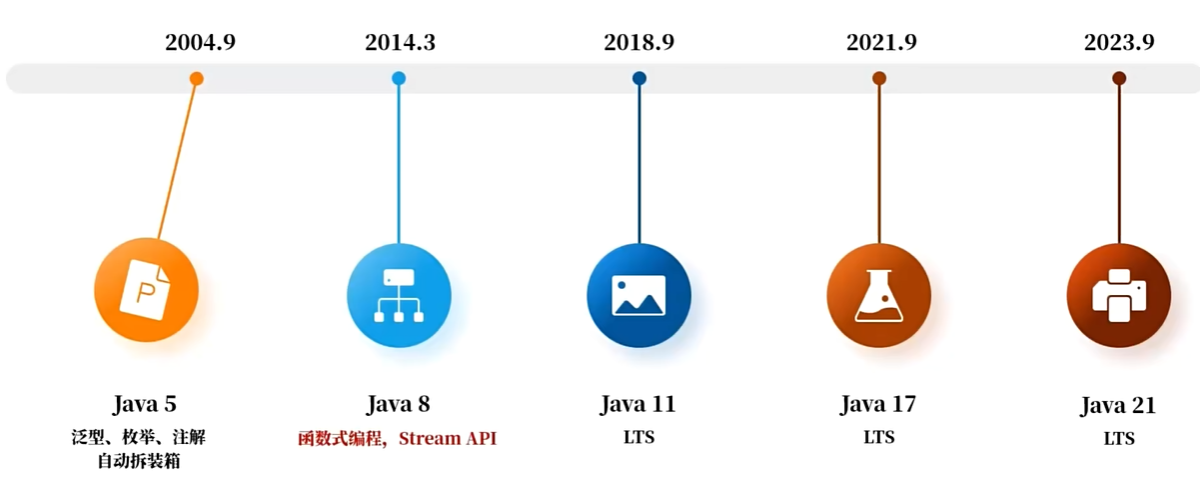
Java函数式编程(上)
课程:黑马程序员Java函数式编程全套视频教程,Lambda表达式、Stream流、函数式编程一套全通关_哔哩哔哩_bilibili
函数式编程的优点:
- 代码简洁
- 功能强大
- 并行处理
- 链式调用
- 延迟执行
一、函数伊始
函数是一段可重复使用的代码块,用于执行特定任务。它接收输入(称为参数),经过处理,返回输出(称为返回值)。函数的主要目的是封装逻辑,提高代码的可读性、复用性和模块化。
示例1:合格的函数
package com.itheima.day1;// 演示【合格】的函数
public class Sample1 {public static void main(String[] args) {System.out.println(square(10));System.out.println(square(10));System.out.println(square(10));System.out.println(square(10));System.out.println(square(10));}static int square(int x) {return x * x;}
}
只要输入相同,无论多少次调用,无论什么时间调用,输出相同。
示例2:要想成为合格的函数,引用的外部数据必须是不可变的(除参数外)
package com.itheima.day1;// 要想成为合格函数:引用的外部数据必须是不可变的(除参数外)
public class Sample2 {public static void main(String[] args) {System.out.println(pray("张三"));System.out.println(pray("张三"));System.out.println(pray("张三"));
// buddha.name = "魔王";System.out.println(pray("张三"));}// static class Buddha {
// final String name;
//
// public Buddha(String name) {
// this.name = name;
// }
// }record Buddha(String name) {}static Buddha buddha = new Buddha("如来");static String pray(String person) {return (person + "向[" + buddha.name + "]虔诚祈祷");}
}
record自动生成以下内容:
- 私有final字段,如private final String name
- 公开构造方法,如public Buddha(String name)
- 访问方法(getter),如name(),注意不是getName()
- 自动实现的equals、hashCode()、toString()
等价于以下传统代码:
final class Buddha {private final String name;public Buddha(String name) {this.name = name;}public String name() { // 注意方法名是 name() 而非 getName()return name;}// 自动生成 equals(), hashCode(), toString()
}示例3:成员方法算不算函数?
package com.itheima.day1;// 成员方法算不算函数?
public class Sample3 {static class Student {final String name;public Student(String name) {this.name = name;}public String getName(Student this) {return this.name;}}public static void main(String[] args) {Student s1 = new Student("张三");System.out.println(s1.getName()); // getName(s1)System.out.println(s1.getName()); // getName(s1)Student s2 = new Student("李四");System.out.println(s2.getName()); // getName(s2)System.out.println(s2.getName()); // getName(s2)/*方法不算函数它只能算是某个对象专用的法则,是小道,还成不了大道*/}
}
方法与函数并无本质区别。
示例4:有形的函数 -> 化为对象
package com.itheima.day1;public class Sample4 {// 普通函数static int add(int a, int b) {return a + b;}interface Lambda {int calculate(int a, int b);}// 函数化为对象static Lambda add = (a, b) -> a + b;/** 前者是纯粹的一条两数加法规则,它的位置是固定的,要使用它,需要通过 Sample4.add 找到它,然后执行* 而后者(add 对象)就像长了腿,它的位置是可以变化的,想去哪里就去哪里,哪里要用到这条加法规则,把它传递过去* 接口的目的是为了将来用它来执行函数对象,此接口中只能有一个方法定义*/public static void main(String[] args) {System.out.println(Sample4.add(3, 4));System.out.println(add.calculate(5, 6));}}
示例5:Java网络编程 + Lambda表达式 + 序列化
package com.itheima.day1;import java.io.*;
import java.net.ServerSocket;
import java.net.Socket;
import java.util.concurrent.ThreadLocalRandom;public class Sample5 {interface Lambda extends Serializable {int calculate(int a, int b);}static class Server {public static void main(String[] args) throws IOException {ServerSocket ss = new ServerSocket(8080);System.out.println("server start...");while (true) {Socket s = ss.accept();// Java19+的虚拟线程,高效处理多客户端请求Thread.ofVirtual().start(() -> {try {ObjectInputStream is = new ObjectInputStream(s.getInputStream());Lambda lambda = (Lambda) is.readObject();int a = ThreadLocalRandom.current().nextInt(10);int b = ThreadLocalRandom.current().nextInt(10);// 调用客户端的逻辑System.out.printf("%s %d op %d = %d%n", s.getRemoteSocketAddress().toString(), a, b, lambda.calculate(a, b));} catch (IOException | ClassNotFoundException e) {throw new RuntimeException(e);}});}}}// Server 虚拟机端必须有 Client0 这个类,相当于把实现绑定在了服务器端static class Client0 {int add(int a, int b) {return a + b;}}// Server 虚拟机端只需有 Lambda 接口定义,实现与服务器无关static class Client1 {public static void main(String[] args) throws IOException {try(Socket s = new Socket("127.0.0.1", 8080)){Lambda lambda = (a, b) -> a + b;ObjectOutputStream os = new ObjectOutputStream(s.getOutputStream());os.writeObject(lambda);os.flush();}}}static class Client2 {public static void main(String[] args) throws IOException {try(Socket s = new Socket("127.0.0.1", 8080)){Lambda lambda = (a, b) -> a - b;ObjectOutputStream os = new ObjectOutputStream(s.getOutputStream());os.writeObject(lambda);os.flush();}}}static class Client3 {public static void main(String[] args) throws IOException {try(Socket s = new Socket("127.0.0.1", 8080)){Lambda lambda = (a, b) -> a * b;ObjectOutputStream os = new ObjectOutputStream(s.getOutputStream());os.writeObject(lambda);os.flush();}}}
