大模型的开发应用(六):使用 Xtuner QLoRA 微调模型
这里写目录标题
- 0 前言
- 1 Xtuner 简介
- 1.1 主要特点
- 1.2 核心功能
- 1.3 优势与不足
- 1.4 安装
- 2 数据集格式
- 2.1 开源数据集
- 2.2 自定义数据集
- 2.3 数据集存放位置
- 3 微调大模型
- 3.1 Qwen1.5的QLoRA配置文件
- 3.2 修改配置文件
- (1)PART 1 基本设置
- (2)PART 2 模型与分词器设置
- (3)PART 3 数据集与导入器设置
- 3.3 运行配置文件
- 3.4 模型转换与合并
- 3.5 微调Qwen2.5
0 前言
前面的文章介绍了使用 LLaMA-Factory 对大模型进行 LoRA/QLoRA 微调,除了 LLaMA-Factory 之外,还有一款重要的大模型微调框架——Xtuner。截止2025年5月,最常用的就两款,LLaMA Factory 与 Xtuner,本篇文章主要介绍 Xtuner 的基本使用。
XTuner 是由上海人工智能实验室(InternLM 团队)开发的高效、灵活且功能全面的大语言模型(LLM)和多模态模型(VLM)微调工具库,旨在帮助开发者在有限的硬件资源下轻松完成大模型的微调任务。以下是其核心特点和功能:
1 Xtuner 简介
XTuner 是一个适合需要高效微调大模型的开发者的工具库,尤其适合希望在有限硬件条件下快速迭代模型的团队或个人。
文档
1.1 主要特点
-
高效性
- 低显存需求:仅需 8GB 显存即可微调 7B 参数量的模型(如 Llama2、Qwen 等),支持多节点跨设备微调 70B+ 大模型。
- 高性能优化:集成 FlashAttention、Triton kernels 等高效算子,并兼容 DeepSpeed 的 ZeRO 优化策略,显著提升训练效率。
-
灵活性
- 兼容主流模型:支持多种开源大语言模型(如 InternLM、Llama2、ChatGLM、Qwen 等)和多模态模型(如 LLaVA)。
- 数据格式灵活:支持 JSON、CSV 等任意数据格式,适配 Alpaca、MOSS、OpenAI 等主流指令微调数据集。
- 多算法支持:提供 QLoRA、LoRA(低秩适配)和全量参数微调等多种轻量化微调方法。
-
全能性
- 多任务支持:支持增量预训练、指令微调(SFT)、Agent 微调等任务。
- 全流程覆盖:从训练到部署无缝衔接,提供模型转换(如转为 HuggingFace 格式)、合并及性能评测工具(如 OpenCompass、VLMEvalKit)。
1.2 核心功能
- 轻量化微调:通过 QLoRA/LoRA 技术大幅降低显存消耗,适合消费级 GPU(如 8GB 显存)。
- 多模态支持:可对图文模型(如 LLaVA)进行微调,处理图像、文本等多模态数据。
- 一键训练:提供标准化配置文件,用户只需修改少量参数即可启动训练。
- 国产化适配:对国内主流模型(如 InternLM、Qwen)有良好支持。
1.3 优势与不足
-
优势:
- 高效、低成本,适合资源有限的开发者。
- 灵活适配多种模型和数据格式。
- 提供从训练到部署的完整工具链。
-
不足:
- 无可视化界面,依赖命令行操作。
- 官方仅提供 pip/源码安装方式,部署流程需手动配置。
1.4 安装
因为按照可编辑模式 -e 安装的时候,默认安装 PyTorch 最新版,而高版本 PyTorch(如 2.6+)与 bitsandbytes 不兼容,导致依赖链异常,所以在安装 xtuner 之前,建议先安装PyTorch 2.5 版本(我这里cuda是12.4版本,具体安装时,需要和本地的cuda版本对应):
pip install torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 --index-url https://download.pytorch.org/whl/cu124
