告别RAG上下文丢失:Late Chunking 与 Contextual Retrieval 深度对比解析
一 面临的挑战
在传统RAG流程中,必不可少的一个步骤是把长文档进行分块,然后把这些文本块进行向量化处理,并且存放在向量数据库中,当查询的时候,则从数据库中检索出相似的文本块传递给大模型,用于生成响应。
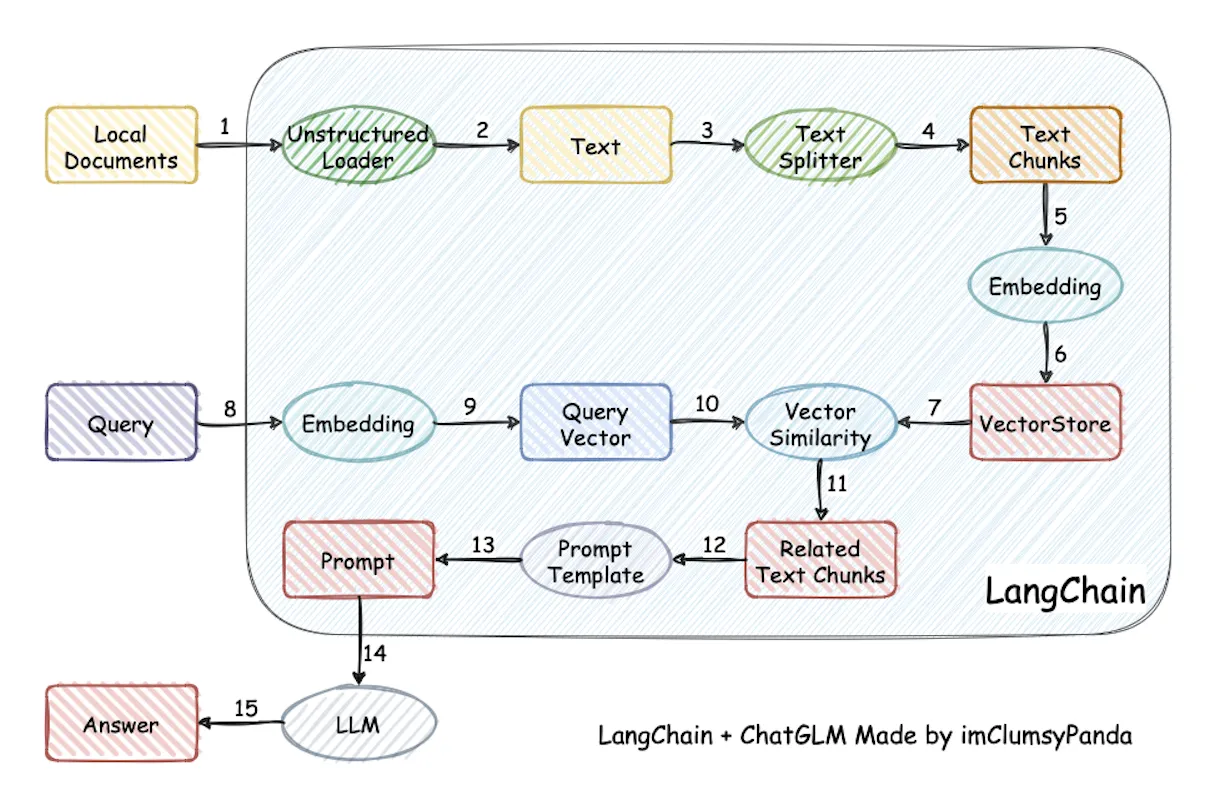
不考虑输入长度的限制,如果不进行分块,那么长文本在被处理成单个向量的时候可能会被过度压缩,导致最终检索效果不理想。但是,分块又会导致另外的问题:当相关信息分散在多个文本块中时,如果把文本简单分成多个文本块,可能会使它们丢失上下文信息,进而影响这些文本块的检索效果。
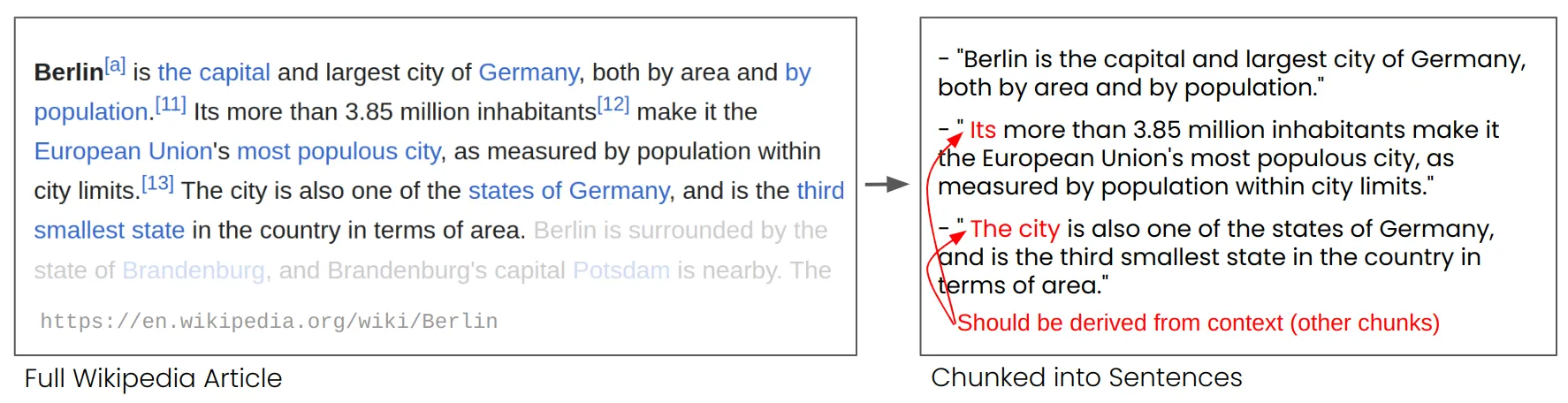
在下图中,一篇维基百科文章被按照句子分成不同的块,其中"its"和"the city"分别属于不同的块,但是这2个词都指代"Berlin",而"Berlin"只在第一个块中出现。嵌入模型只能利用已有的词产生整个句子的向量表示,因此难以将句子与"Berlin"联系起来,导致"Berlin"的向量表示与后2个句子块的向量表示的相似度会非常低。
二 Contextual Retrieval
针对这种情况,Anthropic提出一种思路:将每个块连同完整文档一起发送给LLM,由LLM为每个块添加相关上下文,从而产生更丰富、更有信息量的嵌入。
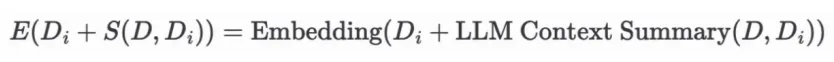
提示词模版,用于让LLM对每一个块生成上下文:
<document>
{{WHOLE_DOCUMENT}}
</document>
Here is the chunk we want to situate within the whole document
<chunk>
{{CHUNK_CONTENT}}
</chunk>
Please give a short succinct context to situate this chunk within the overall document for the purposes of improving search retrieval of the chunk. Answer only with the succinct context and nothing else.