}
问题背景:
- 传统方式(如Client0)需要服务器端预先知道客户端的具体实现(如add方法),耦合度高。
解决方案:
- 使用Lambda接口(Serializable)将计算逻辑(如a + b)作为可序列化的对象传输;
- 服务器只需知道接口定义,具体实现由客户端决定(Client1加法、Client2减法、Client3乘法)
示例6:行为参数化
package com.itheima.day1;import java.util.ArrayList;
import java.util.Comparator;
import java.util.List;
import java.util.function.BiFunction;// 函数对象好处1:行为参数化
public class Sample6 {public static void main(String[] args) {List<Student> students = List.of(new Student("张无忌", 18, "男"),new Student("杨不悔", 16, "女"),new Student("周芷若", 19, "女"),new Student("宋青书", 20, "男"));/*需求1:筛选男性学生*/System.out.println(filter0(students, student -> student.sex.equals("男")));/*需求2:筛选18岁以下学生*/System.out.println(filter0(students, student -> student.age < 18));System.out.println(filter0(students, student -> student.sex.equals("女")));}interface Lambda {boolean test(Student student);}static List<Student> filter0(List<Student> students, Lambda lambda) {List<Student> result = new ArrayList<>();for (Student student : students) {if (lambda.test(student)) {result.add(student);}}return result;}// 参数 -> 逻辑部分 student -> student.sex.equals("男")static List<Student> filter(List<Student> students) {List<Student> result = new ArrayList<>();for (Student student : students) {if (student.sex.equals("男")) {result.add(student);}}return result;}// student -> student.age < 18static List<Student> filter2(List<Student> students) {List<Student> result = new ArrayList<>();for (Student student : students) {if (student.age < 18) {result.add(student);}}return result;}static class Student {private String name;private int age;private String sex;public Student(String name, int age, String sex) {this.name = name;this.age = age;this.sex = sex;}public int getAge() {return age;}public String getName() {return name;}public String getSex() {return sex;}@Overridepublic String toString() {return "Student{" +"name='" + name + '\'' +", age=" + age +", sex='" + sex + '\'' +'}';}}
}
示例7:延迟执行
package com.itheima.day1;import org.apache.logging.log4j.Level;
import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Logger;
import org.apache.logging.log4j.core.LoggerContext;
import org.apache.logging.log4j.core.appender.ConsoleAppender;
import org.apache.logging.log4j.core.config.Configurator;
import org.apache.logging.log4j.core.config.builder.api.AppenderComponentBuilder;
import org.apache.logging.log4j.core.config.builder.api.ConfigurationBuilder;
import org.apache.logging.log4j.core.config.builder.api.ConfigurationBuilderFactory;
import org.apache.logging.log4j.core.config.builder.impl.BuiltConfiguration;// 函数对象好处2:延迟执行
public class Sample7 {static Logger logger = init(Level.DEBUG);
// static Logger logger = init(Level.INFO);public static void main(String[] args) {/*if (logger.isDebugEnabled()) {logger.debug("{}", expensive());}*/logger.debug("{}", expensive()); // expensive() 立刻执行(无论是否输出日志,都会消耗资源)logger.debug("{}", () -> expensive()); // 函数对象使得 expensive 延迟执行(仅当日志级别为DUBUG时执行,避免不必要的计算)}static String expensive() {System.out.println("执行耗时操作...");return "日志";}static Logger init(Level level) {// 1. 创建配置构造器ConfigurationBuilder<BuiltConfiguration> builder = ConfigurationBuilderFactory.newConfigurationBuilder().setStatusLevel(Level.ERROR).setConfigurationName("BuilderTest");// 2. 配置控制台输出(格式、目标)AppenderComponentBuilder appender = builder.newAppender("Stdout", "CONSOLE").addAttribute("target", ConsoleAppender.Target.SYSTEM_OUT).add(builder.newLayout("PatternLayout").addAttribute("pattern", "%d [%t] %-5level: %msg%n%throwable"));// 3. 将配置应用到根日志级别builder.add(appender).add(builder.newRootLogger(level).add(builder.newAppenderRef("Stdout")));// 4. 初始化Log4j配置Configurator.initialize(builder.build());return LogManager.getLogger();}
}
核心功能:
- 传统日志问题:直接调用logger.debug("{}", expensive())时,无论日志级别是否启用,expensive()都会立即执行(浪费资源);
- Lambda优化:通过logger.debug("{}", () -> expensive()),仅当日志级别为DEBUG时才会执行expensive(),避免不必要的计算。
输出:
如果日志级别为DEBUG,两种方式都会输出:
执行耗时操作...
2025-05-31 12:00:00 [main] DEBUG: 日志
执行耗时操作...
2025-05-31 12:00:00 [main] DEBUG: 日志
如果日志基本高于DEBUG(如INFO),则:
- 方式1:仍会打印 执行耗时操作... (但无日志输出)。
- 方式2:完全不会执行expensive()。
原理:
- Log4j 2的日志方法(如debug)支持Supplier<String> 参数;
- 当传递Lambda表达式时,Log4j 2会在内部检查日志级别,只有满足条件时才会调用Supplier.get()执行Lambda。
二、函数编程语法
1. 函数对象表现形式

1.1 Lambda表达式
例1:Lambda表达式的组成部分
(int a, int b) -> a + b;
