【C++】入门基础知识(1.5w字详解)
本篇博客给大家带来的是一些C++基础知识!包含函数栈帧的详解!
🐟🐟文章专栏:C++
🚀🚀若有问题评论区下讨论,我会及时回答
❤❤欢迎大家点赞、收藏、分享!
今日思想:微事不通,粗事不能者,必劳;大事不得,小事不为者,必贫——刘向!

一、C++简介
C++是在C语言的基础上完善C语言的不足(表达能力、可维护性、可扩展性)而发展而来的一门语言,它是由Bjarne Stroustrup(本贾尼 斯特劳斯特卢普)命名并完善。
C++和C语言的区别:
C语言:面向过程。C++:面向对象和泛型编程。
C++:由于C++是在C语言的基础上完善而来的一门语言,它比C语言更加便捷,很多人学习了这门语言之后都不想写C语言了。
二、C++的重要性
论述一门编程语言的重要性我们可以看它在各种语言的排名、能干些什么(仅个人观点)。
1、2025年5月TIOBE编程语言排行榜:
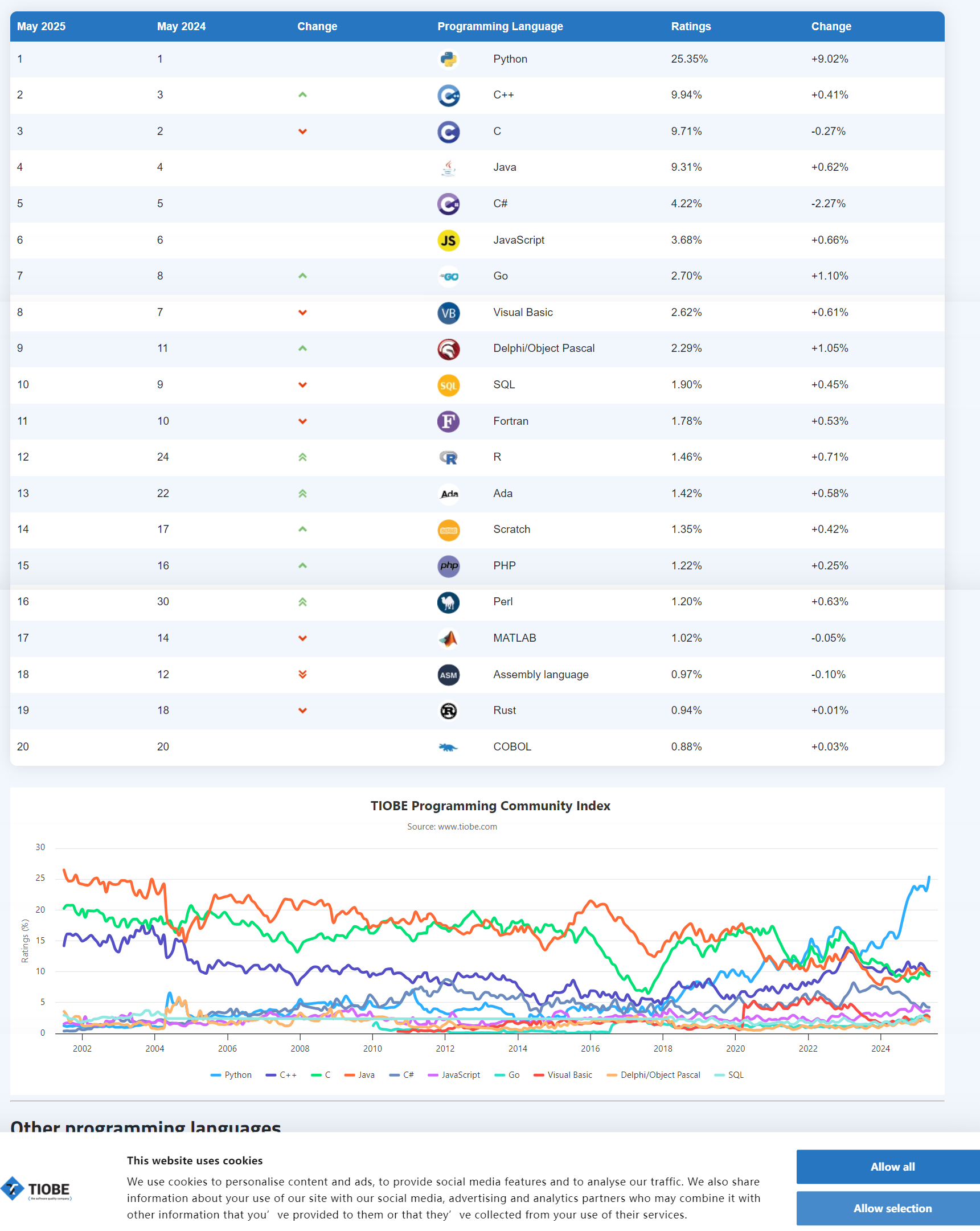
从上图我们可以看出在近几年C++的排名是在前5名的,这表明在各行各业C++起着至关重要的作用。
2、C++作用
1)大型系统软件开发。浏览器、操作系统、编译器等的开发。
2)音视频处理。FFmpeg、WebRTC等开发最主要的技术栈就是C++。
3)PC客户端开发。开发Windows上的桌面软件。
4)服务端开发。游戏服务、流媒体服务、量化高频交易服务等的开发。
5)游戏引擎开发。开发游戏的。
6)嵌入式开发。把具有技术能力的主控板嵌入到机器装置或者电子装置的内部,通过软件来控制这些装置。如:智能手环、摄像头、扫地机器人等。
7)机器学习引擎。底层用C++来实现,上层用python封装起来。
8)测试开发测试。根据产品来设计测试用例,然后手动的方式进行测试。
三、C++推荐书籍
1)C++Primer:经典主讲C++语言语法的书籍。
2)STL源码剖析:从底层实现的角度结合STL源码来剖析STL的实现。
3 ) Effctive C++:主讲55个高效使用C++的条款。
四、C++第一个程序
我们之前一开始学C语言第一次编写的代码:
//C语言版
int main()
{printf("hello world\n");return 0;
}由于C++是在C语言的基础上完善的,它兼容C,那么我们可以在后缀为.cpp文件上实现C语言的代码。
那么我们怎么用C++来实现呢??
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#include<iostream>//初学阶段一旦我们使用流插入(cin)和流提取(cout)就要包含这个文件
using namespace std;//这里看不懂,往后学再回来看
//C++版int main()
{cout << "hello world" << endl;return 0;
}他们的区别是什么??
