Dify+MCP+MySQL:智能问数本地实践
此记,一为流程备忘和指引,二为分享共建。
参考多篇帖子,最主要一篇是:
《Dify+MCP 组合拳:彻底根治 Excel 上传知识库回答数据不准的难题!》。在此感谢。
https://blog.csdn.net/python1234567_/article/details/147592305
实际实践下来,与该帖子还是有比较大差异的,虽然dify+mcp的整体流程几乎一样,不过在python环境配置上采用了不同方式。原帖子用uv,我不太懂,换成了conda。
部署架构概述
Dify作为AI应用开发平台,MCP作为中间层,MySQL作为数据存储,三者结合构建完整解决方案。
Dify是一个开源的大型语言模型(LLM)应用开发平台,提供了直观的界面,可帮助开发者快速构建AI聊天助手、工作流、RAG、Agent等生产级的生成式AI应用。
MCP(模型上下文协议)通过为AI模型提供标准化接口,增强其与外部数据源和工具的交互能力,从而支持更智能、上下文感知的自动化。
我的环境准备
- 操作系统:macOS(15.4)+ Docker环境
- 软件依赖:Python 3.12、Docker、MySQL 8.0+
- 硬件配置:M4芯片(10+10核)、24G内存、1T存储
一、MySQL部署与配置
-
安装MySQL
自行官网下载安装,我装的是mysql 8.4。 -
创建专用数据库与用户
安装mysql之后,可以下载安装dbeaver数据管理客户端来对mysql进行新建数据库、数据存储、迁移和查看等。
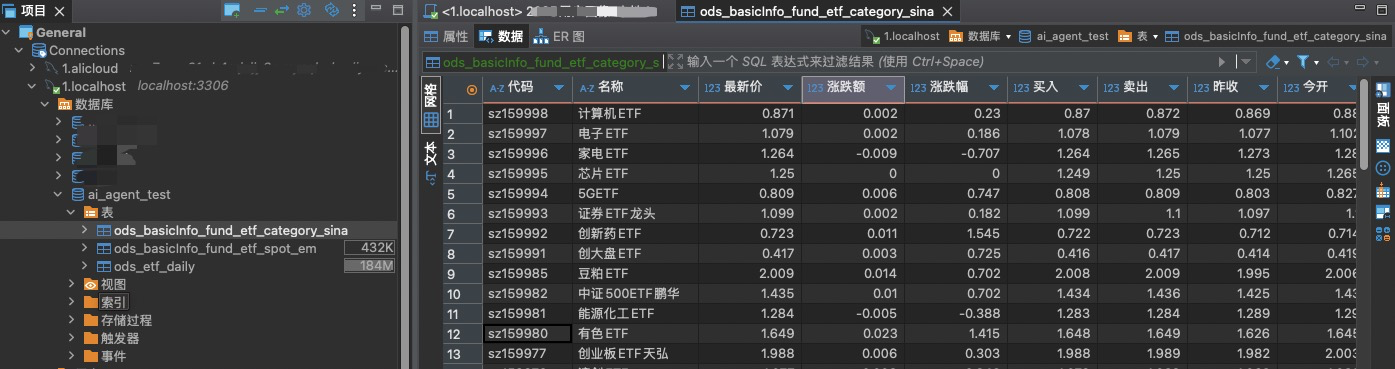
我本来有在用的数据库和部分金融-股票数据,所以直接新建一个库ai_agent_test作为智能问数本地实践测试使用,数据则从现有金融数据库复制一份现有的股票数据,供后续“智能问数”。
二、Dify平台部署
Dify是一个开源的大型语言模型(LLM)应用开发平台,提供了直观的界面,可帮助开发者快速构建AI聊天助手、工作流、RAG、Agent等生产级的生成式AI应用。
