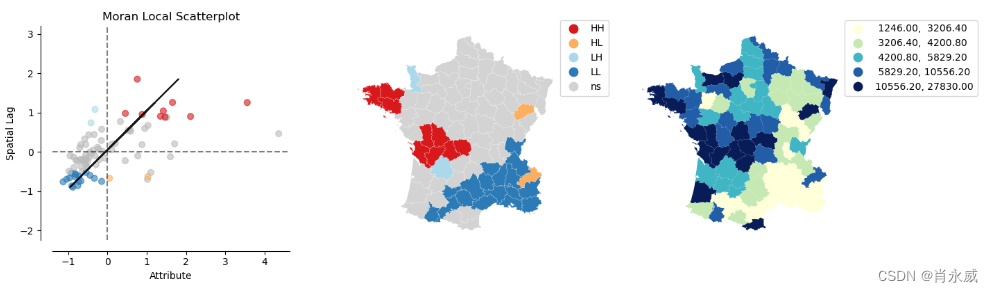
通常情况下,通过不同的可视化方式来观察统计结果或者解释这些结果会更容易理解。在这里,例如,我们可以看到一个莫兰散点图(Moran Scatterplot)、LISA 聚类图和区域填充图(choropleth map)的静态可视化。
-
莫兰散点图(Moran Scatterplot):莫兰散点图用于展示空间自相关性的模式。它通常在 x 轴和 y 轴上分别表示变量的观测值,然后通过散点图来展示空间相关性的程度。通过观察散点图的分布模式,我们可以更直观地了解变量之间的空间关系。
-
LISA 聚类图:LISA(Local Indicators of Spatial Association)聚类图是用于展示空间聚类模式的工具。它显示了地理空间上不同区域之间的局部空间相关性,即是否存在局部空间集聚或分散的现象。通过不同的颜色和形状来表示不同类型的空间关系,比如高高(HH)、低低(LL)、高低(HL)、低高(LH)等。
-
区域填充图(Choropleth Map):区域填充图是一种常见的地图类型,用于展示地理空间上的统计数据。不同区域根据其对应的统计值着色,颜色的深浅或者颜色的种类表示不同的数值范围或者类别,使得观察者能够直观地了解地理空间上的数据分布情况。
综合来看,通过这些可视化工具,我们可以更全面地理解空间数据分析的结果,从不同角度和不同视觉效果来观察数据,有助于发现隐藏在数据背后的模式和规律。
4. 小结
当你有二维坐标的 POI 数据时,你可以使用 PySAL 进行各种空间分析。虽然 PySAL 最初是为地理空间数据设计的,但它也可以处理二维坐标数据,例如对于城市中的 POI 数据。
以下是一些你可以使用 PySAL 进行空间分析的示例:
-
空间权重矩阵的构建: 根据 POI 数据的二维坐标,你可以构建空间权重矩阵来衡量不同 POI 之间的空间关系。常见的空间权重矩阵包括邻近权重矩阵和距离权重矩阵。你可以使用 PySAL 的
weights模块来构建这些权重矩阵。 -
空间自相关分析: 使用 PySAL,你可以计算莫兰指数等空间自相关指标,评估 POI 数据中的空间相关性和集聚模式。你可以使用
esda模块中的Moran类来计算莫兰指数。 -
空间聚类分析: 你可以使用 PySAL 进行空间聚类分析,发现城市中不同 POI 的空间集群和簇。你可以使用
cluster模块中的聚类算法,如 DBSCAN、K-means 等。 -
空间可视化: PySAL 提供了丰富的空间可视化工具,你可以将二维坐标的 POI 数据在地图上进行可视化展示。你可以使用
matplotlib等库来绘制地图,并结合 PySAL 提供的空间分析结果来进行可视化展示。
总体而言,尽管 PySAL 最初是为地理空间数据设计的,但它也可以处理二维坐标数据,并提供了丰富的空间分析工具和方法,可以帮助你理解和分析二维空间数据中的模式、关联和趋势。
参考:
[1]. 酱肉包-. Python空间分析| 01 利用Python计算全局莫兰指数(Global Moran’s I).CSDN博客. 2023.02
[2]. rgb2gray. ESDA in PySal (5):空间数据的探索性分析:空间自相关. CSDN博客. 2023.10
[3]. http://pysal.org/notebooks/viz/splot/esda_morans_viz.html
[4]. https://pysal.org/libpysal/notebooks/examples.html