C++不用手写数据类型,而C语言要。
例如:
//C语言版
int main()
{char arr[] = "hello wolde";printf("%s\n",arr);return 0;
}//C ++版
int main()
{char arr[] = "hello wolde";cout << arr << endl;return 0;
}五、命名空间(namespace)
1、namespace的使用价值
在工作或者学习中我们自己定义的变量、类、函的名称有可能和库里面、其他人定义的一样,为了防止这样的情况出现,我们使用namespace就能能很好解决这样的问题。
2、namespace的定义
1)namespace的书写方式:namespace + 名字。
示例:
namespace LA
{}int main()
{return 0;
}注意:namespace只能写在全局域。他和结构体不一样。
2)命名空间里面可以写些什么?定义变量/函数/类型。
例如:
namespace LA
{int a = 0;int add(int x, int y){return x + y;}struct node{struct node* next;int data;};}3)在C++中有四个域:局部域、全局域、类域、命名空间域。不同域可以定义同名变量。
除了命名空间域和类域不影响变量生命周期,其他会影响生命周期。
例如:
namespace LA
{int a = 0;//命名空间域int add(int x, int y){return x + y;}struct node{struct node* next;int data;};}
//C语言版int a = 8;//全局域
int main()
{int a = 1;//局部域char arr[] = "hello wolde";printf("%s\n",arr);return 0;
}注意:如果访问同名变量,先访问局部再访问全局(就近原则)。如果要访问命名空间域的要使用域作用限定符( ::),::a 访问全局域的a,LA::a访问命名空间域的a。编译器默认的查找规则:先局部再全局。
4)在工作中,如果自己定义类型或者变量与其他人一样,各自可以把自己写的变量和类型放到的自己的命名空间域里面,这样就解决了命名冲突的问题。
5)命名空间域可以嵌套使用。一般只嵌套两层,多个嵌套的命名空间域会认为是一个命名空间域。
例如:
namespace LA
{int a = 0;//命名空间域namespace LB{int a = 10;}int add(int x, int y){return x + y;}struct node{struct node* next;int data;};}
//C语言版int a = 8;//全局域
int main()
{int a = 1;//局部域//char arr[] = "hello wolde";printf("%d\n",LA::LB::a);return 0;
}6)C++标准库放在std(standard)命名空间里面。
3、命名空间的使用
访问命名空间的三种方法:指定命名空间访问(::)、展开命名空间中全部成员、using将命名空间中某个成员展开。
域作用限定符之前讲过了,我们看看展开命名空间中全部成员:
1)展开命名空间中全部成员即:影响编译器的查找规则,此时他们从命名空间域变成了全局域了,不用使用域作用限定符就能访问。
示例:
namespace LA
{int a = 0;//命名空间域int b = 1;namespace LB{int a = 10;}int add(int x, int y){return x + y;}struct node{struct node* next;int data;};}
//C语言版
using namespace LA;
//int a = 8;//全局域
//using LA::b;int main()
{//int a = 1;//局部域//char arr[] = "hello wolde";printf("%d\n",a);注意:这样的冲突风险极大,项目不推荐。
2) 如果经常使用命名空间中的某个成员可以指定的把他展开:
例如:
namespace LA
{int a = 0;//命名空间域int b = 1;namespace LB{int a = 10;}int add(int x, int y){return x + y;}struct node{struct node* next;int data;};}
//C语言版
//using namespace LA;
//int a = 8;//全局域
using LA::b;int main()
{//int a = 1;//局部域//char arr[] = "hello wolde";printf("%d\n",b);return 0;
}因为我们经常使用C++中的cout、cin、endl(换行),所以我们一开始就展开标准库。
例如:
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#include<iostream>//初学阶段一旦我们使用流插入(cin)和流提取(cout)就要包含这个文件
using namespace std;如果不展开std,我们使用cout、cin等要指定std命名空间域:
#include<stdio.h>
#include<iostream>//初学阶段一旦我们使用流插入(cin)和流提取(cout)就要包含这个文件
//using namespace std;int main()
{std::cout << "hello world" << std::endl;return 0;
}六、C++输入和输出
我们一开始就<iostream>文件,iostream是Input Output Stream的缩小,是标准的输入输出库,定义了标准的输入和输出对象。
1)std::cin是istream类的对象,它主要面向窄字符的标准输入流。
2)std::cout是ostream类的对象,它主要面向窄字符的标准输出流。
3)std::endl是一个函数,流插入输出时,相当于插入一个换行字符加刷新缓冲区。
4)<<是流插入运算符,>>是流提取运算符。在C语言里面他们分别为位运算左移和右移。
5)使用C++的输入输出它不用像C语言那样指定类型,更加方便,其实它的本质就是运算符重载。
#include<iostream>//初学阶段一旦我们使用流插入(cin)和流提取(cout)就要包含这个文件
//using namespace std;int main()
{std::cout << "hello world" << '\n'<<"abc"<<std::endl;int a;std::cin >> a ;//不能使用换行return 0;
}6)我们包含<iosream>其实就包含了<stdio.h>,我们包含<stdio.h>也可以用printf和scanf函数(VS是这样,其他不知道)。