可以参考这篇帖子:
大模型(deepseek)之运用Dify构建智能体和工作流应用
https://blog.csdn.net/qq_31400983/article/details/143751581
在安装好docker之后,可以开始dify部署。我采用的是docker部署方式。
dify官网:https://dify.ai/
GitHub源码和镜像:https://github.com/langgenius/dify
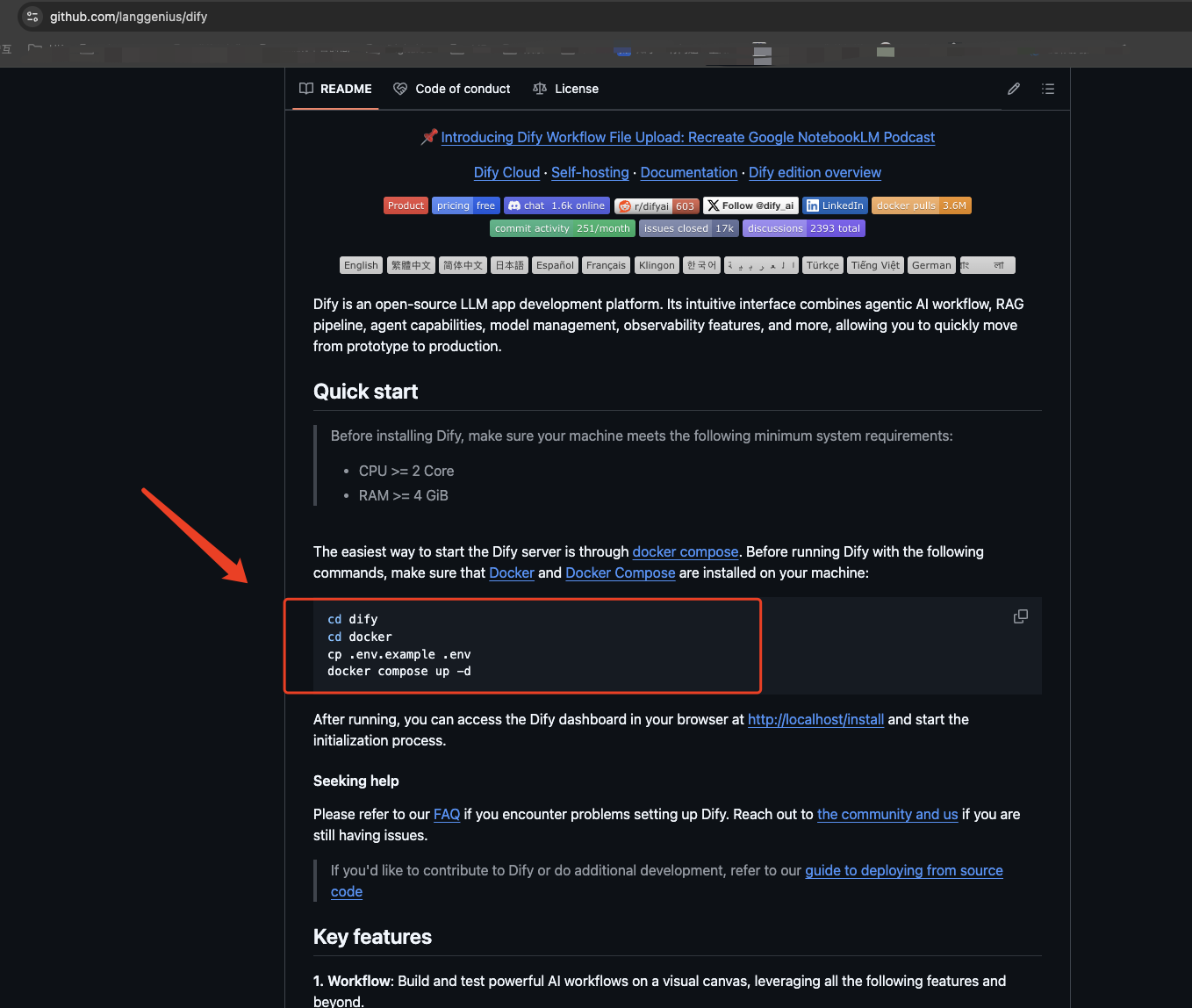
- 克隆代码库
下载Dify代码。可以直接访问Dify官网直接选择进入Github页面下载代码,也可以在cmd窗口运行以下代码克隆代码(事先为Dify克隆文件创建一个文件夹,如docker_files):
cd docker_files # 如果没有这一步,则默认下载在根目录下。
git clone https://github.com/langgenius/dify.git
- 创建dify Docker
cd dify/docker
cp .env.example .env
docker compose up -d
– 这里“dify/docker”要根据实际情况替换实际路径。
此步骤可以参考官网。
- 前端构建与启动
在浏览器输入:http://127.0.0.1/install或者http://localhost/install
回车即可打开dify前端页面。登录后页面如下:
三、MCP中间层集成
(一)下载mysql-mcp-server源码
下载mysql-mcp-server源码,这是一个github项目的源码,原github地址是:https://github.com/mangooer/mysql-mcp-server-sse
(二)准备python环境
因为采取的是源码方式 / Source Code Method,所以需要准备python环境。(如果采用docker方式,则不用)
