deepseek开源资料汇总

参考:DeepSeek“开源周”收官,连续五天到底都发布了什么?
目录
一、首日开源-FlashMLA
二、Day2 DeepEP
三、Day3 DeepGEMM
四、Day4 DualPipe & EPLB
五、Day5 3FS & Smallpond
总结
一、首日开源-FlashMLA
多头部潜在注意力机制(Multi-head Latent Attention)
https://github.com/deepseek-ai/FlashMLA (CUDA)
这是专为英伟达Hopper GPU(H100)优化的高效MLA解码内核,专为处理可变长度序列设计。
在自然语言处理等任务里,数据序列长度不一,传统处理方式会造成算力浪费。而FlashMLA如同智能交通调度员,能依据序列长度动态调配计算资源。例如在同时处理长文本和短文本时,它可以精准地为不同长度的文本分配恰当的算力,避免 “大马拉小车” 或资源不足的情况。发布6小时内,GitHub上收藏量突破5000次,被认为对国产GPU性能提升意义重大。
具体讲解:【DeepSeek开源周】Day 1:FlashMLA 学习笔记_自然语言处理_蓝海星梦-DeepSeek技术社区
-
传统的MHA机制
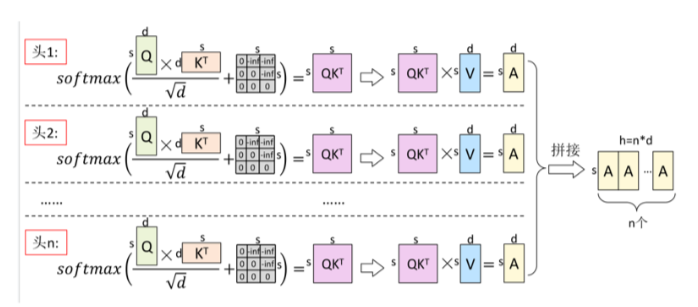
-
DeepSeek-V3的MLA机制
MLA 是多头部潜在注意力机制(Multi-head Latent Attention),其本质是对KV的有损压缩,提高存储信息密度的同时尽可能保留关键细节。 它的核心原理是对注意力键(Key)和值(Value)进行低秩压缩,使用两个线性层和来代替一个大的 Key/Value 投影矩阵,将输入投影到一个低维空间,然后将其投影回原始维度,从而减少存储和计算量。此外,MLA 还可对查询(Query)进行低秩压缩,以进一步减少激活内存。
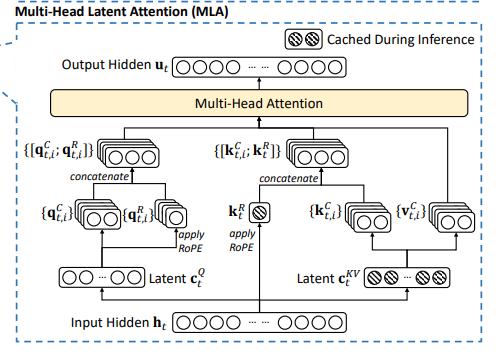
针对MLA与MHA的通俗解释
MLA(Multi-head Latent Attention)和 MHA(Multi-Head Attention)都可以用来实现注意力机制,但它们并不是完全并行的“思考方式”选择,而是针对不同目标优化的设计。
我们可以用图书馆查阅的比喻来理解两者的核心差异:
-
MHA 的思考方式:想象你在一个传统的巨型图书馆查阅资料,每本书(每个注意力头)都完整保留所有原始内容(完整 K/V 缓存),书架按主题(头数 h)严格分区。查阅时每次需要回答问题(计算注意力),必须跑到每个主题区(每个头)翻遍对应书架的所有书籍(加载全部 K/V)
-
MLA 的思考方式:更像是现代化数字图书馆,书籍压缩归档。将相似主题的书籍(h 个头)打包成精华合辑(若干组潜在状态),只保留核心摘要(潜在 K/V),同时为每个合辑建立关键词标签(潜在变量),实时更新内容概要。查阅时先通过关键词标签(潜在状态)定位相关合辑(组),快速浏览摘要(全局注意力),必要时调取合辑内的原始书籍(局部注意力),但频次大幅降低。
相比之下,MHA方式中每个主题区存在重复内容,且随着藏书量增加(序列变长),找书耗时将会快速增长(O(n²)复杂度),这样造成了空间浪费和效率的低下。而MLA找书时间从翻遍全馆变为先看目录再精准查阅(复杂度从降为 O(n) 主导),显著提升了查找效率。
二、Day2 DeepEP
开源EP通信库
https://github.com/deepseek-ai/DeepEP(CUDA)