七、函数重载
C语言是不支持同名函数在同一个作用域的,而C++支持,不过C++对于同名函数的书写是有要求的,具体如下:
1)同名函数的形参不同。
#include<iostream>//初学阶段一旦我们使用流插入(cin)和流提取(cout)就要包含这个文件
using namespace std;int Add(int x)
{cout << "Add(int x,int y)"<<endl;return 1;
}int Add(char x, int y)
{cout << "Add(int x,int y)" << endl;return 4;
}int main()
{Add(1, 'a');Add('d', 1);return 0;
2)同名函数的类型不同。
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#include<iostream>//初学阶段一旦我们使用流插入(cin)和流提取(cout)就要包含这个文件
using namespace std;double Add(double x, double y)
{cout << "double" << endl;return x + y;
}int Add(int x, int y)
{cout << "int" << endl;return x + y;
}
int main()
{int a = 1;int b = 2;double a1 = 3.1;double b2 = 3.14;Add(a, b);Add(a1, b2);return 0;
}3)同名函数的参数个数不同。
using namespace std;void fun()
{cout << "void fun()" << "\n" << endl;
}void fun(int a)
{cout << "void fun(int a)" << "\n" << endl;
}int main()
{fun();int f = 1;fun(f);return 0;
}4)参数类型的顺序不同(本质是类型不同)。
#include<iostream>//初学阶段一旦我们使用流插入(cin)和流提取(cout)就要包含这个文件
using namespace std;int Add(int x, char y)
{cout << "Add(int x,int y)"<<endl;return 1;
}int Add(char x, int y)
{cout << "Add(int x,int y)" << endl;return 4;
}int main()
{Add(1, 'a');Add('d', 1);return 0;
}注意:返回值不同不能构成函数重载。
如:
int fun()
{return 2;
}
int fun()
{return 3;
}int main()
{/*int z = Add();cout << z << endl;*/fun();return 0;
}八、缺省参数(默认参数)
缺省参数是定义函数或者声明的时候指定一个缺省值,在调用该函数的时候如果没有指定实参就采用缺省值,否则就使用指定的实参。缺省参数分为全缺省参数和半缺省参数。
例如:
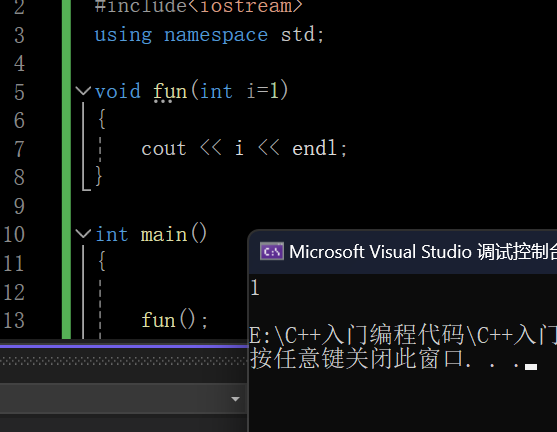
#include<iostream>
using namespace std;void fun(int i=1)
{cout << i << endl;
}int main()
{fun();return 0;
}打印结果:
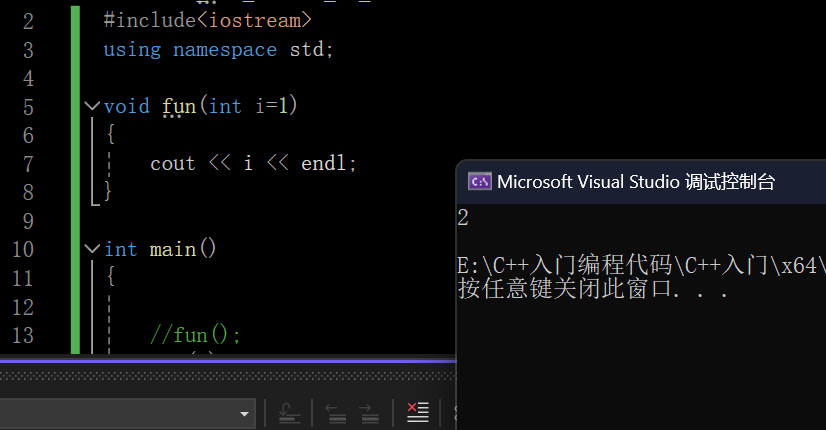
#include<iostream>
using namespace std;void fun(int i=1)
{cout << i << endl;
}int main()
{//fun();fun(2);return 0;
}打印结果:
1、全缺省
全缺省是全部形参都给缺省值。
例如:
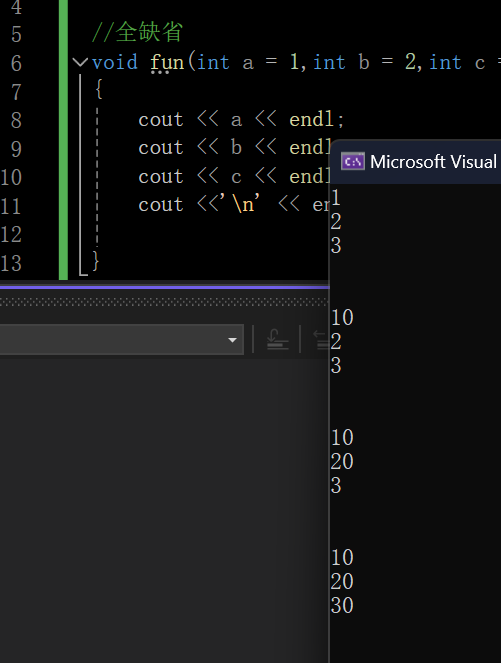
//全缺省
void fun(int a = 1,int b = 2,int c = 3)
{cout << a << endl;cout << b << endl;cout << c << endl;}int main()
{fun();//如果一个不传实参,就用缺省值来打印fun(10);//传一个则a=10,b,c就用缺省值来打印fun(10.20);//传两个实参,则a=10,b=20,c就用缺省值来打印fun(10, 20, 30);//传三个实参,就用这三个值来打印return 0;
}打印结果:
注意:不能跳跃给实参。
如:
#include<iostream>
using namespace std;//全缺省
void fun(int a = 1,int b = 2,int c = 3)
{cout << a << endl;cout << b << endl;cout << c << endl;cout <<'\n' << endl;}int main()
{//fun();//如果一个不传实参,就用缺省值来打印//fun(10);//传一个则a=10,b,c就用缺省值来打印//fun(10,20);//传两个实参,则a=10,b=20,c就用缺省值来打印//fun(10, 20, 30);//传三个实参,就用这三个值来打印fun(, , 30);return 0;
}2、半缺省
半缺省就是部分形参是缺省值。
注意:给缺省值只能从右往左传。
如:
//半缺省
void fun(int a,int b,int c = 3)
{cout << a << endl;cout << b << endl;cout << c << endl;cout <<'\n' << endl;}int main()
{//fun();//如果一个不传实参,就用缺省值来打印//fun(10);//传一个则a=10,b,c就用缺省值来打印fun(10,20);//传两个实参,则a=10,b=20,c就用缺省值来打印fun(10, 20, 30);//传三个实参,就用这三个值来打印return 0;
}注意:不能跳跃着给缺省值。
如:
#include<iostream>
using namespace std;//半缺省
void fun(int a=1,int b,int c = 3)
{cout << a << endl;cout << b << endl;cout << c << endl;cout <<'\n' << endl;}int main()
{//fun();//如果一个不传实参,就用缺省值来打印//fun(10);//传一个则a=10,b,c就用缺省值来打印fun(10,20);//传两个实参,则a=10,b=20,c就用缺省值来打印fun(10, 20, 30);//传三个实参,就用这三个值来打印return 0;