创建虚拟环境及安装依赖包
创建python虚拟环境命名为ai_agent并激活,以及安装必要的依赖包:
– – “ai_agent”可以自定义为你喜欢的名字
# 创建指定Python版本的虚拟环境
conda create --name ai_agent python=3.12
# 激活虚拟环境
conda activate ai_agent
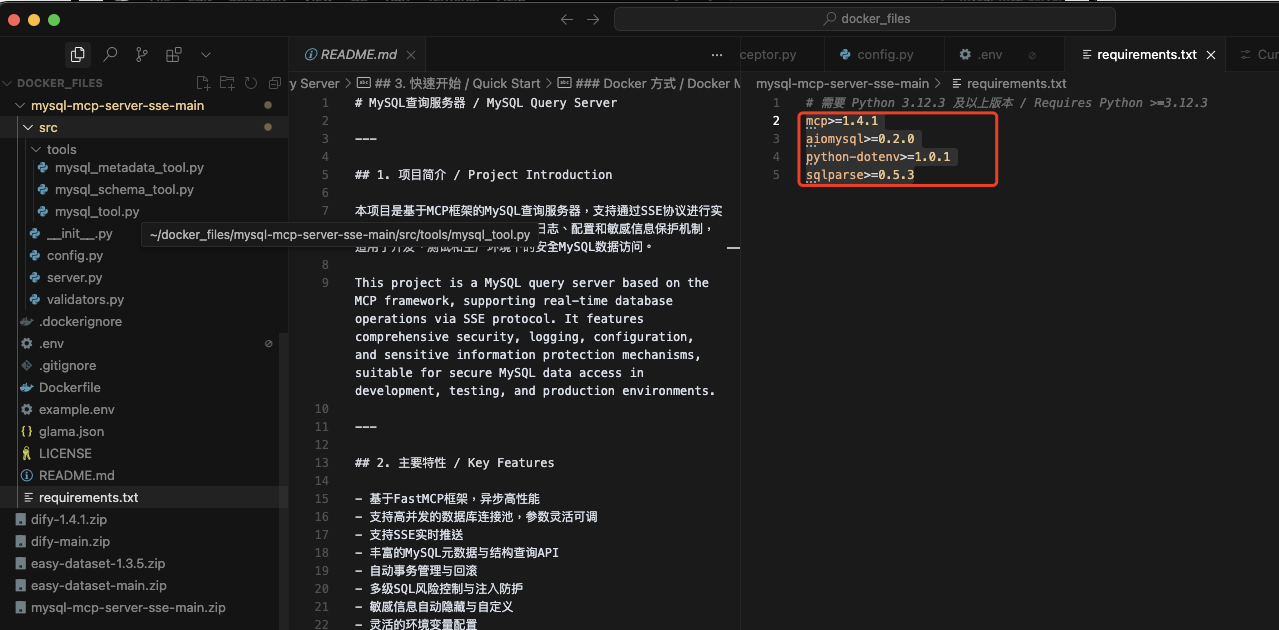
# 从 requirements.txt 批量安装
pip install -r requirements.txt
# 如果requirements.txt批量安装失败,可以尝试单包安装(示例)
pip install mcp
pip install aiomysql
pip install python-dotenv
pip install sqlparse
PS:
我本机用的是anaconda,所以习惯用conda命令。
然后,我的requirements.txt批量安装失败了,所以是单包安装解决的,就几个包,不多。
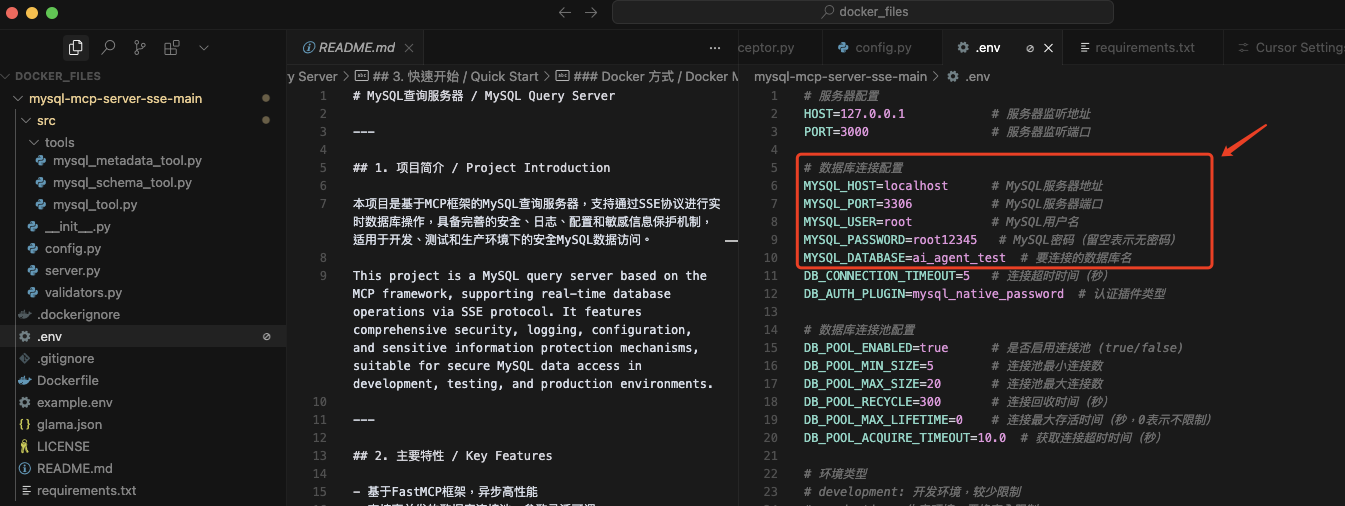
(三)数据库配置
复制.env.example为.env,并根据实际情况修改。 如下图:
# 数据库连接配置
MYSQL_HOST=localhost # MySQL服务器地址
MYSQL_PORT=3306 # MySQL服务器端口
MYSQL_USER=root # MySQL用户名
MYSQL_PASSWORD=root12345 # MySQL密码(留空表示无密码)
MYSQL_DATABASE=ai_agent_test # 要连接的数据库名
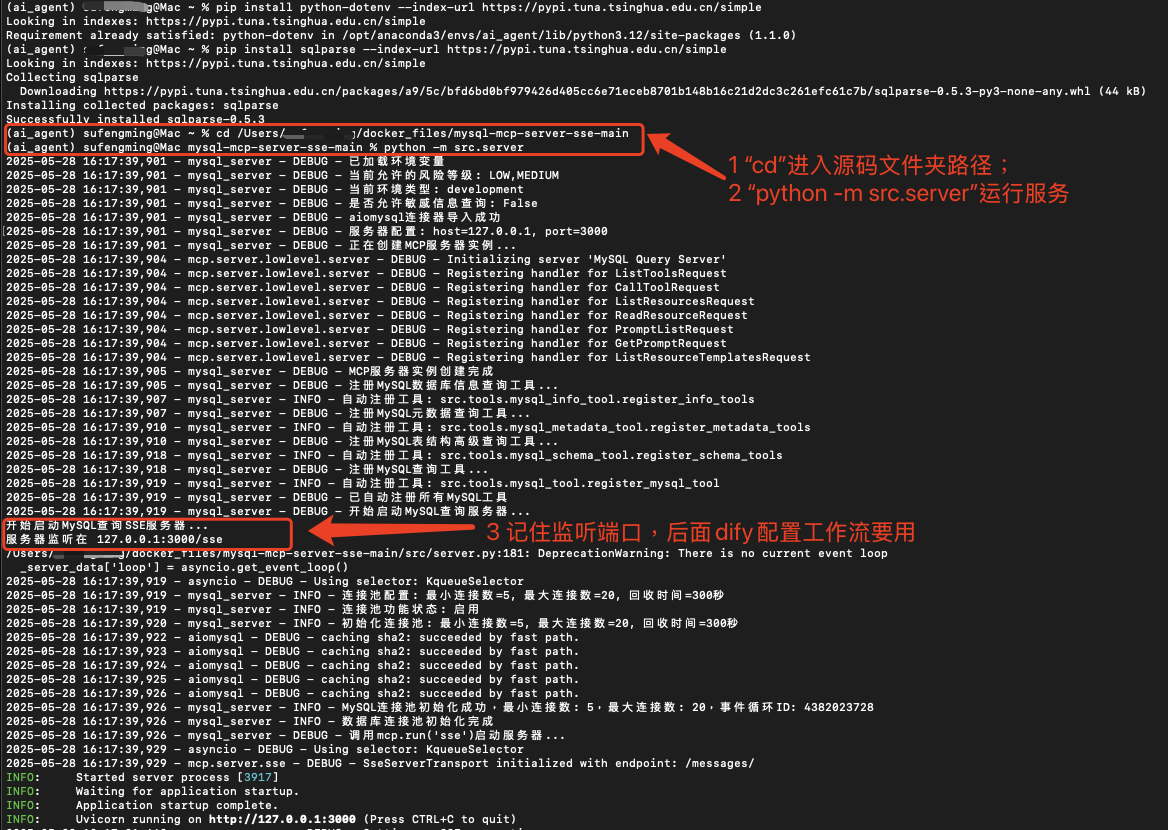
(四)启动服务 / Start the Server
cd /Users/xxx/docker_files/mysql-mcp-server-sse-main # 改成自己实际路径