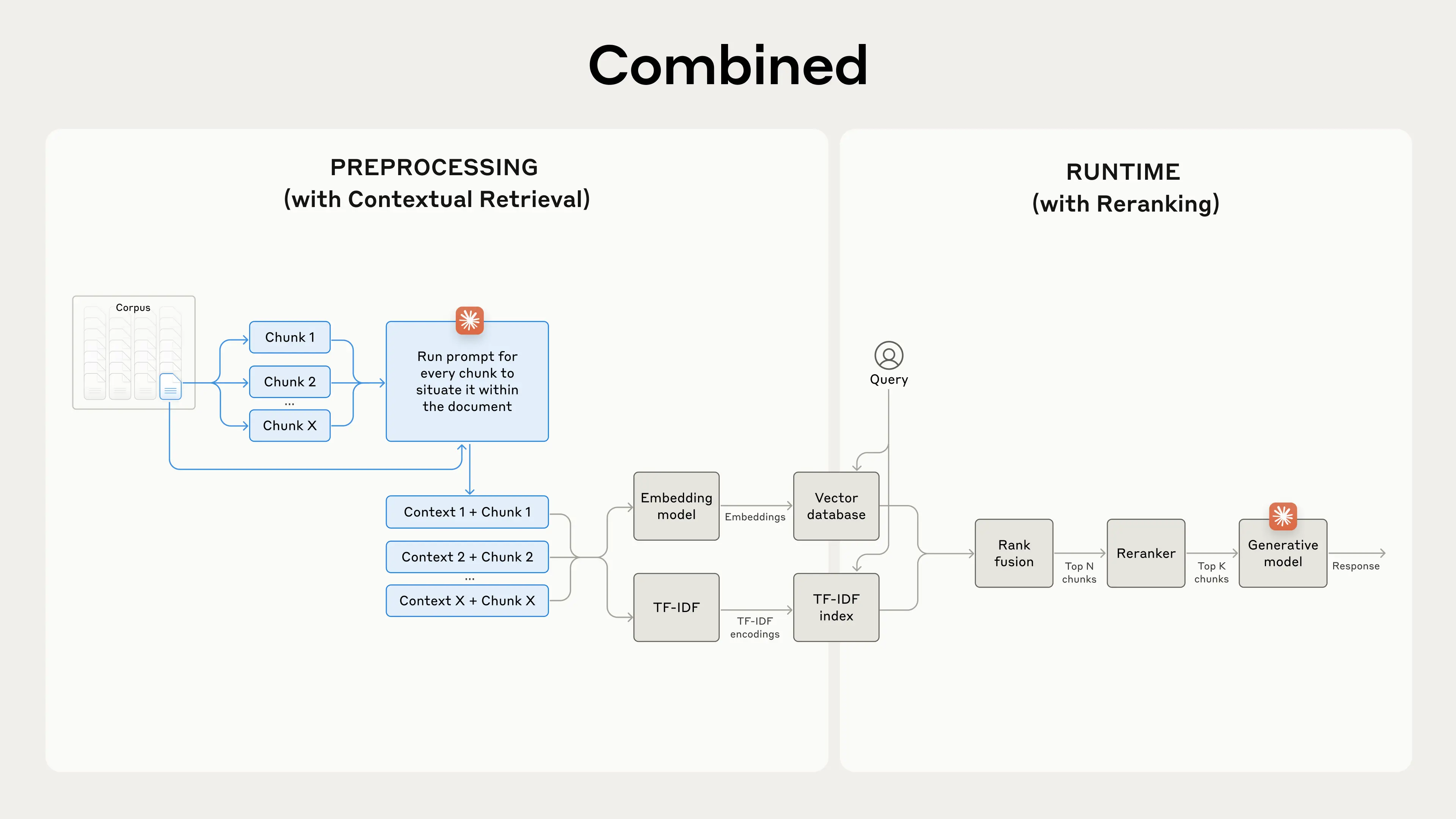
这本质上是一种引入上下文的做法,通过LLM将全局上下文显式地硬编码到每个块中,这在成本、时间和存储方面都是昂贵的。
三 Late Chunking
相比让LLM对一个块生成上下文这样简单粗暴的做法,Jina AI提出了一种更巧妙的方法:利用Transformer Encoder的固有机制实现的Late Chunking方法,这种方法不需要额外的存储,能充分利用更长的上下文信息,因此对于支持更长输入序列的模型来说更有优势,比如jina-embeddings-v3这种支持8192tokens的模型。
尽管利用了嵌入模型的完整上下文长度,但它的速度仍然比使用LLM生成上下文要快得多。
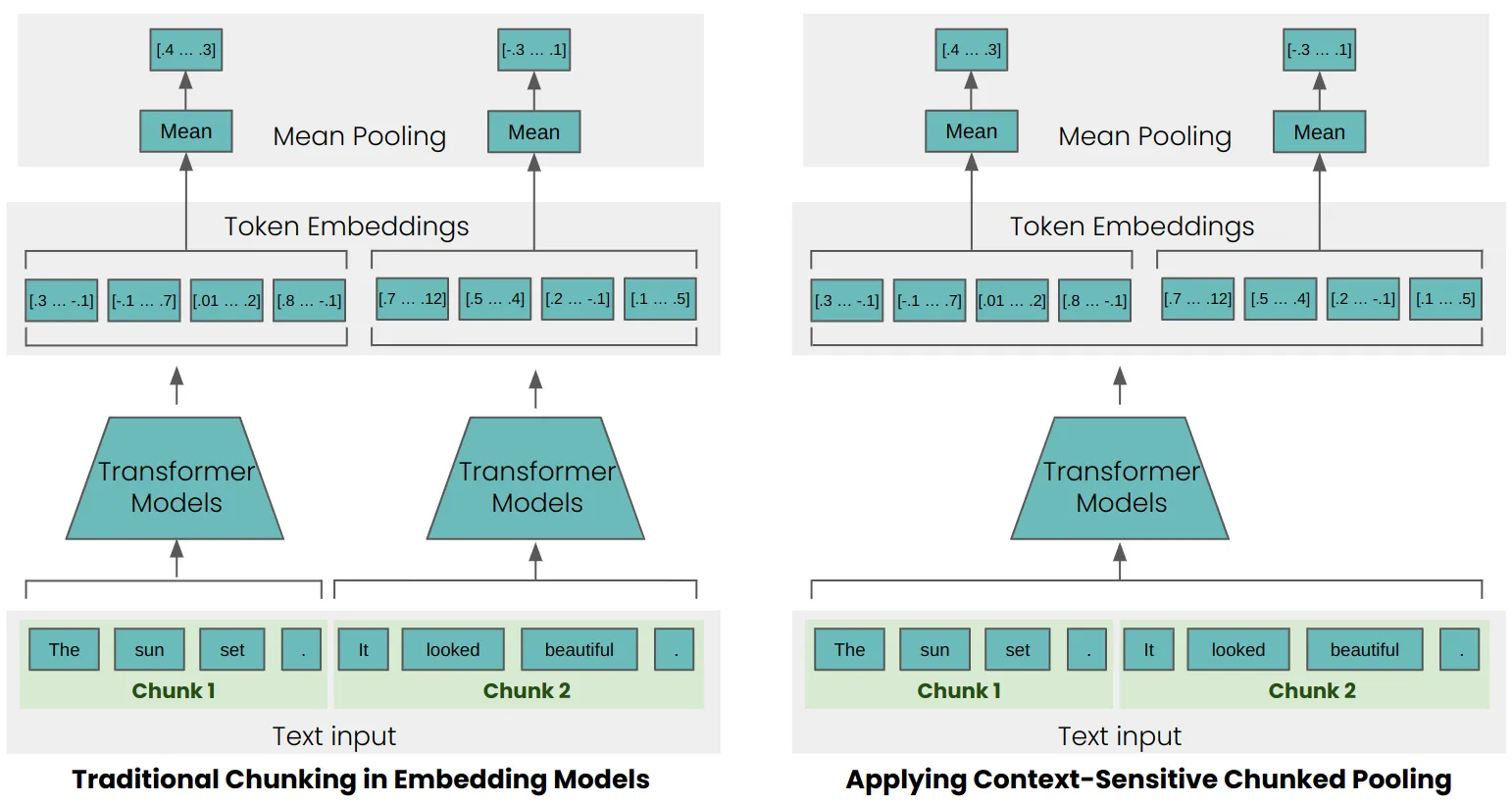
传统的chunking过程是先把特定的文档按照一定策略进行分块,然后再分别对每个块进行向量化表示;顾名思义,Late Chunking则尽量把长文档甚至完整的文档进行向量化表示(不超过模型最长序列限制),然后再对每一个块中所有token的向量之和求平均值。由于每个token的向量是在进行分块之前就已经得到的,因此每个token的向量化表示已经隐含了上下文信息。
不过该方法需要具备以下前提条件:
- 需要Embedding模型能够支持较长的序列长度,如果模型支持的输入序列长度太短(如仅支持最长512 tokens)则效果不明显。
- 需要从底层获取token级别的向量,大部分付费的向量化API接口可能无法直接使用,需要自行调用
Transformers进行本地化部署。
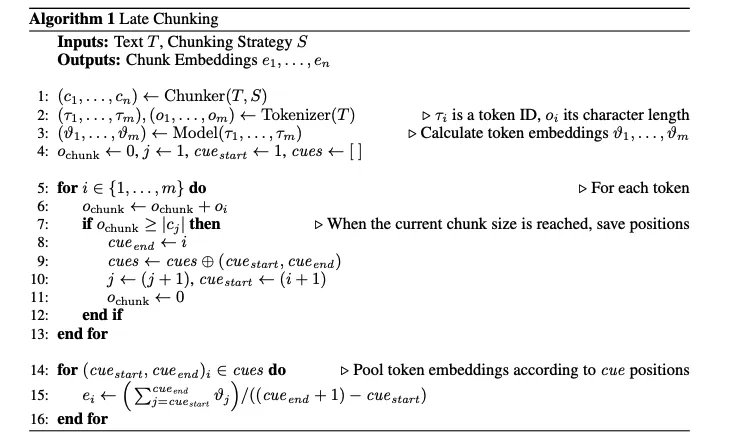
该算法的核心是通过动态分块的方式,将输入文本划分为多个块,并为每个块生成嵌入表示。具体步骤包括:
- 使用分词器对文本进行分词,获取token的ID和长度。
- 使用预训练模型生成token嵌入。
- 动态计算每个块的起止位置,确保块的字符长度不超过限制。
- 对每个块内的 token 嵌入取平均值,生成块嵌入。
四 Late Chunking实战代码
首先下载一个支持长序列的向量模型,如jina-embeddings-v2-base-zh,并通过transformers进行部署。
from transformers import AutoModel
from transformers import AutoTokenizer# load model and tokenizer
tokenizer = AutoTokenizer.from_pretrained('/jina-embeddings-v2-base-zh', trust_remote_code=True)
model = AutoModel.from_pretrained('/jina-embeddings-v2-base-zh', trust_remote_code=True)
