描述性统计的可视化分析
初步研究数据的分布时,最直观的方法就是可视化分析了。
1. 直方图
直方图(histogram)出现得很早,而且应用广泛。
直方图是以一种图形方法来概括给定数值X的分布情况的图示。
如果X是离散的变量,比如股票类型,则对于X的每个已知的值,画一个柱或竖直条。条的高度表示该X值出现的频率(即计数)。这种图更多地被称为条形图(bar chart)。
如果X是连续型变量,比如股票的市盈率,则会更多地使用术语直方图。在术语直方图里,X的值域被划分成不相交的连续子域。子域称为桶(bucket)或箱(bin),是X的数据分布的不相交子集。桶的范围称为宽度。通常,每个桶都是等宽的。比如,值为1~100的价格属性可以划分成子域1~20、21~40、41~60,等等。对于每个子域,画一个条,其高度表示在该子域观测到的商品的计数。
有时候,我们需要比较两个数据集的差异。如何最直观地比较两个数据分布的差异呢?答案就是将两个数据分布画在一张图上。
假设生成两个正态分布的数据集。
数据集1:均值为-1,标准差为2,1000个样本。
数据集2:均值为0,标准差为1,5000个样本。
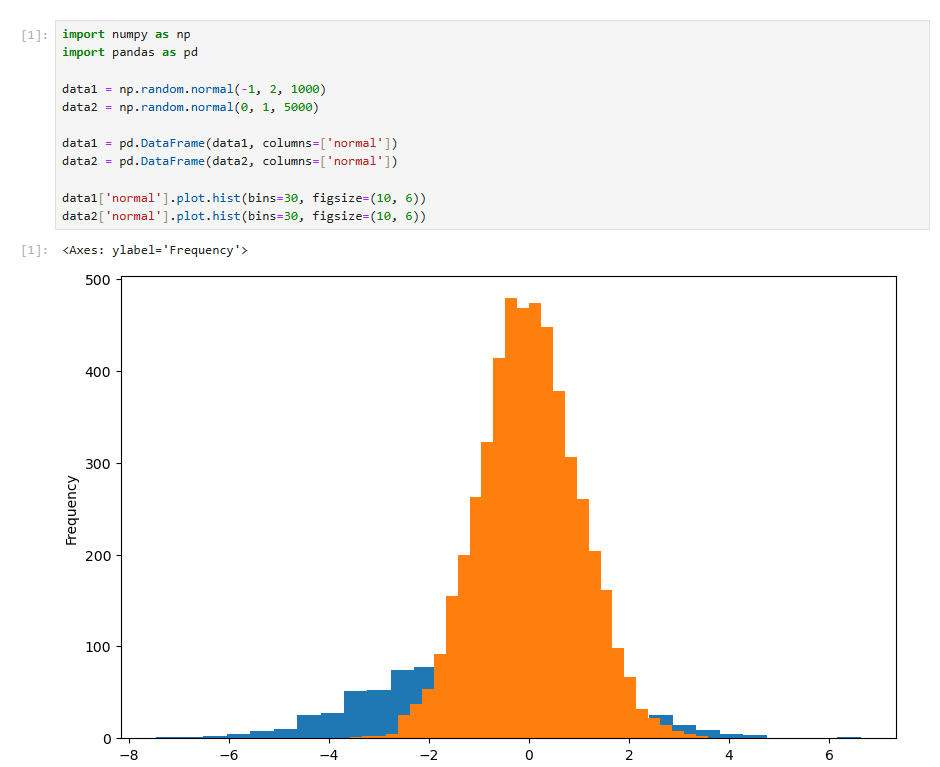
这个图蓝色的区域被红色大面积挡住了,看不太清楚,怎么办呢?可以加入一个参数alpha=0.5,增加图形的透明度。
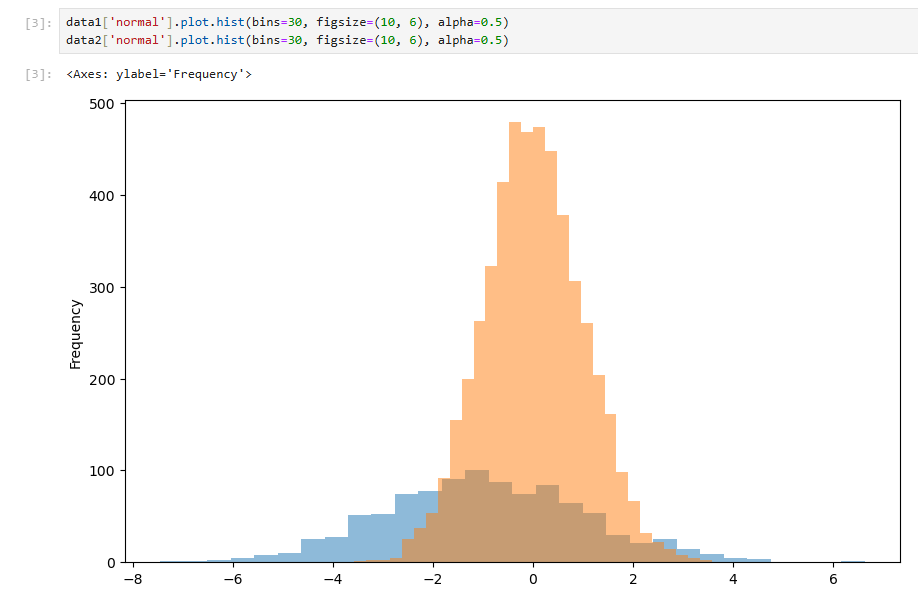
有了透明效果,两个分布就都能看到了。还有一个问题,数据集2有5000个样本,远多于数据集1的1000个。这里默认画的是绝对数量(默认是频数图),所以数据集2看起来要格外高一些。
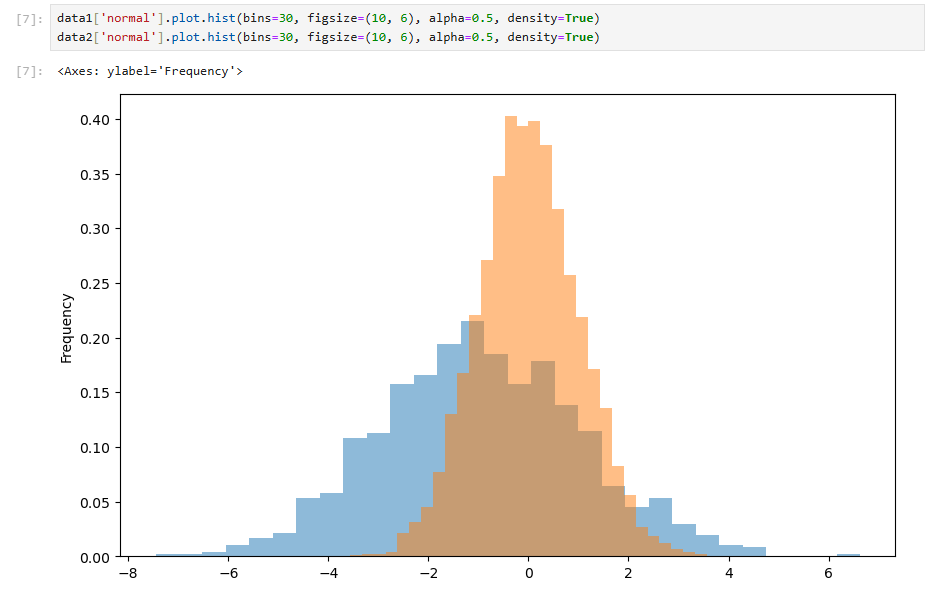
但我们需要的是相对概率,而不是绝对数量。因此可以再加入一个参数density=True(绘制频率图),来比较概率分布。
2. 散点图
散点图(scatter plot)是确定两个数值变量X、Y之间看上去是否存在联系,以及具有怎样的相关模式的最有效的图形方法之一。
为构造散点图,将每个值对(x,y)视为一个代数坐标对,并作为一个点画在平面上。
散点图是一种观察双变量数据的有效方法。两个属性X和Y,如果一个属性和另一个属性有关系,则它们是相关的。相关可能是正的、负的或不相关。