接下来正式安装Xtuner,推荐源码安装:
bash git clone https://github.com/InternLM/xtuner.git cd xtuner pip install -e '.[all]' # 包含 DeepSpeed 和完整依赖
如果GitHub连不上,可以把 Github 仓库中的代码下载下来,然后传到服务器
输入 xtuner list-cfg ,能输出以下内容时,若能打印配置文件列表,则说明安装成功,下面是打印的一部分:
==========================CONFIGS===========================
baichuan2_13b_base_full_custom_pretrain_e1
baichuan2_13b_base_qlora_alpaca_e3
baichuan2_13b_base_qlora_alpaca_enzh_e3
baichuan2_13b_base_qlora_alpaca_enzh_oasst1_e3
baichuan2_13b_base_qlora_alpaca_zh_e3
baichuan2_13b_base_qlora_arxiv_gentitle_e3
baichuan2_13b_base_qlora_code_alpaca_e3
baichuan2_13b_base_qlora_colorist_e5
baichuan2_13b_base_qlora_lawyer_e3
baichuan2_13b_base_qlora_oasst1_512_e3
baichuan2_13b_base_qlora_oasst1_e3
baichuan2_13b_base_qlora_open_platypus_e3
baichuan2_13b_base_qlora_sql_e3
baichuan2_13b_chat_qlora_alpaca_e3
baichuan2_13b_chat_qlora_alpaca_enzh_e3
2 数据集格式
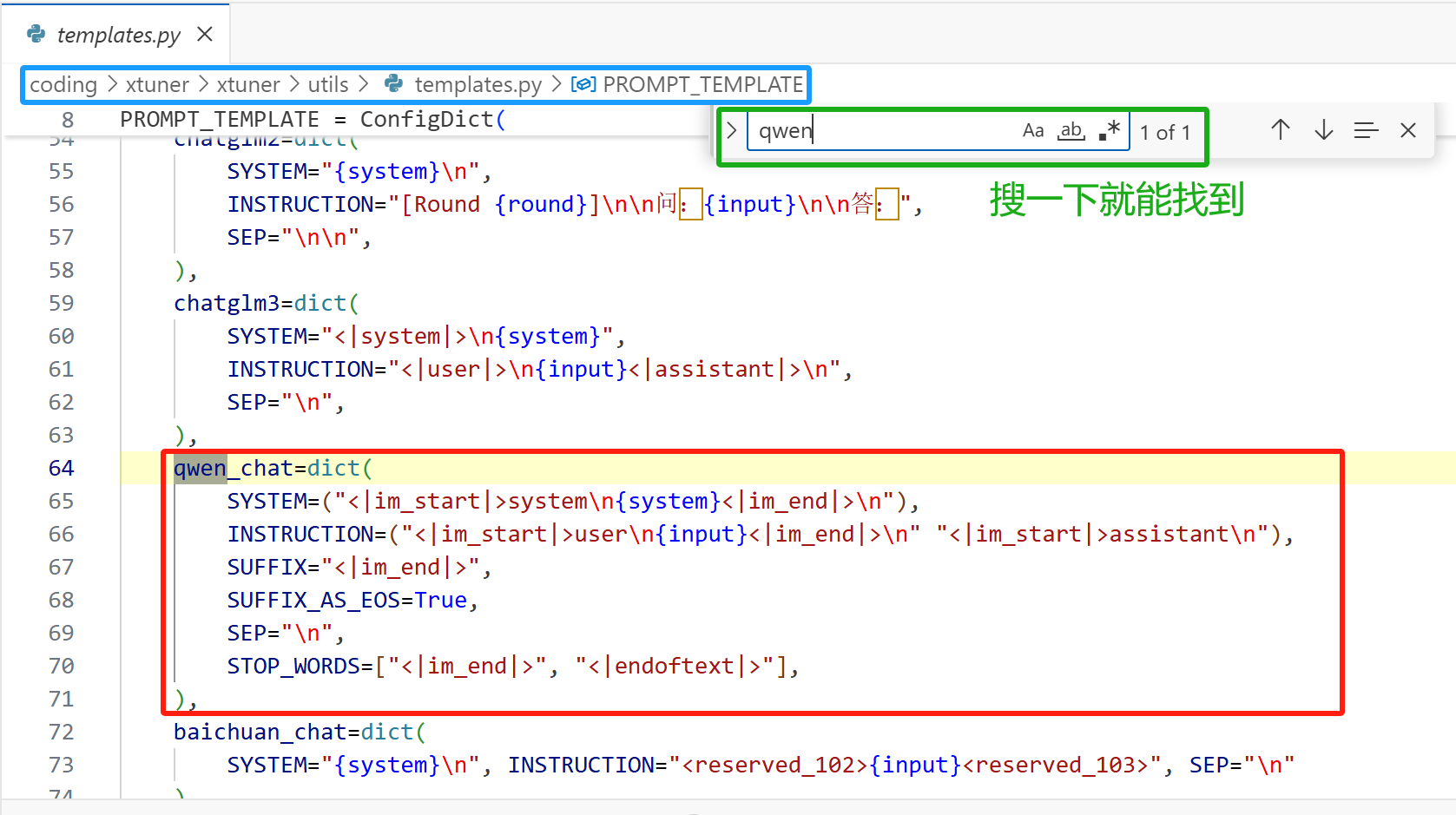
Xtuner 针对指令微调、预训练、多模态训练,都规定了格式,我们这里只看指令微调,相关信息在文档的如下图红框部分:
2.1 开源数据集
XTuner 内置了众多 map_fn (这里),可以满足大多数开源数据集的需要,所谓的开源数据集格式,指的是公开数据集所遵循的格式。此处我们罗列一些常用 map_fn 及其对应的原始字段和参考数据集:

我们打开 alpaca_map_fn 的参考数据集,可以看到它的格式:
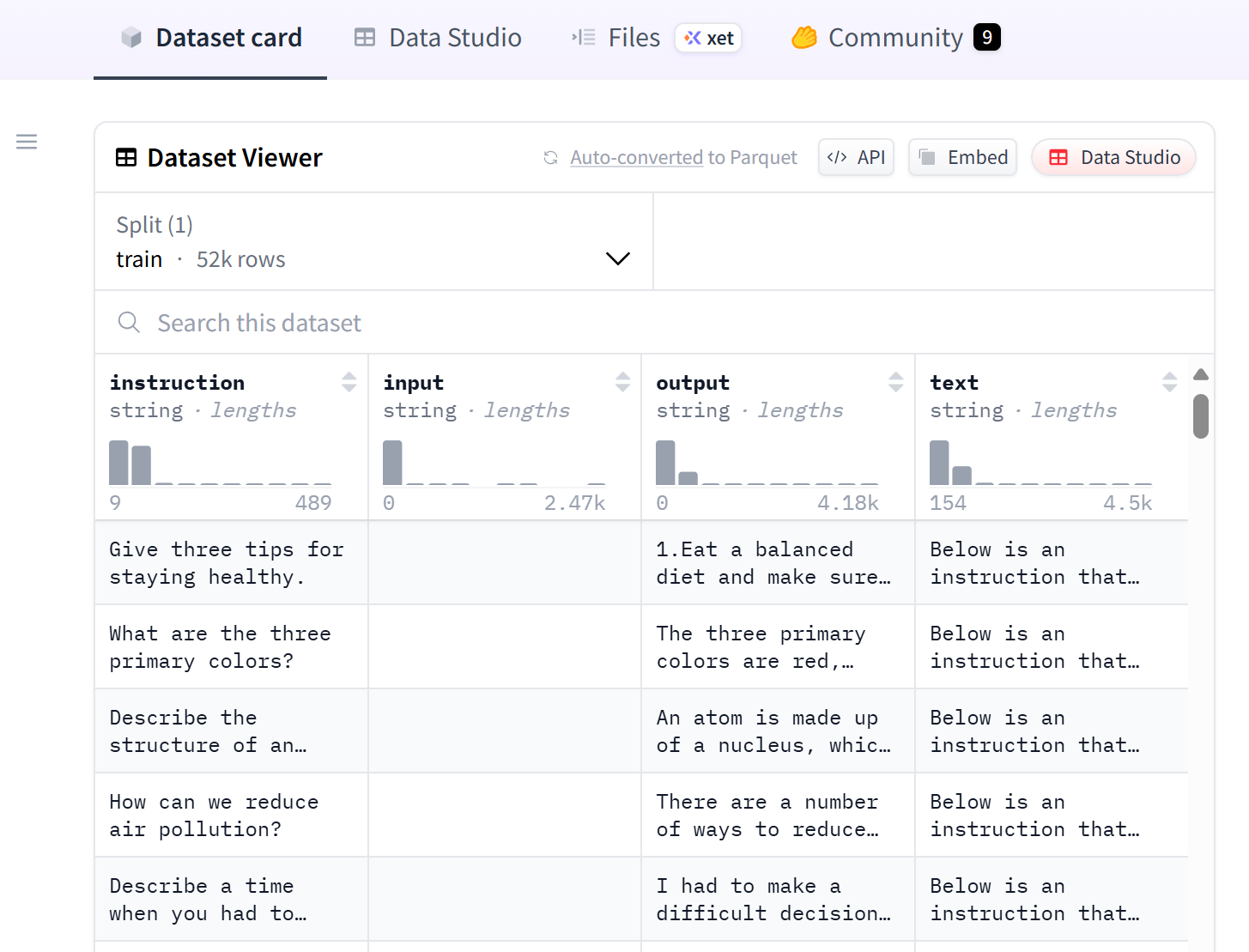
这个其实就是上篇文章介绍的 LLaMA Factory 中介绍的格式。
若使用开源数据集格式,那么需要在配置文件中配置 alpaca_map_fn 参数,这个后面会介绍。
2.2 自定义数据集
针对自定义数据集,Xtuner 推荐采用 OpenAI SFT 数据集格式作为统一的自定义数据集格式,详细格式如下:
[
# 单轮对话
{"messages": [{ "role": "system", "content": "xxx."},{ "role": "user", "content": "xxx." },{ "role": "assistant", "content": "xxx."}]
},
# 多轮对话
{"messages": [{ "role": "system", "content": "xxx." },{ "role": "user", "content": "xxx." },{ "role": "assistant", "content": "xxx.", "loss": False},{ "role": "user", "content": "xxx." },{ "role": "assistant", "content": "xxx.", "loss": True}]