博客讲解:【DeepSeek开源周】Day 2:DeepEP 学习笔记_开源_蓝海星梦-DeepSeek技术社区
DeepEP是首个用于MoE(混合专家模型)训练和推理的开源EP通信库。MoE模型训练和推理中,不同专家模型需高效协作,这对通信效率要求极高。DeepEP支持优化的全对全通信模式,就像构建了一条顺畅的高速公路,让数据在各个节点间高效传输。
它还原生支持FP8低精度运算调度,降低计算资源消耗,并且在节点内和节点间都支持NVLink和RDMA,拥有用于训练和推理预填充的高吞吐量内核以及用于推理解码的低延迟内核。简单来说,它让MoE模型各部分间沟通更快、消耗更少,提升了整体运行效率 。
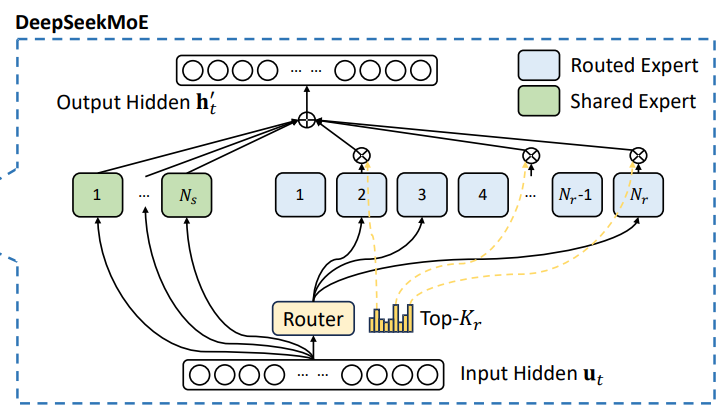
在 DeepSeek‐V3 的 MoE 模块中,主要包含两类专家:
-
路由专家(Routed Experts):每个 MoE 层包含 256 个路由专家,这些专家主要负责处理输入中某些特定、专业化的特征。
-
共享专家(Shared Expert):每个 MoE 层中还有 1 个共享专家,用于捕捉通用的、全局性的知识,为所有输入提供基本的特征提取支持。
token传入MoE时的处理流程:
-
计算得分:首先,经过一个专门的 Gate 网络,该网络负责计算 token 与各个路由专家之间的匹配得分。
-
选择专家:基于得分,Gate 网络为每个 token 选择 Top-K 个最合适的路由专家(DeepSeek‐V3 中通常选择 8 个)
-
各自处理:被选中的专家各自对 token 进行独立处理,产生各自的输出。
-
合并输出:最终,根据 Gate 网络给出的权重加权聚合这些专家的输出,再与共享专家的输出进行融合,形成当前 MoE 层的最终输出表示。
三、Day3 DeepGEMM
矩阵乘法加速库
https://github.com/deepseek-ai/DeepGEMM(python)
博客:【DeepSeek开源周】Day 3:DeepGEMM 学习笔记_学习_蓝海星梦-DeepSeek技术社区
矩阵乘法加速库,为V3/R1的训练和推理提供支持。通用矩阵乘法是众多高性能计算任务的核心,其性能优化是大模型降本增效的关键。DeepGEMM采用了DeepSeek-V3中提出的细粒度scaling技术,仅用300行代码就实现了简洁高效的FP8通用矩阵乘法。
它支持普通GEMM以及专家混合(MoE)分组GEMM,在Hopper GPU上最高可达到1350+ FP8 TFLOPS(每秒万亿次浮点运算)的计算性能,在各种矩阵形状上的性能与专家调优的库相当,甚至在某些情况下更优,且安装时无需编译,通过轻量级JIT模块在运行时编译所有内核。
-
核心亮点
-
FP8 低精度支持:DeepGEMM 最大的特色在于从架构上优先设计为 FP8 服务。传统GEMM库主要优化FP16和FP32,而DeepGEMM针对FP8的特殊性进行了优化设计。
-
极致性能与极简核心实现:DeepGEMM在NVIDIA Hopper GPU上实现了高达1350+ FP8 TFLOPS的计算性能,同时其核心代码仅有约300行
-
JIT 即时编译:DeepGEMM 不是预先编译好所有可能配置的内核,而是利用 JIT 在运行时生成最佳内核。例如,根据矩阵大小、FP8尺度等参数,JIT 会即时优化指令顺序和寄存器分配。
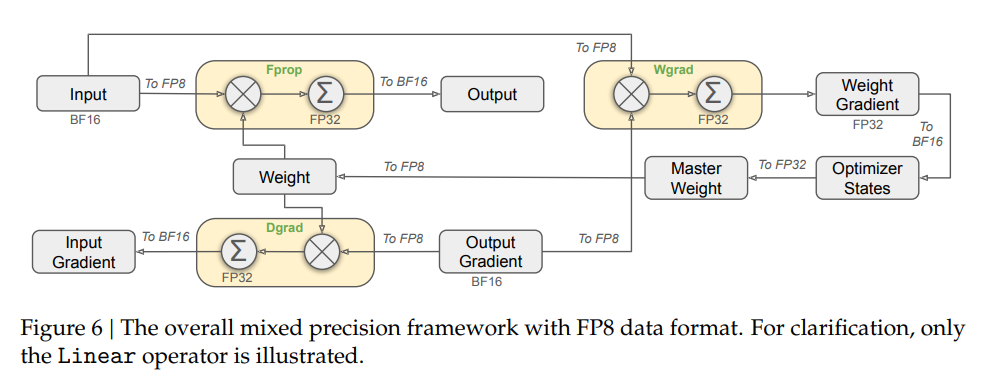
-
传统矩阵乘法 vs. DeepGEMM算法