如果标绘点的模式是从左下向右上倾斜,则意味X的值随着Y值的增加而增加了,表示正相关。
如果标绘点的模式从左上向右下倾斜,则意味着X的值随着Y值的减小而增加了,表示负相关。
可以画一条最佳拟合线,研究变量之间的相关性。
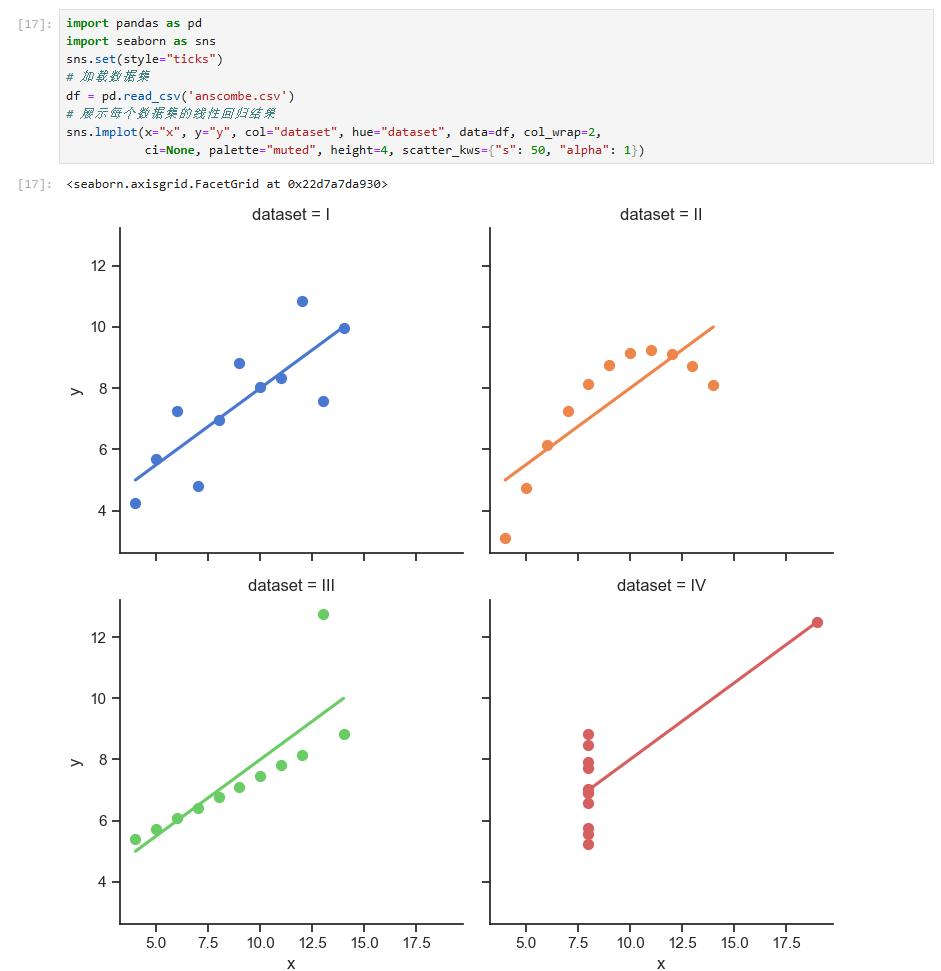
这里使用的是seaborn自带的一个数据集。这个数据集里面总共有四组数据,用罗马数字来代表组数。
我们只需要按类似的格式将数据整理好,就可以使用seaborn.lmplot来画出各组的散点图,而且顺便也能将各组的线性回归直线也画出来。
从图中可以看出,第1组和第3组的x,y值是正相关的。第2组的似乎是一个二次曲线。第4组除了一个异常点之外,其他所有点的x都是相同的。
这就是seaborn的好处,可以非常方便地用一个函数分析出不同数据组之间的相关性。
想了解 seaborn.lmplot 各个参数的具体含义请查看官网介绍。
3. 盒图
为了更加全面地了解一个分布,五数概括是一个很好的工具。