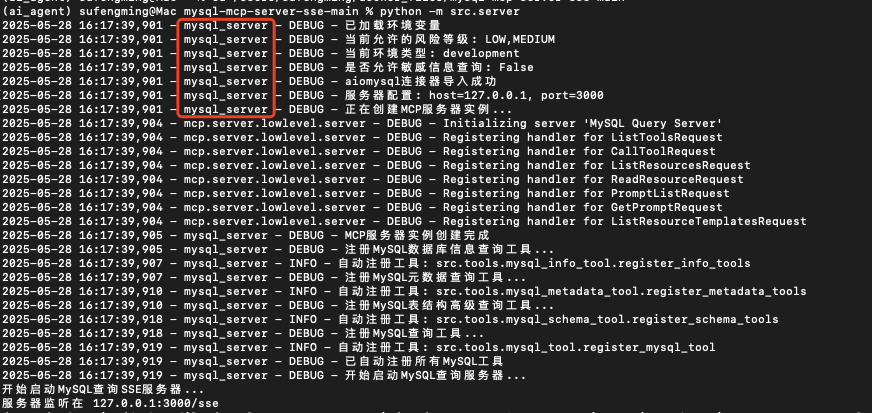
python -m src.server # 默认监听:http://127.0.0.1:3000/sse
可以看到,MCP服务运行在了 3000 端口,请记住该端口号,后面配置Dify工作流会用到。
从这里开始,由于实现路径接近一致,所以要大篇幅复制一下前面提到的参考帖子内容了。如有侵权,请联系我删除。
《Dify+MCP 组合拳:彻底根治 Excel 上传知识库回答数据不准的难题!》
https://blog.csdn.net/python1234567_/article/details/147592305
四、Dify工作流调用MCP服务
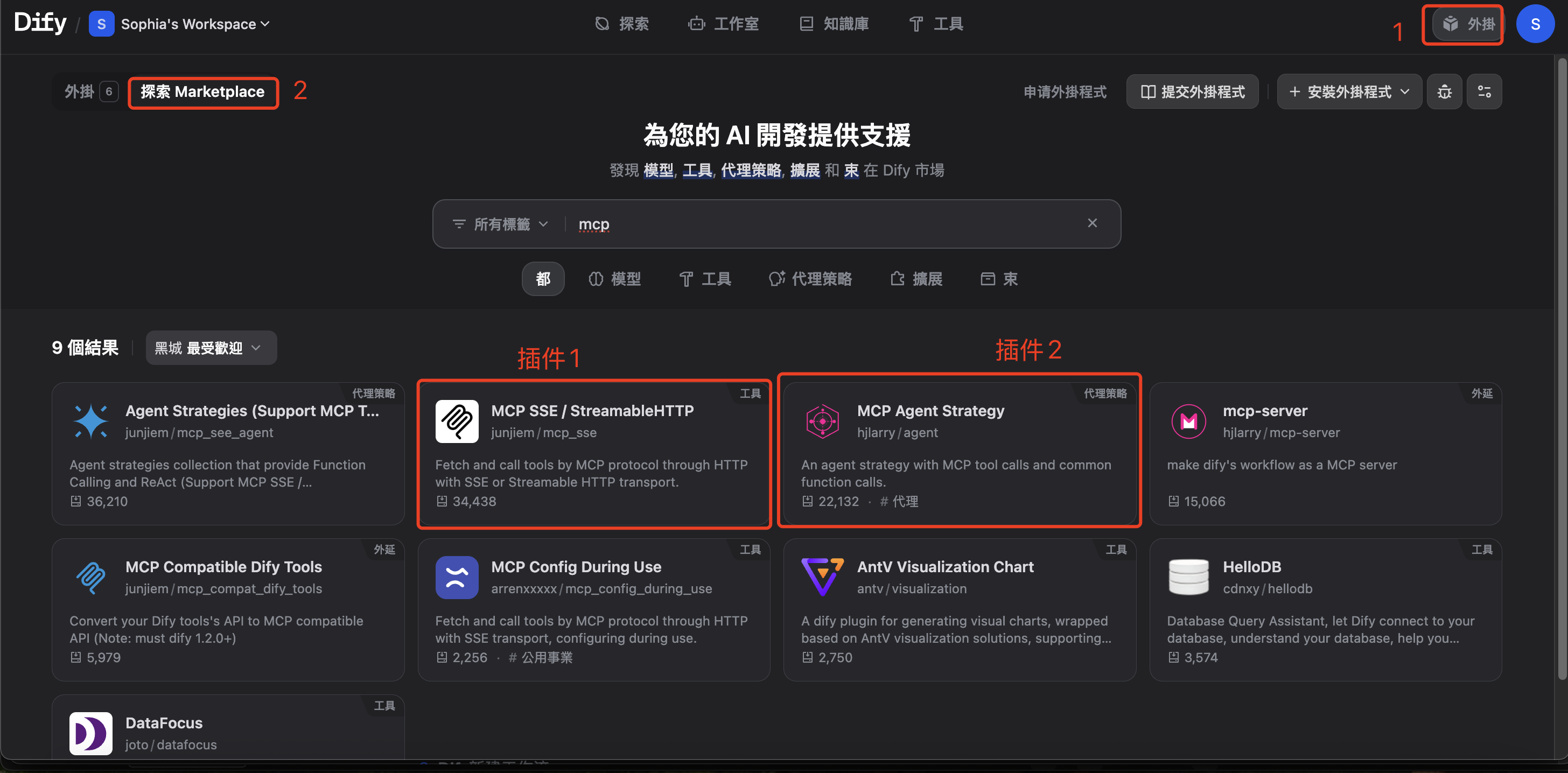
(一)安装插件
安装 MCP Agent策略 MCP SSE 插件,以供后面使用。
(才发现我电脑设置了中文繁体,所以简体“插件”显示成繁体“外褂”。如果看不习惯,可以点击上方链接,参考原帖相应部分。)
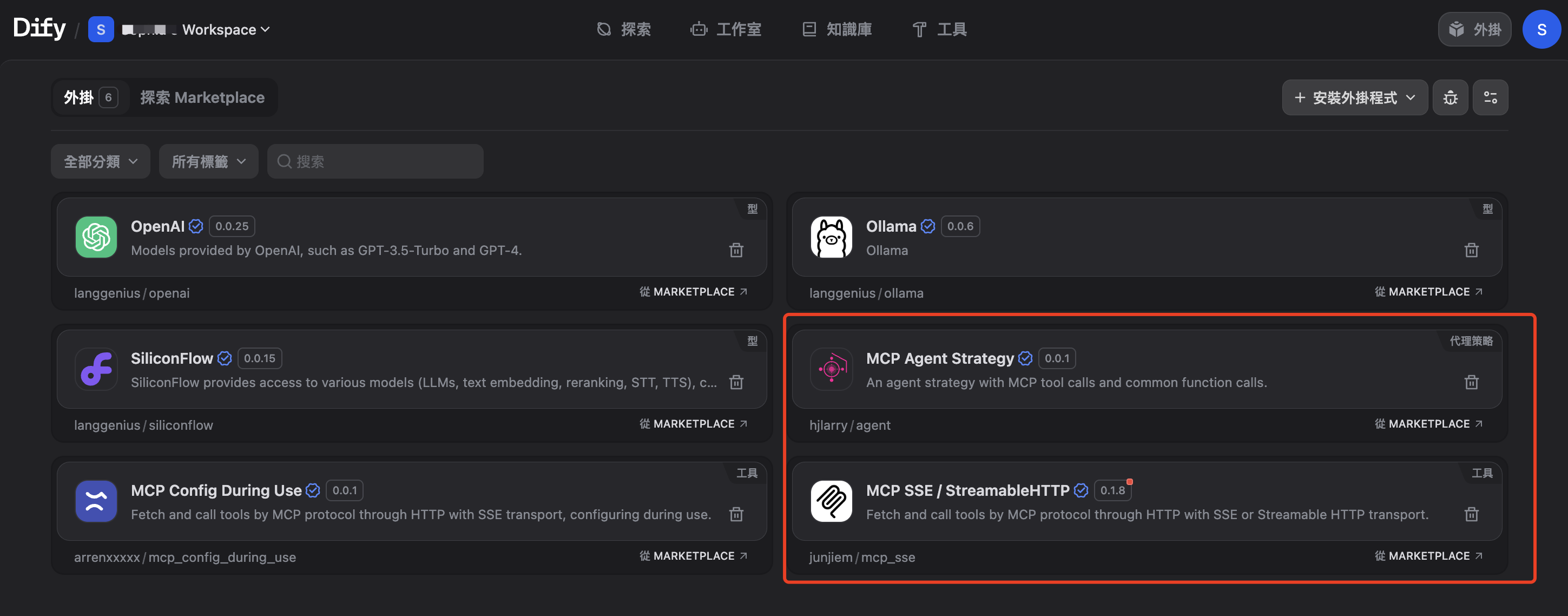
安装好后,是这样的:
(二)创建对话工作流应用
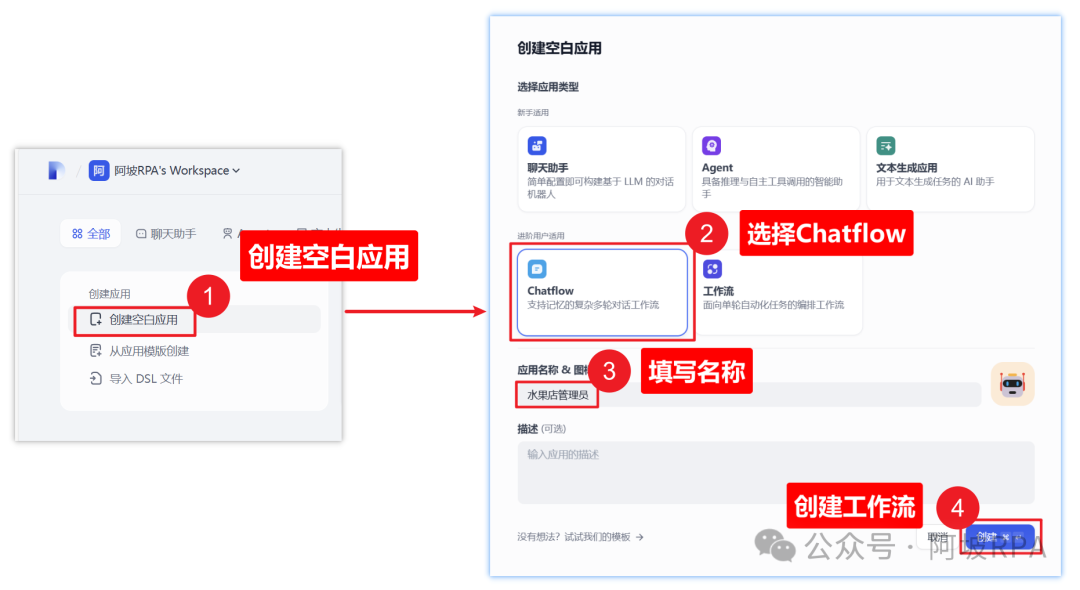
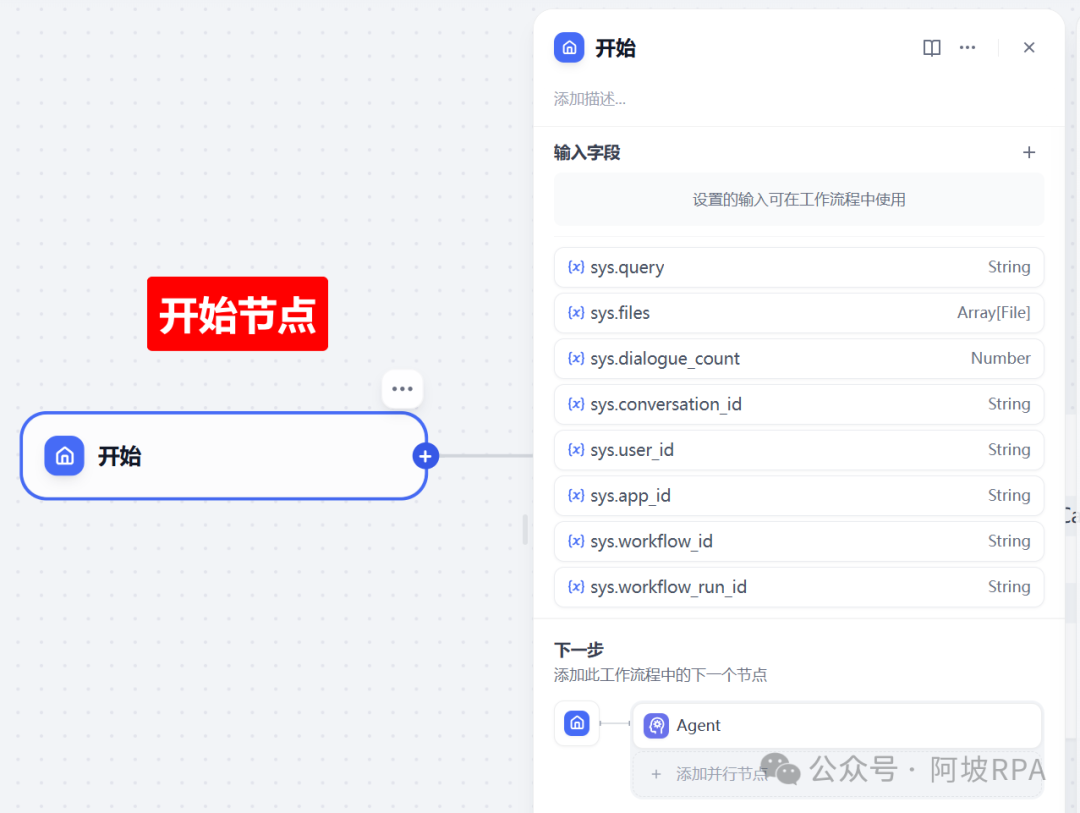
(三)开始节点
开始节点什么都不用填写,默认使用输入框的内容 sys.query 作为输入参数
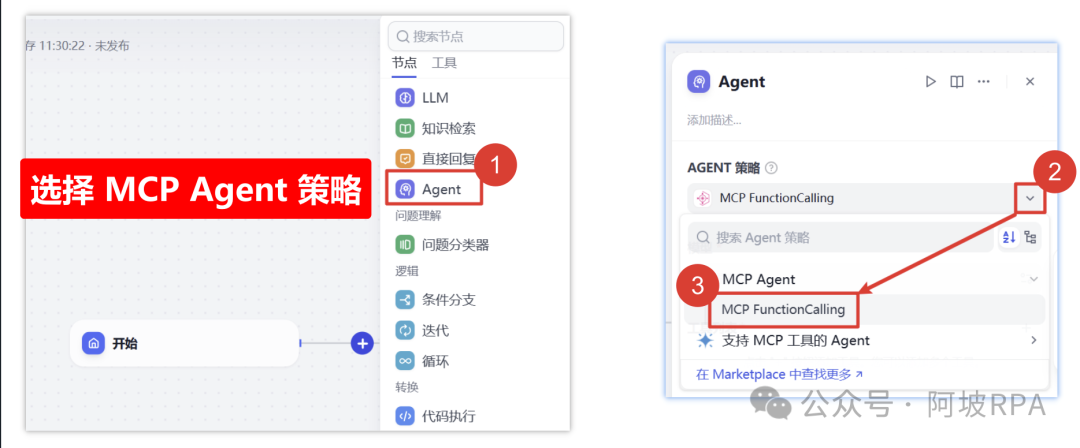
(四)Agent策略节点
1、选择策略工具
选择刚才下载的 MCP Agent 策略作为意图识别的工具,他会自主来决策,该选择调用工具列表中的哪个工具执行任务
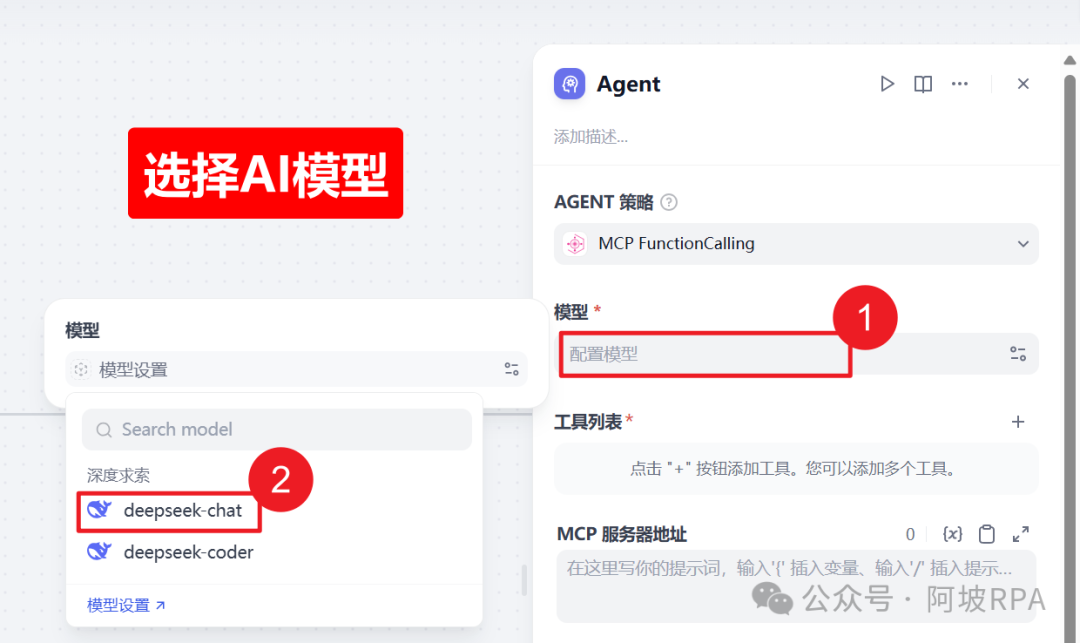
2、选择AI模型
3、添加工具
① 点击添加工具
② 选择前面安装的插件工具
获取MCP工具列表,调用MCP工具,两个都要选择,此处仅以第一个为例,第二个操作步骤一样