}]
系统提示信息可以省略。每条数据除了 OpenAI 标准格式中的 role 字段和 content 字段外,XTuner 还额外扩充了一个 loss 字段,用于控制某轮 assistant 的输出不计算 loss。system 和 user 的 loss 默认为 False,assistant 的 loss 默认为 True。
2.3 数据集存放位置
我们在 xtuner 的根目录下新建一个名为 data 的文件夹,专门用于存放数据 :
3 微调大模型
我们要训练的模型,Xtuner 必须要先支持,进入到 xtuner/xtuner/configs/ 目录下,可以看到支持的模型系列:

常见的开源大模型,Xtuner基本上都是支持的,对于不在上面的模型,那就不支持了。
3.1 Qwen1.5的QLoRA配置文件
Xtuner 对模型的支持是有滞后性的,今天是2025年5月31日,Qwen3已经出来了一个月了,Qwen2.5也出来大半年了,但 Xtuner 对千问系列的支持只停留在 Qwen1.5。当然,如果你确实想微调Qwen2.5,也是有办法的,这个我们后面会说,但如果你想微调的模型不在这个系列中,那就没办法了。
点进qwen1_5,可以看到qwen1.5系列的所有模型:
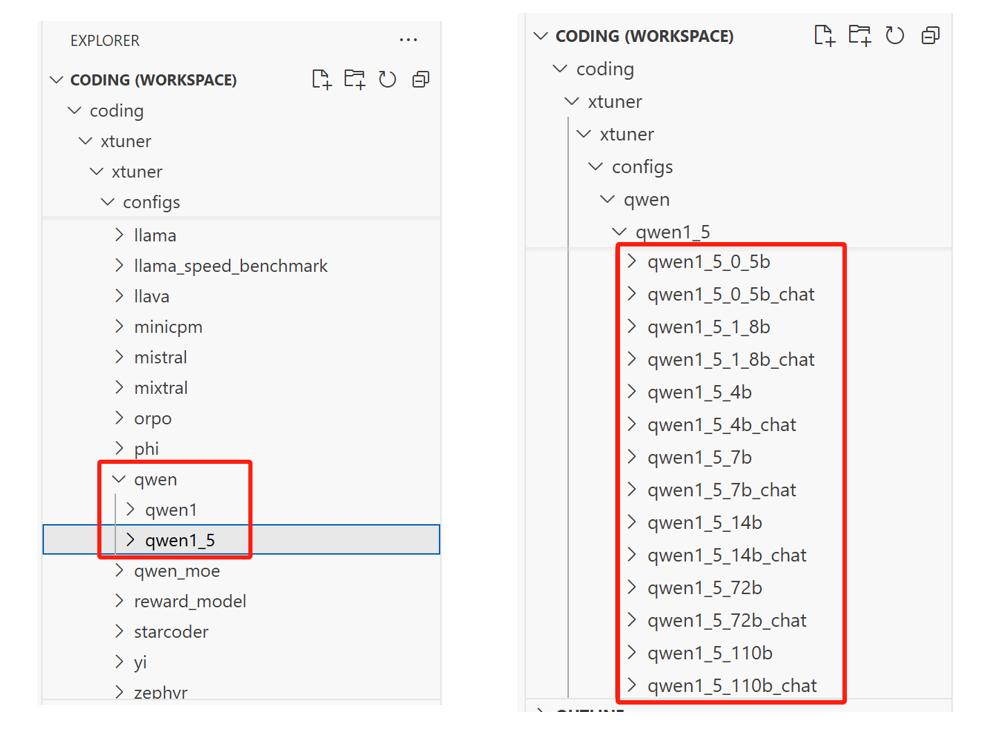
我们选择 qwen1_5_0_5b_chat,打开对应的目录,可以看到两个py文件,它们是用于训练的配置文件,一个用来配置预训练或全量微调,另一个用来配置 QLoRA 微调:
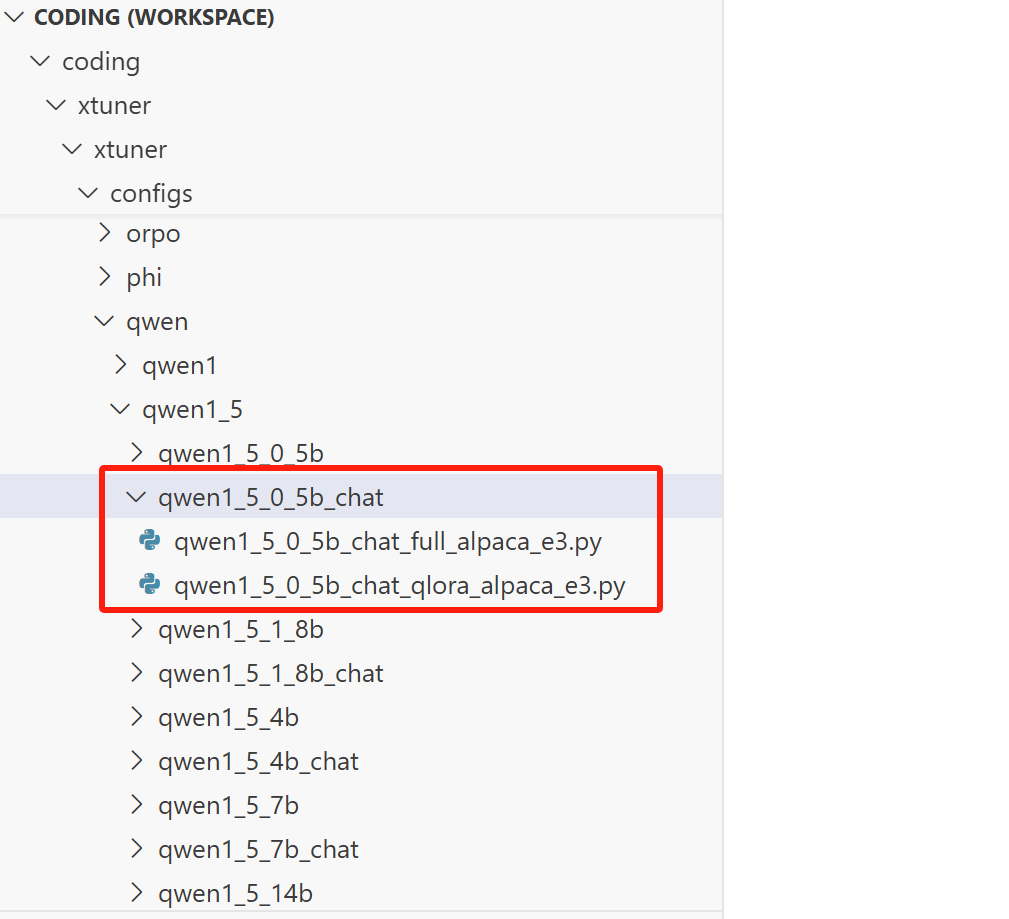
我们在工作中一半不会涉及全量微调,几乎都是QLoRA,所以我们点开 qwen1_5_0_5b_chat_qlora_alpaca_e3.py,接下来我们修改配置文件。
3.2 修改配置文件
修改配置文件,当然不能直接在原来的文件上改,而是复制一份到 xtuner 根目录下,改复制的版本。
(1)PART 1 基本设置
我们先看第一部分(PART 1)的参数含义:
#######################################################################
# PART 1 Settings #
#######################################################################
# Model
# 模型名字或者模型路径,如果直接写模型名字,首次执行时会去 hugging face 下载
pretrained_model_name_or_path = "Qwen/Qwen1.5-0.5B-Chat" # 模型名称或路径
use_varlen_attn = False# Data
alpaca_en_path = "tatsu-lab/alpaca" # 数据集名字或路径,填名字的话,首次运行会去 hugging face 下载
prompt_template = PROMPT_TEMPLATE.qwen_chat # 对话模板
max_length = 2048 # 输入样本最大长度
pack_to_max_length = True# parallel
sequence_parallel_size = 1# Scheduler & Optimizer
batch_size = 1 # 每个设备上的批次大小,即单张卡的 batch_size
accumulative_counts = 16 # 梯度累计次数
accumulative_counts *= sequence_parallel_size
dataloader_num_workers = 0 # 数据导入器的工作进程数,如果是0,则只使用主进程
max_epochs = 3 # 训练的epoch
