HBase数据导入——使用 ImportTsv 将数据导入hbase
HBase数据导入——使用 ImportTsv 将数据导入hbase
- 1.测试数据生成
- 使用shell 生成简易 csv文件
- 使用zd生成测试数据的csv文件 (仅用于生成测试数据,可跳过此步骤)
- 使用zd 执行
- zd的配置文件
- 生成的数据
- 2.将csv文件传到目标主机(在同机器操作的跳过此步骤)
- 3.将文件上传至HDFS,并修改相应的读写权限
- 4.使用ImportTsv 将数据导入hbase
- 语法
- 参数
- 执行导入
使用 ImportTsv 将数据导入hbase
1.测试数据生成
使用shell 生成简易 csv文件
int=1while (($int <= 18)); doecho ${int}','${int} >> int.csvlet "int++"done
生成的数据
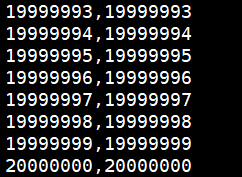
使用zd生成测试数据的csv文件 (仅用于生成测试数据,可跳过此步骤)
https://www.zendata.cn/
使用zd 执行
nohup ./zd -d do_test_10w.yaml -n 20000000 -o output\out_do_2000w.csv &

zd的配置文件
title: 数据开放测试数据-2000w
desc: 数据开放测试数据-2000wauthor: qinon
version: 1.0fields:- field: user_name fields: - field: part1from: name.cn.family.v1select: namewhere: "double='false'"postfix:- field: part2from: name.cn.given.v1where: "double='true'"select: name- field: user_id range: 1-100000000 prefix: "id_" postfix: "" divider: ","- field: client_uuid# from: uuid.v1.yaml# use: length32_random_no_separatormode: rfields:- field: part1from: uuid.prefix.yamluse: uuid_prefix_time- field: part2from: uuid.prefix.yamluse: uuid_prefix_info1- field: part3from: uuid.prefix.yamluse: uuid_prefix_info2- field: part4range: 0-9999999999999999format: "%016d" - field: msisdnfields: - field: field2.1range: 1- field: field2.2range: 3,5,7 - field: field2.3range: 1-999:Rformat: "%03d" - field: field2.4range: 1-999:Rformat: "%03d"- field: field2.5range: 1-999:Rformat: "%03d"- field: sum_month mode: rfields: - field: field2.1range: 2020-2021- field: field2.2range: 1-10format: "%02d" - field: user_email fields:- field: lettersfrom: name.letters.v1.yamluse: letterspostfix: "@"- field: esp_domainfrom: domain.esp.v1.yamluse: esp - field: city from: address.cn.v1.china # 从data/address/v1.xlsx文件中读取名为china的工作簿。select: city # 查询city字段。