Minimax-speech-hd
paper
文章目录
- abstract
- Method
abstract
- speech_encoder 提取音色信息,不需要prompt text(更加适用于跨语言任务,解耦了prompt 文本和prompt style/timbre)
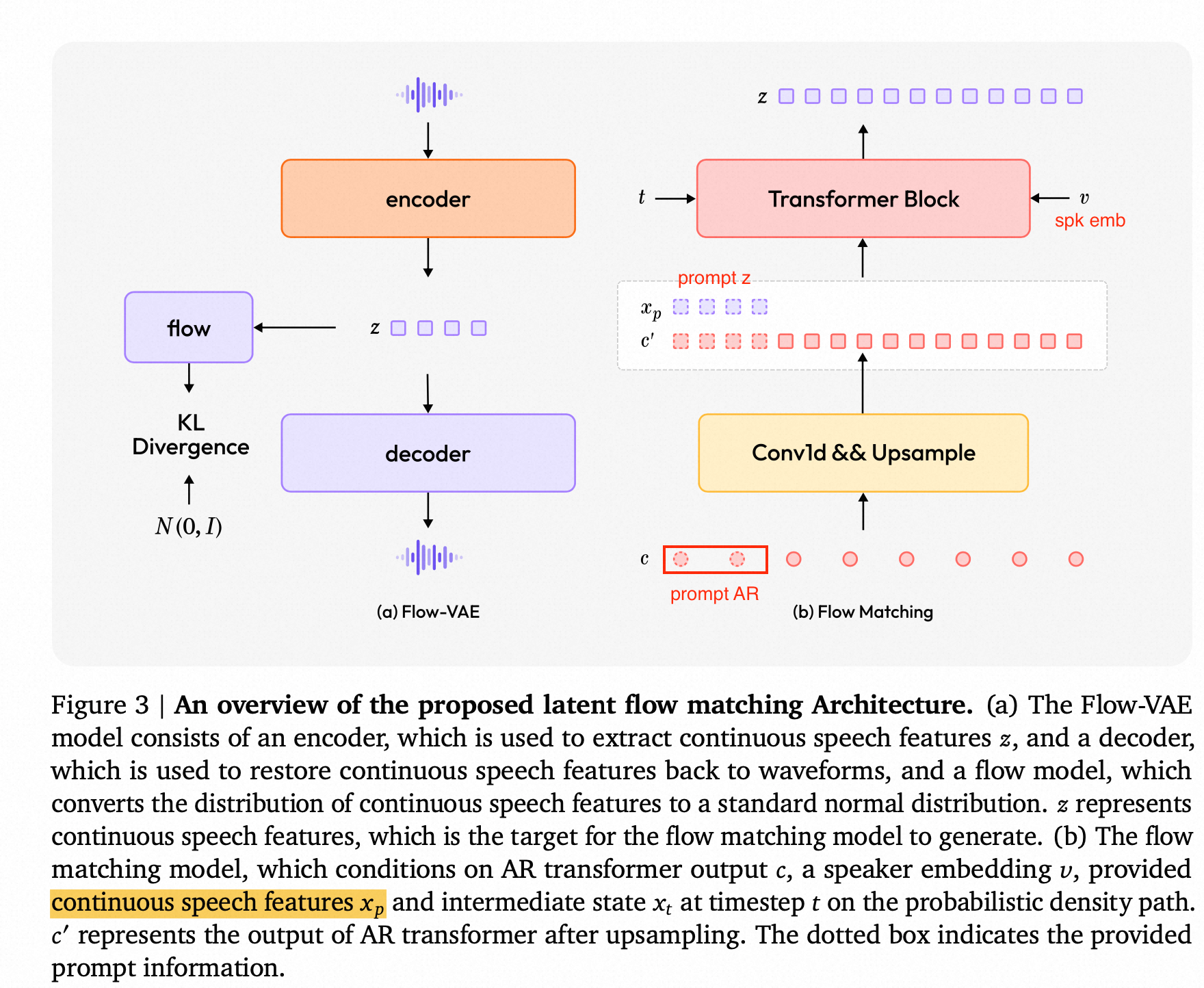
- Flow-VAE 提升合成音质;
Method
- speaker encoder: 相比于其他预训练的SV 模型,our learnable speaker encoder ensures broader linguistic coverage and potentially enhances generalization.
- VQ: MEL 25hz+CTC LOSS
定义:
zero-shot clone:only prompt audio,
one-shot clone: prompt audio embedding + prompt audio token + prompt text