【机器学习基础】机器学习入门核心:数学基础与Python科学计算库
机器学习入门核心:数学基础与Python科学计算库
- 一、核心数学基础回顾
- 1. 函数与导数
- 2. Taylor公式
- 3. 概率论基础
- 4. 统计量
- 5. 重要定理
- 6. 最大似然估计(MLE)
- 7. 线性代数
- 二、Python科学计算库精要
- 1. NumPy:数值计算核心
- 2. SciPy:科学计算工具箱
- 3. Pandas:数据处理神器
- 4. Matplotlib:专业级可视化
- 三、机器学习中的关键应用
- 四、概率论与统计的深度应用
- 1. 贝叶斯理论与机器学习
- 2. 协方差矩阵的特征分解
- 五、优化理论与机器学习
- 1. 梯度下降法的数学原理
- 2. 二阶优化方法
- 六、Python科学计算库高级应用
- 1. NumPy高效计算技巧
- 2. Pandas高级数据处理
- 3. SciPy优化与积分
- 七、机器学习中的矩阵分解
- 1. SVD在推荐系统中的应用
- 2. QR分解解线性系统
- 八、实际案例:房价预测全流程
- 九、学习路径与资源推荐
- 学习路线图:
- 推荐资源:
- 十、核心要点总结
一、核心数学基础回顾
1. 函数与导数
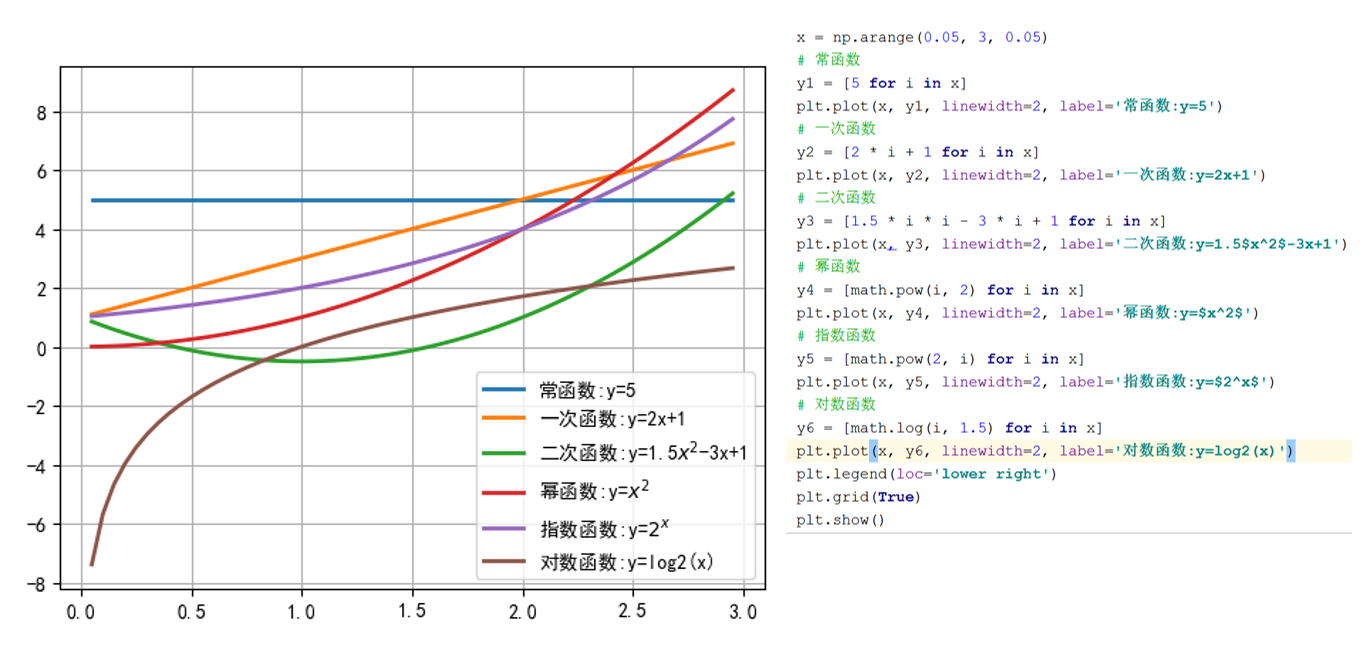
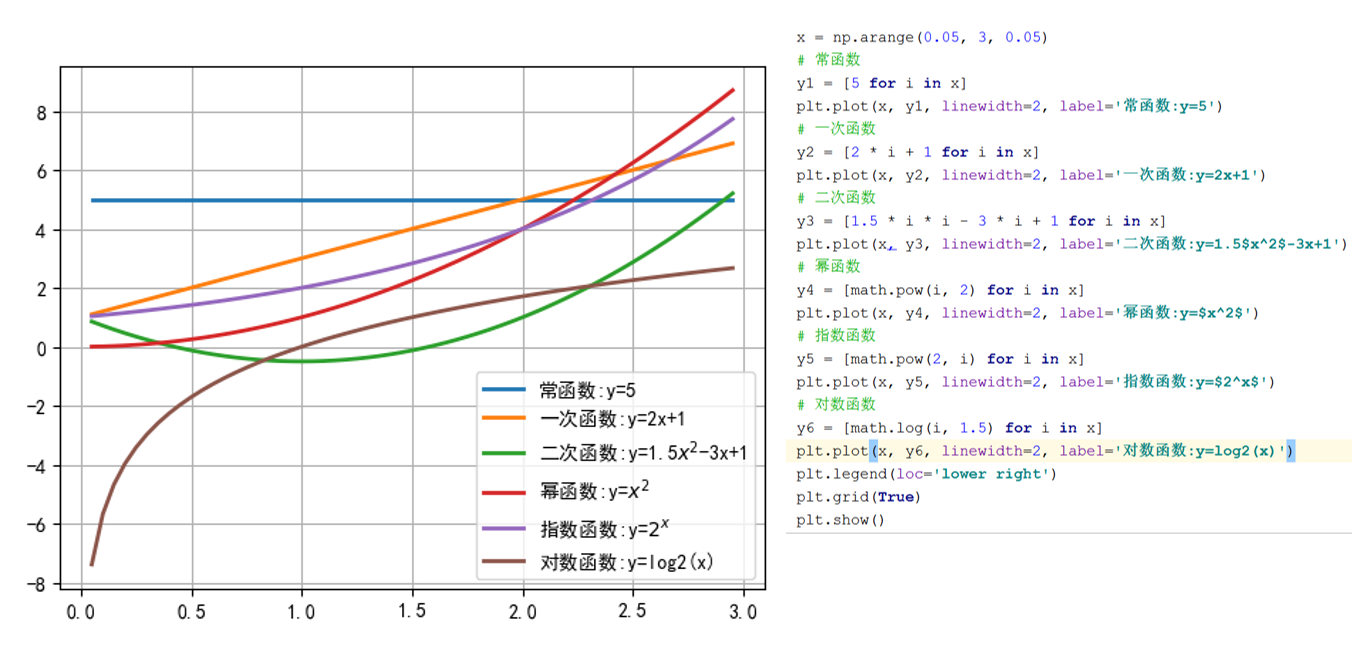
常见函数类型:
- 常函数: f ( x ) = c f(x) = c f(x)=c
- 一次函数: f ( x ) = k x + b f(x) = kx + b f(x)=kx+b
- 二次函数: f ( x ) = a x 2 + b x + c f(x) = ax^2 + bx + c f(x)=ax2+bx+c
- 幂函数: f ( x ) = x a f(x) = x^a f(x)=xa
- 指数函数: f ( x ) = a x ( a > 0 , a ≠ 1 ) f(x) = a^x \quad (a>0, a≠1) f(x)=ax(a>0,a=1)
- 对数函数: f ( x ) = log a x ( a > 0 , a ≠ 1 ) f(x) = \log_a x \quad (a>0, a≠1) f(x)=logax(a>0,a=1)
导数与梯度:
- 导数:描述函数变化率,几何意义为曲线切线斜率
f ′ ( x 0 ) = lim Δ x → 0 f ( x 0 + Δ x ) − f ( x 0 ) Δ x f'(x_0) = \lim_{\Delta x \to 0} \frac{f(x_0 + \Delta x) - f(x_0)}{\Delta x} f′(x0)=Δx→0limΔxf(x0+Δx)−f(x0) - 偏导数:多变量函数中针对单个变量的导数
∂ f ∂ x i = lim Δ x i → 0 f ( x 1 , . . . , x i + Δ x i , . . . , x n ) − f ( x 1 , . . . , x n ) Δ x i \frac{\partial f}{\partial x_i} = \lim_{\Delta x_i \to 0} \frac{f(x_1,...,x_i+\Delta x_i,...,x_n)-f(x_1,...,x_n)}{\Delta x_i} ∂xi∂f=Δxi→0limΔxif(x1,...,xi+Δxi,...,xn)−f(x1,...,xn) - 梯度:多变量函数的导数向量,指向函数增长最快方向