optim_type = AdamW # 优化器
lr = 2e-4 # 学习率
betas = (0.9, 0.999) # AdamW的相关参数
weight_decay = 0 # L2正则化参数
max_norm = 1 # grad clip,梯度范数,裁剪的时候用
warmup_ratio = 0.03 # 学习率预热的步数,占总步数的比例# Save
save_steps = 500 # 每隔多少个 step 保存一次检查点(并非真保存)
save_total_limit = 2 # Maximum checkpoints to keep (-1 means unlimited),这里为2则是只保存最后2个检查点# Evaluate the generation performance during the training
evaluation_freq = 500 # 每隔多少个 step 验证一次,一般和 save_steps 同步,即保存之前先验证一次
SYSTEM = SYSTEM_TEMPLATE.alpaca
evaluation_inputs = ["请给我介绍五个上海的景点", "Please tell me five scenic spots in Shanghai"] # 主观验证的问题,每次验证的时候,模型的答复输出到屏幕
上面的参数并非全部都要改,只需要改一下部分,其他都使用默认:
# 预训练模型存放的位置
pretrained_model_name_or_path = "/data/coding/model_weights/Qwen/Qwen1.5-0.5B-chat"# 微调数据存放的位置
data_files = '/data/coding/xtuner/data/target_data.json'# 训练中最大的文本长度
max_length = 512 # 每个设备的 batch_size
batch_size = 8 # 最大训练轮数
max_epochs = 300# 只保存最后几个检查点
save_total_limit = 5# 主观验证问题,一般挑几个核心的问题做验证
evaluation_inputs = [ '只剩一个心脏了还能活吗?', '爸爸再婚,我是不是就有了个新娘?', '樟脑丸是我吃过最难吃的硬糖有奇怪的味道怎么还有人买','马上要上游泳课了,昨天洗的泳裤还没 干,怎么办', '我只出生了一次,为什么每年都要庆生' ]
(2)PART 2 模型与分词器设置
第二部分(PART 2)是分词器和模型。
#######################################################################
# PART 2 Model & Tokenizer #
#######################################################################
tokenizer = dict(type=AutoTokenizer.from_pretrained,pretrained_model_name_or_path=pretrained_model_name_or_path,trust_remote_code=True,padding_side="right",
)model = dict(type=SupervisedFinetune,use_varlen_attn=use_varlen_attn,llm=dict(type=AutoModelForCausalLM.from_pretrained,pretrained_model_name_or_path=pretrained_model_name_or_path,trust_remote_code=True,torch_dtype=torch.float16,quantization_config=dict( # QLoRA相关配置type=BitsAndBytesConfig,load_in_4bit=True, # 