}注意:传实参的时候形参有几个没有给缺省值就至少要传几个实参。
如:
#include<iostream>
using namespace std;//半缺省
void fun(int a,int b,int c = 3)
{cout << a << endl;cout << b << endl;cout << c << endl;cout <<'\n' << endl;}int main()
{//fun();//如果一个不传实参,就用缺省值来打印//fun(10);//传一个则a=10,b,c就用缺省值来打印fun(10,20);//传两个实参,则a=10,b=20,c就用缺省值来打印fun(10, 20, 30);//传三个实参,就用这三个值来打印return 0;
}3、声明和定义不能同时给缺省值
正确代码:
//声明
#pragma onceint Add(int x = 10, int y = 20);//定义
int Add(int x, int y)
{return x + y;
}int main()
{int z = Add();cout << z << endl;//打印结果为30return 0;
}错误代码:
//声明
#pragma onceint Add(int x = 10, int y = 20);//定义
int Add(int x=1, int y=2)
{return x + y;
}int main()
{int z = Add();cout << z << endl;return 0;
}注意:不能在定义那里给缺省值,而定义那里给,因为我们包含的是头文件,别人使用是声明的那个。
注意:如果一个函数有缺省值,另外一个没有,则他们构成函数重载,但是他们在调用的使用有些问题。
如:
void fun()
{cout << "void fun "<<endl;
}
void fun(int a=1)
{cout << "void fun(int a=1)" << endl;
}int main()
{/*int z = Add();cout << z << endl;*/fun(10);//没有问题fun();//有问题,不知道调用哪个return 0;
}九、引用
引用就是给一个变量取别名,例如:我叫橘颂,别人叫我小橘子,那么小橘子就是我,小橘子的改变等于我的改变。引用的符号为:&,引用的底层是指针,引用不能代替指针(例如:链表)。
代码示例:
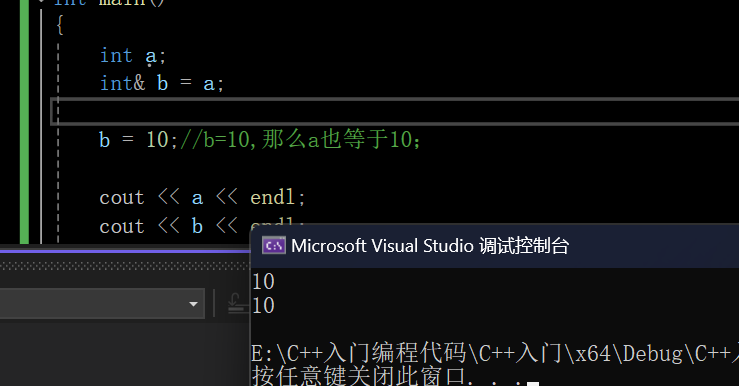
int main()
{int a;int& b = a;b = 10;//b=10,那么a也等于10;cout << a << endl;cout << b << endl;return 0;
}打印结果:
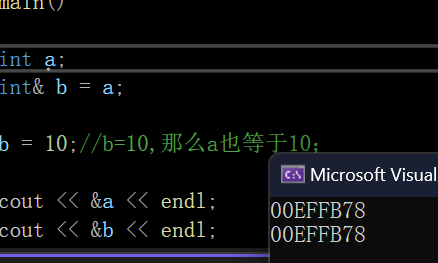
注意:他们的地址也是一样的,如:
int main()
{int a;int& b = a;b = 10;//b=10,那么a也等于10;cout << &a << endl;cout << &b << endl;return 0;
}打印结果:
1、引用的特性
1、1引用定义时必须初始化
int main()
{//错误代码int a = 1;int& b;//编译报错,必须确定引用的对象是什么b = a;//正确代码int a = 1;int& b = a;return 0;
}1、2一个变量可以有多个引用
int main()
{int a = 1;int& b = a;int& c = b;int& d = a;return 0;
}1、3引用一旦引用一个实体就不能再引用其他实体
int main()
{int a = 1;int b = 2;int& c = a;c = b;//这里不是引用而是赋值return 0;
}2、引用的使用
2.1引用传参
原来我们传地址过去,通过解引用来改变他们,选择同取别名来直接改变,增强了代码的可读性。
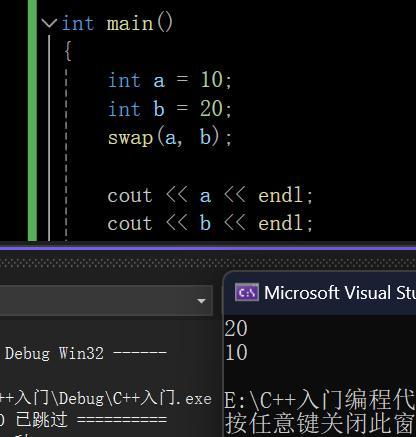
void swap(int& x, int& y)//相当于int& x=a,int& y=b
{int tmp = x;x = y;y = tmp;
}int main()
{int a = 10;int b = 20;swap(a, b);//不能swap(10,20),常量不能做变量的别名,如果真的要这样传可以swap(const int& x,const int& y)让x具有常属性cout << a << endl;cout << b << endl;return 0;
}打印结果:
typedef struct test
{int a;
}test;int Add(test& x)//x就是a
{x.a = 2;return x.a + 2;
}
int main()
{test a;Add(a);//不用传地址过去return 0;
}2、2引用在引用传参和引用做返回值中可以提高效率和减少拷贝并且改变引用对象的同时也改变被引用对象
我们以前在使用C语言传值调用的时候会进行临时对象的拷贝而引用不用这样提高了代码执行的效率,当然我们使用传址传参的时候会开空间,而引用不用这样也提高了代码的效率。
int tmp;
int& Add(int x, int y)
{tmp = x + y;//如果定义成int tmp=x+y,把第一行代码删除,当函数栈帧销毁的时候tmp就成了野引用return tmp;//返回值必须为左值(变量),不能是常量
}
int main()
{tmp += Add(2, 3);//tmp=5+5;cout << tmp << endl;return 0;
}注意:如果我们返回是常量,这时候会拷贝临时对象作为返回值,而临时对象具有常属性,不能让引用作为返回值。左值:能取地址的就是左值,左值能被修改。右值和左值相反。
示例:
int Add(int x, int y)
{return x+y;//传值返回的时候会生成它的拷贝即临时对象,临时对象具有常性,相当于被const修饰了
}
int main()
{Add(2, 3)+=2;//相当于5=5+2,这样是不对的,一般都是变量在左边:a+=2;a=a+2;return 0;
}课外知识:
int main()
{int arr[10];//越界读,编译器通常不报错cout << arr[10] << endl;cout << arr[11] << endl;cout << arr[12] << endl;return 0;
}int main()
{int arr[10];//越界读,编译器通常不报错//cout << arr[10] << endl;//cout << arr[11] << endl;//cout << arr[12] << endl;//越界写通常会报错,但是数组检查一般是抽查,如果多次越界写偶尔不会报错arr[10] = 10;return 0;