∇ f = ( ∂ f ∂ x 1 , ∂ f ∂ x 2 , . . . , ∂ f ∂ x n ) \nabla f = \left( \frac{\partial f}{\partial x_1}, \frac{\partial f}{\partial x_2}, ..., \frac{\partial f}{\partial x_n} \right) ∇f=(∂x1∂f,∂x2∂f,...,∂xn∂f)
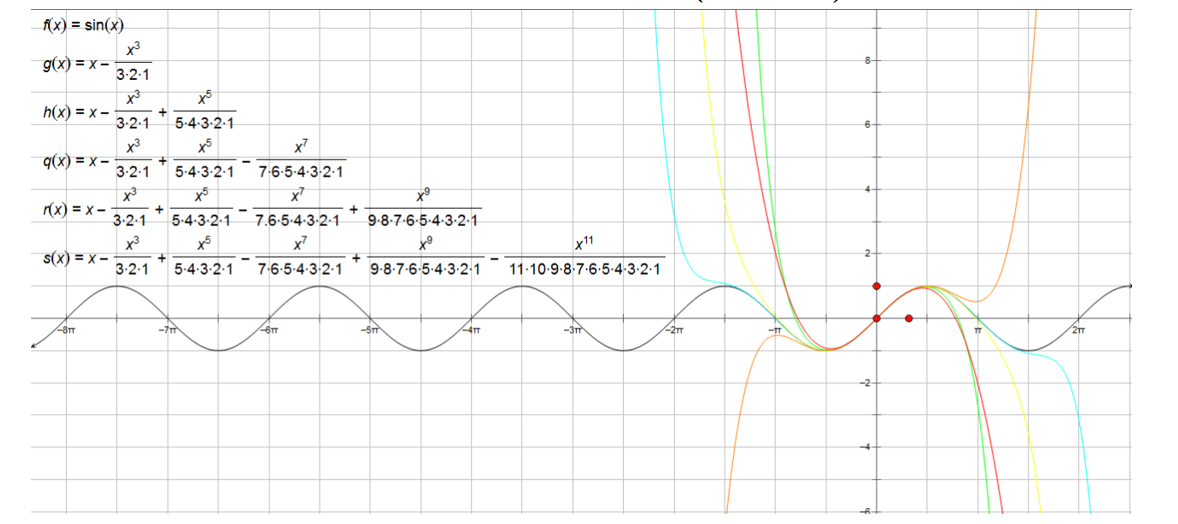
2. Taylor公式
用多项式逼近函数值,在优化算法中广泛应用:
f ( x ) = f ( x 0 ) + f ′ ( x 0 ) ( x − x 0 ) + f ′ ′ ( x 0 ) 2 ! ( x − x 0 ) 2 + . . . + f ( n ) ( x 0 ) n ! ( x − x 0 ) n + R n ( x ) f(x) = f(x_0) + f'(x_0)(x-x_0) + \frac{f''(x_0)}{2!}(x-x_0)^2 + ... + \frac{f^{(n)}(x_0)}{n!}(x-x_0)^n + R_n(x) f(x)=f(x0)+f′(x0)(x−x0)+2!f′′(x0)(x−x0)2+...+n!f(n)(x0)(x−x0)n+Rn(x)
其中 R n ( x ) R_n(x) Rn(x)为余项(高阶无穷小)
应用场景:
- 函数近似计算(如 e 0.1 ≈ 1 + 0.1 + 0.1 2 2 ! = 1.105 e^{0.1} \approx 1 + 0.1 + \frac{0.1^2}{2!} = 1.105 e0.1≈1+0.1+2!0.12=1.105)
- 梯度下降法等优化算法的理论基础
3. 概率论基础
核心公式:
- 联合概率: P ( A ∩ B ) = P ( A , B ) P(A \cap B) = P(A,B) P(A∩B)=P(A,B)
- 条件概率: P ( A ∣ B ) = P ( A ∩ B ) P ( B ) P(A|B) = \frac{P(A \cap B)}{P(B)} P(A∣B)=P(B)P(A∩B)
- 全概率公式:
P ( B ) = ∑ i = 1 n P ( A i ) P ( B ∣ A i ) ( { A i } 为样本空间划分 ) P(B) = \sum_{i=1}^n P(A_i)P(B|A_i) \quad (\{A_i\}为样本空间划分) P(B)=i=1∑nP(Ai)P(B∣Ai)({Ai}为样本空间划分) - 贝叶斯公式:
P ( A j ∣ B ) = P ( A j ) P ( B ∣ A j ) ∑ i = 1 n P ( A i ) P ( B ∣ A i ) P(A_j|B) = \frac{P(A_j)P(B|A_j)}{\sum_{i=1}^n P(A_i)P(B|A_i)} P(Aj∣B)=∑i=1nP(Ai)P(B∣Ai)P(Aj)P(B∣Aj)
4. 统计量
| 概念 | 定义 | 意义 |
|---|---|---|
| 期望 | E [ X ] = ∑ x i p i \mathbb{E}[X] = \sum x_i p_i E[X]=∑xipi (离散) E [ X ] = ∫ x f ( x ) d x \mathbb{E}[X] = \int x f(x)dx E[X]=∫xf(x)dx (连续) | 随机变量平均值 |
| 方差 | Var ( X ) = E [ ( X − μ ) 2 ] \text{Var}(X) = \mathbb{E}[(X - \mu)^2] Var(X)=E[(X−μ)2] | 数据离散程度 |