接着可以自行定义分块逻辑,比如这里按照中文句子进行分块,因此需要利用。作为分隔符。常见的分块逻辑还有固定长度分块、按照自然段落进行分块等,也可以使用更加高级的分块方法,比如使用语义模型进行语义分块。
def chunk_by_sentences(input_text: str, tokenizer: callable):"""Split the input text into sentences using the tokenizer:param input_text: The text snippet to split into sentences:param tokenizer: The tokenizer to use:return: A tuple containing the list of text chunks and their corresponding token spans"""inputs = tokenizer(input_text, return_tensors='pt', return_offsets_mapping=True)punctuation_mark_id = tokenizer.convert_tokens_to_ids('。')sep_id = tokenizer.convert_tokens_to_ids('[SEP]')token_offsets = inputs['offset_mapping'][0]token_ids = inputs['input_ids'][0]chunk_positions = [(i, int(start + 1))for i, (token_id, (start, end)) in enumerate(zip(token_ids, token_offsets))if token_id == punctuation_mark_idand (token_offsets[i + 1][0] - token_offsets[i][1] >= 0or token_ids[i + 1] == sep_id)]chunks = [input_text[x[1] : y[1]]for x, y in zip([(1, 0)] + chunk_positions[:-1], chunk_positions)]span_annotations = [(x[0], y[0]) for (x, y) in zip([(1, 0)] + chunk_positions[:-1], chunk_positions)]return chunks, span_annotations
接下来调用上述定义好的函数进行分块:
input_text = "本研究以江汉平原旱改水为研究背景,采用土壤盆栽试验和室内淹水培养相结合的方法,以多年水旱轮作土壤为对照,研究了多年旱作田改水后稻田土壤中生长和发育元素的含量以及对土壤氧化还原电位和有效铁、锰、锌的含量变化,为旱改水水稻品种选育提供参考。结果表明,稻田改水后,水稻根系生长速率明显降低且根系变短。其地上部干重和叶绿素含量分别约为未稻水处理的 30%和 20%。旱田水处理后土壤中 Fe 含量显著低于,而 Cu 和 Zn 含量则分别高于稻水处理。稻田土壤改水土壤氧化还原电位比原旱田土壤的低,而 DTPA-Fe 含量比原旱田土壤的高 7%左右,而 DTPA-Cu 和 DTPA-Zn 含量则分别比原旱田土壤的 1.4-2.5 倍和 1.6-1.8 倍。随着淹水时间的增加,稻田土壤改水土壤氧化还原电位逐渐增加,而 Fe、Cu 和 Zn 含量则先升高后降低趋势;到淹水处理的第 28 d,稻田土壤改水土壤氧化还原电位、铁、铜和锌含量与水旱田之间均呈负相关趋势。Fe 不足及 Cu 过量可能是导致旱改水水稻幼苗生长缓慢、根系变短的主要原因。旱田条件下添加磷钾肥可以降低土壤的 Fe 含量,提高土壤 DTPA-Fe 含量及氧化还原电位,DTPA-Cu 和 DTPA-Zn 含量。压茬种植和初春灌水均能有效降低叶绿素含量,但对根系生长量显著且直截了当。添加秸秆并不能完全补偿磷钾肥对水稻幼苗生长的作用。"# determine chunks
chunks, span_annotations = chunk_by_sentences(input_text, tokenizer)
print('Chunks:\n- "' + '"\n- "'.join(chunks) + '"')
分块结果:
Chunks:
- "本研究以江汉平原旱改水为研究背景,采用土壤盆栽试验和室内淹水培养相结合的方法,以多年水旱轮作土壤为对照,研究了多年旱作田改水后稻田土壤中生长和发育元素的含量以及对土壤氧化还原电位和有效铁、锰、锌的含量变化,为旱改水水稻品种选育提供参考。"
- "结果表明,稻田改水后,水稻根系生长速率明显降低且根系变短。"
- "其地上部干重和叶绿素含量分别约为未稻水处理的 30%和 20%。旱田水处理后土壤中 Fe 含量显著低于,而 Cu 和 Zn 含量则分别高于稻水处理。"
- "稻田土壤改水土壤氧化还原电位比原旱田土壤的低,而 DTPA-Fe 含量比原旱田土壤的高 7%左右,而 DTPA-Cu 和 DTPA-Zn 含量则分别比原旱田土壤的 1.4-2.5 倍和 1.6-1.8 倍。"
- "随着淹水时间的增加,稻田土壤改水土壤氧化还原电位逐渐增加,而 Fe、Cu 和 Zn 含量则先升高后降低趋势;到淹水处理的第 28 d,稻田土壤改水土壤氧化还原电位、铁、铜和锌含量与水旱田之间均呈负相关趋势。"
- "Fe 不足及 Cu 过量可能是导致旱改水水稻幼苗生长缓慢、根系变短的主要原因。"
- "旱田条件下添加磷钾肥可以降低土壤的 Fe 含量,提高土壤 DTPA-Fe 含量及氧化还原电位,DTPA-Cu 和 DTPA-Zn 含量。"
- "压茬种植和初春灌水均能有效降低叶绿素含量,但对根系生长量显著且直截了当。"
