xLSTM技术介绍
各位朋友大家好呀,欢迎大家来到每日前沿技术分享专栏,每日进步一点点,积跬步,才能致千里。见证从量变到质变的成长。
今天要分享的是xLSTM技术,看看它到底是怎么让LSTM重获新生的。
LSTM自 20 世纪 90 年代诞生以来,就凭借其处理序列数据的强大能力,在自然语言处理、语音识别等诸多领域大显身手,成为了深度学习领域的一颗明星。它能够有效地解决传统循环神经网络(RNN)面临的梯度消失问题,出色地捕捉时间序列中的长期依赖关系。
然而,随着时代的发展和技术的进步,数据量如同滚雪球一般越来越大,任务也越来越复杂。在这样的大环境下,传统的 LSTM 模型也开始有些力不从心了。它在处理长序列和大规模数据场景时,无论是处理能力还是效率方面,都出现了一些局限性。这时候,Transformer 等新架构迅速吸引了大家的目光,在很多任务中取得了优于 LSTM 的表现, 让 LSTM 一度有些黯然失色。
就当大家都以为 Transformer 将在语言模型领域稳稳占据主导地位的时候,LSTM 以一种全新的姿态 ——xLSTM,强势回归了!xLSTM技术已发表了论文,大家也可以去看看,
项目代码链接:https://github.com/NX-AI/xlstm
一、xLSTM 要解决什么问题
1. 无法修改存储决策
假设有一堆参考向量,现在要按顺序扫描一个序列,在这个序列里找出与参考向量最相似的向量,并且在序列末端给出它的附加值。在这个过程中,如果 LSTM 已经存储了一个看起来比较相似向量的信息,但是后面又遇到了一个更相似的向量,这时候 LSTM 想要修改之前存储的值,就会变得非常困难。这就好像在写一篇文章,已经记录了某个观点,但是后来发现有个更好的观点,却很难把之前记录的内容完全擦掉,重新记录新的观点。
2、 存储容量有限
LSTM 的存储容量是有限的,它必须把信息压缩成标量单元状态来存储。在 LSTM 处理数据时,当遇到一些不常见的 token(可以理解为文本中的单词或者其他数据单元)时,**由于存储容量有限,它就很难很好地处理这些信息,**表现自然也就不尽如人意了。
3. 缺乏可并行性