| 协方差 | Cov ( X , Y ) = E [ ( X − μ X ) ( Y − μ Y ) ] \text{Cov}(X,Y) = \mathbb{E}[(X-\mu_X)(Y-\mu_Y)] Cov(X,Y)=E[(X−μX)(Y−μY)] | 变量线性相关性 |
| 标准差 | σ = Var ( X ) \sigma = \sqrt{\text{Var}(X)} σ=Var(X) | 方差算术平方根 |
协方差矩阵:
Σ = [ Cov ( X 1 , X 1 ) ⋯ Cov ( X 1 , X n ) ⋮ ⋱ ⋮ Cov ( X n , X 1 ) ⋯ Cov ( X n , X n ) ] \Sigma = \begin{bmatrix} \text{Cov}(X_1,X_1) & \cdots & \text{Cov}(X_1,X_n) \\ \vdots & \ddots & \vdots \\ \text{Cov}(X_n,X_1) & \cdots & \text{Cov}(X_n,X_n) \end{bmatrix} Σ= Cov(X1,X1)⋮Cov(Xn,X1)⋯⋱⋯Cov(X1,Xn)⋮Cov(Xn,Xn)
5. 重要定理
大数定律:
lim n → ∞ P ( ∣ 1 n ∑ i = 1 n X i − μ ∣ < ϵ ) = 1 \lim_{n \to \infty} P\left( \left| \frac{1}{n}\sum_{i=1}^n X_i - \mu \right| < \epsilon \right) = 1 n→∞limP( n1i=1∑nXi−μ <ϵ)=1
意义:样本均值依概率收敛于总体均值
中心极限定理:
∑ i = 1 n X i − n μ σ n → d N ( 0 , 1 ) \frac{\sum_{i=1}^n X_i - n\mu}{\sigma\sqrt{n}} \xrightarrow{d} N(0,1) σn∑i=1nXi−nμdN(0,1)
意义:独立同分布随机变量和的标准化近似服从标准正态分布
6. 最大似然估计(MLE)
估计步骤:
- 写出似然函数: L ( θ ; x ) = ∏ i = 1 n f ( x i ∣ θ ) L(\theta; x) = \prod_{i=1}^n f(x_i|\theta) L(θ;x)=∏i=1nf(xi∣θ)
- 取对数: ℓ ( θ ) = ln L ( θ ) \ell(\theta) = \ln L(\theta) ℓ(θ)=lnL(θ)
- 求导并解方程: ∂ ℓ ∂ θ = 0 \frac{\partial \ell}{\partial \theta} = 0 ∂θ∂ℓ=0
示例:高斯分布参数估计
μ ^ = 1 n ∑ x i , σ ^ 2 = 1 n ∑ ( x i − μ ^ ) 2 \hat{\mu} = \frac{1}{n}\sum x_i, \quad \hat{\sigma}^2 = \frac{1}{n}\sum (x_i - \hat{\mu})^2 μ^=n1∑xi,σ^2=n1∑(xi−μ^)2
7. 线性代数
矩阵运算:
- 加法: C i j = A i j + B i j C_{ij} = A_{ij} + B_{ij} Cij=Aij+Bij
- 数乘: C i j = λ A i j C_{ij} = \lambda A_{ij} Cij=λAij
- 矩阵乘法: C i j = ∑ k A i k B k j C_{ij} = \sum_k A_{ik}B_{kj} Cij=∑kAikBkj