接着根据前面提供的算法伪代码,可以定义出Late Chunking的函数:
def late_chunking(model_output: 'BatchEncoding', span_annotation: list, max_length=None
):token_embeddings = model_output[0]outputs = []for embeddings, annotations in zip(token_embeddings, span_annotation):if (max_length is not None): # remove annotations which go bejond the max-length of the modelannotations = [(start, min(end, max_length - 1))for (start, end) in annotationsif start < (max_length - 1)]pooled_embeddings = [embeddings[start:end].sum(dim=0) / (end - start)for start, end in annotationsif (end - start) >= 1]pooled_embeddings = [embedding.detach().cpu().numpy() for embedding in pooled_embeddings]outputs.append(pooled_embeddings)return outputs
为了测试该算法的效果,可以使用传统的向量化方法作为对照。
# chunk before
embeddings_traditional_chunking = model.encode(chunks)# chunk afterwards (context-sensitive chunked pooling)
inputs = tokenizer(input_text, return_tensors='pt')
model_output = model(**inputs)
embeddings = late_chunking(model_output, [span_annotations])[0]
import numpy as npcos_sim = lambda x, y: np.dot(x, y) / (np.linalg.norm(x) * np.linalg.norm(y))berlin_embedding = model.encode('旱改水')for chunk, new_embedding, trad_embeddings in zip(chunks, embeddings, embeddings_traditional_chunking):print(f'similarity_new("旱改水", "{chunk}"):', cos_sim(berlin_embedding, new_embedding))print(f'similarity_trad("旱改水", "{chunk}"):', cos_sim(berlin_embedding, trad_embeddings))