}十、const引用
补充知识:
int main()
{const int a = 2;//表示a指向内容不能被修改,例如:a++int const b = 2;//也表示b指向的内容不能改变,和上一句代码一样int const b=2和const int b=2,一样//在const修饰指针的时候不一样int c = 2;int d = 3;const int* f = &c;//const在*号的左边,表示指向的内容不能别修改如:*f=20;但是本身可以改变:d=*f;int* const f = &c;//本身不能被修改如:f=NULL;但是指向的内容可以改变如:*f=20return 0;
}1、权限的放大和缩小
int main()
{const int a = 1;int& b = a;//权限的放大,本来a是不能改变它指向的内容,你b是a的别名之后有权力改变,倒反天罡啊!!const int& b = a;//正确代码return 0;
}int main()
{//const int a = 1;//int& b = a;//权限的放大,本来a是不能改变它指向的内容,你b是a的别名之后有权力改变,倒反天罡啊!!//const int& b = a;//正确代码int b = 2;const int& a = b;//权限的缩小,但是a不能a++return 0;
}注意:权限可以缩小不能放大。
2、const使用的场景
1):
void swap(int& x, int& y)
{//
}
int main()
{const int a = 10;const int b = 30;swap(a, b);//权限的放大return 0;
}正确代码:
void swap(const int& x,const int& y)
{//
}
int main()
{const int a = 10;const int b = 30;swap(a, b);return 0;
}2):
void swap(int& x,int& y)
{//
}
int main()
{const int a = 10;const int b = 30;swap(10, 10);//编译错误return 0;
}正确代码:
void swap(const int& x,const int& y)
{//
}
int main()
{const int a = 10;const int b = 30;swap(10, 10);//int& x = 1;//变量不能做常量的别名const int& x = 1;//const修饰变量x让它具有常属性,而且不能改变它的内容即:x++return 0;
}3):
int main()
{double a = 3.14;int b = a;//进行隐式类型转换,过程是a创建一个临时对象给b,把a的整形(3)给它//int& c = a;//错误代码,因为临时对象具有常属性,引用的是它的临时对象,相当于权限放大。const int& c = a;//正确代码return 0;
}注意:临时对象一般存储在寄存器,而寄存器一般是4个字节或者8个字节,存储不下之后放到内存的某块区域。临时对象的产生的场景:函数传值返回,表达式运算(a+b),类型转换等。
4)权限的放大和缩小只涉及到引用和指针(大白话:除了引用和指针有权限的放大和缩小,其他都没有),不涉及到变量。
int main()
{const int a = 3;int b = a;//a的改变不影响b,b的改变也不影响a,这个代码实现的过程是把a的值拷贝给c,他们是两个不同的空间return 0;
}十一、指针和引用的关系
1)指针和引用互相不能替代,在语法层面上:引用是不开空间,指针要开空间(存储地址),但是底层就不一定咯,就像老婆饼没有老婆,引用的底层也是要开空间的,我们可以通过它汇编代码来看一下:
int main()
{int a = 2;int& b = a;int* c = &a;*c = 3;return 0;
}汇编代码:
int main()
{
001118C0 push ebp
001118C1 mov ebp,esp
001118C3 sub esp,0E8h
001118C9 push ebx
001118CA push esi
001118CB push edi
001118CC lea edi,[ebp-28h]
001118CF mov ecx,0Ah
001118D4 mov eax,0CCCCCCCCh
001118D9 rep stos dword ptr es:[edi]
001118DB mov eax,dword ptr [__security_cookie (011A040h)]
001118E0 xor eax,ebp
001118E2 mov dword ptr [ebp-4],eax
001118E5 mov ecx,offset _889F381A_C++_test@cpp (011C066h)
001118EA call @__CheckForDebuggerJustMyCode@4 (0111343h) int a = 2;
001118EF mov dword ptr [a],2 int& b = a;
001118F6 lea eax,[a] //和下面指针代码执行指令一模一样,都要开空间存储地址
001118F9 mov dword ptr [b],eax int* c = &a;
001118FC lea eax,[a]
001118FF mov dword ptr [c],eax *c = 3;
00111902 mov eax,dword ptr [c]
00111905 mov dword ptr [eax],3 return 0;
0011190B xor eax,eax
}总结:引用的底层是指针。
2)引用和指针一样,有野指针也有野引用。引用在定义的时候必须初始化,而指针可以不初始化(建议初始化防止成为野指针)
3)引用初始化引用一个对象之后就不能引用其他对象而指针可以。
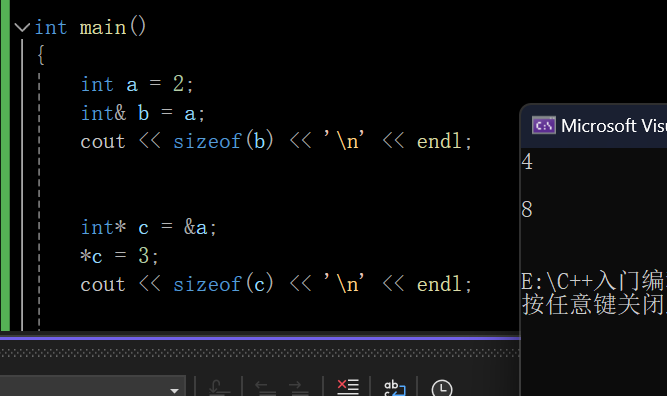
4)sizeof计算引用的大小是引用类型的大小,而指针始终是地址空间所占字节个数(32位平台下占4个字节,64位下是8字节)
示例:
//64位下
int main()
{int a = 2;int& b = a;cout << sizeof(b) << '\n' << endl;int* c = &a;*c = 3;cout << sizeof(c) << '\n' << endl;return 0;
}打印结果:
5)指针很容易出现空指针和野指针的问题,而引用很少出现,能用引用就不用指针。
十二、inline(内联)
补充知识:
//正确的宏函数的书写
#define ADD(a,b) ((a)+(b))
//1)为什么不能加分号?
//2)为什么要加外面的括号?