- 转置: B = A T ⇒ B i j = A j i B = A^T \Rightarrow B_{ij} = A_{ji} B=AT⇒Bij=Aji
矩阵分解:
- SVD分解: A = U Σ V T A = U\Sigma V^T A=UΣVT
- QR分解: A = Q R A = QR A=QR(Q正交,R上三角)
向量求导:
- ∇ x ( a T x ) = a \nabla_x (a^Tx) = a ∇x(aTx)=a
- ∇ x ( x T A x ) = ( A + A T ) x \nabla_x (x^TAx) = (A + A^T)x ∇x(xTAx)=(A+AT)x (当A对称时: 2 A x 2Ax 2Ax)
二、Python科学计算库精要

1. NumPy:数值计算核心
import numpy as np# 创建数组
arr = np.array([1, 2, 3])
matrix = np.array([[1,2],[3,4]])# 矩阵运算
dot_product = np.dot(arr1, arr2) # 点积
mat_mult = np.matmul(matrix1, matrix2) # 矩阵乘法# 线性代数
eigenvals = np.linalg.eigvals(matrix) # 特征值
svd_u, svd_s, svd_vt = np.linalg.svd(matrix) # SVD分解
2. SciPy:科学计算工具箱
from scipy import optimize, linalg, stats# 优化求解
result = optimize.minimize(f, x0) # 函数优化# 矩阵分解
Q, R = linalg.qr(matrix) # QR分解# 统计分析
mean = stats.mean(data) # 均值
t_test = stats.ttest_ind(sample1, sample2) # T检验
3. Pandas:数据处理神器
import pandas as pd# 数据加载与处理
df = pd.read_csv("data.csv")
df = df.dropna() # 删除缺失值# 数据统计
group_stats = df.groupby('category')['value'].describe()
corr_matrix = df.corr() # 相关系数矩阵# 数据可视化
df['value'].plot.hist(bins=30, alpha=0.5)
4. Matplotlib:专业级可视化
import matplotlib.pyplot as plt# 创建画布
fig, ax = plt.subplots(figsize=(10,6))# 绘制图形
ax.plot(x, y, label='Linear')
ax.scatter(x, y2, color='red', label='Points')
ax.set_xlabel('X Axis')
ax.set_ylabel('Y Axis')
ax.legend()# 保存输出
plt.savefig('plot.png', dpi=300)
plt.show()
三、机器学习中的关键应用
-
特征工程:
- Pandas数据清洗与转换
- NumPy实现特征标准化: z = x − μ σ z = \frac{x - \mu}{\sigma} z=σx−μ
-
模型训练:
- SciPy优化算法求解损失函数最小值