(1)参数列表,如 (int a, int b)
- 作用:声明Lambda接收的输入参数
- 规则:
- 参数类型可以显式声明(如int a),也可以省略(由编译器根据上下文自动推断)
-
(a, b) -> a + b // 等效写法(类型推断) - 空参数时用 () 表示
-
() -> System.out.println("No args") - 单参数时可省略括号(前提:没加类型声明)
-
x -> x * x
(2)箭头操作符 ->
- 作用:分隔参数列表和Lambda体
- 固定语法:不可省略或替换
(3)Lambda体,如 a + b
- 作用:定义Lambda的具体行为(逻辑实现)
- 两种形式:
- 表达式体(单行,无需return):
-
(a, b) -> a + b // 自动返回计算结果 - 代码块体(多行,不能省略{}以及需显式return):
-
(a, b) -> {int sum = a + b;return sum; }
(4)隐含的接口类型(函数式接口)
Lambda表达式需要匹配一个函数式接口(只有一个抽象方法的接口)。例如:
@FunctionalInterface
interface Calculator {int calculate(int a, int b); // 抽象方法签名与 Lambda 匹配
}// 使用 Lambda 实现接口
Calculator add = (a, b) -> a + b;
System.out.println(add.calculate(3, 5)); // 输出 8
可以根据上下文推断参数类型时,可以省略参数类型。
1.2 方法引用
例1:静态方法引用
Math::max 等价于 (int a, int b) -> Math.max(a, b);
- 左侧是类型,右侧是静态方法
- 适用场景:需要直接调用某个类的静态方法时适用。
例2:实例方法引用
Student::getName 等价于 (Student stu) -> stu.getName();
- 左侧是类型,右侧是非静态方法
- 适用场景:对流操作中的对象方法调用,如 students.stream().map(Student::getName))。
例3:对象方法引用
System.out::println 等价于 (Object obj) -> System.out.println(obj);
- 左侧是一个对象,右侧是这个对象的非静态方法
- 直接调用某个对象的实例方法,如日志输出、集合操作。
例4:构造方法引用
Student::new 等价于 () -> new Student();
- 左侧是类型,右侧是一个关键字
- 适用场景:工厂模式、流式操作中创建对象,如 .map(Student::new)。
练习:写出等价Lambda表达式
static class Student {private String name;public Student(String name) {this.name = name;}public String getName() {return name;}public void setName(String name) {this.name = name;}@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Student student = (Student) o;return Objects.equals(name, student.name);}@Overridepublic int hashCode() {return Objects.hash(name);}
}例1:Math::random
- () -> Math.random()
例2:Math::sqrt
- (double number) -> Math.sqrt(number)
例3:Student::getName
- (Student stu) -> stu.getName()
例4:Student::setName
- (Student stu, String newName) -> stu.setName(newName)
例5:Student:hashCode
- (Student stu) -> stu.hashCode()
例6:Student::equals
- (Student stu, Object o) -> stu.equals(o)
例7:假设已有对象 Student stu = new Student("张三")
- 7.1 stu::getName
- () -> stu.getName()
- 7.2 stu::setName
- (String newName) -> stu.setName(newName)
- 7.3 Student:new
- (String name) -> new Student(name)
2. 函数对象类型
2.1 如何归类

归类练习:

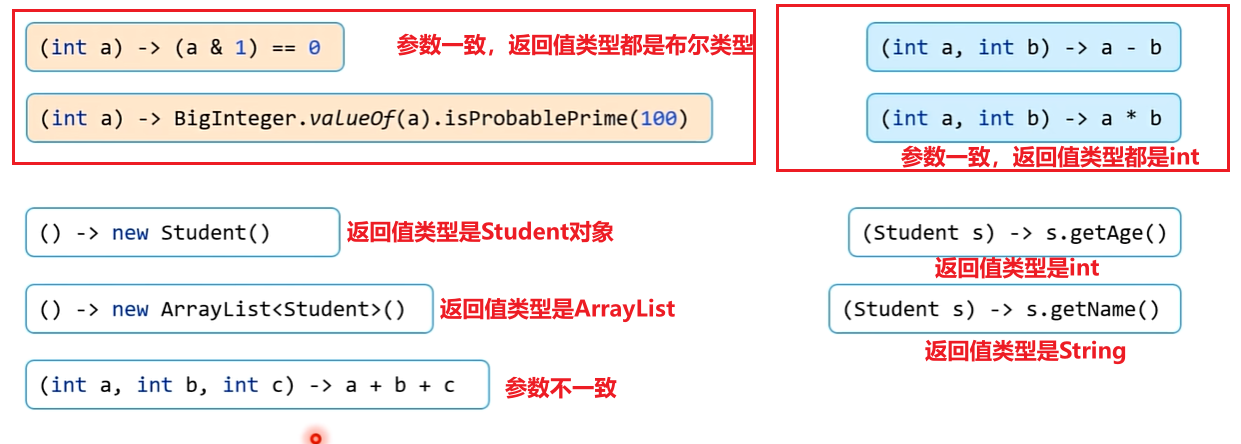
package com.itheima.day2;import java.math.BigInteger;
import java.util.ArrayList;
import java.util.List;
import java.util.function.Function;
import java.util.function.IntBinaryOperator;
import java.util.function.IntPredicate;
import java.util.function.Supplier;public class CategoryTest {static class Student {private String name;private String sex;private int age;public String getName() {return name;}public void setName(String name) {this.name = name;}public String getSex() {return sex;}public void setSex(String sex) {this.sex = sex;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}}public static void main(String[] args) {
// Type1 obj1 = a -> (a & 1) == 0;
// Type1 obj2 = a -> BigInteger.valueOf(a).isProbablePrime(100);
// Type2 obj3 = (a, b, c) -> a + b + c;
// Type3 obj4 = (a, b) -> a - b;
// Type3 obj5 = (a, b) -> a * b;
// Type6<Student> obj6 = () -> new Student();
// Type6<List<Student>> obj7 = () -> new ArrayList<Student>();
// Type7<String, Student> obj8 = s -> s.getName();
// Type7<Integer, Student> obj9 = s -> s.getAge();IntPredicate obj1 = a -> (a & 1) == 0;IntPredicate obj2 = a -> BigInteger.valueOf(a).isProbablePrime(100);IntTernaryOperator obj3 = (a, b, c) -> a + b + c;IntBinaryOperator obj4 = (a, b) -> a - b;IntBinaryOperator obj5 = (a, b) -> a * b;Supplier<Student> obj6 = () -> new Student();Supplier<List<Student>> obj7 = () -> new ArrayList<Student>();Function<Student, String> obj8 = s -> s.getName();Function<Student, Integer> obj9 = s -> s.getAge();}@FunctionalInterfaceinterface Type7<O, I> {O op(I input); // s -> s.getName(); s -> s.getAge();}@FunctionalInterfaceinterface Type1 {boolean op(int a); // a -> (a & 1) == 0}@FunctionalInterfaceinterface IntTernaryOperator {int op(int a, int b, int c); // (a, b, c) -> a + b + c;}@FunctionalInterfaceinterface Type3 {int op(int a, int b); // (a, b) -> a - b; (a, b) -> a * b}@FunctionalInterfaceinterface Type4 {Student op(); // () -> new Student();}@FunctionalInterfaceinterface Type5 {List<Student> op(); // () -> new ArrayList<Student>();}@FunctionalInterfaceinterface Type6<T> {T op(); // 泛型 -> 参数相同,但返回值不同 -> 扩展性↑// () -> new Student(); () -> new ArrayList<Student>();}