是否使用4位量化load_in_8bit=False, # 是否使用8位量化llm_int8_threshold=6.0, # LLM.int8()量化时的阈值llm_int8_has_fp16_weight=False, # 是否将部分权重以 FP16 格式保存# 部分权重可能因数值范围较大或动态范围较广,无法用 INT8 精确表示,若设置为True,则会将这些权重以 FP16 格式保存,以减少量化误差# 通常默认值为 False(即所有权重均以 INT8 格式保存),节约显存bnb_4bit_compute_dtype=torch.float16, # 4位量化时,反量化后的数据类型bnb_4bit_use_double_quant=True, # 4位量化时,是否使用二次量化bnb_4bit_quant_type="nf4", # 量化类型,4位量化用 NF4 比较多),),lora=dict(type=LoraConfig,r=64, # 秩lora_alpha=16, # 缩放系数lora_dropout=0.1,bias="none", task_type="CAUSAL_LM",),
)
上面是标准模式,即 NF4 量化的 QLoRA 微调,如果我想把量化方式改成 LLM.int8(),那么将QLoRA相关配置改为(只改了有注释的那两行):
quantization_config=dict( type=BitsAndBytesConfig,load_in_4bit=False, # 4位量化改成 Falseload_in_8bit=True, # 8位量化改成 Truellm_int8_threshold=6.0, llm_int8_has_fp16_weight=False, bnb_4bit_compute_dtype=torch.float16, bnb_4bit_use_double_quant=True, bnb_4bit_quant_type="nf4",)
此外,还要把 lora_alpha 改成秩的 2 倍,即:
lora=dict(type=LoraConfig,r=64, # 秩lora_alpha=128, # 缩放系数lora_dropout=0.1,bias="none", task_type="CAUSAL_LM",),
如果我们不做QLoRA,只做纯LoRA微调,可以把 quantization_config 注释掉,即:
model = dict(type=SupervisedFinetune,use_varlen_attn=use_varlen_attn,llm=dict(type=AutoModelForCausalLM.from_pretrained,pretrained_model_name_or_path=pretrained_model_name_or_path,trust_remote_code=True,torch_dtype=torch.float16,# quantization_config=dict(# type=BitsAndBytesConfig,# load_in_4bit=True,# load_in_8bit=False,# llm_int8_threshold=6.0,# llm_int8_has_fp16_weight=False,# bnb_4bit_compute_dtype=torch.float16,# bnb_4bit_use_double_quant=True,# bnb_4bit_quant_type="nf4",# ),),lora=dict(type=LoraConfig,r=64,lora_alpha=128,lora_dropout=0.1,bias="none",task_type="CAUSAL_LM",),
)
