前端开发定时,ES学习,java集合
1.前端vue3加入定时任务:
import { onMounted, ref,onUnmounted } from 'vue';//初始化,结束调用部分引用let timer: any;//定时器onMounted(async () => {timer = setInterval(() => {open()//需要定时的任务}, 60000)//一分钟调用一次});
onUnmounted(() => {clearInterval(timer)timer = null
})//结束调用,定时器清空其中open这个方法是需要定时刷新的方法,定时在一分钟刷新
2.ES-Elasticsearch-分布式搜索引擎学习
Elaticsearch,简称为es, es是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。es也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
ElasticSearch(简称 ES) 是面向文档的,文档是所有可搜索数据的最小单位。
文档理解为关系型数据库中的一条记录
在 ES 中文档会被序列化成 JSON 格式,保存在 ES 中,JSON 对象由字段组成,其中每个字段都有对应的字段类型(字符串/数组/布尔/日期/二进制/范围类型)
在 ES 中,每个文档都有一个 Unique ID,可以自己指定 ID 或者通过 ES 自动生成
索引简单来说就是相似结构文档的集合,索引可能有很多文档,索引中的数据分散在分片上
在一个的索引当中,可以去为它设置 Mapping 和 Setting,Mapping 定义的是索引当中所有文档字段的类型结构,Setting 主要是指定要用多少的分片以及数据是怎么样进行分布的。
ES 集群其实是一个分布式系统,要满足高可用性,高可用就是当集群中有节点服务停止响应的时候,整个服务还能正常工作,也就是服务可用性;或者说整个集群中有部分节点丢失的情况下,不会有数据丢失,即数据可用性。
数据的增长越来越多的时候,系统需要把数据分散到其他节点上,最后来实现水平扩展。当集群中有节点出现问题的时候,整个集群的服务也不会受到影响
节点其实就是一个 ES 实例,本质上是一个 Java 进程,一台机器上可以运行多个 ES 进程,但是生产环境一般建议一台机器上只运行一个 ES 实例。
默认节点会去加入一个名称为 elasticsearch 的集群,如果直接启动很多节点,那么它们会自动组成一个 elasticsearch 集群,当然一个节点也可以组成一个 elasticsearch 集群。
每一个节点启动后,默认就是一个 Master-eligible 节点,可以通过在配置文件中设置 node.master: false 禁止,Master-eligible 节点可以参加选主流程,成为 Master 节点。当第一个节点启动时候,它会将自己选举成 Master 节点。
每个节点上都保存了集群的状态,只有 Master 节点才能修改集群的状态信息,如果是任意节点都能修改信息就会导致数据的不一致性。
集群状态(Cluster State),维护一个集群中必要的信息,主要包括如下信息:
所有的节点信息
所有的索引和其相关的 Mapping 与 Setting 信息
分片的路由信息
数据节点:负责保存分片上存储的所有数据,当集群无法保存现有数据的时候,可以通过增加数据节点来解决存储上的问题(解决数据存储问题)
Coordinating Node 负责接收 Client 的请求,将请求分发到合适的节点,最终把结果汇集到一起返回给客户端,每个节点默认都起到了 Coordinating Node 的职责。
ES 可以将一个索引中的数据切分为多个分片(Shard),分布在多台服务器上存储。有了分片就可以横向扩展,存储更多数据,让搜索和分析等操作分布到多台服务器上去执行,提升吞吐量和性能。
一个 ES 索引包含很多分片,一个分片是一个 Lucene 的索引,它本身就是一个完整的搜索引擎,可以独立执行建立索引和搜索任务。Lucene 索引又由很多分段组成,每个分段都是一个倒排索引。 ES 每次 refresh 都会生成一个新的分段,其中包含若干文档的数据。在每个分段内部,文档的不同字段被单独建立索引。每个字段的值由若干词(Term)组成,Term 是原文本内容经过分词器处理和语言处理后的最终结果
3.java集合学习(javaguide学习心得):
Java 集合,也叫作容器,主要是由两大接口派生而来:一个是 Collection接口,主要用于存放单一元素;另一个是 Map 接口,主要用于存放键值对。对于Collection 接口,下面又有三个主要的子接口:List(列表)、Set(集合) 、 Queue(队列)
List(对付顺序的好帮手): 存储的元素是有序的、可重复的。Set(注重独一无二的性质): 存储的元素不可重复的。Queue(实现排队功能的叫号机): 按特定的排队规则来确定先后顺序,存储的元素是有序的、可重复的。Map(用 key 来搜索的专家): 使用键值对(key-value)存储,类似于数学上的函数 y=f(x),"x" 代表 key,"y" 代表 value,key 是无序的、不可重复的,value 是无序的、可重复的,每个键最多映射到一个值

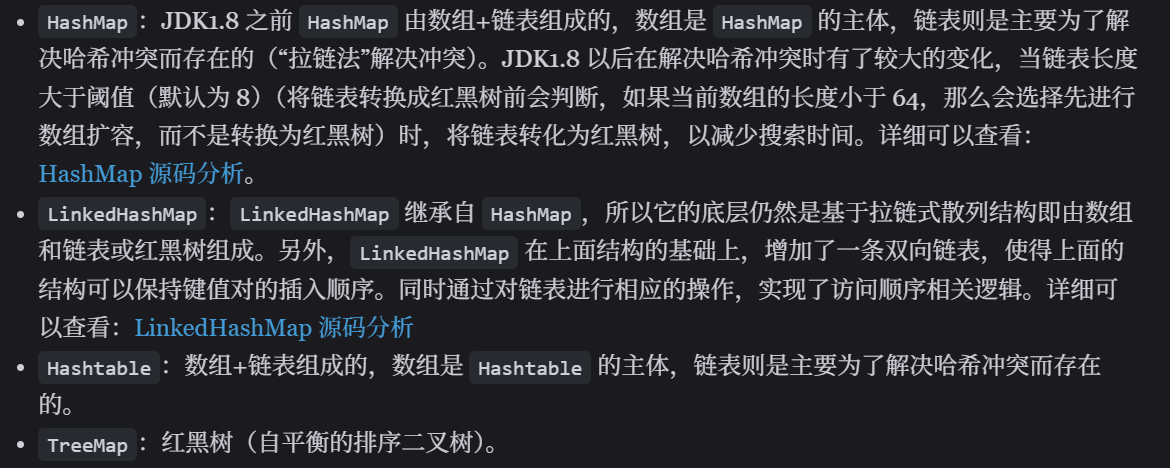
- 我们需要根据键值获取到元素值时就选用
Map接口下的集合,需要排序时选择TreeMap,不需要排序时就选择HashMap,需要保证线程安全就选用ConcurrentHashMap。 - 我们只需要存放元素值时,就选择实现
Collection接口的集合,需要保证元素唯一时选择实现Set接口的集合比如TreeSet或HashSet,不需要就选择实现List接口的比如ArrayList或LinkedList,然后再根据实现这些接口的集合的特点来选用。

使用并发集合类(例如 ConcurrentHashMap、CopyOnWriteArrayList 等)或者手动实现线程安全的方法来提供安全的多线程操作支持
ArrayList 中可以存储任何类型的对象,包括 null 值。不过,不建议向ArrayList 中添加 null 值, null 值无意义,会让代码难以维护比如忘记做判空处理就会导致空指针异常