//3)为什么要加里面的括号?int main()
{//1)ADD(a,b)((a)+(b));//int a = 2;//int b = 3;//if(ADD(a,b))//if((((2)+(3));)错误//{// ////}//2)ADD(a,b) (a)+(b)//int a = 2;//int b = 3;//cout << ADD(2, 3) * 5 << endl;//本来计算结果是25,但是(2)+(3)*5,结果是17,错误//3)ADD(a,b) a+b//cout << ADD(2&1, 3&1) << endl;//当出现比加号的优先级低的就会出现问题:本来预想:(2&1)+(3&1)结果:2&(1+3)&1return 0;
}1)我们在C语言部分的时候经常定义宏函数,从上面的知识补充可知宏函数很复杂而且容易出错,还不能调试,这些都是宏函数的缺点。宏函数的优点:预处理的时候直接替换不用建立函数栈帧,效率提高。这里我们C++设计了inline目的就是为了解决宏函数的缺点来代替宏函数。
2)函数可以解决宏函数的缺点但是会建立函数栈帧,效率降低。我们可以把函数放到内联里面,这样编译C++时候调用的时候展开内联函数,不用建立函数栈帧,提高效率。
小知识:内联代替宏函数,const和enum代替宏常量。
3)inline对于编译器来说只是一个建议,既然是个建议编译器可以在调用的时候展开inline也不展开。不同编译器关于inline什么情况展开各不相同,因为C++标准没有规定。一般来说放到内联的函数代码较少的,会展开,反之会被编译器忽略。
注意:关于函数栈帧的创立、销毁和汇编代码指令的理解我们要补充一下相关知识:
代码示例:
inline int Add(int x, int y)
{
005A1910 push ebp
005A1911 mov ebp,esp
005A1913 sub esp,0CCh
005A1919 push ebx
005A191A push esi
005A191B push edi
005A191C lea edi,[ebp-0Ch]
005A191F mov ecx,3
005A1924 mov eax,0CCCCCCCCh
005A1929 rep stos dword ptr es:[edi]
005A192B mov ecx,offset _ACF1371A_test3@cpp (05AC15Ch)
005A1930 call @__CheckForDebuggerJustMyCode@4 (05A133Eh) int ret = x + y;
005A1935 mov eax,dword ptr [x]
005A1938 add eax,dword ptr [y]
005A193B mov dword ptr [ret],eax return ret;
005A193E mov eax,dword ptr [ret]
}
005A1941 pop edi
005A1942 pop esi
005A1943 pop ebx
005A1944 add esp,0CCh
005A194A cmp ebp,esp
005A194C call __RTC_CheckEsp (05A125Dh)
005A1951 mov esp,ebp
005A1953 pop ebp
005A1954 ret int main()
{
005A1970 push ebp
005A1971 mov ebp,esp
005A1973 sub esp,0CCh
005A1979 push ebx
005A197A push esi
005A197B push edi
005A197C lea edi,[ebp-0Ch]
005A197F mov ecx,3