若进行全量微调,则把lora分支也注释掉:
model = dict(type=SupervisedFinetune,use_varlen_attn=use_varlen_attn,llm=dict(type=AutoModelForCausalLM.from_pretrained,pretrained_model_name_or_path=pretrained_model_name_or_path,trust_remote_code=True,torch_dtype=torch.float16,# quantization_config=dict(# type=BitsAndBytesConfig,# load_in_4bit=True,# load_in_8bit=False,# llm_int8_threshold=6.0,# llm_int8_has_fp16_weight=False,# bnb_4bit_compute_dtype=torch.float16,# bnb_4bit_use_double_quant=True,# bnb_4bit_quant_type="nf4",# ),),# lora=dict(# type=LoraConfig,# r=64,# lora_alpha=16,# lora_dropout=0.1,# bias="none",# task_type="CAUSAL_LM",# ),
)(3)PART 3 数据集与导入器设置
第三部分(PART 3)是数据集及其导入器的配置:
#######################################################################
# PART 3 Dataset & Dataloader #
#######################################################################
alpaca_en = dict(type=process_hf_dataset,dataset=dict(type=load_dataset, path=alpaca_en_path),tokenizer=tokenizer,max_length=max_length,dataset_map_fn=alpaca_map_fn,template_map_fn=dict(type=template_map_fn_factory, template=prompt_template),remove_unused_columns=True,shuffle_before_pack=True,pack_to_max_length=pack_to_max_length,use_varlen_attn=use_varlen_attn,
)sampler = SequenceParallelSampler if sequence_parallel_size > 1 else DefaultSamplertrain_dataloader = dict(batch_size=batch_size,num_workers=dataloader_num_workers,dataset=alpaca_en,sampler=dict(type=sampler, shuffle=True),collate_fn=dict(type=default_collate_fn, use_varlen_attn=use_varlen_attn),
)
这里我们只改数据集配置,按如下方式修改(只改了有注释的那两行):