- NumPy实现梯度下降:
w t + 1 = w t − η ∇ w J ( w ) w_{t+1} = w_t - \eta \nabla_w J(w) wt+1=wt−η∇wJ(w)
-
矩阵分解应用:
- SVD用于推荐系统(协同过滤)
- QR分解求解线性回归: X β = y ⇒ β = R − 1 Q T y X\beta = y ⇒ \beta = R^{-1}Q^Ty Xβ=y⇒β=R−1QTy
-
概率建模:
from scipy.stats import norm # 最大似然估计高斯分布参数 mu_mle = np.mean(data) std_mle = np.std(data) -
可视化分析:
- 使用Matplotlib绘制决策边界
- Pandas绘制特征相关性热力图
四、概率论与统计的深度应用
1. 贝叶斯理论与机器学习
贝叶斯公式的机器学习视角:
P ( θ ∣ D ) = P ( D ∣ θ ) P ( θ ) P ( D ) P(\theta|D) = \frac{P(D|\theta)P(\theta)}{P(D)} P(θ∣D)=P(D)P(D∣θ)P(θ)
- θ \theta θ:模型参数
- D D D:观测数据
- P ( θ ) P(\theta) P(θ):先验分布
- P ( D ∣ θ ) P(D|\theta) P(D∣θ):似然函数
- P ( θ ∣ D ) P(\theta|D) P(θ∣D):后验分布
应用场景:
- 朴素贝叶斯分类器
- 贝叶斯优化(超参数调优)
- 概率图模型
# 朴素贝叶斯实现示例
from sklearn.naive_bayes import GaussianNB
model = GaussianNB()
model.fit(X_train, y_train)
probabilities = model.predict_proba(X_test)
2. 协方差矩阵的特征分解
协方差矩阵的特征值和特征向量揭示了数据的本质结构:
Σ = Q Λ Q T \Sigma = Q\Lambda Q^T Σ=QΛQT
- Q Q Q:特征向量矩阵(主成分方向)
- Λ \Lambda Λ:特征值对角矩阵(各方向方差)
PCA降维的数学本质:
- 计算数据协方差矩阵
- 特征值分解
- 选择前k大特征值对应的特征向量
- 投影到低维空间
# PCA实现
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)
print("解释方差比:", pca.explained_variance_ratio_)
五、优化理论与机器学习
1. 梯度下降法的数学原理
参数更新公式:
θ t + 1 = θ t − η ∇ J ( θ t ) \theta_{t+1} = \theta_t - \eta \nabla J(\theta_t) θt+1=θt−η∇J(θt)
其中 η \eta η为学习率, ∇ J \nabla J ∇J为损失函数的梯度
梯度推导示例(线性回归):
损失函数: J ( w ) = 1 2 N ∑ i = 1 N ( y i − w T x i ) 2 J(w) = \frac{1}{2N}\sum_{i=1}^N (y_i - w^Tx_i)^2 J(w)=2N1∑i=1N(yi−wTxi)2
梯度: ∇ w J = − 1 N X T ( y − X w ) \nabla_w J = -\frac{1}{N}X^T(y - Xw) ∇wJ=−N1XT(y−Xw)
2. 二阶优化方法
牛顿法更新公式:
θ t + 1 = θ t − H − 1 ∇ J ( θ t ) \theta_{t+1} = \theta_t - H^{-1}\nabla J(\theta_t) θt+1=θt−H−1∇J(θt)
其中 H H H为Hessian矩阵(二阶导数矩阵)
优势与局限:
- 👍 收敛速度快
- 👎 计算复杂度高( O ( n 3 ) O(n^3) O(n3))
- 👎 需要保证Hessian正定
六、Python科学计算库高级应用
1. NumPy高效计算技巧
广播机制:
A = np.array([[1, 2], [3, 4]])
B = np.array([10, 20])
print(A * B) # 自动扩展维度 [[10,40],[30,80]]
爱因斯坦求和约定:
# 矩阵乘法
np.einsum('ij,jk->ik', A, B)# 双线性变换
np.einsum('ij,kj->ik', A, B)
2. Pandas高级数据处理
时间序列分析:
# 创建时间序列
date_rng = pd.date_range('2023-01-01', periods=6, freq='D')
ts = pd.Series(np.random.randn(6), index=date_rng)# 重采样
weekly = ts.resample('W').mean()
数据透视分析:
pivot = df.pivot_table(values='sales',index='region',columns='quarter',aggfunc=np.sum,fill_value=0
)
3. SciPy优化与积分
函数优化:
from scipy.optimize import minimizedef rosen(x):return sum(100.0*(x[1:]-x[:-1]**2.0)**2.0 + (1-x[:-1])**2.0result = minimize(rosen, x0=[0,0], method='BFGS')
print("最优解:", result.x)
数值积分:
from scipy.integrate import quad# 计算高斯积分
integral, error = quad(lambda x: np.exp(-x**2), -np.inf, np.inf)
print(f"∫e^(-x²)dx = {integral:.5f} (误差={error:.2e})")
七、机器学习中的矩阵分解
1. SVD在推荐系统中的应用
协同过滤模型:
R ≈ U Σ V T R \approx U\Sigma V^T R≈UΣVT
- R R R:用户-物品评分矩阵
- U U U:用户潜在特征
- V V V:物品潜在特征
# SVD实现推荐
from scipy.sparse.linalg import svds
U, sigma, Vt = svds(user_item_matrix, k=50)
predicted_ratings = U @ np.diag(sigma) @ Vt
2. QR分解解线性系统
求解线性回归:
X β = y ⇒ Q R β = y ⇒ R β = Q T y X\beta = y \quad \Rightarrow \quad QR\beta = y \quad \Rightarrow \quad R\beta = Q^Ty Xβ=y⇒QRβ=y⇒Rβ=QTy
# QR分解解线性系统
Q, R = np.linalg.qr(X)
beta = np.linalg.solve(R, Q.T @ y)
八、实际案例:房价预测全流程