005A1984 mov eax,0CCCCCCCCh
005A1989 rep stos dword ptr es:[edi]
005A198B mov ecx,offset _ACF1371A_test3@cpp (05AC15Ch)
005A1990 call @__CheckForDebuggerJustMyCode@4 (05A133Eh) int ret = Add(2, 3);
005A1995 push 3
005A1997 push 2
005A1999 call Add (05A11D6h)
005A199E add esp,8
005A19A1 mov dword ptr [ret],eax cout << ret << endl;
005A19A4 mov esi,esp
005A19A6 push offset std::endl<char,std::char_traits<char> > (05A103Ch)
005A19AB mov edi,esp
005A19AD mov eax,dword ptr [ret]
005A19B0 push eax
005A19B1 mov ecx,dword ptr [__imp_std::cout (05AB0A8h)]
005A19B7 call dword ptr [__imp_std::basic_ostream<char,std::char_traits<char> >::operator<< (05AB09Ch)]
005A19BD cmp edi,esp
005A19BF call __RTC_CheckEsp (05A125Dh)
005A19C4 mov ecx,eax
005A19C6 call dword ptr [__imp_std::basic_ostream<char,std::char_traits<char> >::operator<< (05AB0A0h)]
005A19CC cmp esi,esp
005A19CE call __RTC_CheckEsp (05A125Dh) return 0;
005A19D3 xor eax,eax
}图片解疑:
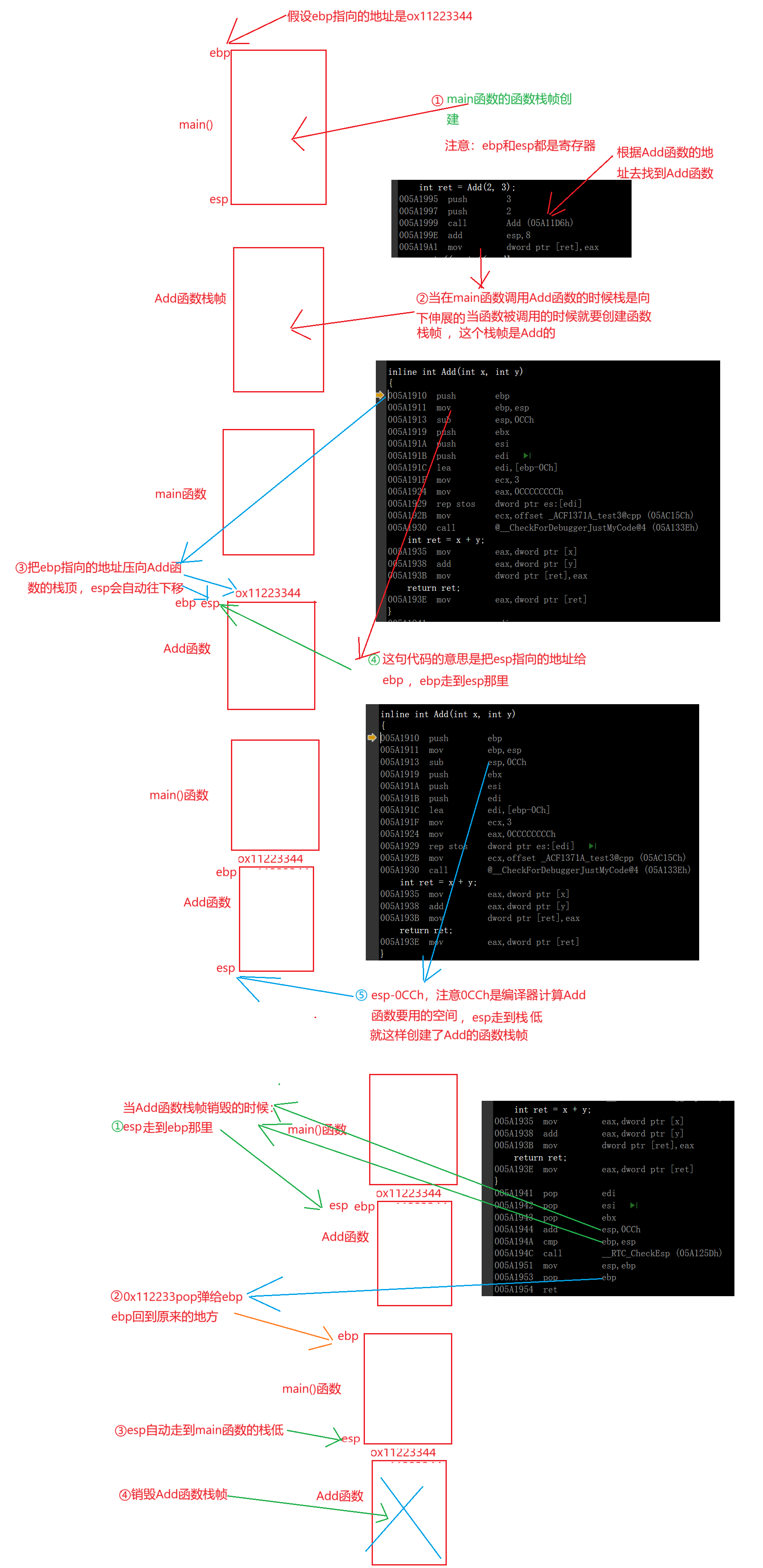
好了我们接着解读内联是否展开的问题,有了前面函数栈帧的创建和销毁的知识铺垫我们可以得出一个结论:
通过汇编代码观察内联是否展开,如果汇编代码出现call Add就是没有展开,反之就是展开了。
代码示例:
int ret = Add(2, 3);
005A1995 push 3
005A1997 push 2
005A1999 call Add (05A11D6h) //没有展开,根据Add函数的地址跳到Add函数执行代码
005A199E add esp,8
005A19A1 mov dword ptr [ret],eax 注意:VS的call Add后面跟的不是Add函数的地址,它做了一些优化。如:

现在Add后面跟的才是Add函数的地址。
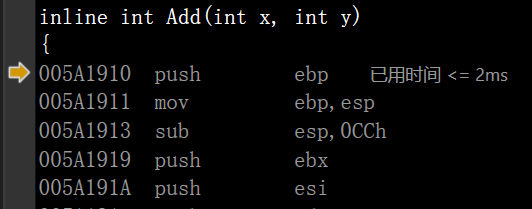
总结欸:通过上面的知识我们可得:inline在一定程度上会让编译后的可执行程序变大。可执行程序变大,用户体验降低。如果inline展开受程序员来控制(本质就是对程序员的不放心),那么可执行程序会变大,所以inline受编译器来控制是否展开。
示例:函数编译号之后一共10行指令,调用10000次,inline展开合计:10000*10行,不展开:10000+10行(原因:通过调用函数来栈帧来完成)
4)VS编译器debug版本下默认是不展开inline的,这样方便调试。debug版本如果想展开需要设置一下:
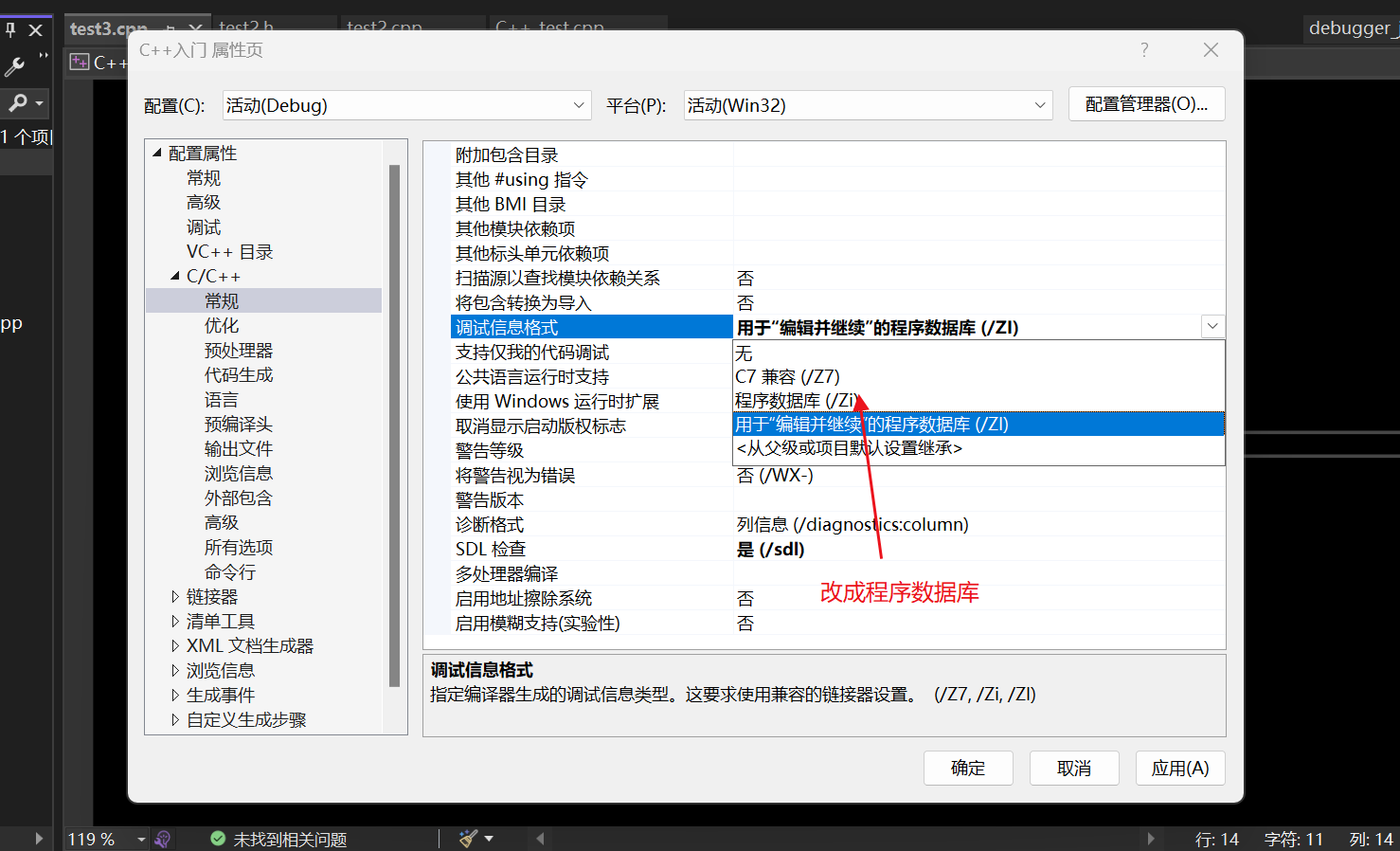
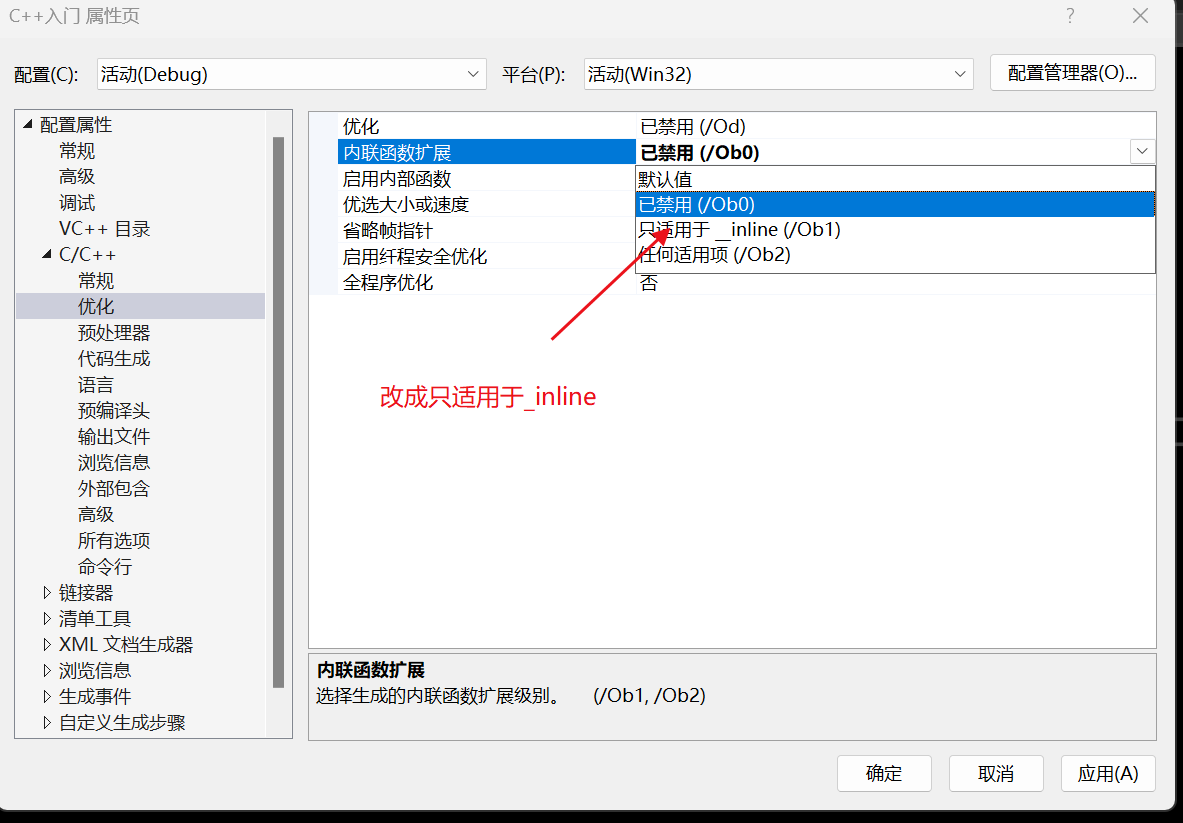 这时候就展开了,代码示例:
这时候就展开了,代码示例:
int ret = Add(2, 3);
00301560 mov eax,2
00301565 add eax,3
00301568 mov dword ptr [ebp-8],eax
0030156B mov ecx,dword ptr [ebp-8]
0030156E mov dword ptr [ret],ecx 5)inline不建议声明和定义分离,分离会导致链接错误,因为inline被展开,就没有函数地址,链接就会出现报错。
//test2.cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include"test2.h"
using namespace std;inline int Add(int x, int y)
{int ret = x + y;return ret;
}//test2.h
#pragma onceinline int Add(int x, int y);//test3.cpp
#define _CRT_SECURE_NO_WARNINGS 1
using namespace std;
#include<iostream>#include"test2.h"
int main()
{int ret = Add(2, 3);cout << ret << endl;return 0;
}结果:

解读:链接错误,找不到Add函数。一般来说我们只要定义和声明分离,然后在使用Add函数的时候我们在前面声明一下,给编译器说一声这个函数是有的,然后在链接过程中在其他文件的符号表找到Add函数的地址填充使用Add函数的时候给他一个地址,这样就算是完整的链接了(声明的时候是没有Add函数的地址的,定义才有)。那么inline使用定义和声明分离,在inline定义的那个文件上,链接过程中是不会放到符号表的,如果加static也是不会放到符号表的。
正确书写inline的定义:不要定义和声明分离,把它直接放到头文件就行。
代码示例:
//test2.h
#pragma onceinline int Add(int x, int y)
{int ret = x + y;return ret;
}
十三、nullptr
在C语言中我们知道NULL是个宏,被定义为((void*)0),空指针不是一个无效的地址,它是内存地址的最开始的第一个字节的编号(地址是指向一个一个的字节),系统认为它没有人用会自动的把它空出来进行初始化,如果访问就会报错。在C++中被定义为0。
NULL的缺陷:
void fun(int x)
{cout << "void fun(int x)" << endl;
}
void fun(int* ptr)
{cout << "void fun(int* ptr)" << endl;
}
int main()
{fun(0);//调用第一个函数fun(NULL);//在C++中NULL在预处理的时候被替换成0,所以调用第一个函数fun((int*)NULL);//如果想调用第二个函数就要对NUULL进行强转,太麻烦了。所以在C++创建了nullptrfun(nullptr);return 0;
}运行结果:
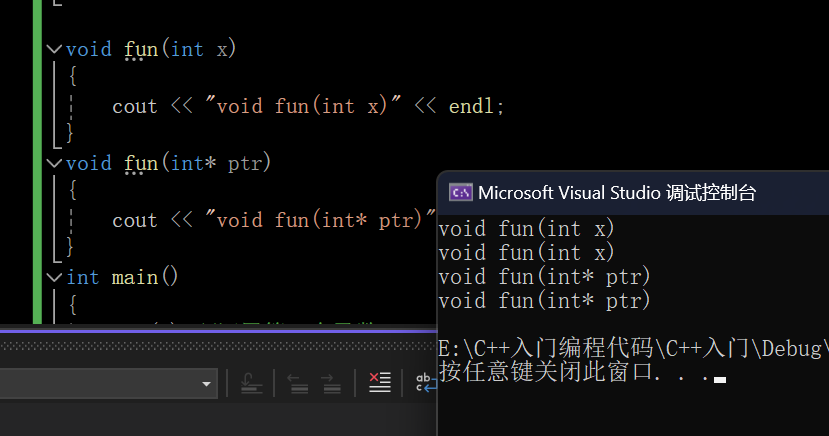
注意:nullptr是一个特殊的关键字,它可以自动转换成任何类型的指针类型,但是不会转换整型,为什么?如果能转换成整型要NULL干嘛!,就是说在C++中NULL表示0,而nullptr表示指针。
完!!