}
常见函数接口
1. Runnable
- () -> void :没有参数,也没有返回值
2. Callable
- () -> T : 没有参数,但是有返回值
3. Comparator
- (T, T) -> int :接收两个参数,返回int类型的结果,其中:返回值为负数表示前一对象小于后一对象;0表示两对象相等;正数表示前一对象大于后一对象
4. Consumer, BiConsumer, IntConsumer, LongConsumer, DoubleConsumer
- (T) -> void :有参数,没有返回值,其中Bi是两参,Int指参数是int
5. Function, BiFunction, Int Long Double ...
- (T) -> R:有参数并且有返回值,其中Bi是两参,Int指参数是int,如IntFunction
6. Predicate, BiPredicate, Int Long Double ...
- (T) -> boolean:用来做条件判断,返回值是布尔类型,其中Bi是两参,Int指参数是int,如IntPredicate
7. Supplier, Int Long Double ...
- () -> T :没有参数,有返回值,其中Int指返回值是int,例如IntSupplier
8. UnaryOperator, BinaryOperator, Int Long Double ...
- (T) -> T : Unary一参,Binary两参,Int指参数是int,如IntUnaryOperator、IntBinaryOperator
命名规则
| 名称 | 含义 |
| Consumer | 有参,无返回值 |
| Function | 有参,有返回值 |
| Predicate | 有参,返回boolean |
| Supplier | 无参,有返回值 |
| Operator | 有参,有返回值,并且类型一致 |
| 前缀 | 含义 |
| Unary | 一元 |
| Binary | 二元 |
| Ternary | 三元 |
| Quatenary | 四元 |
| ... | ... |
2.2 使用函数接口解决问题
例1:筛选:判断是否是偶数,但以后可能改变判断规则 -> Predicate(有参,返回boolean)
static List<Integer> filter(List<Integer> list) {List<Integer> result = new ArrayList<>();for (Integer number : list) {// 筛选:判断是否是偶数,但以后可能改变判断规则if((number & 1) == 0) {result.add(number);}}return result;
}解决:把变化的规则作为方法的参数
static List<Integer> filter(List<Integer> list, Predicate<Integer> predicate) {List<Integer> result = new ArrayList<>();for (Integer number : list) {// 调用test方法,实则是执行传入的逻辑if(predicate.test(number)) {result.add(number);}}return result;/*(Integer number) -> (number & 1) == 0*/}例2:转换:将数字转为字符串,但以后可能改变转换规则 -> Function(有参,有返回值)
static List<String> map(List<Integer> list) {List<String> result = new ArrayList<>();for (Integer number : list) {// 转换:将数字转为字符串,但以后可能改变转换规则result.add(String.valueOf(number));}return result;
}解决:
static List<String> map(List<Integer> list, Function<Integer, String> function) {List<String> result = new ArrayList<>();for (Integer number : list) {// 转换:将数字转为字符串,但以后可能改变转换规则result.add(function.apply(number));}return result;}例3:消费:打印,但以后可能改变消费规则 -> Consumer(有参,无返回值)
static void consume(List<Integer> list) {for (Integer number : list) {// 消费:打印,但以后可能改变消费规则System.out.println(number);}
}解决:
static void consume(List<Integer> list, Consumer<Integer> consumer) {for (Integer number : list) {// 消费:打印,但以后可能改变消费规则consumer.accept(number);}}例4:生成:随机数,但以后可能改变生成规则 -> Supplier(无参,有返回值)
static List<Integer> supply(int count) {List<Integer> result = new ArrayList<>();for (int i = 0; i < count; i++) {// 生成:随机数,但以后可能改变生成规则result.add(ThreadLocalRandom.current().nextInt());}return result;
}解决:
static List<Integer> supply(int count, Supplier<Integer> supplier) {List<Integer> result = new ArrayList<>();for (int i = 0; i < count; i++) {// 生成:随机数,但以后可能改变生成规则result.add(supplier.get());}return result;}3. 方法引用
方法引用是Lambda表达式的一种简化写法,用于直接指向一个已经存在的方法(静态方法、非静态方法、构造方法),即将现有方法的调用化为函数对象。它的核心目的是让代码更简洁,避免重复编写简单的Lambda表达式。
例1:静态方法
- Lambda表达式:(a, b) -> Math.max(a, b)
- 方法引用:Math::max
- 示例代码:获取较大值
// 等价于 (a, b) -> Math.max(a, b)
BinaryOperator<Integer> max = Math::max;
System.out.println(max.apply(3, 5)); // 输出 5例2:非静态方法
- Lamba表达式:(stu) -> stu.getName()
- 方法引用:Student::getName
- 应用场景:①提取对象属性;②作为函数式接口(如Function、Comparator)的实现
- 示例1:配合Stream.map()提取学生姓名
class Student {private String name;public Student(String name) {this.name = name;}// 非静态方法(实例方法)public String getName() {return name;}
}import java.util.Arrays;
import java.util.List;
import java.util.stream.Collectors;public class Main {public static void main(String[] args) {List<Student> students = Arrays.asList(new Student("Alice"),new Student("Bob"),new Student("Charlie"));// 使用方法引用替代 Lambda:stu -> stu.getName()List<String> names = students.stream().map(Student::getName) // 关键代码.collect(Collectors.toList());System.out.println(names); // 输出 [Alice, Bob, Charlie]}
}- 示例2:
// 等价于 (s1, s2) -> s1.compareToIgnoreCase(s2)
Comparator<String> comparator = String::compareToIgnoreCase;
System.out.println(comparator.compare("a", "A")); // 输出 0(相等)例3:构造方法
- Lambda表达式:() -> new Student()
- 方法引用:Student::new
- 作用:引用类的构造方法,根据上下文匹配参数
- 示例:
// 等价于 () -> new ArrayList<>()
Supplier<List<String>> listSupplier = ArrayList::new;
List<String> list = listSupplier.get();// 等价于 name -> new Student(name)
Function<String, Student> studentCreator = Student::new;
Student s = studentCreator.apply("Alice");3.1 类名::静态方法名
它对应怎样的函数对象呢?
- 逻辑,就是执行此静态方法
- 参数,就是静态方法的参数
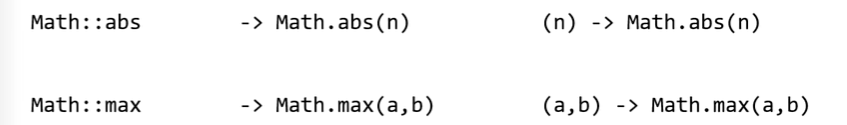
例1:挑选出所有男性学生
package com.itheima.day2.methodref;import java.util.stream.Stream;public class MethodRef1 {public static void main(String[] args) {/*需求:挑选出所有男性学生*/Stream.of(new Student("张无忌", "男"),new Student("周芷若", "女"),new Student("宋青书", "男"))
// .filter(stu -> stu.sex().equals("男")) // lambda 表达式方式.filter(MethodRef1::isMale) // 静态方法引用方式
// .forEach(stu -> System.out.println(stu)); // lambda 表达式方式.forEach(MethodRef1::abc); // 静态方法引用方式/*(Student stu) -> stu.sex().equals("男")(Student stu) -> MethodRef1.isMale(stu)*//*(Student stu) -> System.out.println(stu)类名::静态方法(Student stu) -> MethodRef1.abc(stu);*/}public static boolean isMale(Student stu) {return stu.sex().equals("男");}public static void abc(Student stu) {System.out.println(stu);}record Student(String name, String sex) {public void print() {System.out.println(this);}/*Student::print(stu) -> stu.print()*/public boolean isMale() {return this.sex.equals("男");}/*Student::isMale(stu) -> stu.isMale()*/}
}
要点:函数对象的逻辑就是执行此静态方法。为了执行这个静态方法,就需要把未知的部分作为函数对象的参数
3.2 类名::非静态方法名
它对应怎样的函数对象呢?
- 逻辑,就是执行此非静态方法
- 参数,一是此类对象,一是非静态方法的参数

package com.itheima.day2.methodref;import java.util.stream.Stream;public class MethodRef1 {public static void main(String[] args) {/*需求:挑选出所有男性学生*/Stream.of(new Student("张无忌", "男"),new Student("周芷若", "女"),new Student("宋青书", "男"))
// .filter(stu -> stu.sex().equals("男")) // lambda 表达式方式
// .filter(MethodRef1::isMale) // 静态方法引用方式.filter(Student::isMale) // 非静态方法引用方式
// .forEach(stu -> System.out.println(stu)); // lambda 表达式方式
// .forEach(MethodRef1::abc); // 静态方法引用方式.forEach(Student::print); // 静态方法引用方式/*(Student stu) -> stu.sex().equals("男")(Student stu) -> MethodRef1.isMale(stu)*//*(Student stu) -> System.out.println(stu)类名::静态方法(Student stu) -> MethodRef1.abc(stu);*/}public static boolean isMale(Student stu) {return stu.sex().equals("男");}public static void abc(Student stu) {System.out.println(stu);}record Student(String name, String sex) {public void print() {System.out.println(this);}/*Student::print(stu) -> stu.print()*/public boolean isMale() {return this.sex.equals("男");}/*Student::isMale(stu) -> stu.isMale()*/}
}
3.3 对象::非静态方法名
它对应怎样的函数对象呢?
- 逻辑,就是执行此对象的非静态方法
- 参数,就是非静态方法的参数

与类名::非静态方法名的区别:知道了调用方法的对象,不需要作为参数传入。
示例:
package com.itheima.day2.methodref;import java.util.stream.Stream;public class MethodRef3 {static class Util {public boolean isMale(Student stu) {return stu.sex().equals("男");}public String xyz(Student stu){return stu.name();}}public static void main(String[] args) {Util util = new Util();Stream.of(new Student("张无忌", "男"),new Student("周芷若", "女"),new Student("宋青书", "男")).filter(util::isMale)
// .map(stu->stu.name()) // lambda 表达式
// .map(util::xyz) // 对象::非静态方法.map(Student::name) // 类名::非静态方法.forEach(System.out::println); // 对象名::非静态方法}/*(stu) -> util.isMale(stu)(stu) -> util.xyz(stu)*//*对象::非静态方法System.out::printlnstu -> System.out.println(stu)*/record Student(String name, String sex) {public String name() {return this.name;}/*Student::namestu -> stu.name()*/public String sex() {return this.sex;}}
}
3.4 类名::new
它对应怎样的函数对象呢?
