前端-关于apk文件分片上传
为什么需要分片上传?
一次性处理的致命缺陷:
内存溢出:大文件完全加载到内存
界面冻结:读取过程阻塞主线程
上传失败:单次请求可能超时或被服务器拒绝
需求:一个弹出框,将apk文件上传,显示进度条,上传完毕显示基本信息(比如apk名称,大小点),点击“确定”按钮上传到后端
1、解析apk文件,获得一些基本信息,需要第三方库 App-Info-Parser
2、有的apk文件很大,需要分片上传
3、具体上传的地点:本项目是对象存储,因此只需要调用对象存储的方法;如果不用对象存储,可以考虑第三方库,比如 simple-uploader.js (同事用过)
html中引入第三方库,挂载在window对象上
<script src="/AppInfoParser.js"></script>vue组件
import { uploadFile } from '../components/uploadFile.js'
/*** 解析apk文件* @param file*/
const parseApk = async file => {let resulttry {result = await new window.AppInfoParser(file).parse()if (result) {//通过result获得apk信息,比如应用包名、版本号等,省略// 解析完成后上传文件,分片上传uploadFileMethod()}} catch (e) {if (result && (!result.application.label || result.application.label.length <= 0)) {proxy.$warningTip('获取应用名失败')} else {proxy.$warningTip('解析失败,请重试')}console.log('解析apkFile失败', e)}
}
const fileBuffer = ref([])
let fileLength = ref(1) //原始分片数
let taskComplete = ref(1) //已完成上传的分片数/*** 上传文件*/
const uploadFileMethod = async () => {// 文件分片fileBuffer.value = await uploadFile(file.value, 5 * 1024 * 1024)fileLength.value = fileBuffer.value.length
}uploadFile.js 文件
export const uploadFile = async (file, chunkSize = 8 * 1024 * 1024) => {let buffersArray = await getFileChunk(file, chunkSize)return buffersArray
}/*** 获取文件分块成二维数组的buffer* @param {*} file 需要分块的文件* @param {*} chunkSize 一块大小,默认为8M(8 * 1024 * 1024)* @returns*/
const getFileChunk = (file, chunkSize) => {return new Promise(resovle => {//兼容性处理,目的是在不同浏览器中安全地获取文件切割方法let blobSlice = File.prototype.slice || File.prototype.mozSlice || File.prototype.webkitSlice,//向上取整,确保最后一片不足 chunkSize 的部分也能被处理chunks = Math.ceil(file.size / chunkSize),currentChunk = 0,fileReader = new FileReader(),buffers = []//每次读取一个分片就会触发一次`onload`事件fileReader.onload = function (e) {const chunk = e.target.result //一个分片大小,是一个 ArrayBuffer 对象,是处理二进制数据的核心类型currentChunk++if (currentChunk <= chunks) {buffers.push(chunk)loadNext() //读取下一个分片} else {resovle(buffers)}}//错误处理fileReader.onerror = function () {console.warn('oops, something went wrong.')}function loadNext() {let start = currentChunk * chunkSize,end = start + chunkSize >= file.size ? file.size : start + chunkSizelet chunk = blobSlice.call(file, start, end) //文件切片fileReader.readAsArrayBuffer(chunk) //触发一次异步读取,执行一次onload事件}//注意函数从这里开始执行!!!loadNext()})
}在 JavaScript 中,Buffer 是处理二进制数据的核心对象,但浏览器环境和 Node.js 环境有所不同,
(浏览器环境)ArrayBuffer:
固定长度的原始二进制数据缓冲区
不能直接操作,需要通过视图对象访问
特点:
1、智能引用:ArrayBuffer 只是指向原始文件的内存映射
2、零拷贝技术:浏览器底层优化,不复制实际数据
3、分片释放:上传后立即解除引用 → 垃圾回收
(Nodejs环境)Buffer 类:
Node.js 特有的二进制处理类
注意:
1、fileReader.readAsArrayBuffer读取为二进制,内容为ArrayBuffer
2、 fileReader.readAsArrayBuffer 触发一次异步读取,会执行一次onload事件
尝试运行上述代码:
<template><div>我是home</div><input type="file" id="fileInput" @change="handleFileSelect"><button @click="handleUpload">上传</button>
</template><script lang="ts" setup>
import {ref} from 'vue'
//省略import上述方法
const fileBuffer = ref([])//buffer数组
let fileLength = ref(1) //原始分片数
const selectedFile = ref(null)//上传文件const handleFileSelect = (event) => {selectedFile.value = event.target.files[0]
}async function handleUpload(){// 文件分片fileBuffer.value = await uploadFile(selectedFile.value, 1 * 1024 * 1024)fileLength.value = fileBuffer.value.length}
</script>发现一个问题:上传1.79M的一个apk文件,把chunkSize改成1*1024*1024(即1M),在onload里 console.log('chunk',chunk),发现 onload 运行了3遍

这是因为:
chunks为2,(因为一共1.79M,chunkSize为1M)
-
第一次 onload 后:
-
currentChunk 从 0 → 1
-
检查:1 <= 2 (true) → 调用 loadNext()
-
-
第二次 onload 后:
-
currentChunk 从 1 → 2
-
检查:2 <= 2 (true) → 调用 loadNext()
-
-
第三次调用 loadNext():
FileReader.readAsArrayBuffer()读到一个空的分片,又触发onload,因此打印看到了第三次执行
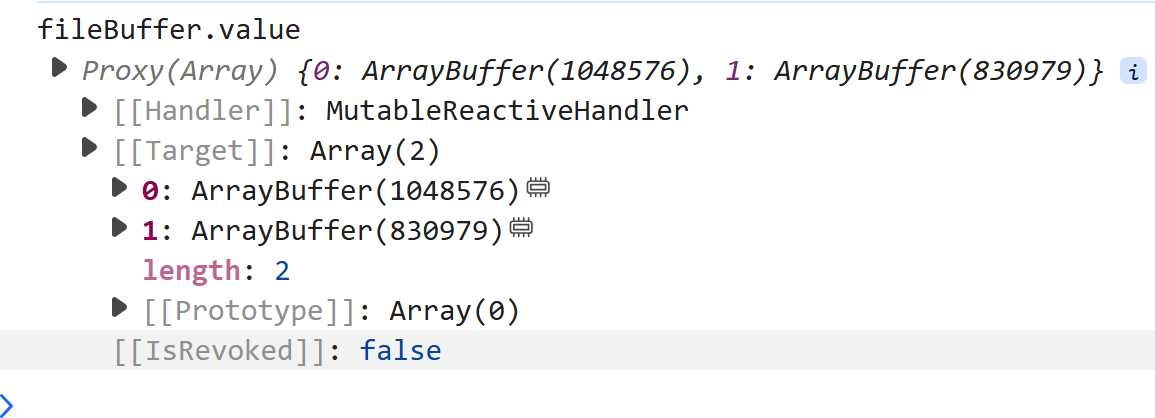
最后的打印结果:fileBuffer.value
AI说的修复逻辑,没试过~
fileReader.onload = function (e) {// 1. 获取当前分片数据(对应currentChunk索引)const chunk = e.target.resultbuffers.push(chunk)// 2. 递增为下一个分片做准备currentChunk++// 3. 检查是否还有更多数据(关键修复)const nextStart = currentChunk * chunkSizeif (nextStart < file.size) {// 还有数据 → 读取下一个分片loadNext()} else {// 所有分片完成resolve(buffers)}
}