五数概括由中位数、两个四分数、最小、最大值组成。按次序分别表示为Minimum,Q1,Median,Q3,Maximum。
盒图(boxplot)是一种流行的分布的图形表示。盒图就体现了五数概括的特点。
- 盒的端点一般在四分位数上,使得盒的长度是四分位数极差IQR。
- 中位数用盒内的线标记。
- 盒外的两条线延伸到最小和最大的观测值。
seaborn也可以非常方便地画出盒图。
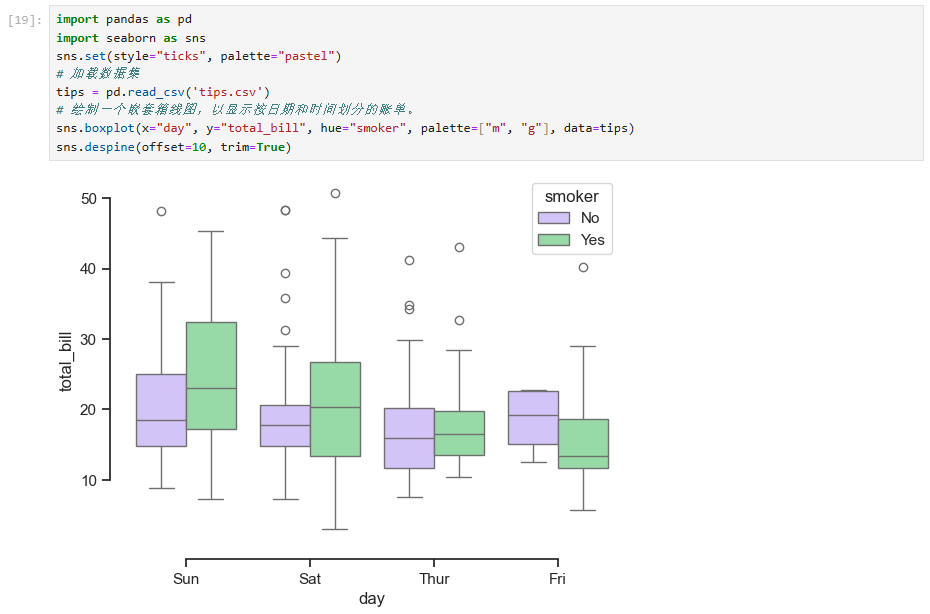
这里也是使用了seaborn自带的数据集。这个数据集有好几个维度,比如sex(性别)、smoker(是否吸烟)、day(星期几)。统计数据有total_bill(总账单)、tip(小费)。
以上代码是将day作为x轴,用smoker作为第二维度,画出了total_bill的盒图(数据分布)。最中间的线就是中位数,实体上下边缘是四分位数,上下影线是最大最小值、灰点是异常值。
我们也可以将第二维度选为sex,只需要将函数中的参数hue换为sex即可。
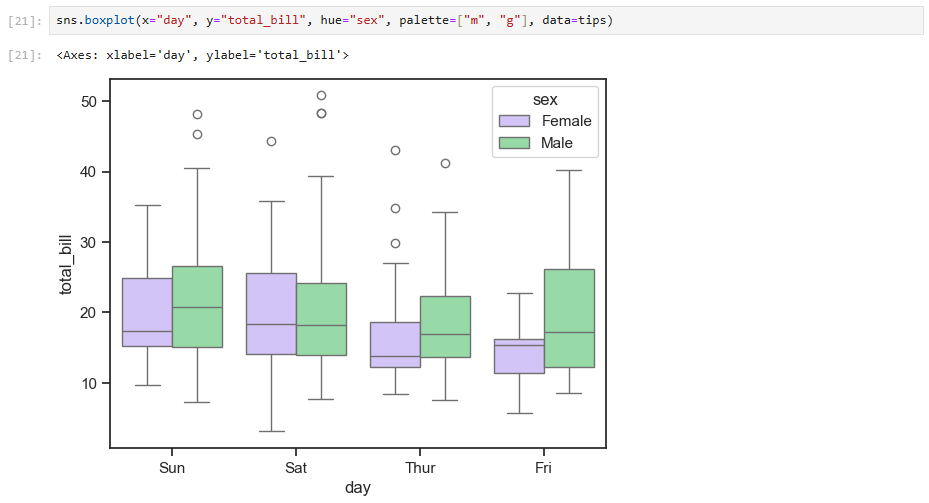
可以看到图例变为了sex。