| 特性 | 传统矩阵乘法 | DeepGEMM算法 |
| 计算方式 | 逐元素顺序计算,无并行加速 | 利用GPU并行计算,分块处理,使用张量核心等优化 |
| 计算速度 | 慢,尤其在大规模矩阵时效率低下 | 极快,能在短时间内完成大规模矩阵乘法 |
| 内存使用 | 内存占用高,可能面临内存不足问题 | 内存管理高效,避免内存瓶颈 |
| 适用场景 | 适用于小型或简单矩阵运算场景 | 专为大规模矩阵运算设计,如深度学习模型训练和推理 |
四、Day4 DualPipe & EPLB
DualPipe:https://github.com/deepseek-ai/DualPipe(python)
EPLB:https://github.com/deepseek-ai/EPLB(python)
博文:https://deepseek.csdn.net/67da0cb5807ce562bfe34746.html
DualPipe是一种用于V3/R1训练中计算与通信重叠的双向管道并行算法。以往的管道并行存在 “气泡” 问题,即计算和通信阶段存在等待时间,造成资源浪费。DualPipe通过实现 “向前” 与 “向后” 计算通信阶段的双向重叠,将硬件资源利用率提升超30%。
EPLB则是一种针对V3/R1的专家并行负载均衡器。基于混合专家(MoE)架构,它通过冗余专家策略复制高负载专家,并结合启发式分配算法优化GPU间的负载分布,减少GPU闲置现象。
五、Day5 3FS & Smallpond
https://github.com/deepseek-ai/3FS(C++)
https://github.com/deepseek-ai/smallpond (python)
博文:https://deepseek.csdn.net/67db6b09b8d50678a24ed021.html
DeepSeep开源了面向全数据访问的推进器3FS,也就是Fire-Flyer文件系统。它是一个专门为了充分利用现代SSD和RDMA网络带宽而设计的并行文件系统,能实现高速数据访问,提升AI模型训练和推理的效率。
此外,DeepSeek还开源了基于3FS的数据处理框架Smallpond,它可以进一步优化3FS的数据管理能力,让数据处理更加方便、快捷。
总结
在 2025 年 2 月 24 日至 28 日的 DeepSeek 开源周期间,DeepSeek 开源了五个核心项目,这些项目涵盖了 AI 开发的计算优化、通信效率和存储加速等关键领域,共同构成了一个面向大规模 AI 的高性能基础设施。
-
FlashMLA:针对 NVIDIA Hopper GPU 优化的多头线性注意力解码内核,显著提升了推理效率,支持实时翻译和长文本处理。
-
DeepEP:专为混合专家模型(MoE)设计的通信库,通过优化节点间数据分发与合并,大幅提升了训练速度。
-
DeepGEMM:基于 FP8 的高效矩阵乘法库,专为 MoE 模型优化,显著提升了大规模矩阵运算效率。
-
DualPipe & EPLB:创新的双向流水线并行算法和动态负载均衡工具,优化了资源利用率,提升了并行训练效率。
-
3FS & Smallpond:高性能分布式文件系统,支持 RDMA 网络和 SSD 存储,解决了海量数据的高速存取与管理问题。
参考:
https://devpress.csdn.net/user/Eternity__Aurora
https://github.com/orgs/deepseek-ai/repositories?type=all