③ 点击工具授权
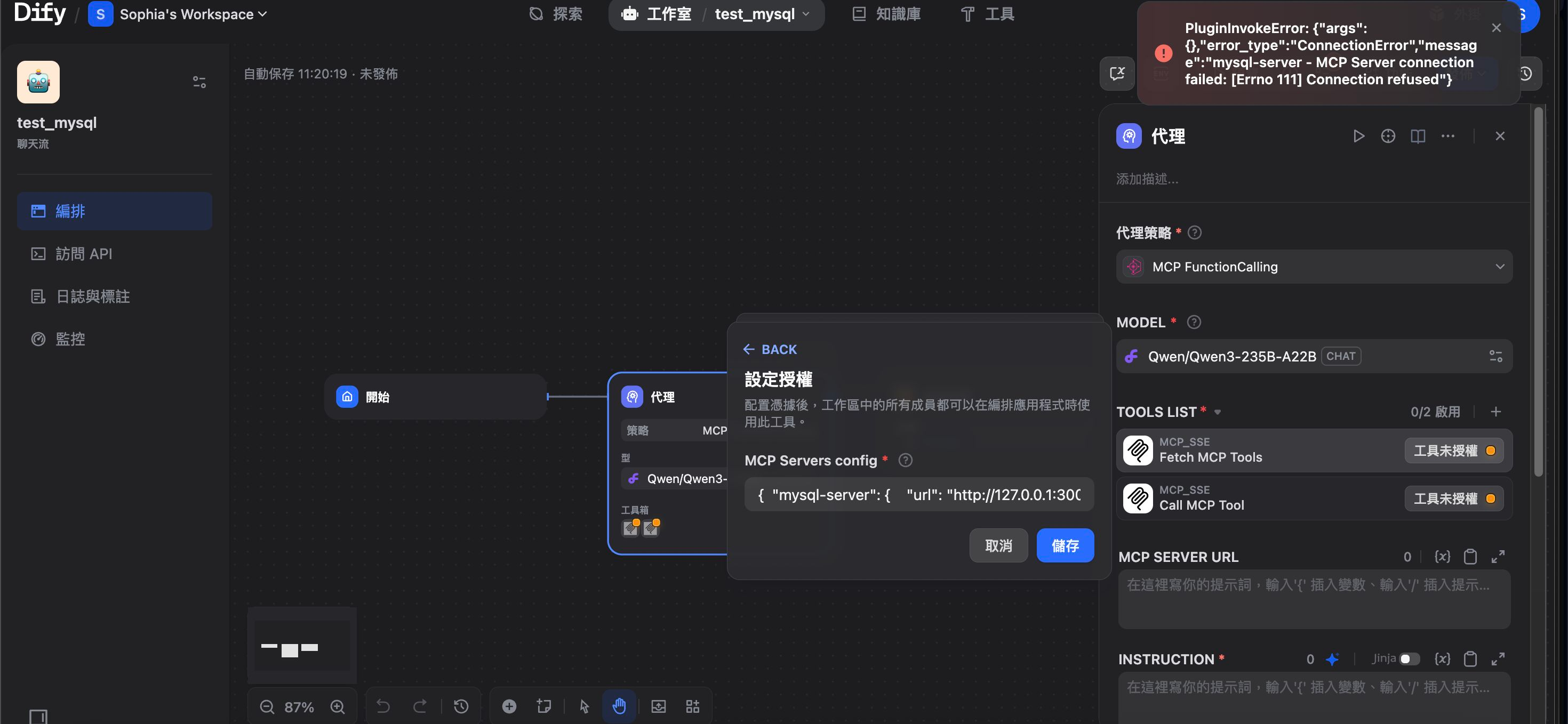
④ 填写MCP的SSE服务配置
此处填写的信息就用到了前面启动MCP服务时我提到的端口号 3000了。
{ "mysql-server": { "url": "http://host.docker.internal:3000/sse", "headers": {}, "timeout": 60, "sse_read_timeout": 300 }}
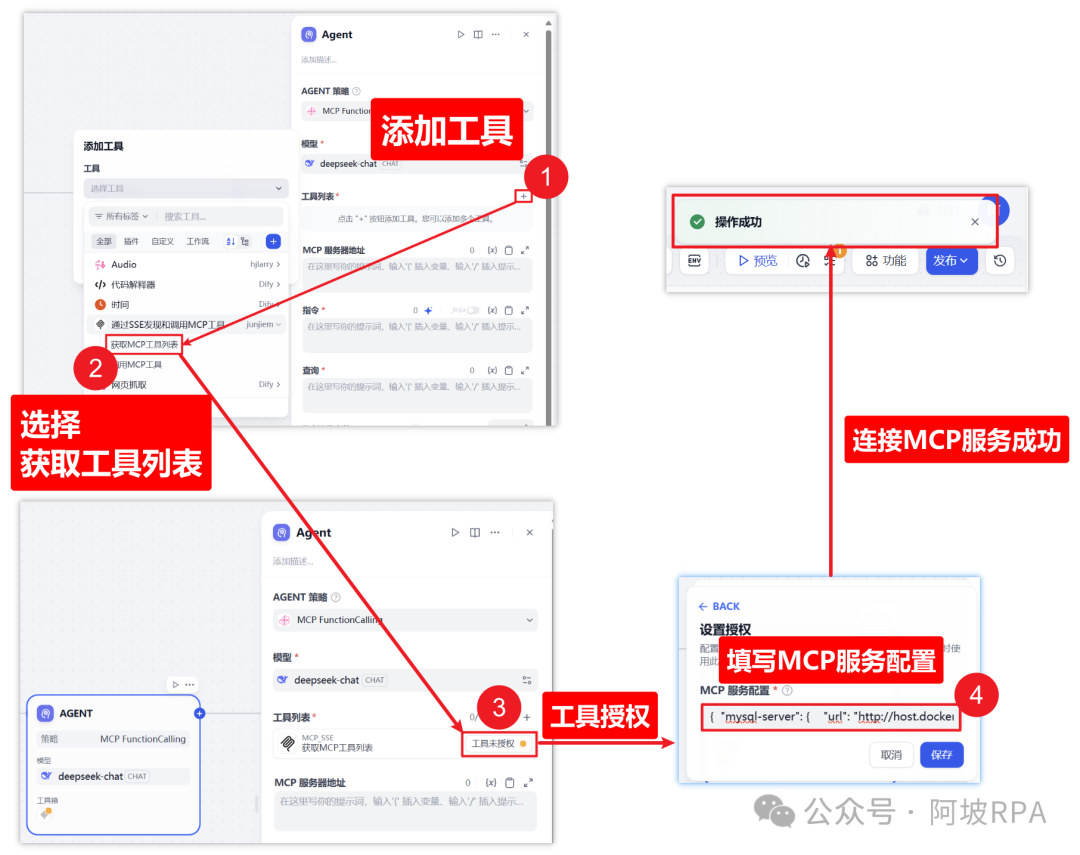
– – 切记:除了端口号,其他信息都不用改。
– – 我一开始以为要根据实际情况自定义,所以尝试在"url"处输入http://127.0.0.1:3000或者http://localhost:3000,也曾尝试把"mysql-server"替换成"mysql_server",都提示无法连接MCP server。后来发现,直接复制粘贴就OK。
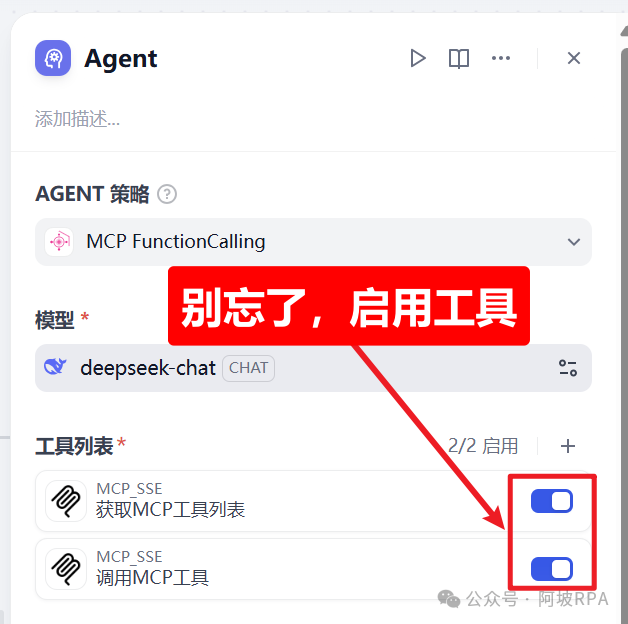
4、启用工具
5、选择另一个工具
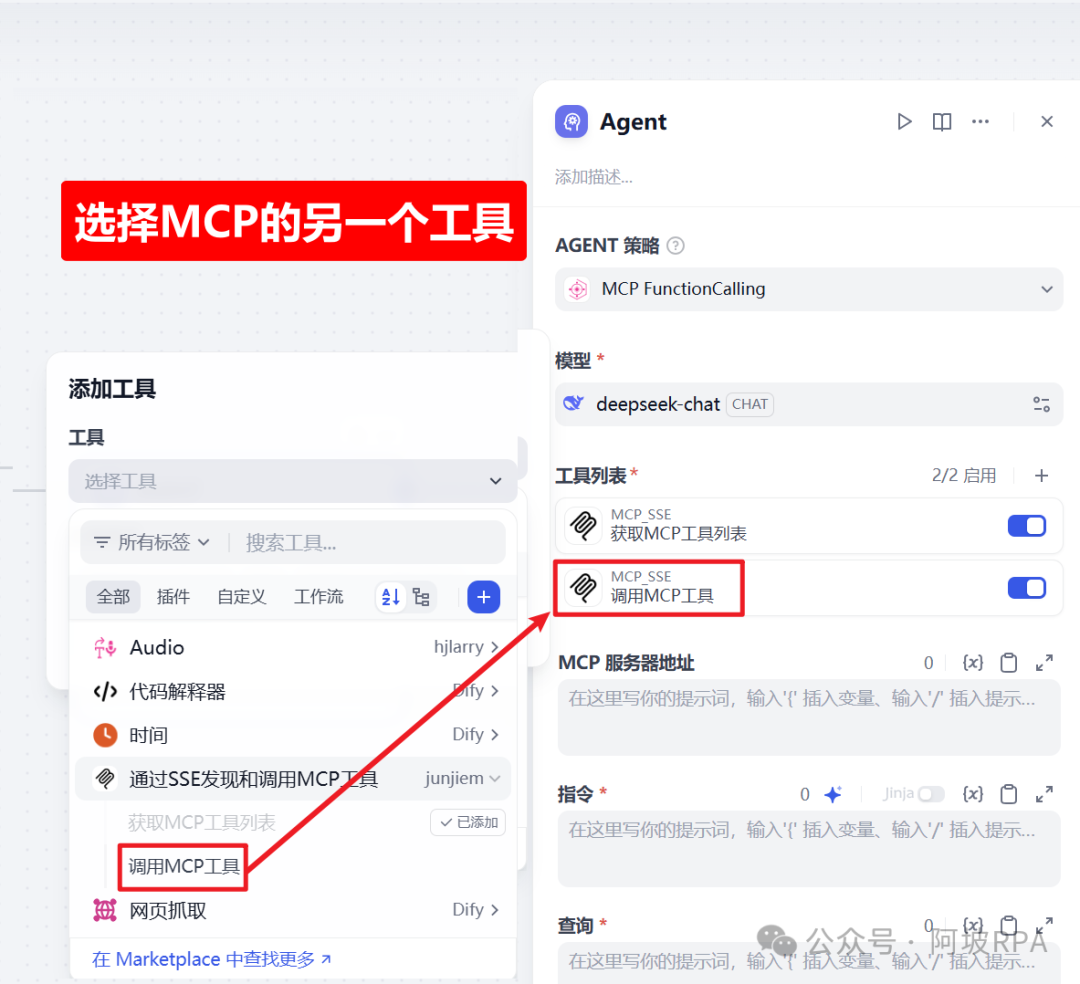
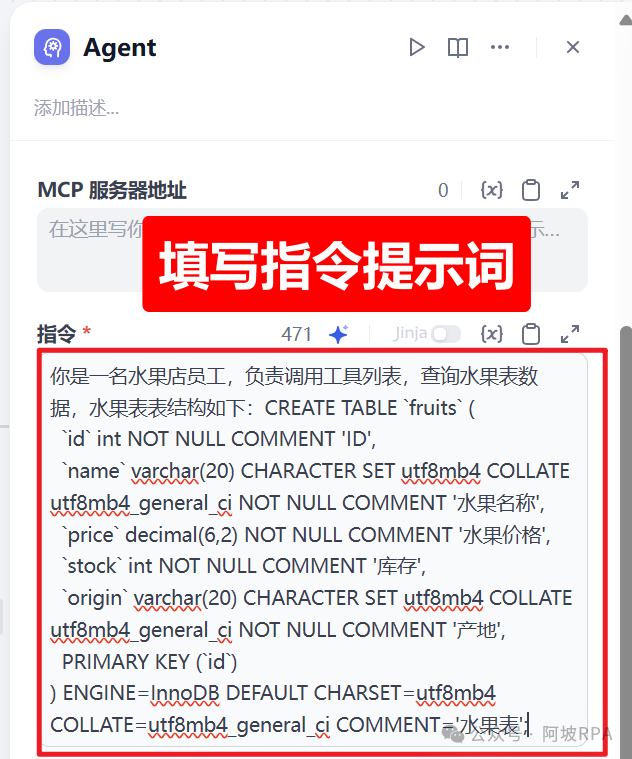
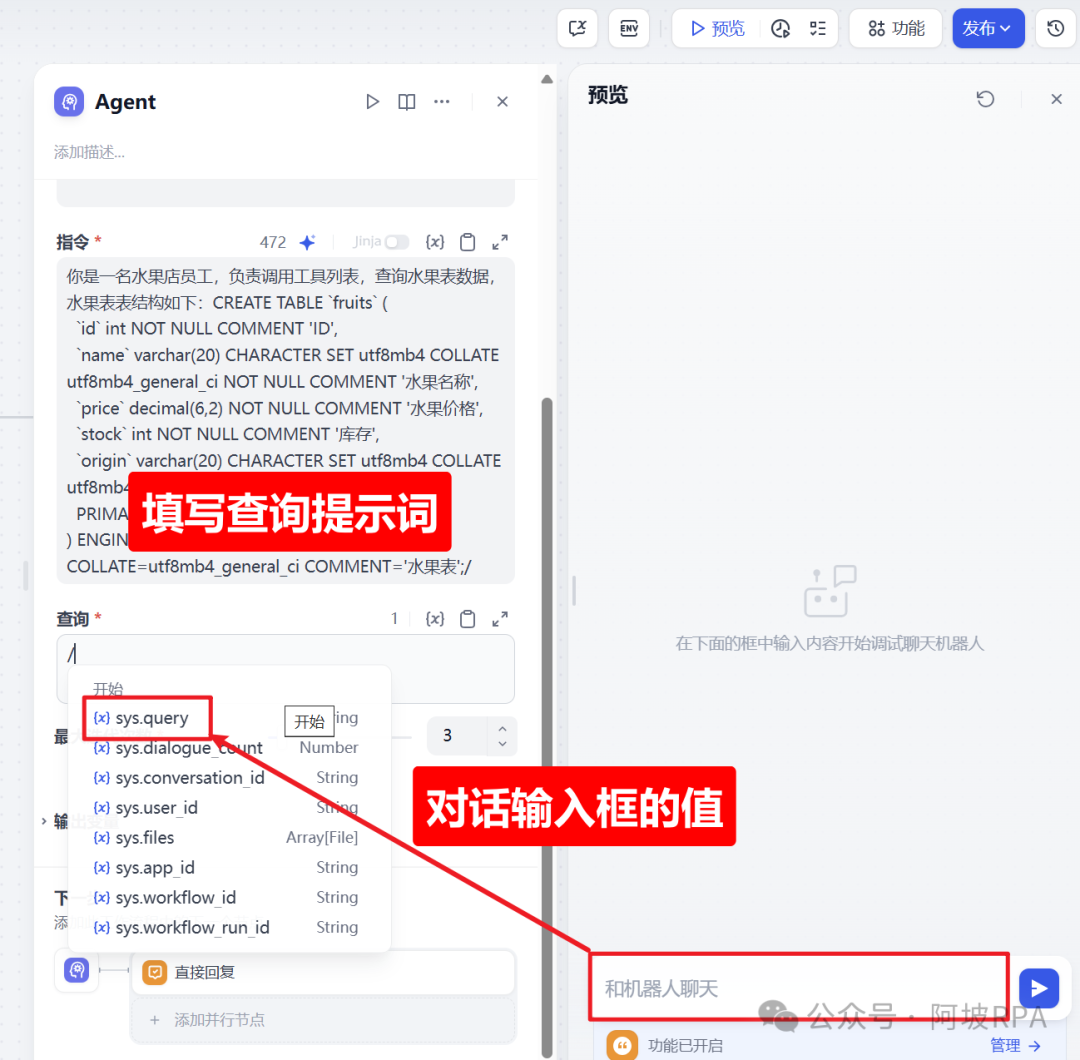
6、填写指令提示词
你是一名水果店员工,负责调用工具列表,查询水果表数据,水果表表结构如下:CREATE TABLE `fruits` (`id` int NOT NULL COMMENT 'ID',`name` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '水果名称',`price` decimal(6,2) NOT NULL COMMENT '水果价格',`stock` int NOT NULL COMMENT '库存',`origin` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '产地',PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='水果表';