- 逻辑,就是执行此构造方法
- 参数,就是构造方法的参数

示例:
package com.itheima.day2.methodref;import java.util.function.BiFunction;
import java.util.function.Function;
import java.util.function.Supplier;public class MethodRef4 {static class Student {private final String name;private final Integer age;public Student() {this.name = "某人";this.age = 18;}public Student(String name) {this.name = name;this.age = 18;}public Student(String name, Integer age) {this.name = name;this.age = age;}@Overridepublic String toString() {return "Student{" +"name='" + name + '\'' +", age=" + age +'}';}}public static void main(String[] args) {Supplier<Student> s1 = Student::new;Function<String, Student> s2 = Student::new;BiFunction<String, Integer, Student> s3 = Student::new;System.out.println(s1.get());System.out.println(s2.apply("张三"));System.out.println(s3.apply("李四", 25));}
}
3.5 this::非静态方法名
属于对象::非静态方法的特例,只能在类内部使用
package com.itheima.day2.methodref;import java.util.stream.Stream;public class MethodRef5 {public static void main(String[] args) {Util util = new UtilExt();util.hiOrder(Stream.of(new Student("张无忌", "男"),new Student("周芷若", "女"),new Student("宋青书", "男")));}record Student(String name, String sex) { }static class Util {private boolean isMale(Student stu) {return stu.sex().equals("男");}boolean isFemale(Student stu) {return stu.sex().equals("女");}// 过滤男性学生并打印void hiOrder(Stream<Student> stream) {stream
// .filter(stu->this.isMale(stu)).filter(this::isMale).forEach(System.out::println);}}
}
3.6 super::非静态方法名
属于对象::非静态方法的特例,在类内部使用
示例:
package com.itheima.day2.methodref;import java.util.stream.Stream;public class MethodRef5 {public static void main(String[] args) {Util util = new UtilExt();util.hiOrder(Stream.of(new Student("张无忌", "男"),new Student("周芷若", "女"),new Student("宋青书", "男")));}record Student(String name, String sex) { }static class Util {private boolean isMale(Student stu) {return stu.sex().equals("男");}boolean isFemale(Student stu) {return stu.sex().equals("女");}// 过滤男性学生并打印void hiOrder(Stream<Student> stream) {stream
// .filter(stu->this.isMale(stu)).filter(this::isMale).forEach(System.out::println);}}static class UtilExt extends Util {// 过滤女性学生并打印void hiOrder(Stream<Student> stream) {stream.filter(super::isFemale).forEach(System.out::println);}}
}
比较
| 格式 | 特点 | 备注 |
| 类名::静态方法 | 参数一致 | |
| 类名::非静态方法 | 参数多一个该类对象 | |
| 对象::非静态方法 | 参数一致 | |
| 类名::new | 参数一致 | |
| this::非静态方法 | - | 3的特例,很少用 |
| super::非静态方法 | - | 3的特例,很少用 |
特例
对于无需返回值的函数接口,例如Consumer和Runnable,它们可以配合有返回值的函数对象使用。(实际的函数对象多出的返回值也不影响使用)
package com.itheima.day2.methodref;import java.util.function.Consumer;
import java.util.function.Function;public class MethodRef7 {public static void main(String[] args) {Consumer<Object> x = MethodRef7::print1;Function<Object, Integer> y = MethodRef7::print2;Consumer<Object> z = MethodRef7::print2; // 忽略返回值}static void print1(Object obj) {System.out.println(obj);}static int print2(Object obj) {System.out.println(obj);return 1;}
}
练习1:写出等价的方法引用
(1)类名::静态方法名
Lambda:Function<String, Integer> lambda = (String s) -> Integer.parseInt(s);
方法引用:Function<String, Integer> lambda1 = Integer::parseInt;
(2)类名::非静态方法名
Lambda:BiPredicate<List<String>, String> lambda2 = (list, element) -> list.contains(element);
方法引用:BiPredicate<List<String>, String> lambda2 = List::contains;
(3)类名::非静态方法名
Lambda:BiPredicate<Student, Object> lambda3 = (stu, obj) -> stu.equals(obj);
方法引用:BiPredicate<Student, Object> lambda3 = Student::equals;(4)类名::非静态方法名
Lambda: Predicate<File> lambda4 = (file) -> file.exists();
方法引用:Predicate<File> lambda4 = File::exists;
(5)对象::非静态方法
Runtime runtime = Runtime.getRuntime();
Lambda:Supplier<Long> lambda5 = () -> runtime.freeMemory();
方法引用:Supplier<Long> lambda5 = Runtime.getRuntime()::freeMemory;
练习2:方法引用 + 自定义函数式接口
package com.itheima.day2.exercise;public class Exercise5 {record Color(Integer red, Integer green, Integer blue) { }// 如果想用 `Color::new` 来构造 Color 对象,还应当补充哪些代码public static void main(String[] args) {TernaryFunction lambda = Color::new; // (Integer, Integer, Integer) -> ColorColor white = lambda.create(255, 255, 255);System.out.println(white);}@FunctionalInterfaceinterface TernaryFunction {// 三元Color create(Integer red, Integer green, Integer blue);}
}
练习3:类名::静态方法 || 类名::非静态方法
package com.itheima.day2.exercise;import java.util.List;
import java.util.function.Predicate;public class Exercise6 {record Student(String name, int age) {boolean abc() {return this.age() >= 18;}}/*传入参数时,分别用类名::静态方法类名::非静态方法来表示【学生年龄大于等于18】的条件*/static void highOrder(Predicate<Student> predicate) {List<Student> list = List.of(new Student("张三", 18),new Student("李四", 17),new Student("王五", 20));for (Student stu : list) {if (predicate.test(stu)) {System.out.println(stu + "通过测试");}}}static boolean ageGreaterOrEquals18(Student student) {return student.age() >= 18;}public static void main(String[] args) {// 类名::静态方法highOrder(Exercise6::ageGreaterOrEquals18);// 类名::非静态方法highOrder(Student::abc);/*(Student stu) -> stu.abc()*/}
}
4. 闭包和柯里化
4.1 闭包
问题1:什么是闭包?
- 闭包就是函数对象与外界变量绑定在一起,形成的整体。
- 或 闭包是指有个函数可以访问并记住其外部作用域的变量,即使该函数在外部作用域之外执行。
关键特点:
- 函数 + 环境:闭包不仅是一个函数,还包含其定义时的词法作用域(lexical scope)
- 变量捕获:闭包可以捕获外部变量,并保持对这些变量的引用(即使外部函数已执行完毕)
- 常见场景:在函数式编程、回调、延迟计算等场景中使用。
示例代码1:
public class ClosureTest1 {interface Lambda {int add(int y);}public static void main(String[] args) {int x = 10;highOrder(y -> x + y);}static void highOrder(Lambda lambda) {System.out.println(lambda.add(20));}
}代码解析:
- 代码中的 y -> x + y 和 x = 10,就形成了一个闭包;
- 可以想象成,函数对象有个背包,背包里可以装变量随身携带,将来函数对象甭管传递到多远的地方,包里总装着个 x = 10;
- 有个限制,局部变量x必须是final或effective final的,effective final意思就是,虽然没有用final修饰,但就像是用final修饰了一样,不能重新赋值,否则就语法错误;
- 意味着闭包变量,在装进包里的那一刻开始就不能变化了;
- 道理也简单,为了保证函数的不变性。
- 闭包是一种给函数执行提供数据的手段,函数执行既可以使用函数入参还可以使用闭包变量
示例代码2:闭包作用:给函数对象提供除参数以外的数据
public class ClosureTest2 {// 闭包作用:给函数对象提供参数以外的数据public static void main(String[] args) throws IOException {// 创建 10 个任务对象,并且每个任务对象给一个任务编号List<Runnable> list = new ArrayList<>();for (int i = 0; i < 10; i++) {int k = i + 1;Runnable task = () -> System.out.println(Thread.currentThread()+":执行任务" + k);list.add(task);}ExecutorService service = Executors.newVirtualThreadPerTaskExecutor();for (Runnable task : list) {service.submit(task);}System.in.read();}
}问题2:闭包的限制?