alpaca_en = dict(type=process_hf_dataset,dataset=dict(type=load_dataset, path="json",data_files=data_files), # 改成我们自制数据集的配置tokenizer=tokenizer,max_length=max_length,dataset_map_fn=None, # 因为使用了 xtuner 默认支持的格式,所以 map_fn 为 Nonetemplate_map_fn=dict(type=template_map_fn_factory, template=prompt_template),remove_unused_columns=True,shuffle_before_pack=True,pack_to_max_length=pack_to_max_length,use_varlen_attn=use_varlen_attn,
)
其他还有 PART 4、PART 5,不过我们不需要修改了,用默认就行。
3.3 运行配置文件
在当前目录下,输入以下命令启动微调脚本:
xtuner train qwen1_5_0_5b_chat_qlora_alpaca_e3.py
新建一个终端,查看显存占用情况:
训练开始后,会在 xtuner/workdir 新建一个文件夹,名字与我们所用的配置文件相同,里面会保存训练日志、最后的五个检查点、复制的配置文件还有名为 last_checkpoint 的文件,这5个检查点都是pth文件。
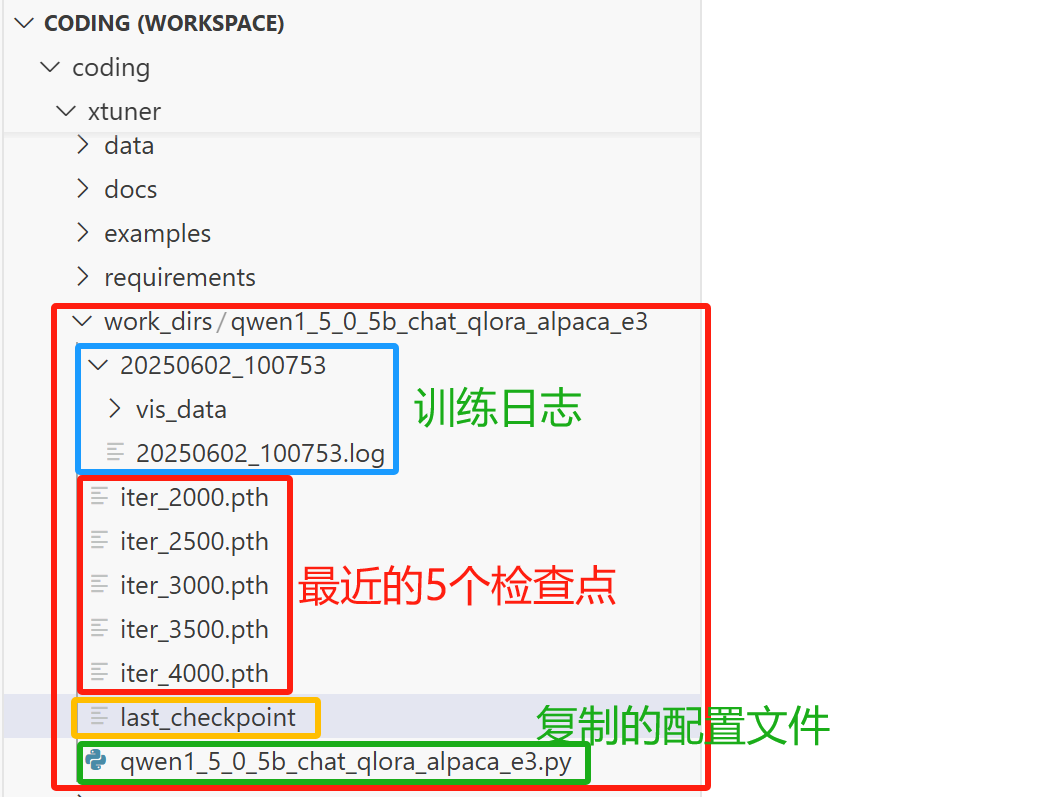
last_checkpoint 其实是个文档,里面只有一句话:/data/coding/xtuner/work_dirs/qwen1_5_0_5b_chat_qlora_alpaca_e3/iter_4000.pth
因为我们设置了只保存5个检查点,所以训练过程中只保存5个,如果还在训练的过程中,那么每保存一个,就会自动删掉一个。
训练日志是一个名为程序运行时间的文件夹,里面有个 .log 文件和 vis_data 文件夹。 .log 文件是控制台的输出,里面可以看到系统环境、运行环境、参数配置,还有训练过程中的各种输出信息。vis_data文件夹下,保存了每次验证时,主观验证的输出(如eval_outputs_iter_1499.txt),配置文件,以及模型损失过程(文件名为20250602_100753.json,配置文件中,默认是每隔50个step打印一次,因此这里是每10个step会往这个json文件中写入一次损失信息)。
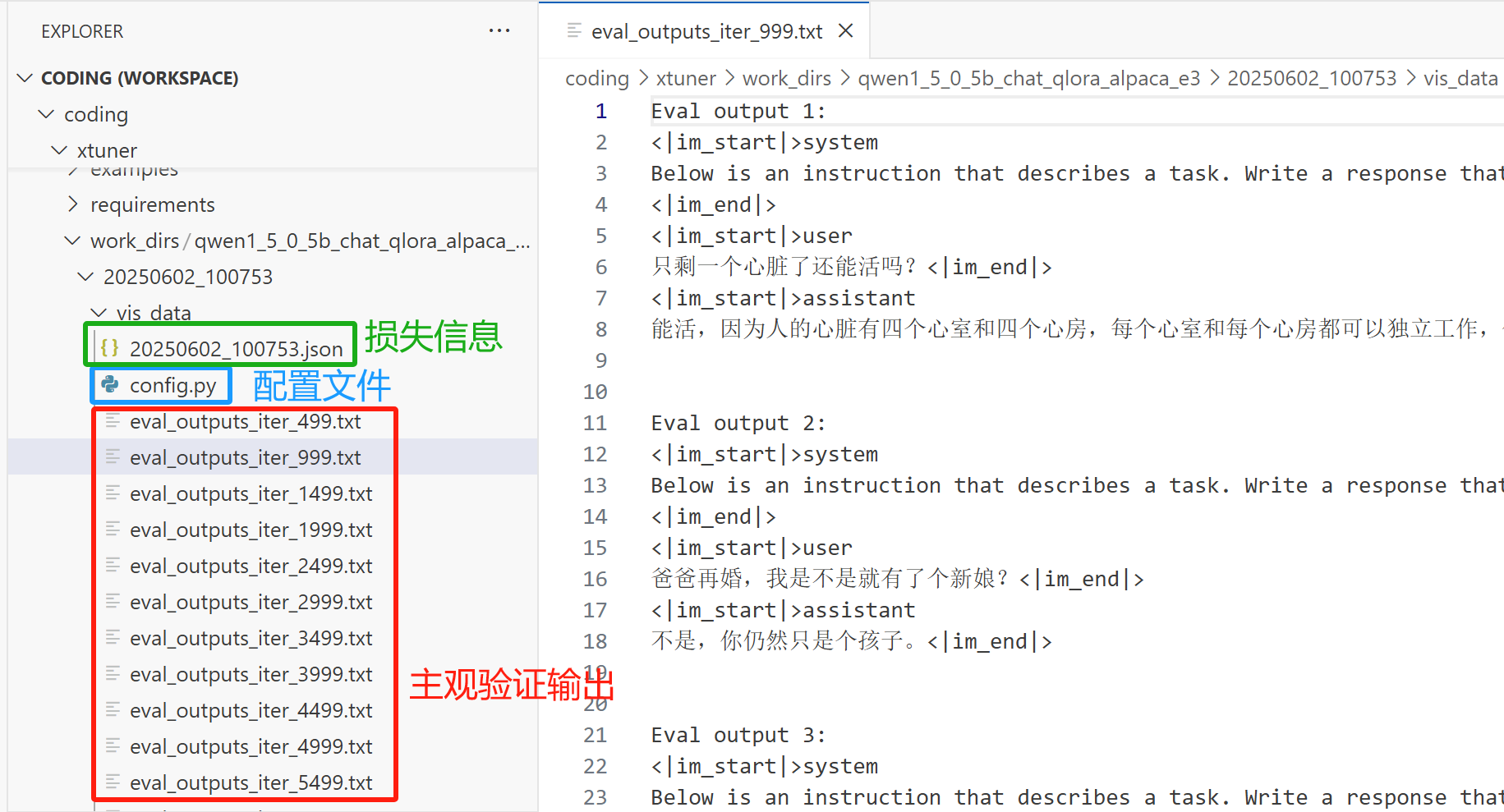
20250602_100753.json 示例信息如下:
{"lr": 6.925007692307691e-06, "data_time": 0.016223382949829102, "loss": 2.3829189777374267, "time": 1.4962422609329225, "iter": 10, "memory": 10071, "step": 10}
{"lr": 1.461723846153846e-05, "data_time": 0.015976953506469726, "loss": 2.4221604824066163, "time": 1.4898574352264404, "grad_norm": 1.5558911561965942, "iter": 20, "memory": 10302, "step": 20}
{"lr": 2.230946923076924e-05, "data_time": 0.2168890953063965, "loss": 2.4825533628463745, "time": 1.5853452205657959, "grad_norm": 1.5558911561965942, "iter": 30, "memory": 10302, "step": 30}