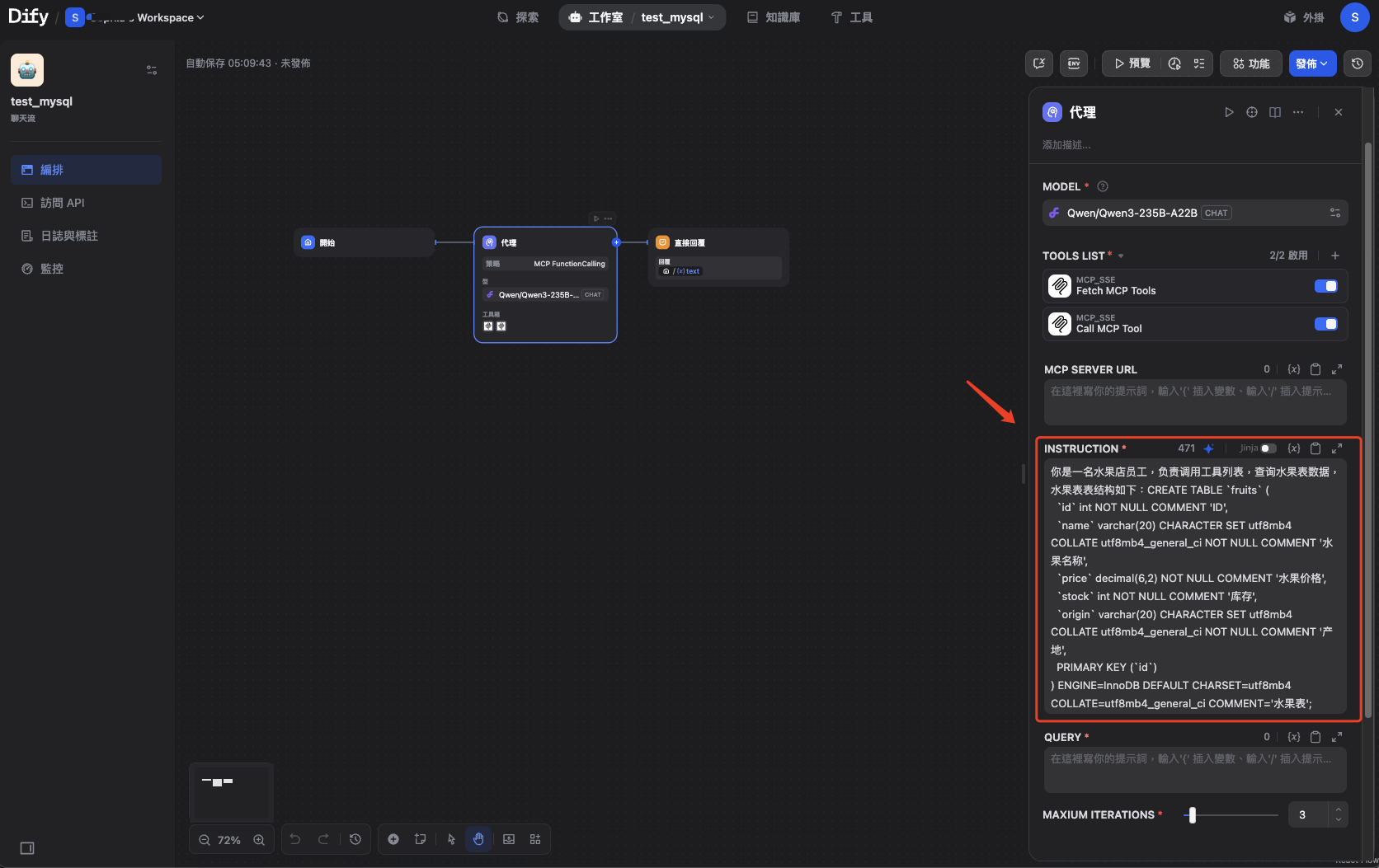
我的提示词和页面:
你是一名投资分析师,负责调用工具列表,查询财经数据,相关表结构如下:
-- ai_agent_test.ods_basicInfo_fund_etf_spot_em definitionCREATE TABLE `ods_basicInfo_fund_etf_spot_em` (`代码` varchar(255) DEFAULT NULL,`名称` varchar(255) DEFAULT NULL,`最新价` double DEFAULT NULL,`IOPV实时估值` double DEFAULT NULL,`基金折价率` double DEFAULT NULL,`涨跌额` double DEFAULT NULL,`涨跌幅` double DEFAULT NULL,`成交量` double DEFAULT NULL,`成交额` double DEFAULT NULL,`开盘价` double DEFAULT NULL,`最高价` double DEFAULT NULL,`最低价` double DEFAULT NULL,`昨收` double DEFAULT NULL,`振幅` double DEFAULT NULL,`换手率` double DEFAULT NULL,`量比` double DEFAULT NULL,`委比` double DEFAULT NULL,`外盘` double DEFAULT NULL,`内盘` double DEFAULT NULL,`主力净流入-净额` double DEFAULT NULL,`主力净流入-净占比` double DEFAULT NULL,`超大单净流入-净额` double DEFAULT