Java的闭包(Lambda/方法引用)相比其它语言(如JavaScript、Python)有以下限制:
(1)只能捕获final或等效final的变量
- 被闭包捕获的变量必须是final或不可变(不能再闭包外修改),即变量引用不可变。
- 示例(错误):
int x = 10;
Runnable r = () -> System.out.println(x++); // 编译错误:x 必须是 final 或 effectively final(2)不能修改捕获的变量
- 闭包内部不能修改外部变量
- 示例(错误):
int x = 10;
Runnable r = () -> x = 20; // 编译错误:x 不能被修改(3)不支持真正的“可变状态”闭包
- 其它语言(如JavaScript)允许闭包修改外部变量,但Java不允许
- 替代方案:使用AtomicInteger、数组等可变容器绕过限制:
int[] x = {10}; // 使用数组模拟可变变量
Runnable r = () -> x[0]++; // 合法,因为数组引用未变(4)不能捕获this(除非是实例方法引用)
- Lambda中的this指向外部类,而非Lambda自身(与匿名内部类不同)。
问题3:闭包的作用?
(1)封装状态
- 闭包可以隐藏变量,避免全局污染,同时保持对变量的访问权。
- 示例:计数器工厂
public static Supplier<Integer> createCounter() {int[] count = {0}; // 被闭包捕获return () -> ++count[0]; // 返回一个闭包
}
public static void main(String[] args) {Supplier<Integer> counter = createCounter();System.out.println(counter.get()); // 1System.out.println(counter.get()); // 2
}(2)回调函数
- 闭包可以传递行为(如事件处理器、线程任务)。
- 示例:按钮点击事件
button.setOnAction(event -> System.out.println("Clicked!")); // Lambda 作为闭包(3)延迟执行
- 闭包可以保存计算逻辑,在需要时才执行。
- 示例:延迟加载
Supplier<String> lazyMessage = () -> "Hello, " + getName(); // 闭包捕获 getName()
System.out.println(lazyMessage.get()); // 此时才执行 getName()(4)函数组合与高阶函数
- 闭包可以作为参数或返回值,支持函数式编程风格。
- 示例:函数工厂
Function<Integer, Integer> adder(int x) { // 返回一个闭包return y -> x + y; // 捕获 x
}
Function<Integer, Integer> add5 = adder(5);
System.out.println(add5.apply(3)); // 8示例代码:
package com.itheima.day2.closure;public class ClosureTest1 {@FunctionalInterfaceinterface Lambda {int op(int y);}static void highOrder(Lambda lambda) {System.out.println(lambda.op(1));}public static void main(String[] args) {/*函数对象 (int y) -> x + y 与它外部的变量 x 形成了闭包effective final*/final int x = 10;highOrder((int y) -> x + y);// --------------------------------Student stu = new Student(20);Lambda lambda = y -> y + stu.d;highOrder(lambda);// 变量引用不可变,而非“对象内容不可变”stu.d = 40;highOrder(lambda);}static class Student {int d;public Student(int d) {this.d = d;}}static int a = 1;int b = 2;public void test(int c) {highOrder(y -> a + y);highOrder(y -> b + y);highOrder(y -> c + y);}
}
问题:在Java的闭包中,捕获的外部变量必须是final或等效final,即变量引用不可变。但为什么下面的代码可以修改stu.d并执行highOrder(lambda)?
Student stu = new Student(20);
Lambda lambda = y -> y + stu.d; // 捕获 stu.d
stu.d = 40; // 修改 stu.d
highOrder(lambda); // 输出 41(1 + 40)原因分析:
(1)Java闭包的限制是“变量引用不可变”,而非“对象内容不可变”
- final或effectively final限制的是变量(引用)的重新赋值,而不是对象内部字段的修改。
- 在代码中:
- stu是一个对象引用,且stu本身没有被重新赋值(如stu = new Student(30);会报错)。
- stu.d是对象的字段,可以自由修改,因为闭包捕获的是stu的引用,而不是d的值。
(2)闭包捕获的是引用,而非值
- 当Lambda y -> y + stu.d 捕获stu时:
- 它保存的是stu的引用(内存地址),而不是stu.d的当前值(20)
- 后续修改stu.d = 40时,Lambda仍然通过stu的引用访问最新的d值
(3)反例:如果尝试修改stu引用本身,会编译报错
Student stu = new Student(20);
Lambda lambda = y -> y + stu.d;
stu = new Student(40); // 编译错误:Variable 'stu' must be final or effectively final底层原理:
Java的Lambda闭包是通过“捕获变量引用”实现的:
- 如果捕获的是局部变量(如int x),Java会隐式将其视为final,并复制值到Lambda中。
- 如果捕获的是对象字段(如stu.d),Lambda会持有对象的引用,因此对象的内部状态可以变化。
4.2 柯里化
问题1:什么是柯里化?
- 柯里化(Currying)是一种将 多参数函数 转换为 一系列单参数函数 的技术。
- 它由数学家Haskell Curry提出,核心思想是:一个接受多个参数的函数,可以分解为多个接受单个参数的函数链。
示例1:
原始函数(未柯里化):
int add(int a, int b, int c) {return a + b + c;
}柯里化后的形式:
Function<Integer, Function<Integer, Function<Integer, Integer>>> curriedAdd = a -> b -> c -> a + b + c;调用方式:
int result = curriedAdd.apply(1).apply(2).apply(3); // 1 + 2 + 3 = 6示例2:
package com.itheima.day2.currying;public class Carrying0Test {@FunctionalInterfaceinterface F2 {int op(int a, int b);}@FunctionalInterfaceinterface Fa {Fb op(int a);}@FunctionalInterfaceinterface Fb {int op(int b);}public static void main(String[] args) {// 两个参数的函数对象F2 f2 = (a, b) -> a + b;System.out.println(f2.op(10, 20));/* 改造(a) -> 返回另一个函数对象(b) -> a+b*/Fa fa = (a) -> (b) -> a + b;Fb fb = fa.op(10);int r = fb.op(20);System.out.println(r);}}
示例3:
public class Carrying1Test {public static void main(String[] args) {highOrder(a -> b -> a + b);}static void highOrder(Step1 step1) {Step2 step2 = step1.exec(10);System.out.println(step2.exec(20));System.out.println(step2.exec(50));}interface Step1 {Step2 exec(int a);}interface Step2 {int exec(int b);}
}代码解析:
- a -> 是第一个函数对象,它的返回结果是 b-> 是第二个函数对象
- 后者与前面的参数a构成了闭包
- step1.exec(10)确定了a的值是10,返回第二个函数对象step2,a被放入了step2对象的背包记下来了;
- step2的exec(2)确定了b的值是20,此时可以执行a + b的操作,得到结果30
- step2.exec(50)分析过程类似
示例4:分布合并多个列表,通过函数式接口的链式调用逐步传递数据
package com.itheima.day2.currying;import java.util.ArrayList;
import java.util.List;public class Carrying1Test {/*柯里化思想:将 "(a, b, c) -> 合并逻辑" 拆解为 "a -> b -> c -> 合并逻辑"*/@FunctionalInterfaceinterface Fa {Fb op(List<Integer> a); // 接收列表a,返回处理b的函数}@FunctionalInterfaceinterface Fb {Fc op(List<Integer> b); // 接收列表b,返回处理c的函数}@FunctionalInterfaceinterface Fc {List<Integer> op(List<Integer> c); // 处理列表c,返回最终合并结果}/*目标:把三份数据合在一起,逻辑既定,但数据不能一次得到a -> 函数对象b -> 函数对象c -> 完成合并*/static Fb step1() {List<Integer> x = List.of(1, 2, 3); // 初始化数据aFa fa = a -> b -> c -> {// 柯里化合并逻辑List<Integer> list = new ArrayList<>();list.addAll(a);list.addAll(b);list.addAll(c);return list;};// 固定 a=x,返回处理b的函数Fbreturn fa.op(x);}static Fc step2(Fb fb) {List<Integer> y = List.of(4, 5, 6); // 数据breturn fb.op(y); // 固定b=y,返回处理c的函数Fc}static void step3(Fc fc) {List<Integer> z = List.of(7, 8, 9); // 数据cList<Integer> result = fc.op(z); // 合并a、b、cSystem.out.println(result); // 输出 [1, 2, 3, 4, 5, 6, 7, 8, 9]}public static void main(String[] args) {step3(step2(step1())); // 链式调用}
}
问题2:如何实现柯里化?