结果表明,每一个分块后的句子,在使用了Late Chunking后,与query的相似度均得到提升。而且,除了第一个句子之外,其他句子相似度均大幅度提升了。这是因为第一个句子中含有query词汇旱改水,因此传统方法和Late Chunking区别不大,而其他的句子并没有包含该关键词,所以相似度会大幅Late Chunking。这刚好验证了Late Chunking在克服上下文丢失问题中的作用。
similarity_new("旱改水", "本研究以江汉平原旱改水为研究背景,采用土壤盆栽试验和室内淹水培养相结合的方法,以多年水旱轮作土壤为对照,研究了多年旱作田改水后稻田土壤中生长和发育元素的含量以及对土壤氧化还原电位和有效铁、锰、锌的含量变化,为旱改水水稻品种选育提供参考。"): 0.6720659
similarity_trad("旱改水", "本研究以江汉平原旱改水为研究背景,采用土壤盆栽试验和室内淹水培养相结合的方法,以多年水旱轮作土壤为对照,研究了多年旱作田改水后稻田土壤中生长和发育元素的含量以及对土壤氧化还原电位和有效铁、锰、锌的含量变化,为旱改水水稻品种选育提供参考。"): 0.64791536
similarity_new("旱改水", "结果表明,稻田改水后,水稻根系生长速率明显降低且根系变短。"): 0.66255337
similarity_trad("旱改水", "结果表明,稻田改水后,水稻根系生长速率明显降低且根系变短。"): 0.41631764
similarity_new("旱改水", "其地上部干重和叶绿素含量分别约为未稻水处理的 30%和 20%。旱田水处理后土壤中 Fe 含量显著低于,而 Cu 和 Zn 含量则分别高于稻水处理。"): 0.60238755
similarity_trad("旱改水", "其地上部干重和叶绿素含量分别约为未稻水处理的 30%和 20%。旱田水处理后土壤中 Fe 含量显著低于,而 Cu 和 Zn 含量则分别高于稻水处理。"): 0.41089594
similarity_new("旱改水", "稻田土壤改水土壤氧化还原电位比原旱田土壤的低,而 DTPA-Fe 含量比原旱田土壤的高 7%左右,而 DTPA-Cu 和 DTPA-Zn 含量则分别比原旱田土壤的 1.4-2.5 倍和 1.6-1.8 倍。"): 0.59922785
similarity_trad("旱改水", "稻田土壤改水土壤氧化还原电位比原旱田土壤的低,而 DTPA-Fe 含量比原旱田土壤的高 7%左右,而 DTPA-Cu 和 DTPA-Zn 含量则分别比原旱田土壤的 1.4-2.5 倍和 1.6-1.8 倍。"): 0.53304046