NULL,`超大单净流入-净占比` double DEFAULT NULL,`大单净流入-净额` double DEFAULT NULL,`大单净流入-净占比` double DEFAULT NULL,`中单净流入-净额` double DEFAULT NULL,`中单净流入-净占比` double DEFAULT NULL,`小单净流入-净额` double DEFAULT NULL,`小单净流入-净占比` double DEFAULT NULL,`现手` double DEFAULT NULL,`买一` double DEFAULT NULL,`卖一` double DEFAULT NULL,`最新份额` double DEFAULT NULL,`流通市值` bigint DEFAULT NULL,`总市值` bigint DEFAULT NULL,`数据日期` datetime DEFAULT NULL,`更新时间` varchar(255) DEFAULT NULL,`update_time` timestamp NULL DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
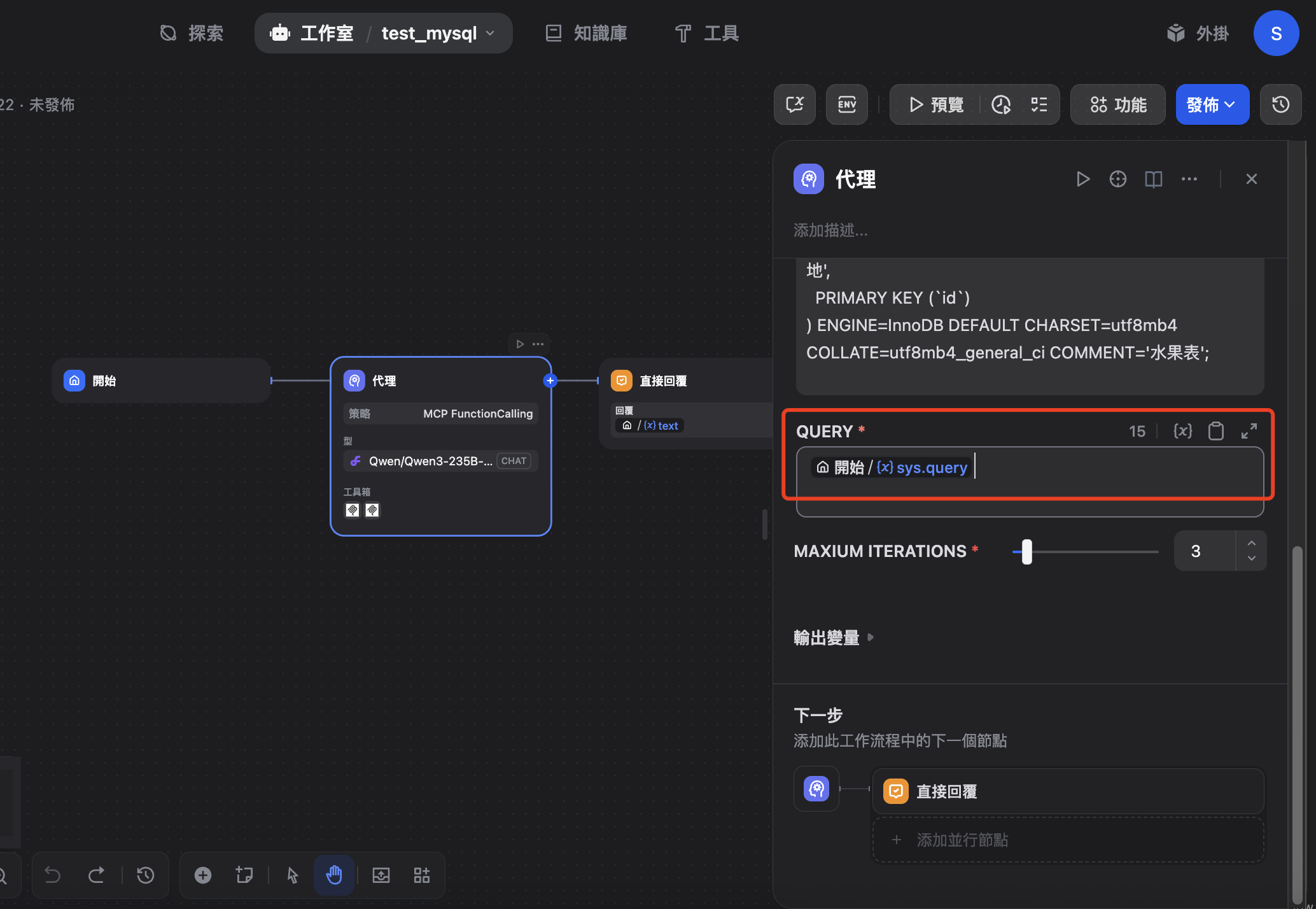
7、设置查询提示词
聊天输入框的值就是 sys.query
上图是原帖,下面附上我的步骤: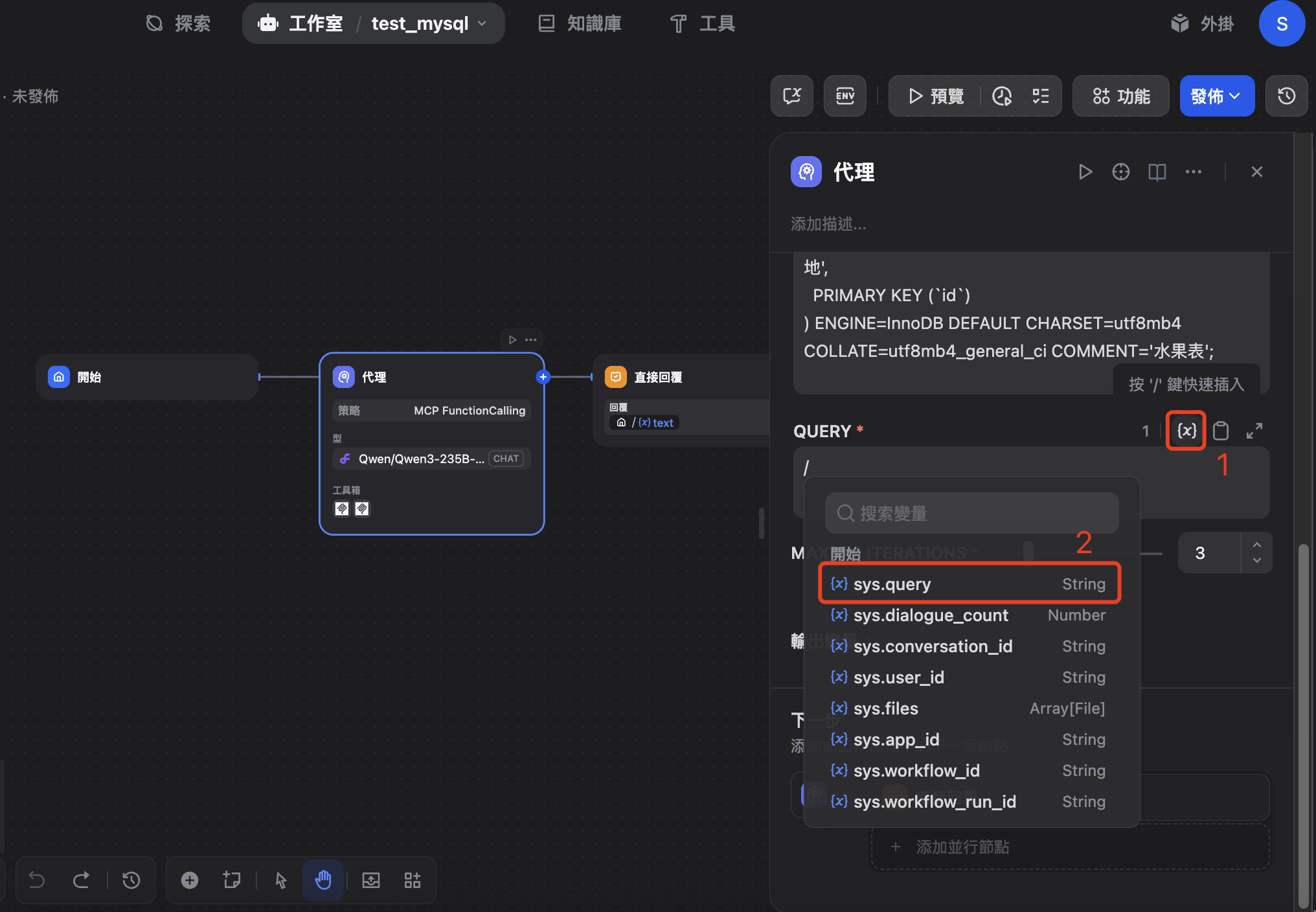
然后显示如下:
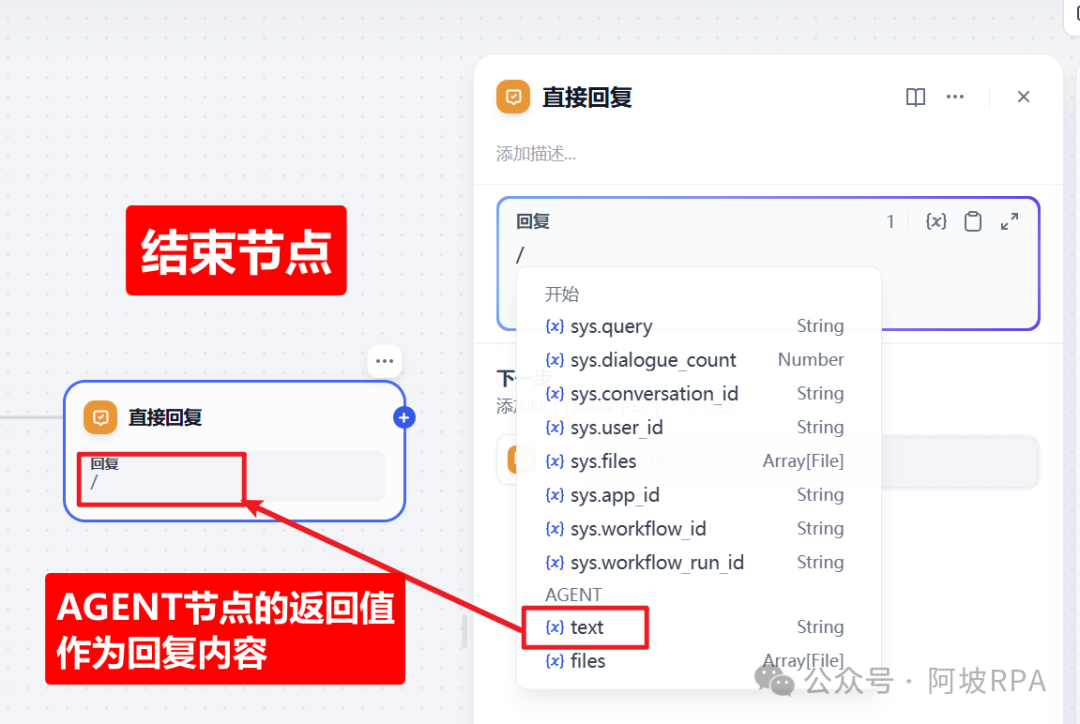
(五)直接回复节点
(六)测试效果
1、dify的返回结果
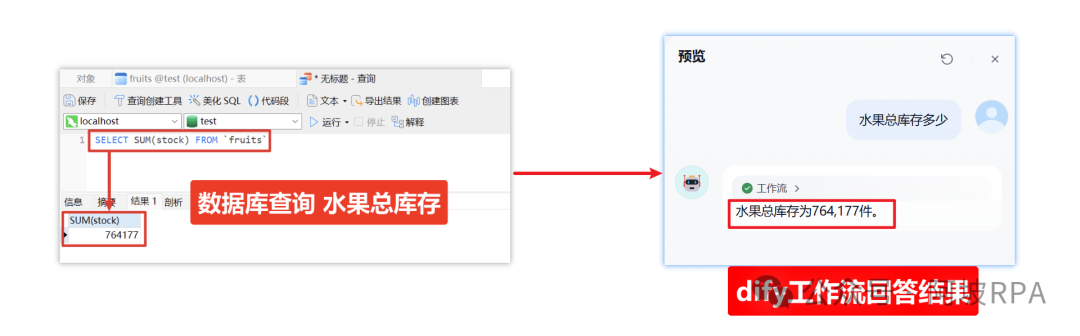
原帖子博主(上图)是成功了,不过我暂时失败了(下图),晚点再更新。
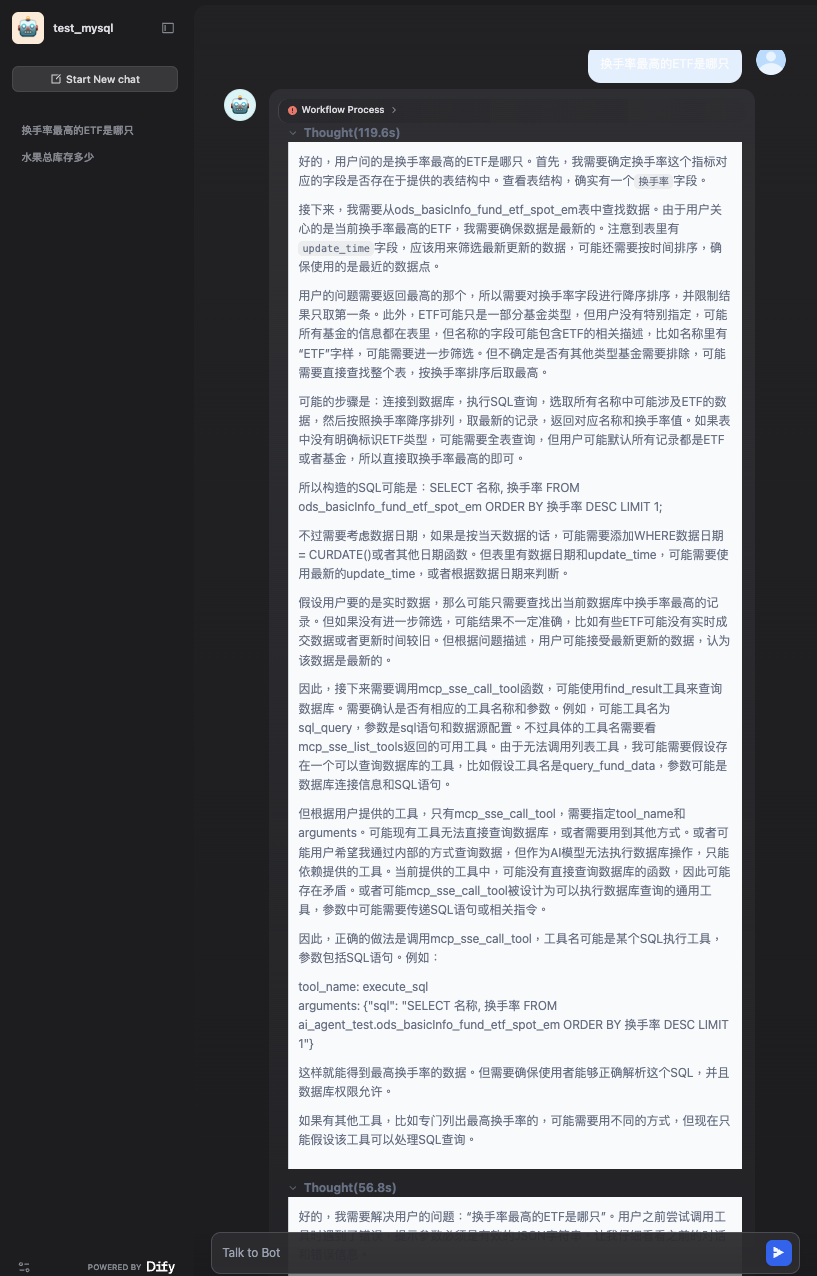
我的提问、大模型思考过程、答案:
提问
换手率最高的ETF是哪只?