在Java中,可以通过函数式接口和Lambda表达式实现柯里化。以下是具体步骤:
方式1:手动柯里化
import java.util.function.Function;public class CurryingExample {// 原始函数static int add(int a, int b, int c) {return a + b + c;}// 柯里化后的函数static Function<Integer, Function<Integer, Function<Integer, Integer>>> curriedAdd() {return a -> b -> c -> add(a, b, c);}public static void main(String[] args) {// 分步调用Function<Integer, Function<Integer, Integer>> step1 = curriedAdd().apply(1);Function<Integer, Integer> step2 = step1.apply(2);int result = step2.apply(3); // 输出 6// 链式调用int result2 = curriedAdd().apply(1).apply(2).apply(3); // 输出 6}
}方式2:通过柯里化工具
import java.util.function.BiFunction;
import java.util.function.Function;public class CurryingUtils {// 将 BiFunction 柯里化static <T, U, R> Function<T, Function<U, R>> curry(BiFunction<T, U, R> biFunction) {return t -> u -> biFunction.apply(t, u);}public static void main(String[] args) {BiFunction<Integer, Integer, Integer> add = (a, b) -> a + b;Function<Integer, Function<Integer, Integer>> curriedAdd = curry(add);int result = curriedAdd.apply(1).apply(2); // 输出 3}
}问题3:柯里化的作用?让函数分步执行
柯里化不仅是一种理论概念,还有以下实际用途:
(1)参数复用(Partial Application)
- 固定部分参数,生成新函数。
- 示例:
Function<Integer, Function<Integer, Integer>> curriedAdd = a -> b -> a + b;
Function<Integer, Integer> add10 = curriedAdd.apply(10); // 固定 a=10
System.out.println(add10.apply(5)); // 输出 15(10 + 5)
System.out.println(add10.apply(15)); // 输出 25(10 + 15)(2)延迟计算(Lazy Evaluation)
- 分步传入参数,按需触发计算。
- 示例:
Function<Integer, Function<Integer, Function<Integer, Integer>>> curriedAdd = a -> b -> c -> a + b + c;
Function<Integer, Function<Integer, Integer>> step1 = curriedAdd.apply(1);
// 稍后传入剩余参数...
int result = step1.apply(2).apply(3); // 输出 6(3)增强代码组合性
- 将复杂函数拆分为可组合的小函数。
- 示例:字符串处理
Function<String, Function<String, String>> concatWith = prefix -> suffix -> prefix + " " + suffix;
Function<String, String> greet = concatWith.apply("Hello");
System.out.println(greet.apply("World")); // 输出 "Hello World"(4)函数式编程兼容性
- 适应需要单参数函数的场景(如流式操作、高阶函数)。
- 示例:结合Stream API
// 假设的 CurryingUtils 类(实际需自行实现)
class CurryingUtils {// 将 BiFunction 柯里化为 Function<T, Function<U, R>>public static <T, U, R> Function<T, Function<U, R>> curry(BiFunction<T, U, R> biFunction) {return t -> u -> biFunction.apply(t, u);}
}List<Integer> numbers = List.of(1, 2, 3);
Function<Integer, Integer> add5 = CurryingUtils.curry((a, b) -> a + b).apply(5);
numbers.stream().map(add5).forEach(System.out::println); // 输出 6, 7, 8-
(a, b) -> a + b是一个BiFunction<Integer, Integer, Integer>,表示普通的加法。 -
CurryingUtils.curry((a, b) -> a + b)返回柯里化后的函数:
Function<Integer, Function<Integer, Integer>>(即a -> b -> a + b)。 -
.apply(5)固定第一个参数a=5,返回一个新的函数b -> 5 + b,赋值给add5。-
此时
add5的类型是Function<Integer, Integer>。
-
5. 高阶函数
问题1:什么是高阶函数
所为高阶,就是指它是其它函数对象的使用者。高阶函数是指满足以下任意条件的函数:
- 接收函数作为参数;
- 返回一个函数作为结果。
在函数式编程中,高阶函数是核心概念,它允许将函数像普通数据一样传递和操作。
作用:
- 将通用、复杂的逻辑隐含在高阶函数内
- 将易变、未定的逻辑放在外部的函数对象中
示例1:接收函数作为参数
import java.util.function.Function;public class HigherOrderExample {// 高阶函数:接收一个函数作为参数static int operate(int x, Function<Integer, Integer> func) {return func.apply(x);}public static void main(String[] args) {// 传递 Lambda 表达式(函数)int result = operate(5, n -> n * 2); // 输出 10System.out.println(result);}
}- operate是高阶函数,因为它接收Function<Integer, Integer>作为参数。
示例2:返回函数作为结果
import java.util.function.Function;public class HigherOrderExample {// 高阶函数:返回一个函数static Function<Integer, Integer> multiplyBy(int factor) {return x -> x * factor; // 返回一个 Lambda 表达式(函数)}public static void main(String[] args) {Function<Integer, Integer> doubleIt = multiplyBy(2);System.out.println(doubleIt.apply(5)); // 输出 10}
}- multiplyBy是高阶函数,因为它返回一个Function。
Java内置高阶函数
Java标准库中大量使用了高阶函数,尤其是在java.util.function包和Stream API中:
(1)Stream API的map、filter、reduce
List<Integer> numbers = List.of(1, 2, 3);
// map 接收一个函数(高阶函数)
List<Integer> doubled = numbers.stream().map(x -> x * 2) // 传递 Lambda.toList(); // [2, 4, 6](2)Comparator.comparing
List<String> names = List.of("Alice", "Bob", "Charlie");
// comparing 接收一个函数(高阶函数)
names.sort(Comparator.comparing(String::length)); // 按字符串长度排序高阶函数的典型应用场景
| 场景 | 说明 | 示例 |
|---|---|---|
| 回调机制 | 将函数作为参数传递,延迟执行逻辑(如事件监听)。 | button.setOnAction(event -> System.out.println("Clicked!")); |
| 策略模式 | 动态切换算法或行为。 | Collections.sort(list, (a, b) -> b.compareTo(a));(降序排序) |
| 函数组合 | 将多个函数组合成新函数(如 andThen、compose)。 | Function<Integer, Integer> func = ((Function<Integer, Integer>) x -> x + 1).andThen(x -> x * 2); |
| 延迟计算 | 通过返回函数实现懒加载。 | Supplier<String> lazyValue = () -> expensiveOperation(); |
5.1 内循环
示例1:将 遍历逻辑 和 元素处理逻辑 解耦
- 需求:逆序遍历一个不可变集合,并对每个元素执行自定义操作(如打印)
package com.itheima.day2.hiorder;import java.util.List;
import java.util.ListIterator;
import java.util.function.Consumer;public class C01InnerLoop {public static void main(String[] args) {List<Integer> list = List.of(1, 2, 3, 4, 5, 6, 7);// 需求:逆序遍历集合,只想负责元素处理,不改变集合hiOrder(list, (value) -> System.out.println(value));}public static <T> void hiOrder(List<T> list, Consumer<T> consumer) {ListIterator<T> iterator = list.listIterator(list.size());while (iterator.hasPrevious()) {T value = iterator.previous();consumer.accept(value);}}
}
- hiOrder负责遍历逻辑(逆序)
- Consumer参数负责元素处理逻辑(如打印、计算等)
- 灵活性:通过传递不同的Consumer,可以动态改变对元素的操作,而无需修改遍历逻辑。
示例2:二叉树的遍历与处理
package com.itheima.day2.hiorder;import java.util.LinkedList;