{"lr": 3.0001700000000008e-05, "data_time": 0.01598968505859375, "loss": 2.3637911081314087, "time": 1.4791534900665284, "grad_norm": 2.2266902327537537, "iter": 40, "memory": 10302, "step": 40}中间用于主观验证的问题,每当到了验证的步数,会在控制台打印模型回答:

这些信息也会保留到日志中,如果觉得模型的回复合适,可以提前终止训练。(本文我们只介绍 Xtuner 的使用流程,所以先不管上面的回答质量。)
3.4 模型转换与合并
模型训练后会自动保存成 PTH 模型(例如 iter_2000.pth ,如果使用了 DeepSpeed,则将会是一个文件夹),我们需要利用 xtuner convert pth_to_hf 将其转换为 HuggingFace 模型,以便于后续使用。具体命令为:
xtuner convert pth_to_hf ${FINETUNE_CFG} ${PTH_PATH} ${ADAPTER_SAVE_PATH}
# FINETUNE_CFG 是配置文件,PTH_PATH 是 pth 模型路径,ADAPTER_SAVE_PATH 是转换成 Hugging Face 的保存路径,推荐用绝对路径
# 例如:xtuner convert pth_to_hf qwen1_5_0_5b_chat_qlora_alpaca_e3.py /data/coding/xtuner/work_dirs/qwen1_5_0_5b_chat_qlora_alpaca_e3/iter_6000.pth /data/coding/xtuner/adapter_save_dir/qwen/
转换之后,会在当前目录下新建一个名为 adapter_save_dir 的文件夹,我们的低秩适配器(LoRA 分支)在 qwen 目录下:
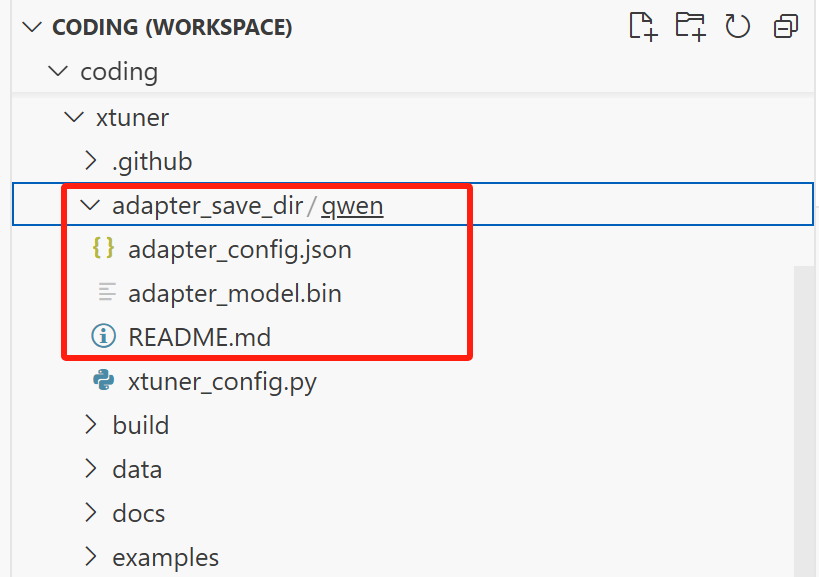
对于 LoRA / QLoRA 微调,模型转换后得到的是 adapter 参数(即低秩适配器),而并不包含原 LLM 参数。如果期望获得合并后的模型权重(例如用于后续评测),那么可以利用 xtuner convert merge :
xtuner convert merge ${LLM_PATH} ${LLM_ADAPTER} ${SAVE_PATH}
# LLM_PATH 是原始模型路径,LLM_ADAPTER 是低秩适配器的路径,SAVE_PATH 是合并后的保存路径,推荐用绝对路径
# 例如:xtuner convert merge /data/coding/model_weights/Qwen/Qwen1.5-0.5B-chat /data/coding/xtuner/adapter_save_dir/qwen /data/coding/model_weights/Qwen/Qwen1.5-0.5B-xtuner-qlora
上述过程完成后,能在指定目录下看到合并的结果:
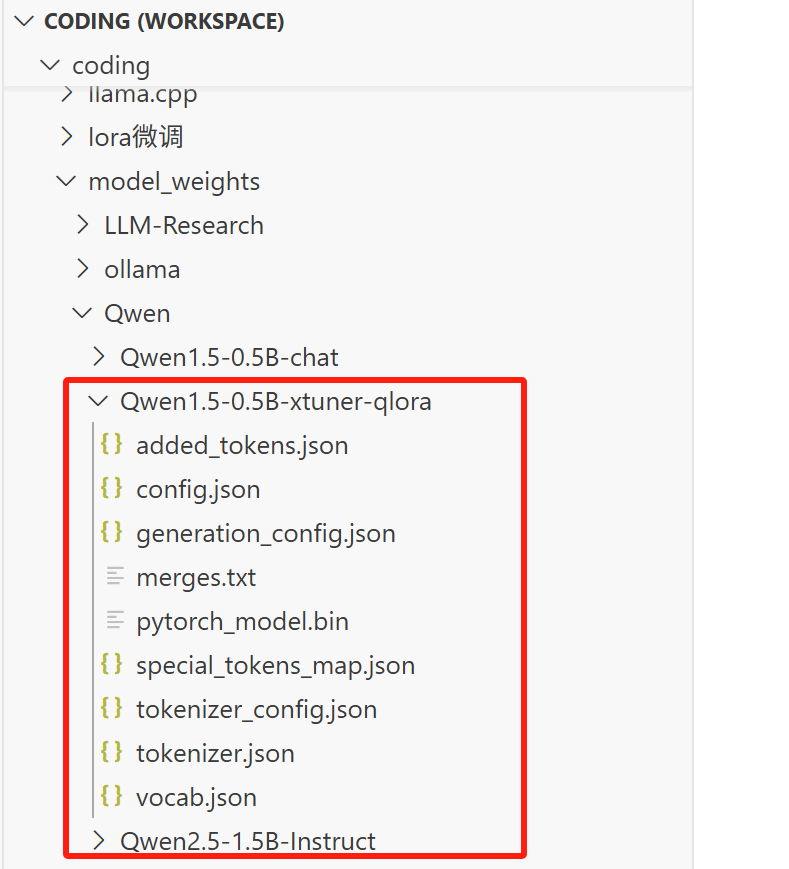
接下来就能用合并的模型进行推理部署了。
3.5 微调Qwen2.5
微调 Qwen2.5 也是可以的。
先在配置文件的 PART 1中,把模型路径改成 Qwen2.5 的路径,其他参数按照前面的步骤设置:
pretrained_model_name_or_path = "/data/coding/model_weights/Qwen/Qwen2.5-1.5B-Instruct"
随后随后进行训练、转换与合并,得到 Hugging Face 模型。
接下来是对话模板,因为 Qwen1.5 和 Qwen2.5 使用的对话模板是不一样的,我们微调 Qwen2.5 用的是 1.5 的对话模型,那么最后推理部署的时候,也得用 1.5 的对话模板。Xtuner 把能支持的所有模型的对话模板,都放在 /data/coding/xtuner/xtuner/utils/templates.py 中,搜一下就能找到。