import pandas as pd
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error# 1. 数据加载与预处理
df = pd.read_csv('housing.csv')
df = df.dropna()# 2. 特征工程
df['age_squared'] = df['house_age']**2
X = df[['distance', 'rooms', 'house_age', 'age_squared']]
y = df['price']# 3. 数据标准化
X_mean, X_std = X.mean(), X.std()
X_normalized = (X - X_mean) / X_std# 4. 模型训练
model = LinearRegression()
model.fit(X_normalized, y)# 5. 模型评估
y_pred = model.predict(X_normalized)
rmse = np.sqrt(mean_squared_error(y, y_pred))
print(f"RMSE: {rmse:.2f}")# 6. 结果可视化
plt.figure(figsize=(10,6))
plt.scatter(y, y_pred, alpha=0.5)
plt.plot([y.min(), y.max()], [y.min(), y.max()], 'r--')
plt.xlabel('Actual Price')
plt.ylabel('Predicted Price')
plt.title('Actual vs Predicted Housing Prices')
九、学习路径与资源推荐
- 数学基础 → 2. NumPy核心操作 → 3. Pandas数据处理 → 4. SciPy数值计算 → 5. Matplotlib可视化
关键要点:
- 掌握导数与梯度是理解梯度下降等优化算法的前提
- 概率论基础(贝叶斯公式、MLE)是机器学习模型的理论核心
- NumPy的广播机制和向量化操作可提升代码效率100倍+
- 矩阵分解(SVD/QR)是降维与特征提取的数学基础
学习路线图:
推荐资源:
-
数学基础:
- 《线性代数及其应用》(Gilbert Strang)
- 《概率论与数理统计》(陈希孺)
-
Python科学计算:
- 《Python数据科学手册》(Jake VanderPlas)
- NumPy官方文档
-
实战平台:
- Kaggle
- Google Colab
-
可视化学习:
- Matplotlib图库
- Seaborn示例
十、核心要点总结
-
数学是机器学习的基础:
- 梯度下降依赖导数计算
- 概率分布构建生成模型
- 矩阵分解实现降维与推荐
-
Python库的合理选择:
-
高效计算实践:
- 向量化操作优先于循环
- 适当使用内存视图(避免复制)
- 利用稀疏矩阵处理高维数据
-
模型调试技巧:
- 梯度检验: J ( θ + ϵ ) − J ( θ − ϵ ) 2 ϵ ≈ ∇ J ( θ ) \frac{J(\theta+\epsilon)-J(\theta-\epsilon)}{2\epsilon} \approx \nabla J(\theta) 2ϵJ(θ+ϵ)−J(θ−ϵ)≈∇J(θ)
- 损失函数可视化
- 特征重要性分析
通过扎实的数学基础和熟练的Python工具使用,您将能:
- 深入理解机器学习算法原理
- 高效实现数据预处理和特征工程
- 快速构建和调试复杂模型
- 直观解释模型行为和结果