思考过程(两轮):
第一轮
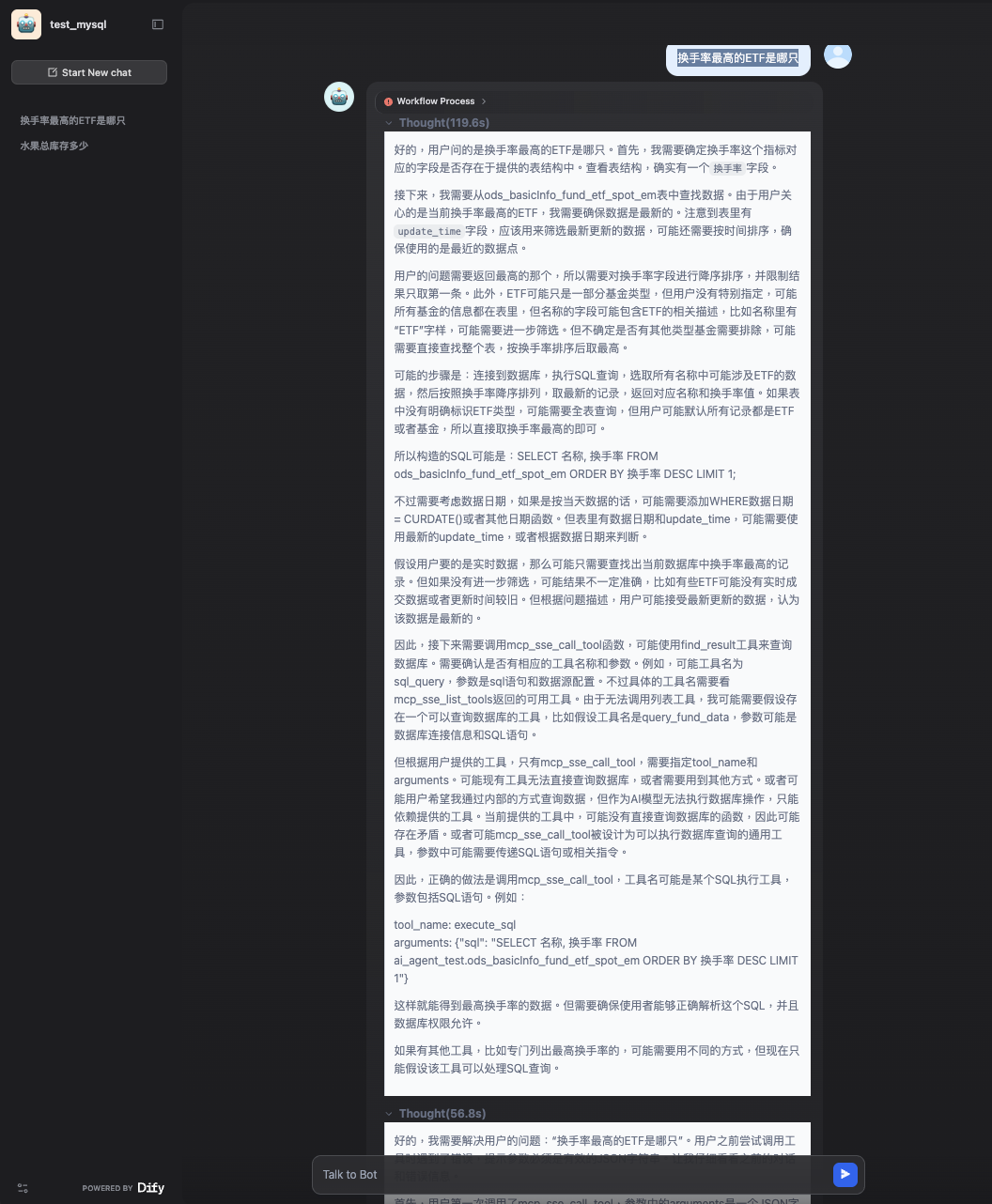
第二轮

答案:
没有输出答案。。
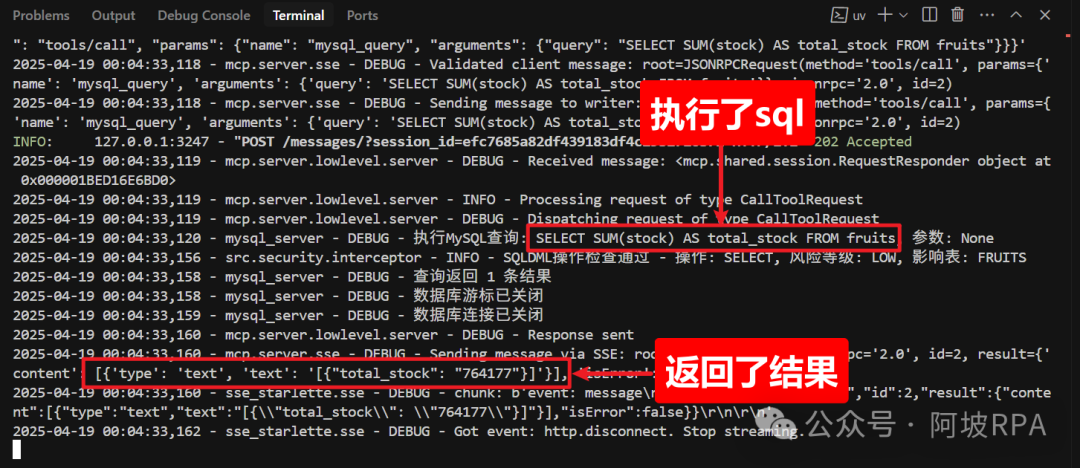
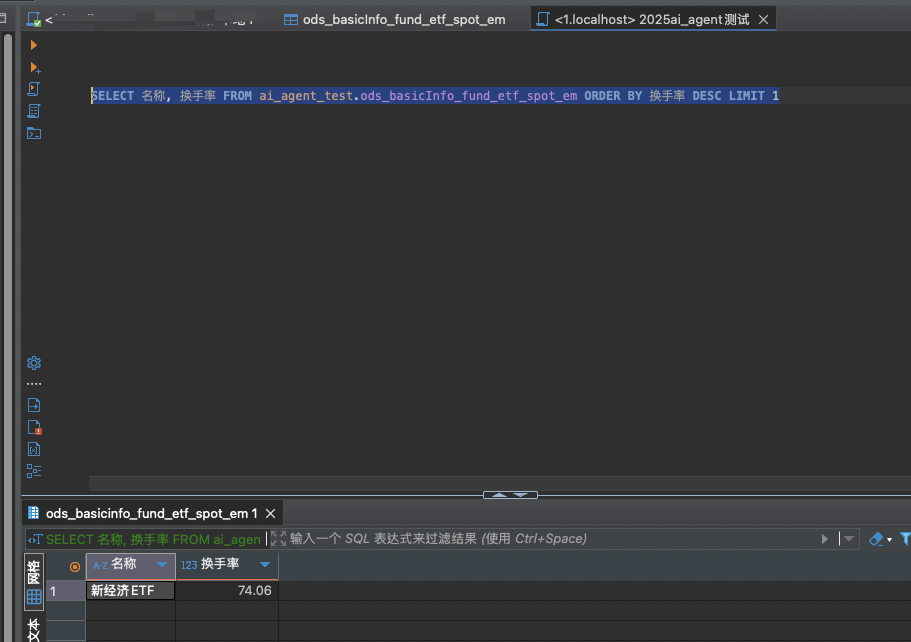
下图是我通过thinking思考过程中提及的sql语句,去debeaver中直接查询而来。
2、可以看到MCP服务控制台的打印信息
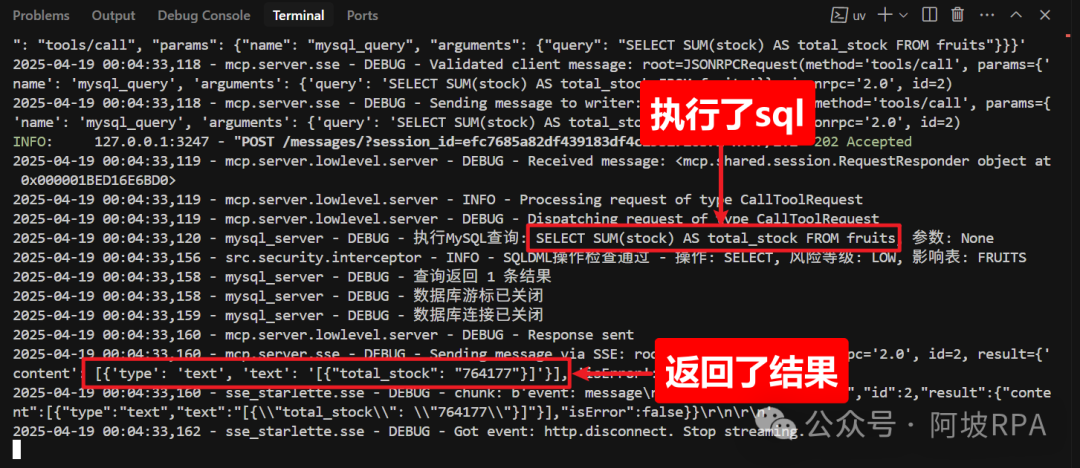
3、工作流的日志追踪
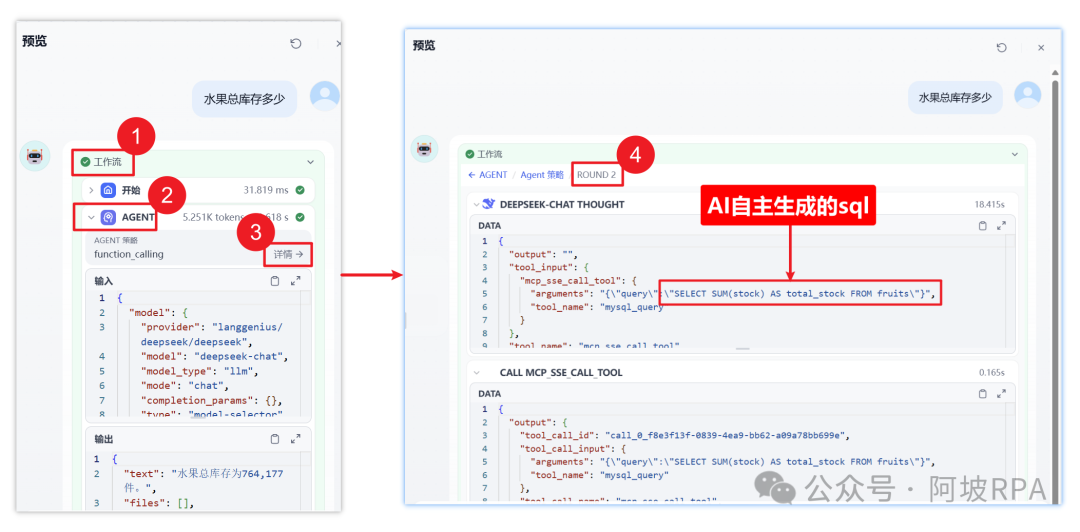
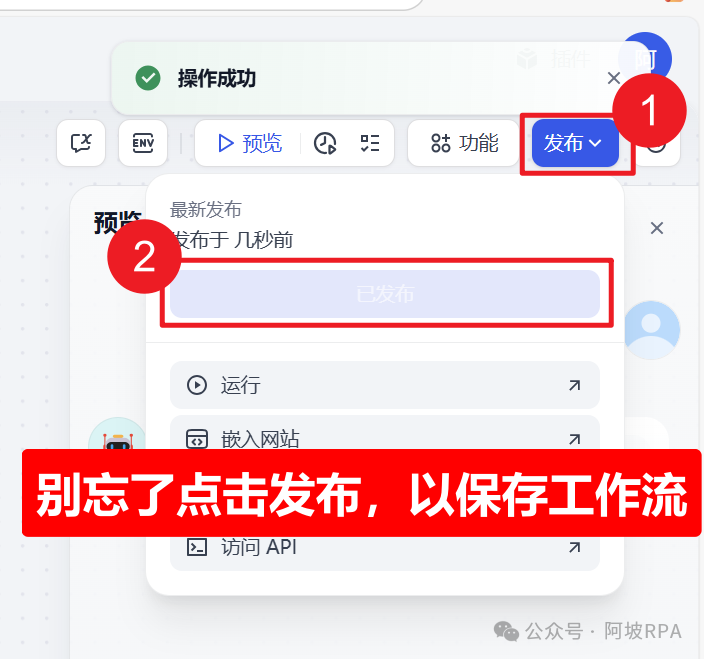
(七)保存工作流
总结
MCP结合数据库的方案为Dify等知识库应用提供了高效、精准的结构化数据检索能力,显著提升了数据查询的准确性和灵活性,弥补了RAG的检索精度上的不足。
但是,这一方案也是有缺点的,与RAG每次只检索相关文本片段不同,MCP+数据库会真正执行SQL查询,若一次查询数据量过大,会消耗大量Token,甚至可能导致MCP客户端卡死。
在实际应用中,我们应该将两种技术结合使用,取长补短,灵活处理自己的业务场景。