where: state like '%福建%' # 条件是省份包含山东。rand: true # 随机取数据- field: province from: address.cn.v1.china # 从data/address/v1.xlsx文件中读取名为china的工作簿。select: state # 查询city字段。where: state like '%福建%' # 条件是省份包含山东。 - field: user_status range: 1-9:R prefix: "" postfix: "" divider: "," - field: data_part value: " $user_id % 20" divider: ","
生成的数据
第一列将被默认为 rowkey,从第二列开始映射为columnFamily:column,需在mapreduce时指定映射关系。列数对不上时,将导致导入失败

2.将csv文件传到目标主机(在同机器操作的跳过此步骤)
scp 当前主机的源文件路径 目标主机用户名@ip:目标路径
随后输入密码开始传输。
未开启认证的:scp 当前主机的源文件路径 ip:目标路径
3.将文件上传至HDFS,并修改相应的读写权限
hdfs dfs -ls /
hdfs dfs -put /home/udapdev/out_do_10w.csv /dotest
-put 源 目标路径
改文件权限
hdfs dfs -chmod a+x /dotest/out_do_10w.csv
4.使用ImportTsv 将数据导入hbase
语法
hbase [类] [分隔符] [行键,列族] [表] [导入文件]
参数
类 org.apache.hadoop.hbase.mapreduce.ImportTsv
分隔符 ‘-Dimporttsv.separator=,’
行键,列簇 ‘-Dimporttsv.columns=HBASE_ROW_KEY,family:user_name’
csv 文件使用 【,】 分割,第一列默认为rowkey,从第二列开始指定。格式为 列簇:列名,csv文件中的列数要与 此处 rowkey、列簇:列名 的数据量对应。否则会导入失败。
表名: 非default 的要写明 namespace dotest:do_test_2000w
导入文件的路径为文件放置于hdfs上 的路径。
执行导入
./hbase org.apache.hadoop.hbase.mapreduce.ImportTsv '-Dimporttsv.columns=HBASE_ROW_KEY,family:user_id,family:client_uuid,family:msisdn,family:sum_month,family:user_email,family:city,family:province,family:user_status,family:data_part' '-Dimporttsv.separator=,' -Dimporttsv.skip.bad.lines=false dotest:do_test_10w /dotest/out_do_10w.csv
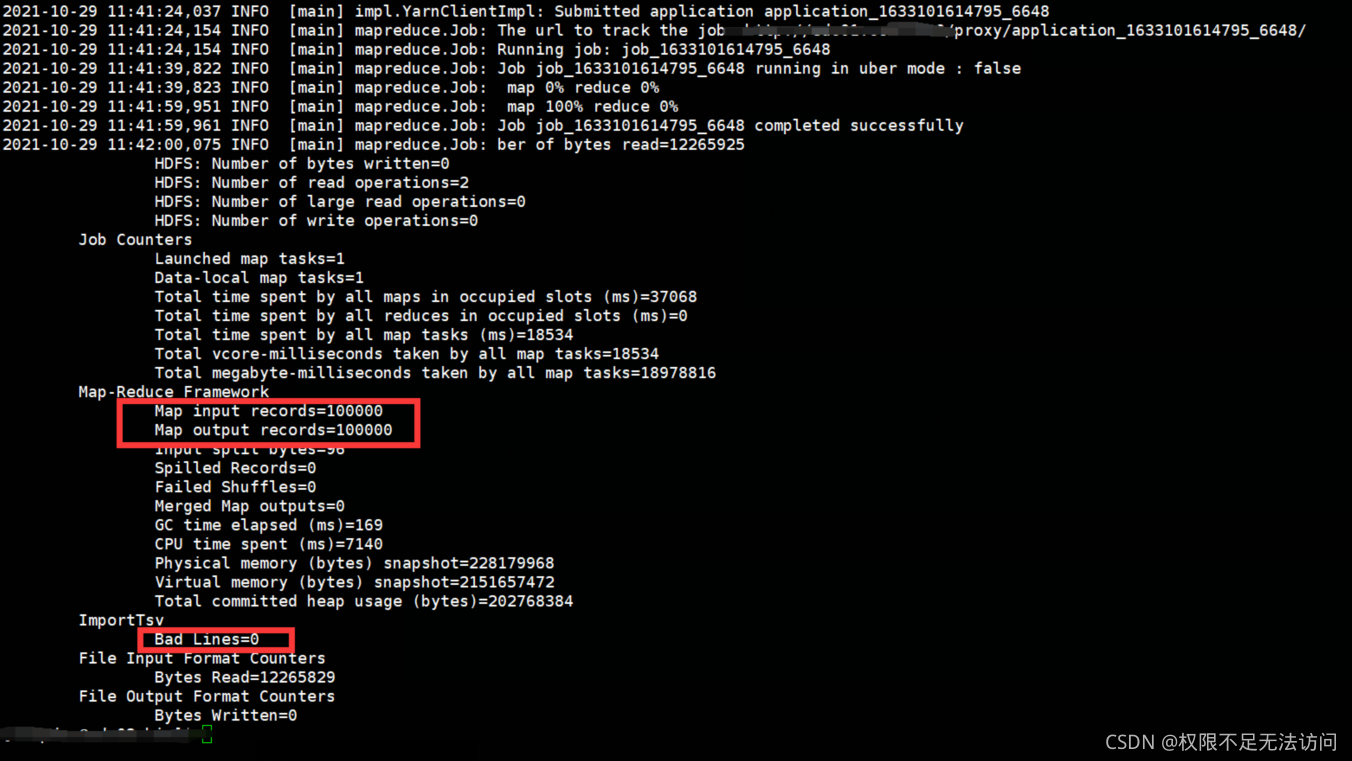
可看Map input records的数据量与导入的记录数是否一致,Bad Lines =0 为全部记录导入成功。
如出现 Bad Lines =记录数,大概是列数对不上,导入失败,可去检查 columns映射是否多写、漏写
'-Dimporttsv.columns=HBASE_ROW_KEY,family:user_id,family:client_uuid,family:msisdn,family:sum_month,family:user_email,family:city,family:province,family:user_status,family:data_part'
参考资料:
https://blog.csdn.net/gdkyxy2013/article/details/84300090
https://blog.csdn.net/weixin_33739523/article/details/92537856