similarity_new("旱改水", "随着淹水时间的增加,稻田土壤改水土壤氧化还原电位逐渐增加,而 Fe、Cu 和 Zn 含量则先升高后降低趋势;到淹水处理的第 28 d,稻田土壤改水土壤氧化还原电位、铁、铜和锌含量与水旱田之间均呈负相关趋势。"): 0.60846937
similarity_trad("旱改水", "随着淹水时间的增加,稻田土壤改水土壤氧化还原电位逐渐增加,而 Fe、Cu 和 Zn 含量则先升高后降低趋势;到淹水处理的第 28 d,稻田土壤改水土壤氧化还原电位、铁、铜和锌含量与水旱田之间均呈负相关趋势。"): 0.45983577
similarity_new("旱改水", "Fe 不足及 Cu 过量可能是导致旱改水水稻幼苗生长缓慢、根系变短的主要原因。"): 0.58728385
similarity_trad("旱改水", "Fe 不足及 Cu 过量可能是导致旱改水水稻幼苗生长缓慢、根系变短的主要原因。"): 0.45934817
similarity_new("旱改水", "旱田条件下添加磷钾肥可以降低土壤的 Fe 含量,提高土壤 DTPA-Fe 含量及氧化还原电位,DTPA-Cu 和 DTPA-Zn 含量。"): 0.5464428
similarity_trad("旱改水", "旱田条件下添加磷钾肥可以降低土壤的 Fe 含量,提高土壤 DTPA-Fe 含量及氧化还原电位,DTPA-Cu 和 DTPA-Zn 含量。"): 0.3906071
similarity_new("旱改水", "压茬种植和初春灌水均能有效降低叶绿素含量,但对根系生长量显著且直截了当。"): 0.46369302
similarity_trad("旱改水", "压茬种植和初春灌水均能有效降低叶绿素含量,但对根系生长量显著且直截了当。"): 0.25598907
五 总结
Late Chunking和Contextual Retrieval都为传统分块方法中固有的上下文丢失问题提供了各自的解决方案:
● Late Chunking 采用“先嵌入后分块”的方式 ,在多个分块之间保留语义信息,利用的是模型结构的特点,不会造成额外的消耗;
● Contextual Retrieval 则基于LLM为每个分块添加文档范围的上下文信息进行增强 ,会造成大量的token损耗,同时效果高度依赖于所使用的LLM。
在实际使用时,可以根据情况灵活选择这两种方式:
● 如果对于嵌入速度以及成本有要求,同时有能力自行部署向量化模型,那么 Late Chunking往往是最佳选择 ;
● 如果对检索准确性要求极高,并且对LLM的性能非常自信,那么Contextual Retrieval的层次化上下文方法在正确实现的情况下可以取得非常优秀的效果。
总之,这两种方法都强调了上下文在检索中的重要性,说明有效的文本分块不仅仅是简单地切割文本,更重要的是保留其语义和含义 。