LSTM 由于内存混合的原因,需要进行顺序处理。从一个时间步到下一个时间步的隐藏状态之间存在隐藏 - 隐藏连接,**所以它不能像 Transformer 那样,同时对所有的 token 进行处理,而只能一个一个按顺序来。**在面对大规模数据时,LSTM 的这种顺序处理方式,就显得效率低下了。

二、xLSTM 的核心方法
1、 指数门控
在 xLSTM 中,一个重要的改进就是引入了指数门控。我们先来回顾一下传统 LSTM 中的门控机制,在传统 LSTM 里,有输入门、遗忘门和输出门,这些门就像是一个个开关,控制着信息的流入、保留和流出。它们通常是由 sigmoid 函数来实现的,sigmoid 函数会把输入的值映射到 0 到 1 之间,以此来决定信息通过的程度。
而在 xLSTM 中,对门控机制进行了升级,引入了指数门控。简单来说,就是对门控的计算方式进行了改变,通过适当的归一化和稳定技术,让门控的作用更加有效。指数门控能够增强每个时刻输入信息对模型状态的修正作用。我们在前面提到过 LSTM 在 “最近邻搜索” 场景中会遇到问题,指数门控就像是给 LSTM 的 “记忆力” 加上了一个 “智能修正器”,当遇到更相似的向量时,它能够更容易地修改之前存储的值,从而更好地适应数据的变化。
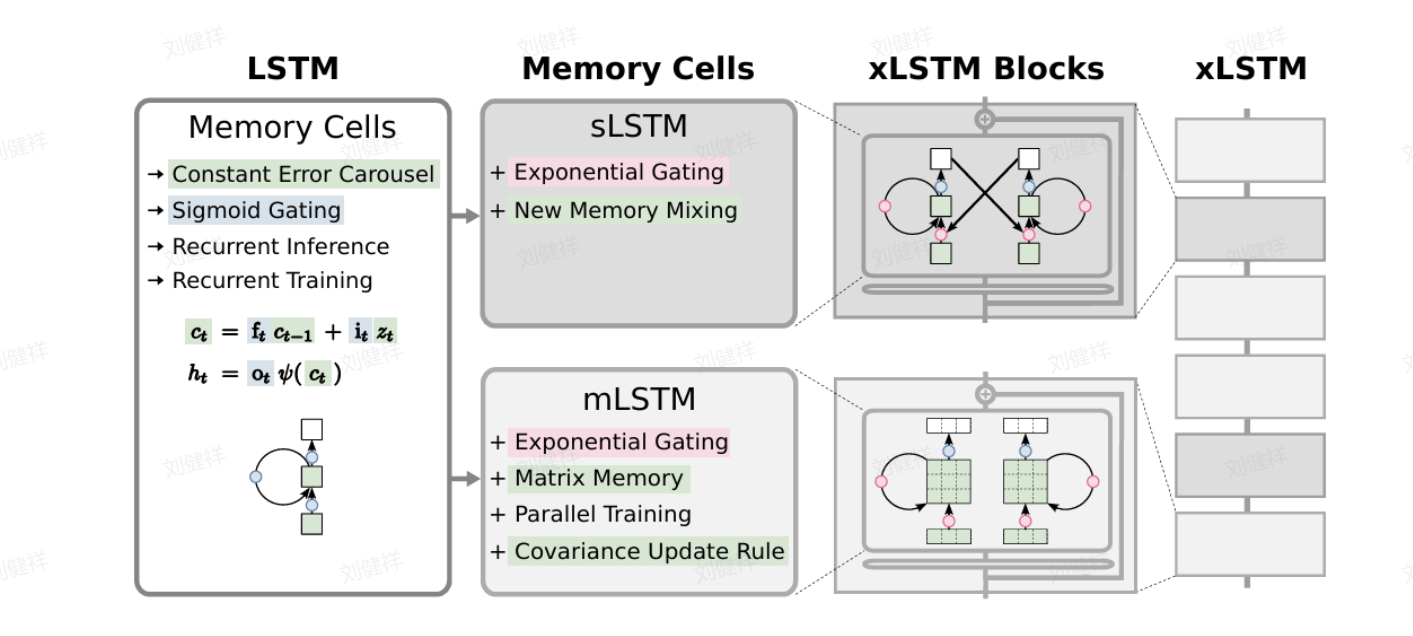
2、 sLSTM(标量内存)
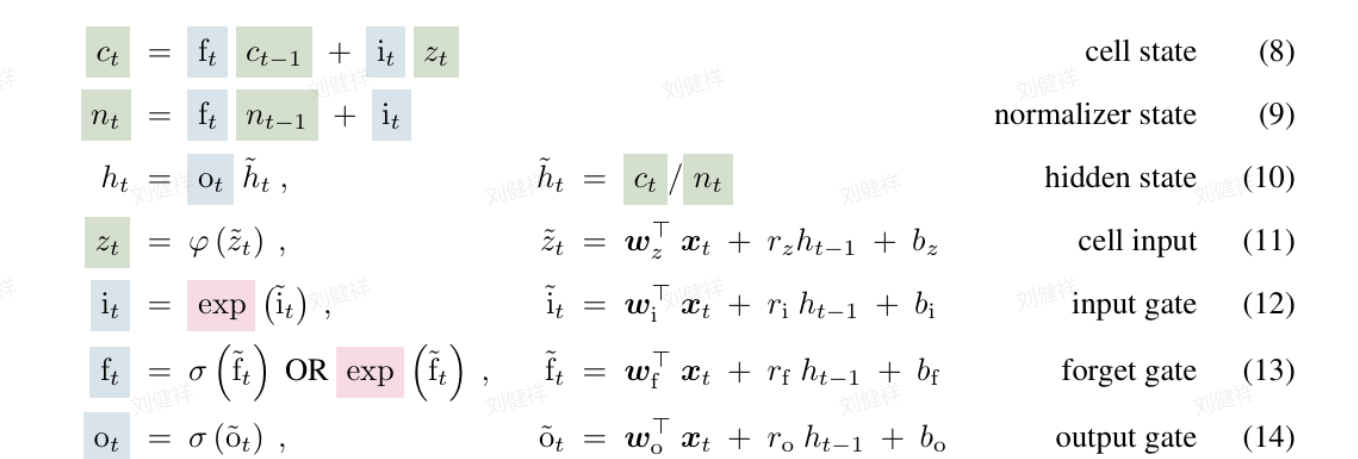
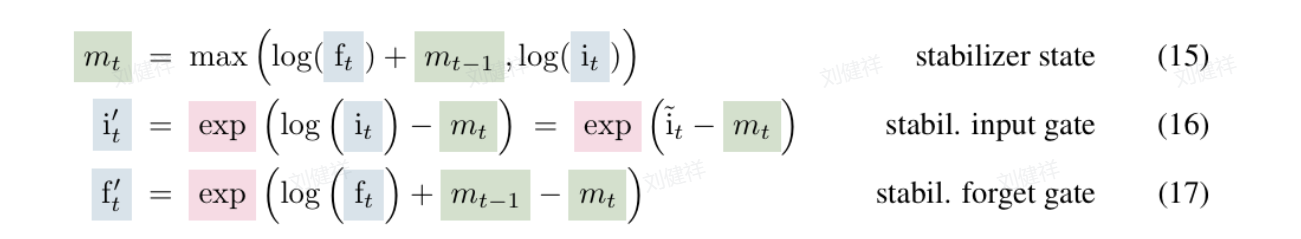
sLSTM 具有标量内存和标量更新的特点。它在存储信息时,采用标量的形式,这和传统 LSTM 有一定的相似性。但是在更新内存的方式上,它又有自己独特的地方。它通过指数门控来对内存进行混合,这种新的内存混合方式,让 sLSTM 在处理信息时更加灵活
另外,LSTM 可以扩展到多个存储单元,并且具有跨单元内存混合的特点。而且,sLSTM 还可以有多个头,不过需要注意的是,不存在跨头的内存混合,而只存在每个头内单元间的内存混合。这样的设计,既保证了模型能够从多个方面提取信息,又避免了不同头之间信息的混乱干扰。
3、 mLSTM(矩阵内存)
点击xLSTM技术介绍查看全文