import java.util.function.Consumer;public class C02BinaryTree {public record TreeNode(int value, TreeNode left, TreeNode right) {public String toString() {return "%d ".formatted(value);}}enum Type {PRE, IN, POST}public static void traversal2(TreeNode root, Type type, Consumer<TreeNode> consumer) {if (root == null) {return;}// 前序处理值if (type == Type.PRE) {consumer.accept(root);}// 递归左子树traversal2(root.left, type, consumer);// 中序处理值if (type == Type.IN) {consumer.accept(root);}// 递归右子树traversal2(root.right, type, consumer);// 后序处理值if (type == Type.POST) {consumer.accept(root);}}// 通过栈模拟递归,避免递归的栈溢出风险public static void traversal(TreeNode root, Type type, Consumer<TreeNode> consumer) {// 用来记住回去的路LinkedList<TreeNode> stack = new LinkedList<>();// 当前节点TreeNode curr = root;// 记录最近一次处理完的节点TreeNode last = null;// 没有向左走到头或者还有未归的路while (curr != null || !stack.isEmpty()) {// 左边未走完if (curr != null) {// 记住来时的路stack.push(curr);// ------------------ 处理前序遍历的值if(type == Type.PRE) {consumer.accept(curr);}// 下次向左走curr = curr.left;}// 左边已走完else {// 上次的路TreeNode peek = stack.peek();// 没有右子树if (peek.right == null) {// ------------------ 处理中序、后序遍历的值if(type == Type.IN || type == Type.POST) {consumer.accept(peek);}last = stack.pop();}// 有右子树, 已走完else if (peek.right == last) {// ------------------ 处理后序遍历的值if (type == Type.POST) {consumer.accept(peek);}last = stack.pop();}// 有右子树, 未走完else {// ------------------ 处理中序遍历的值if (type == Type.IN) {consumer.accept(peek);}// 下次向右走curr = peek.right;}}}}public static void main(String[] args) {/*1/ \2 3/ / \4 5 6前序 1 2 4 3 5 6 值左右中序 4 2 1 5 3 6 左值右后序 4 2 5 6 3 1 左右值*/TreeNode root = new TreeNode(1,new TreeNode(2,new TreeNode(4, null, null),null),new TreeNode(3,new TreeNode(5, null, null),new TreeNode(6, null, null)));// 前序遍历traversal2(root, Type.PRE, System.out::print); // 解耦节点遍历逻辑与处理逻辑System.out.println();// 中序遍历traversal2(root, Type.IN, System.out::print);System.out.println();// 后序遍历traversal2(root, Type.POST, System.out::print);System.out.println();}
}示例3:Stream流
package com.itheima.day2.hiorder;import java.util.*;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.function.*;public class C04SimpleStream<T> {public static void main(String[] args) {List<Integer> list = List.of(1, 2, 3, 4, 5, 1, 2, 3);/*统计元素出现次数key value1 22 23 24 15 1*/HashMap<Integer, Integer> collect4 = C04SimpleStream.of(list).collect(HashMap::new, (map, t) -> {if (!map.containsKey(t)) {map.put(t, 1);} else {Integer v = map.get(t);map.put(t, v + 1);}});System.out.println(collect4);System.out.println("-----------------------------");/*如果 key 在 map 中不存在,将 key 连同新生成的 value 值存入 map, 并返回 value如果 key 在 map 中存在,会返回此 key 上次的 value 值1, 2, 3, 4, 5, 1, 2, 3key value1 AtomicInteger(2)2 AtomicInteger(2)3 AtomicInteger(2)4 AtomicInteger(1)5 AtomicInteger(1)*/HashMap<Integer, AtomicInteger> collect5 = C04SimpleStream.of(list).collect(HashMap::new, (map, t) -> map.computeIfAbsent(t, k -> new AtomicInteger()).getAndIncrement());System.out.println(collect5);// 1. 简单的Stream流 C04SimpleStream.of(list).filter(x -> (x & 1) == 1) // 过滤奇数 .map(x -> x * x).forEach(System.out::println);// 2. 简单流 - 化简(两个元素,按照某种规则合并为一个)// 两个元素相加 -> 求和System.out.println(C04SimpleStream.of(list).reduce(0, Integer::sum));// 两个元素里挑小的 -> 求最小值System.out.println(C04SimpleStream.of(list).reduce(Integer.MAX_VALUE, Math::min));// 两个元素里挑大的 -> 求最大值System.out.println(C04SimpleStream.of(list).reduce(Integer.MIN_VALUE, Math::max));// 3. 简单流 - 收集HashSet<Integer> collect1 = C04SimpleStream.of(list).collect(HashSet::new, HashSet::add); // HashSet::add (set,t)->set.add(t)System.out.println(collect1);StringBuilder collect2 = C04SimpleStream.of(list).collect(StringBuilder::new, StringBuilder::append);System.out.println(collect2);C04SimpleStream.of(list).collect(()->new StringJoiner("-"), (joiner, t)-> joiner.add(String.valueOf(t)));StringJoiner collect3 = C04SimpleStream.of(list).map(t -> String.valueOf(t)).collect(() -> new StringJoiner("-"), StringJoiner::add);System.out.println(collect3);// (StringJoiner, Integer) -> void// (StringJoiner, CharSequence) -> void}// ----------------------------------// 收集操作// C 代表容器类型, supplier 用来创建容器public <C> C collect(Supplier<C> supplier, BiConsumer<C, T> consumer) {C c = supplier.get(); // 创建了容器for (T t : collection) {consumer.accept(c, t); // 向容器中添加元素}return c;}// -----------------------------// 归约操作 - 将流中的元素两两合并// o 代表 p 的初始值public T reduce(T o, BinaryOperator<T> operator) {T p = o; // 上次的合并结果for (T t : collection) { // t 是本次遍历的元素p = operator.apply(p, t);}return p;}// --------------------------------// 过滤操作public C04SimpleStream<T> filter(Predicate<T> predicate) {List<T> result = new ArrayList<>();for (T t : collection) {if (predicate.test(t)) {result.add(t);}}return new C04SimpleStream<>(result);}// 映射操作public <U> C04SimpleStream<U> map(Function<T, U> function) {List<U> result = new ArrayList<>();for (T t : collection) {U u = function.apply(t);result.add(u);}return new C04SimpleStream<>(result);}// 遍历操作public void forEach(Consumer<T> consumer) {for (T t : collection) {consumer.accept(t);}}// ----------------------------public static <T> C04SimpleStream<T> of(Collection<T> collection) {// 工厂方法return new C04SimpleStream<>(collection);}private Collection<T> collection;private C04SimpleStream(Collection<T> collection) {this.collection = collection;}}